
기존에 구글에서 서치해서 찾아볼 수 있는 스마트스토어 리뷰 스크래핑 코드에서 일부 수정한 코드입니다. 데모데이 프로젝트를 위해 바늘이야기 네이버 스마트 스토어에 등록되어 있는 제품들의 리뷰를 스크래핑해 텍스트 분석을 해보려고 합니다.
1. 사용할 라이브러리 불러오기
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time, random, datetime
import pandas as pd2. Chrome Webdriver 불러오기
def chromeWebdriver():
chrome_service = ChromeService(executable_path=ChromeDriverManager().install())
options = Options()
options.add_experimental_option('detach', True)
options.add_experimental_option('excludeSwitches', ['enable-logging'])
user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.75 Safari/537.36'
options.add_argument(f'user-agent={user_agent}')
driver = webdriver.Chrome(service=chrome_service, options=options)
return driver3. 스크래핑할 스마트스토어 주소(복붙)
url ='https://smartstore.naver.com/danchoo/products/4454697133'
driver = chromeWebdriver()4. 페이지가 로드될 때까지 5초 기다리기
driver.implicitly_wait(5)
driver.get(url)5. 긁어올 리뷰 페이지 수, 리뷰 XPATH 넣어주기
cnt = 1
review = []
for page in range(1, 371//20+3):
time.sleep(2)
lis = driver.find_element(By.XPATH, f'//*[@id="REVIEW"]/div/div[3]/div[2]/ul').find_elements(By.TAG_NAME, 'li')
for li in lis:
review.append(li.text.split('\n')) # '\n'을 기준으로 문자열 나누어서 리스트 각각의 원소로 만들기
cnt += 1
time.sleep(random.uniform(2, 4))
driver.find_element(By.CSS_SELECTOR, '#REVIEW > div > div._180GG7_7yx > div.cv6id6JEkg > div > div > a.fAUKm1ewwo._2Ar8-aEUTq').click()
driver.implicitly_wait(7)
driver.quit()- for page in range(1,
리뷰 페이지 수//20+3): - lis = driver.find_element(By.XPATH,
리뷰가 존재하는 코드의 XPATH).find_elements(By.TAG_NAME, 'li')
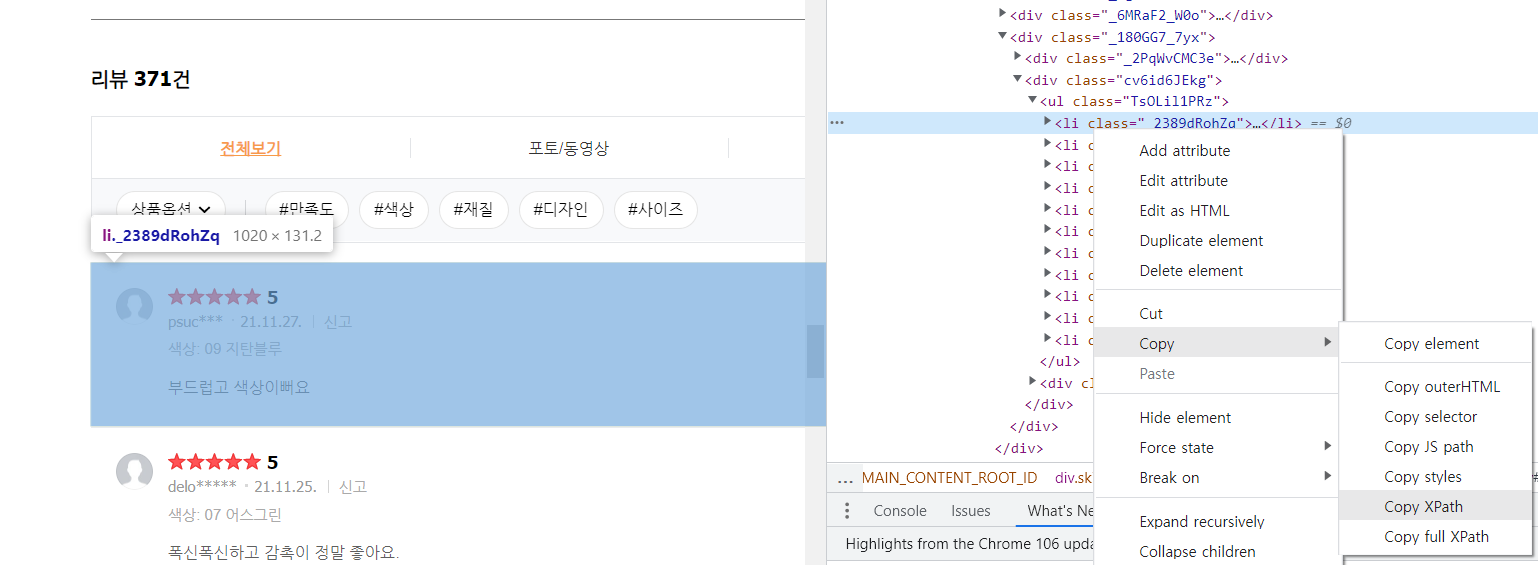
- driver.find_element(By.CSS_SELECTOR,
다음 버튼 코드의 selector).click()
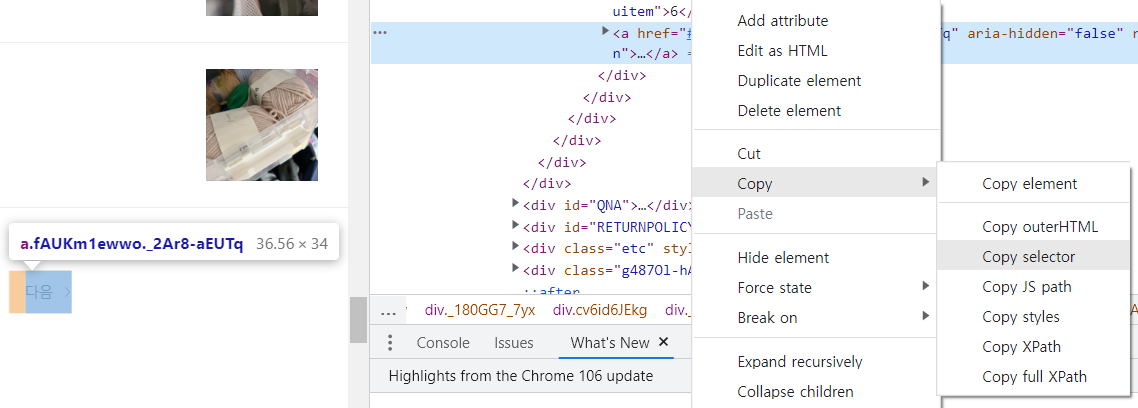
: 기존 구글에 올라온 코드에서 확인된 오류는 '다음'버튼을 XPATH로 긁어와서 리뷰 페이지를 처음 들어가면 위와 같은 index로 나와 '다음'에 부여된 숫자는 8(
리뷰 페이지를 처음 들어가면 위와 같은 index로 나와 '다음'에 부여된 숫자는 8(//*[@id="REVIEW"]/div/div[3]/div[2]/div/div/a[8])인데 '다음'을 누르고 나면
 위와 같이 변경되어 '다음'에 부여된 숫자는 9(
위와 같이 변경되어 '다음'에 부여된 숫자는 9(//[@id="REVIEW"]/div/div[3]/div[2]/div/div/a[9])로 변경이 되어 8이 부여된 리뷰 7페이지가 중복되어 나오는 것을 확인할 수 있습니다.
그래서 '다음' 버튼의 고유 코드가 나올 수 있도록 CSS_Selector로 긁어왔습니다.
6. 스크래핑한 리뷰를 데이터 프레임으로 저장하기
df = pd.DataFrame(review)
df스크래핑 완료!
7. 저장한 데이터 프레임을 .txt 파일로 저장하기
df.to_csv('버터 6 리뷰.txt',sep='\t', index=False)- df.to_csv('
저장할 파일 이름.txt', sep='\t', index=False)
-sep = '\t': tab키가 적용된 부분 기준으로 열을 나눠 줌
-index = False: 인덱스 붙여지면 헷갈릴까봐 붙여주지 않음(붙이고 싶으면 True로 변경)
주의할 점: 첫 페이지의 리뷰 20개가 중복으로 나온다. 그래서 나는 따로 앞 20개의 리뷰만 직접 지워주는 작업을 했다.

데글데글 굴러가는 데린이 일지