public void race() {
cars.stream()
.filter(car -> isMovable())
.forEach(Car::move);
}함수형 프로그래밍이 항상 옳진 않습니다. 때로는 전통적인 for loop가 더 좋기도 하죠.
이 글을 한 번 읽어볼까요?
스트림은 자바 8부터 도입된걸로 당연히 더 좋은 것이라고 생각했다. 그래서 아직 사용이 자연스럽지 않음에도 연습할 필요성을 느꼈었다. 하지만 리뷰어님의 말에 흥미를 느끼고 블로그들을 읽었다.
스트림이란?
컬렉션 내부에서 요소들을 반복시키고 개발자는 요소당 처리해야할 코드만 제공하는 코드 패턴
스트림을 반환한다는 것은 연산의 파이프라인(pipeline)을 반환한다는 의미이다. 스트림은 lazy한데, 매번 중간 연산마다 조건을 실행하지 않는다. 대신, 중간 연산마다 연산의 파이프라인을 리턴한다. 최종 연산 과정에 들어와서야 이전 중간 연산들을 모두 합친 후에야 이를 이용해서 최종 연산에 돌입한다.
성능
primitive type

원시 데이터를 반복문으로 처리할 때는 절대적으로 for-loop이 유리하다. (Collections 보다는 배열의 경우가 특히 그렇다)
왜 그럴까?
Langer씨는 JIT Compiler가 for-loop을 워낙 40년 이상 다뤄왔다 보니까 for-loop에 대한 internal optimization이 이미 잘 되어 있다고 말한다. 하지만 스트림은 2015년 이후에 도입되었으므로 아직 컴파일러가 최적화를 제대로 하지 못했다는 것이다.
wrapped type

차이가 눈에 띄게 줄었음을 확인할 수 있다. ArrayList를 순회하는 비용 자체가 워낙 크기 때문에, for-loop와 stream 간의 성능 차이를 압도해버리는 것이다. ArrayList에서 모든 원소를 순회하는 데 걸리는 시간 복잡도는 O(n)이다. wrapped type은 primitive type과 달리 stack이 아닌 heap 메모리 영역에 저장된다.
JVM 상에서 Heap Memory에 저장되는 간접 참조는 힙에 객체의 내용이 있다면 중간에 그곳을 가리키는 메모리 영역이 있고(핸들 메모리) 스택에 있는 변수가 핸들 메모리를 참조해서 실제 힙의 주소를 얻은 후 힙의 실제 내용을 참조하게 되는 방식이다. 반면, JVM 상에서 Stack Memory에 저장되는 직접 참조의 경우 스택에 있는 변수가 힙 메모리의 실제 주소를 가지고 있어 직접 참조 하게 되는 방식이다. 그러므로 자주 참조되는 변수나 객체가 있다면 직접 참조 방식이 훨씬 뛰어난 성능을 보인다.
즉, int와 같은 primitive type은 stack에 저장되어 JVM 상에서 직접 참조로 값을 바로 불러올 수 있지만, wrapped type은 heap에 저장되어 간접적으로 주소를 가져와 값을 참조해야 한다. 간접 참조하는 비용이 직접 참조하는 비용보다 훨씬 비싸기 때문에, iteration cost 자체가 높다는 뜻이고 결국 for-loop의 컴파일러 최적화 이점이 사라진다는 것이다.
지금까지 우리가 살펴본 예제는 순회비용(cost of iteration)이 계산비용(cost of functionality)보다 높은 것이었다. 만약 원소를 단순히 순회하는 비용보다 원소 하나하나에 대한 계산비용이 훨씬 높다면 어떨까?
expensive functionality

더 이상 for-loop이 빠르지 않다! slowSin() 함수 계산 비용이 순회 비용을 압도하는 것이다. 이를 통하여 우리는 함수 내부의 시간 복잡도가 충분히 크다면, stream을 사용하는 것이 for-loop에 대비하여 속도 손실이 없을 것임을 확인할 수 있다. Langer씨도 iteration cost와 functionality cost의 합이 충분히 클 때, 순차 스트림의 속도는 for-loop와 가까워진다라고 말한다.
순차 스트림 vs 병렬 스트림
순차 스트림은 하나의 쓰레드에서 모든 반복(Iteratior)을 수행하는 것을 의미한다. 순차 스트림은 싱글 스레드를 사용하기 때문에 CPU 코어 자원을 마음껏 활용하지 못하는 대신, 공유 자원 이슈를 고민할 필요가 없다.
병렬 스트림은 여러 개의 쓰레드에서 반복을 나누어 수행하는 것이다. 멀티 쓰레드이므로 공유자원 동기화 문제가 발생한다. 만약 mutate state가 있는 객체가 있다면, 각 코어 별로 할당된 쓰레드가 동일한 메모리 영역에 접근하여 값을 서로 바꾸려고 할 것이다.

Java 8에서는 병렬 스트림을 위하여 parallelStream() API를 제공한다. 스트림에 .parallel()을 붙여주면, 병렬 스트림을 사용하겠다는 선언이 된다. parallel()은 fork-join framework를 바탕으로 하나의 쓰레드를 재귀적으로 특정 depth까지 반복하며 여러 개의 쓰레드로 잘게 나눈 뒤, 자식 쓰레드의 결과값을 취합하여 최종 쓰레드의 결과값을 만들어 리턴하는 방식으로 구현되었다.
병렬 쓰레드는 분명 순차 쓰레드보다 오버헤드 비용이 더욱 발생한다. fork-join task object를 만들고, job을 split하고, thread pool 스케줄링을 관리하고, common pool을 사용하여 오브젝트를 재사용하는 만큼 쓰지 않는 오브젝트를 정리하는 Garbage Collector 비용도 발생할 것이다. 이러한 오버헤드 비용을 감수하더라도 병렬 스트림을 쓰는 것이 우위에 있을 때 parallelStream을 사용해야 할 것이다.
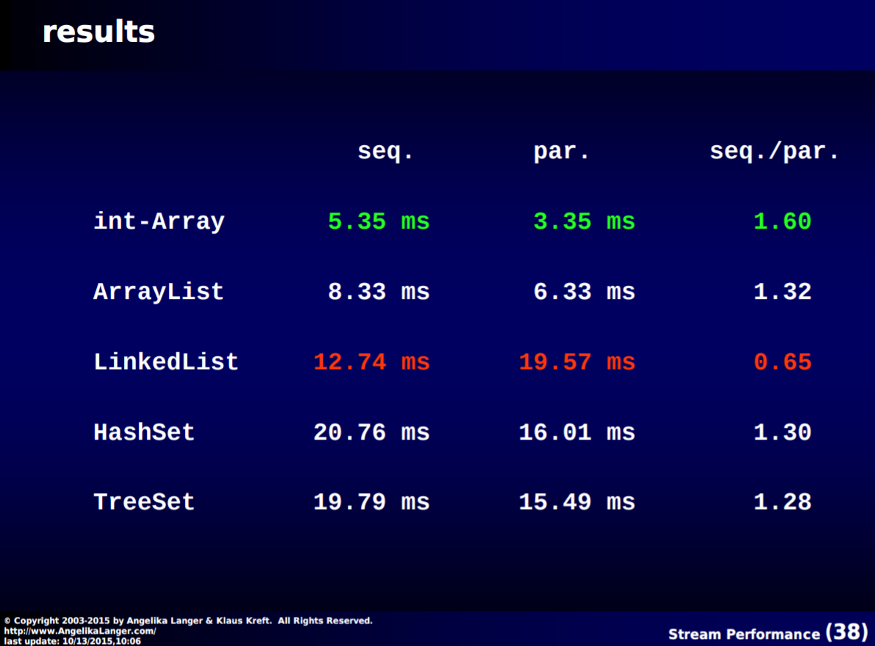
병렬 스트림이 순차 스트림보다 빨랐지만, 그 차이가 드라마틱하지 않다. 그 이유는 이전에서 보았듯이 계산 비용이 작아서 쓰레드를 나누는 비용이 훨씬 비싸기 때문이다. 심지어 LinkedList를 사용한 경우에는 병렬 스트림이 오히려 느렸다. 그 이유는 무엇일까? LinkedList는 job을 split하기 어렵기 때문이다. 약 50만번 iterator를 사용해서 next()를 하며 값을 일일이 참조해야 하는데 순회 비용이 비싼 것이다. 이와 달리 ArrayList는 index를 통해 List 값에 접근할 수 있다. 아무튼 이번 예시 역시 computing cost가 크지 않은 연산이었다.

렬 스트림이 순차 스트림이 1.8배 정도 빨랐다. 벤치마크 환경이 CPU 듀얼코어 임을 생각하면 2배 정도 빨라야 하는데, 0.2배 차이가 나는 이유는 병렬 알고리즘의 오버헤드 비용이나 Amdahl’s Law에서 말하듯 병렬 스트림이 속도를 높일 수 있는 한계점이 있거나 하기 때문일 것이다.
가독성
속도도 중요한 이슈이지만, 가독성과 유지보수의 용이도 중요한 이슈이다. 상황에 따라 개발자가 어떠한 방식을 취할 것인가를 종합적으로 고려해 판단할 필요가 있어보인다.
결론
결론
오늘의 결론이다. 스트림 사용이 for-loop보다 의미가 있으려면 Collection이 되는 스트림 소스의 크기가 충분히 크거나, 컴퓨팅 연산이 CPU-intensive할 정도로 비용이 매우 비싸야 한다. 병렬 스트림을 사용하려면, 스트림 소스인 Collection은 split하기 쉬운 자료 구조이어야 하며, 웬만해서는 연산이 stateful하지 않아야 한다.
사실 stream에 익숙하지 않은데도 최근 것이니 당연히 더 좋겠지라고 생각을 했습니다. 참조해주신 글을 보니 신기했습니다. 그럼 실무에서는 스트림은 잘 사용하지 않는편인가요?
스타일마다 다르겠지만 많이 쓰입니다.
하지만 제 경험상 stream().forEach()문은 자주 사용되지 않는 것 같아요 😄

혹시 스트림 성능 테스트 도구 이름이 뭔지 알 수 있을까요..?