이미지 분류 task에서 딥러닝은 눈부신 발전을 이룩하였습니다. 그리고 그 이면에는 잘 정립되고 라벨링된 막대한 양의 데이터가 있습니다. 헌데 라벨링 작업은 많은 resource를 요구하기 때문에 실제 산업현장에서 정확히 라벨링된 데이터를 얻기란 쉽지 않습니다. 이에 연구자들은 소수의 labeled 데이터를 이용하여 좋은 분류 성능을 내기 위해 많은 노력을 기울여왔습니다.
그 노력의 일환으로, 최근 unlabeled 데이터를 학습에 함께 사용하면 일반화 성능의 증가와 더불어 학습 성능을 더 높일수 있다는 연구 결과가 나오고 있습니다. 그리고 이러한 방법론을 통틀어 semi-supervised learning이라 명명하였습니다.
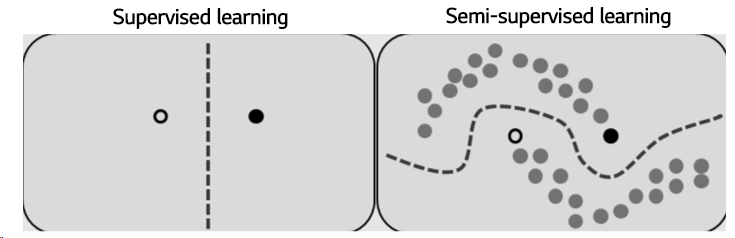
산업 데이터를 분석하는 제 입장에서도, 고객사로부터 깔끔히 정제된 데이터를 얻기가 쉽지 않습니다. 이에 분석을 시작하기 전 여러 데이터 augmentation 기법들을 이용해서 일단 데이터부터 부풀려놓고 분석을 진행해야합니다. 그렇기에 적은양의 labeled 데이터로도 좋은 분류 성능을 보장하는 semi-supervised learning이 이러한 분석에서의 애로사항을 해결해줄 것이라 기대하고 있습니다.
본 글은 2021년 IEEE에 개재된 A survey on Semi-, Self- and Unsupervised Learning for Image Classification 논문을 중심으로, 추가적인 내용들을 덧붙여 정리하였습니다.
Semi-supervised learning의 기본 컨셉
상기 언급했듯, SSL(semi-supervised learning)은 unlabeled data를 활용하여 적은 양의 labeled data 하에서도 좋은 학습 성능을 내는 것입니다. 결국, 학습의 근본은 labeled data에 있습니다. unlabeled data의 주요 목적은 labeled data가 만들어 놓은 decision boundary를 더 정교하고 신뢰성있게 변형시켜주는 것입니다. unlabeled data를 사용함으로써 기존의 supervised learning model과 비교하여 추가적으로 고려해야할 사항이 몇가지 있습니다.
-
어떻게 unlabeled data의 loss를 계산할 것인가?
-
계산된 unsupervised loss를 어떻게 supervised loss와 결합시켜 성능을 향상시킬것인가?
SSL 모델은 unlabeled 된 데이터의 unsupervised loss를 어떻게 측정하고, 학습 과정에 활용하는가에 따라 그 종류가 달라집니다. 각각의 방법론은 독자적인 방식으로 unlabeled data의 loss를 학습과정에서 고려합니다. 그 중 가장 기본적이면서 공통적으로 공유하는 concept을 소개드리고자 합니다.
Consistency Regularization
SSL은 labeled 데이터와 unlabeled 데이터를 함께 사용합니다. labeled data는 supervised learning과 동일하게 모델의 예측값 와 ground-truth 간의 loss를 계산하여 모델을 학습시킵니다. 이때, unlabeled data는 어떻게 사용될 수 있을까요?
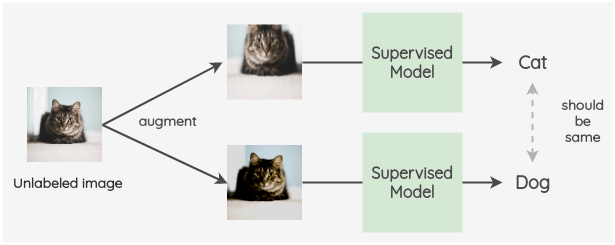
고양이 사진을 crop하거나, 색을 변환시켜도 그 사진은 여전히 고양이 사진입니다. 어떻게 변형을 가하든 간에 고양이 사진이 강아지 사진으로 둔갑할 없죠. consistent training은 이러한 점에서 착안한 방법입니다.
-
하나의 unlabeled 데이터에 여러 변형을 통해 augmented 데이터 생성
-
각 augmented 데이터를 학습 모델에 학습 시켜 augmented 데이터의 라벨 추론
-
의 loss minimize 되도록 학습
이렇게 하나의 이미지로부터 augmented된 이미지간의 간극을 줄이도록 학습시키는 것을 consistent regularization이라고 합니다.
Self-training
딥러닝 학습은 여러 epoch에 걸쳐 진행됩니다. 때로는 완전히 학습이 완료되지 않은 중간 과정에서의 결과가 학습에서 도움을 주기도 합니다. self training은 학습 과정 중간에 발생하는 결과치들을 바탕으로 스스로 학습을 하는 방법론들을 일컫습니다. 여기서는 그중 가장 대표적인 pseudo label에 대해 소개드리겠습니다.
Pseudo-label
신경망을 통과시키면 해당 데이터에 대한 확률값을 출력을 합니다. 비록 학습이 완전히 마무리 되지 않았을지라도 충분한 epoch이 경과되면, 대부분의 데이터는 정확한 라벨로 분류될 수 있습니다. pseudo label은 중간 학습 과정에서의 출력을 label로 지정하여 다시 학습을 진행하는 방법을 일컫습니다.
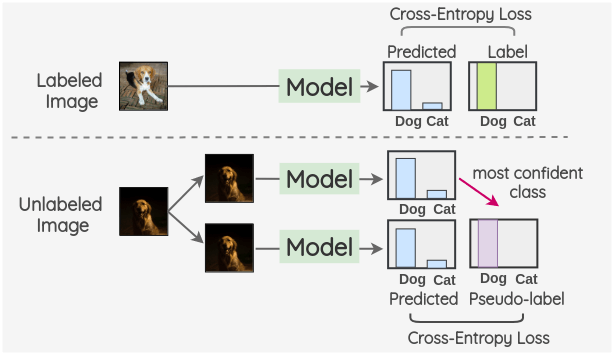
위 이미지의 아래 그림을 보면, 첫번째 모델을 통해서 개와 고양이의 확률 값을 얻은 결과, 개일 확률이 더 높음을 확인하였습니다. 이를 바탕으로 (개, 고양이) → [1, 0]인 pseudo label을 생성하여 다음번 학습에 사용합니다. 그리고 이를 바탕으로 cross entropy를 계산하고 이를 minimize 합니다.
다만, 학습 초기에는 이러한 pseudo label이 정확하지 않아 학습에 혼선을 초래할 수 있습니다. 그러므로 unlabeled loss의 weight term 를 0에 가깝도록 설정하여 초기에는 pseudo label을 거의 참조하지 않도록 합니다. 는 시간이 지날수록 증가하는 ramp-up함수를 사용합니다.
기본적인 SSL 모델들
Consistency Regularization 기반
-model & temporal ensembling
가장 전형적인 consistency regularization 기반의 SSL 알고리즘으로, labeled 데이터의 cross entropy와 unlabeled data의 MSE loss를 조합하여 loss function을 구성합니다.
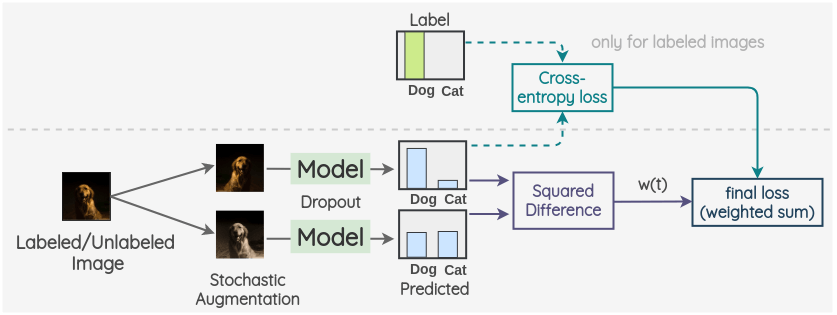
-
타겟 데이터를 random하게 augmentation하여 새로운 이미지 데이터 생성
-
과 를 모델에 입력으로 넣고 각 데이터의 확률 값 획득(이때 모델은 dropout등을 적용하여 변형)
-
출력의 MSE를 consistency error로 설정
-
(labeled 데이터의 경우) 과 ground-truth간의 cross entropy 계산
-
(labeled 데이터의 경우) 4의 supervised loss와 3의 unsupervised loss의 weighted sum을 minimize
이미지 데이터의 여러 augmentation을 생성 후 증강된 데이터 간의 consistency error를 구한다는 점에서 consistency regularization 방법을 차용하고 있음을 알 수 있습니다. 파이모델의 차별점은 과 ground truth 간의 loss를 구해 최종 Loss function에 추가해준다는 점입니다.
만약 이미지가 unlabeled인 경우, cross entropy 계산은 하지않고 consistency error만을 최소화 하도록학습을 진행합니다.
또한 가중치 를 사용하여, 학습 과정에서 supervised cross entropy loss와 consistency error의 비중을 조정할 수 있습니다.
파이모델의 변형 모델로 temporal ensembling이 있습니다. 전체적으론 파이모델과 동일하나 augmented data 의 consistency loss를 구하는 것이 아닌, 과 과거의 예측치를 가지고 consistency error를 구합니다. 이때 과거의 학습 결과는 이전 epoch에서 얻어진 return들의 Exponential Moving Average를 사용합니다.
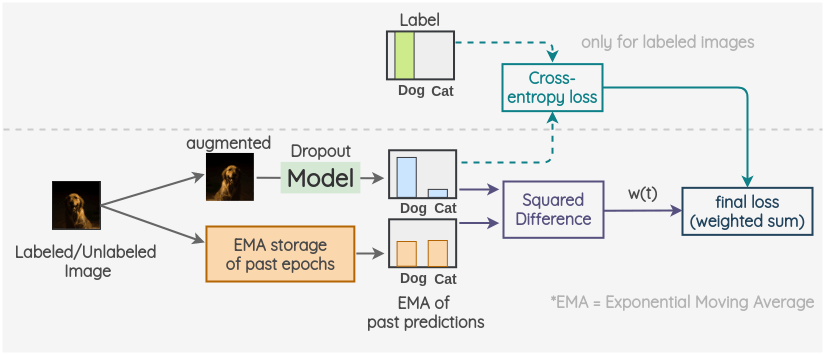
실험 결과, 파이 모델보다 temporal ensembling 모델이 최대 2배 더 빠르고 안정적인 추론 결과를 보여줌이 확인되었다고 합니다.
Mean Teacher
mean teacher는 앞서 언급한 temporal ensembling 모델과 매우 유사합니다. 기존의 temporal ensembling 모델은 결과의 EMA를 계산하기 위해 매 epoch 마다 결과를 intergrate 해주어야합니다. 헌데 결과를 ensemble하는 기존 모델은 epoch마다 1번의 계산만을 수행하기 때문에 intergrating 속도가 매우 느립니다. 이는 모델의 학습 속도를 저하시키는 요인입니다. 이에 mean teacher는 과거 학습의 ‘결과'의 EMA를 사용하는 것이 아닌, ‘parameter’의 EMA를 사용한다는 차이점이 있습니다.
mean teacher는 teacher와 student 2개의 모델을 가집니다. 두 모델의 아키텍처는 동일하나 student 모델은 자체적으로 모델을 학습하는 반면, teacher model은 student모델의 parameter의 EMA를 Parameter로 사용합니다.
이후는 동일하게 student model이 augmented data 의 prediction을 구하고, teacher model이 augmented data 의 prediction을 구합니다.
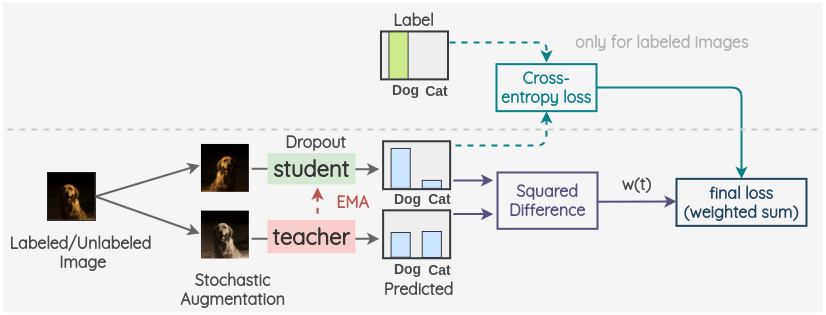
mean teacher나 여기선 언급하지 않은 VAT의 경우 여전히 여러 bechmark 데이터에서 좋은 퍼포먼스를 보이고 있습니다.
Self training 기반
Noise student
Noise student는 pseudo label의 아이디어를 확장한 방법으로, pseudo label을 생성하는 모델(teacher)과 이를 적용하여 재학습하는 모델(student)을 따로 구분합니다.
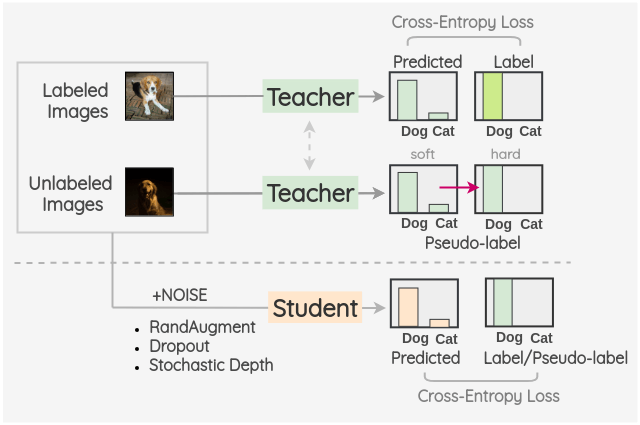
- teacher 모델을 이용하여 unlabeled image의 pseudo label을 생성
- 여러 augmentation 기법을 적용해 augmented unlabeled data를 생성하고 pseudo label을 할당
- student model을 사용하여 augmented unlabeled 이미지에 대해 학습
data augmentation과 pseudo labeling 개념을 사용한 모델입니다. 이때 student model은 teacher model을 기본으로 하지만, dropout이나 stochasitc depth와 같은 여러 변형을 가하므로 teacher model과는 다른 모델이 구성됩니다.
정리
여러 semi supervised learning model들에 대한 기본적인 개념과 대표적인 모델들에 대해 알아보았습니다. SSL은 현재도 활발히 연구되고 있는 분야로, 단순히 ‘적은 label로도 좋은 성능을 낸다.’ 가 아닌, ‘지도학습보다 더 좋은 성능을 보이는 준지도학습 모델을 만든다.’라는 목표를 가지고 조금씩 발전해나가고 있습니다.
실제로, 2022년 상반기 기준 SOTA를 달성하고 있는 SimCLRv2의 경우, ImageNet 데이터에 대해 95%의 accuracy를 보이며 정말로 supervised learning을 넘는 모델이 나오지 않을까 괜히 기대하게 됩니다.
참고문헌
- Schmarje, L., Santarossa, M., Schröder, S. M., & Koch, R. (2021). A survey on semi-, self-and unsupervised learning for image classification. IEEE Access, 9, 82146-82168.
- Amit Chaudhary, Semi-Supervised Learning in Computer VIsion, https://amitness.com/2020/07/semi-supervised-learning/

인조님 오랜만이에요 블로그 잘 읽었습니다~ ! 항상 건승하세요~