
옵시디언에서는 코파일럿 기능을 제공합니다.
옵시디언 내의 설정 페이지에 ChatGPT API key를 입력해두면, GPT 3.5를 불러와서 개인 비서처럼 사용할 수 있는데요.
정신 못차리고 쓰다보면, 요금 폭탄을 맞아버릴까봐 어느 순간부터 해당 기능은 꺼두고 있었습니다.
그런데 최근에 ChatGPT 이외에도 자체 Hosting하는 LLM 서버를 연동할 수 있도록 바뀌었더라고요?
그래서 회사 서버에 Llama3 서버를 띄워두고 옵시디언 코파일럿으로 사용하기로 결정했습니다.
그래서 오늘은 Llama3 로컬서버를 구축하는 방법에 대해 공유드릴까합니다.
대부분의 내용은 유튜버 '테디노트'님의 이 영상에서 참고하였으니 직접 가서 보시는 것도 권장드립니다.
🍀 준비물
- Ollama : LLM 로컬 서버 구축을 위한 오픈소스
로컬 서버 구축에는 Ollama라는 오픈소스를 활용할거에요.
Ollama는 Llama와 같은 LLM 모델 실행 환경을 제공하는 오픈소스에요.
🍀 Ollama로 Llama3 로컬 서버 띄우기
1. 🎈 Ollama 다운로드
먼저 Ollama를 다운로드 해주셔야합니다.
여기서 다운로드하시면 됩니다.
각자 자신의 OS에 맞게 다운로드해주세요.
2. 🎈 Llama3 다운 받기
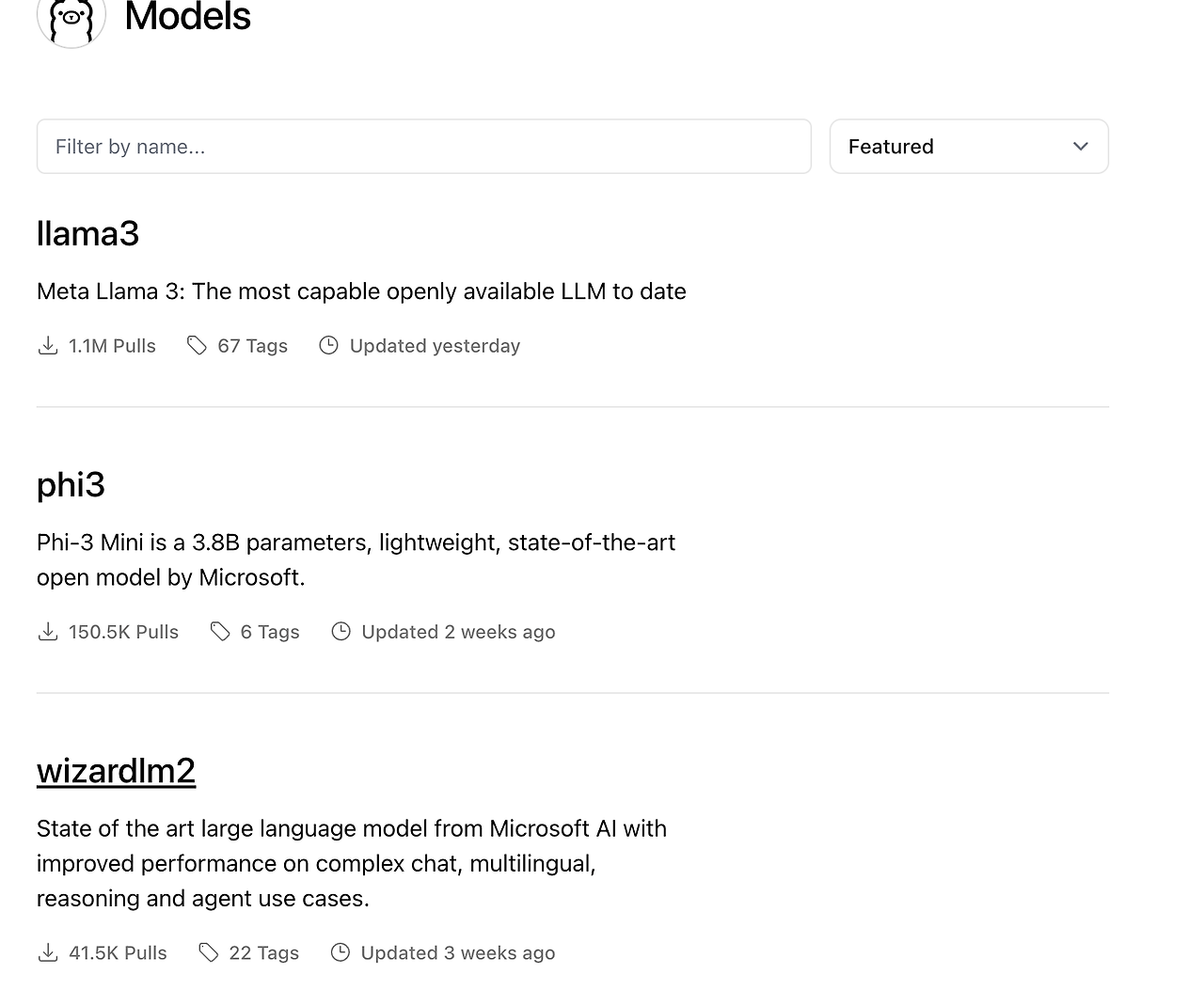
Ollama의 모델 페이지에 보면, Ollama에서 기본적으로 제공하는 모델들을 볼 수 있습니다.
위의 이미지를 보시면, 가장 위에 llama3가 있는거 보이시죠?
오늘은 저 모델을 로컬에 다운 받아 실행할겁니다.
터미널에서 아래의 코드를 실행하면 모델을 다운로드 받을 수 있습니다.
# Llama3 모델 다운로드 받기
ollama pull llama3
# 다운 받은 모델 확인하기
ollama list
ollama list를 실행하면 내가 다운받은 모델들이 출력돼요.
방금 다운로드 받은 llama3 모델이 출력된다면 무사히 다운로드 받은거에요.
참고로 해당 모델은 llama3 8B 모델입니다.
3. 🎈 Llama3 로컬 서버 실행하기
이제 아래의 명령어를 통해 로컬 서버를 실행할 수 있습니다.
# llama3 8B 모델 실행하기
ollama run llama3
# llama3 70B 모델 실행하기
# 추가로 모델 다운로드가 필요할 수도 있음
ollama run llama3:70b
이를 통해 위에서 다운로드 받은 llama3를 실행할 수 있습니다.
그리고 저렇게 바로 ollama를 사용할 수 있는 채팅 인터페이스가 출력됩니다.
저기에 프롬프트를 입력하면은 llama3가 친절하게 답변을 해줍니다.
🍀 마치며
아쉽게도 제가 실습을 진행했던 때에는 Llama3가 한국어를 공식 지원하지는 않았습니다.
그래서 한국인들이 Fine Tuning한 Llama3를 불러와서 사용했었는데요.
시간이 조금 지난 지금은 Llama3에서 오피셜하게 한국어를 지원해주는지는 잘 모르겠네요.
