[교재] 데이터베이스 첫걸음 4장 - 데이터베이스와 아키텍처 구성
4장. 데이터베이스와 아키텍처 구성 - 견고하고 고속의 시스템을 구축하기 위해
아키텍처
- 아키텍처
- 시스템의 구성. 시스템을 만들기 위한 물리 레벨의 조합
- 어떤 기능을 가진 서버를 준비하고 어떤 저장소나 네트워크 기기와 조합하여 시스템 전체를 만들 것인지
- 즉, 하드웨어와 미들웨어의 구성
- 시스템의 목적과 기능의 의미도 포함됨
- 구축 시작 시 이후 아키텍처 변경이 매우 어려움
- 아키텍처 설계
- 아키텍처 구성을 시스템이 완수해야할 목적과 비교하면서 결정해 가는 것
- 서버, OS, 데이터베이스, 기타 미들웨어, 저장소, 로드밸런서나 방화벽 같은 네트워크 기기 등까지 폭넓은 지식 필요
- 가용성, 신뢰성, 재해대책, 성능, 보안 같은 비기능적 요건에 따라 아키텍처 구조가 바뀜
데이터베이스의 아키텍처
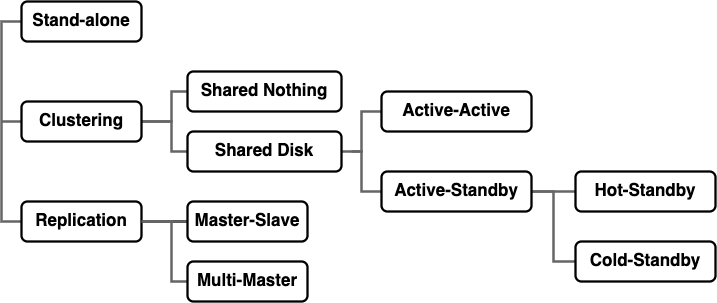
역사와 개요
- Stand-alone (~1980s)
- DB 서버가 LAN이나 인터넷 등의 네트워크에 접속하지 않고 독립되어 동작하는 구성
- DBMS와 애플리케이션 소프트웨어가 같은 DB 서버에서 동작
- 구축이 간단하여 소규모 작업이나 테스트를 빠르게 수행 가능
- 네트워크로 침입할 위험이 없어 보안이 매우 높음
- 물리적으로 떨어진 장소에서 접근 불가
- 복수의 사용자가 동시에 작업 불가
- 가용성이 낮음 (서버 1대에 장애가 발생하면 서비스 정지)
- 확장성 부족 (서버나 부품을 교환하는 방법 뿐이며 교환 시 시스템 정지로 가용성 감소)
- Client/Server (1990s~2000)
- 서버 1대에 복수 사용자의 단말이 접속하는 구성
- 2계층 구성이라고 부르기도 함
- DB 서버에서는 DBMS가 동작하고 클라이언트에서는 업무 애플리케이션이 동작하는 분업체제
- 클라이언트: 엔드 사용자가 직접 조작해 수행하고 싶은 처리 명형을 내보내는 머신
- 서버: 클라이언트로부터 받은 명령을 실행해 업무 처리(비즈니스 로직)를 실행하기 위한 머신
- 인터넷에서 직접 데이터베이스에 접속하는 것에 대한 보안 위험 존재
- 불특정 다수의 사용자가 사용하는 클라이언트에서의 애플리케이션 관리 비용이 많이 듦
- Web 3계층 (2000~)
- 웹 서버 계층: 클라이언트로부터 접속 요청(HTTP 요청)을 직접 받아 애플리케이션 계층(애플리케이션 서버)에 넘기고 그 결과를 클라이언트에 반환
- 애플리케이션 계층: 비즈니스 로직을 구현한 애플리케이션에서 동작하는 층
- 웹 서버로부터 연계된 요청을 처리
- 필요 시 DB 서버에 접속하여 데이터 추출 후 가공한 결과를 웹 서버로 반환
- 사용자로부터 직접적인 접속 요청을 받는 역할을 웹 서버 계층에 한정하여 애플리케이션 계층과 데이터베이스 계층의 보안을 높임
- 애플리케이션 계층에 비즈니스 로직을 집중하여 애플리케이션 관리 비용을 낮춤
- 데이터베이스 계층
DB 서버의 다중화 (또는 고가용성) - 클러스터링
가용성과 확장성
- 가용성
- 사용자 입장에서 볼 때 시스템을 어느 정도 사용할 수 있는지. 사용자 관점
- 시스템이 서비스 제공시간에 장애 없이 서비스를 지속할 수 있는 비율
- 서버 2대가 있다면 1대가 고장나더라도 나머지 1대가 동작하면 서비스의 정지를 막을 수 있음
- cf) 신뢰성: 하드웨어나 소프트웨어가 고장나는 빈도(고장률)나 고장 기간. 시스템 컴포넌트 관점
- 가용성 전략
- 고품질-소수전략: 시스템을 구성하는 각 컴포넌트의 신뢰성을 높여 장애 발생률을 낮게 억제하여 가용성을 높임
- 저품질-다수전략: 시스템을 구성하는 각 컴포넌트의 신뢰성을 계속해서 높이기보다는 사물은 언젠가 망가진다란 체념을 전제로 여분을 준비
- 클러스터
- 동일한 기능의 컴포넌트를 여러 개 준비하여 한 개의 기능을 실현
- 클러스터링: 저품질-다수전략처럼 동일한 기능의 컴포넌트를 병렬화하는 것
- 여유도(Redundancy) 확보 또는 다중화: 클러스터 구성으로 시스템 가동률을 높이는 것
- 단일 장애점(SPOF, Single Point of Failure)
- 다중화되어 있지 않아 시스템 전체 서비스의 계속성에 영향을 주는 컴포넌트
다중화 전략
- Active-Active
- 클러스터를 구성하는 컴포넌트를 동시에 가동
- 시스템 다운 시간이 짧고 성능이 좋음
- 저장소에 병목 현상 발생 가능
- Active-Standby
- 실제 가동하는 것은 Active, 남은 것은 대기(Standby)하다 Active에 장애가 생기면 가동 -> 전환까지의 시차 발생
- Standby는 일정 간격으로 Active에 Heartbeat를 보내 이상이 없는지 확인. 응답이 없다면 Active가 다운된 것을 감지
- Cold-Standby: 평소에는 Standby가 작동하지 않다가 Active가 다운된 시점에 작동
- Hot-Standby: 평소에도 Standby가 작동. 전환 시간이 짧지만 라이선스료 높음
Shared Disk
- 복수의 서버가 1대의 저장소를 사용하는 구성
- Shared Disk 타입의 Active-Active 구성은 DB를 아무리 늘려도 처리율에 한계가 있음
- 저장소가 공유자원이라 쉽게 늘리기 어렵고 DB 서버 대수가 증가할수록 정보공유를 위한 오버헤드가 큼
Shared Nothing
- 네트워크 이외의 자원을 모두 분리. 아무것도 공유하지 않음
- 서버와 저장소의 세트를 늘리면 병렬 처리로 성능이 선형적 향상
- 비용 대비 성능이 좋음
- 각 서버의 DB 서버가 동일한 1개의 데이터에 액세스 불가
- DB 서버 하나가 다운되었을 때 다른 DB 서버가 이를 이어받아 계속 처리할 수 있게 하는 Covering 구성 고려 필요
DB 서버와 데이터 다중화 - Replication
- DB 서버와 저장소를 세트로 다중화
- RAID (Redundant Array of Independent Disks)
- 저장소 내부의 컴포넌트(대부분 하드디스크)를 다중화하는 기술
- 기본적으로 클러스터링과 동일하게 단일 장애점을 없앰
- Standby에 데이터 갱신을 반영하여 동기화하지 않으면 데이터 정합성 유지 불가
- 갱신 주기에 따라 정합성과 성능 사이에 trade-off 발생
- 피라미드형 Replication
- 데이터가 오래되어도 참조만 하면 되는 처리를 child set에서 처리
- parent set에 걸리는 부하 분산
- 그만큼 DB 서버의 라이선스료와 서버, 저장소의 비용, 구성 노력 증가
- Master-Slave 방식: Active-Standby 형식의 Replication
- Multi Master 방식: 양방향 Replication
