File and File System

reposition (lseek): 파일을 한번 읽고나면 다음 포인터부터 읽는데, 그 파일의 다른 부분부터 읽으려할 때 위치를 수정해주는 reposition 연산을 한다.
파일의 metadata를 메모리에 올려놓는 것을 open이라 한다.
Directory and Logical Disk

디스크는 메타데이터 중 일부를 보관하는 파일이다.
디스크는 물리적인 디스크가 있고 논리적인 디스크가 있는데, 운영체제가 보는 것은 논리적인 디스크이다.
open()
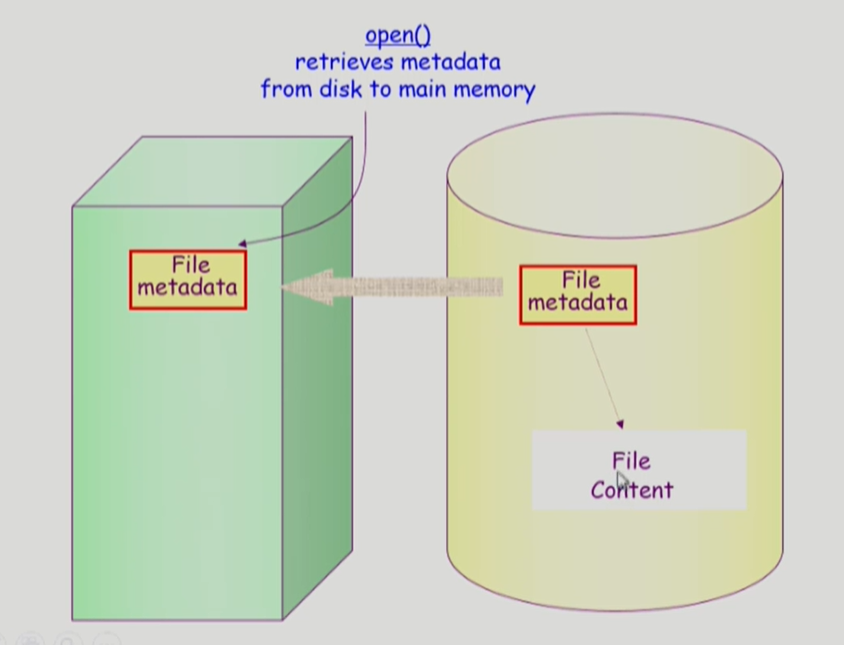
metadata에는 저장 위치도 포함되어 있다.

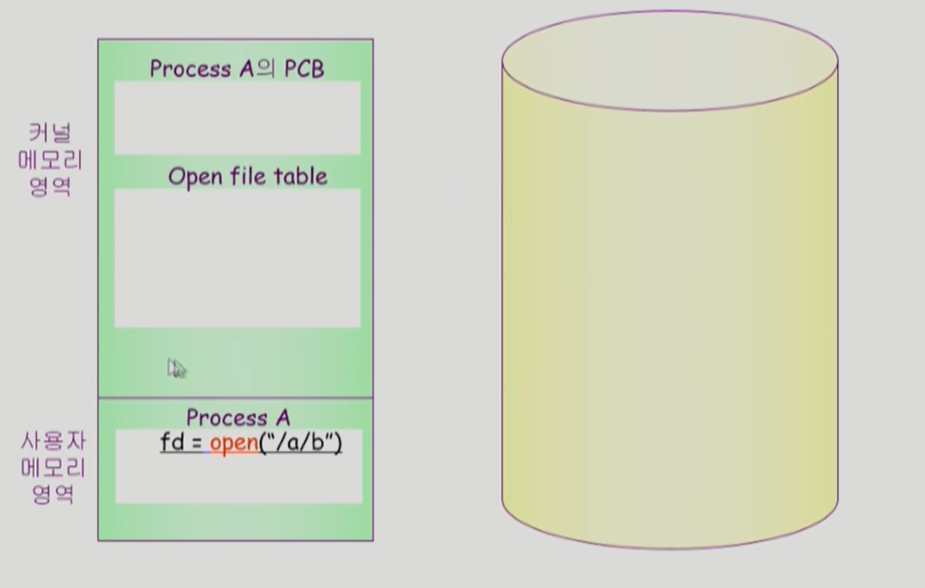
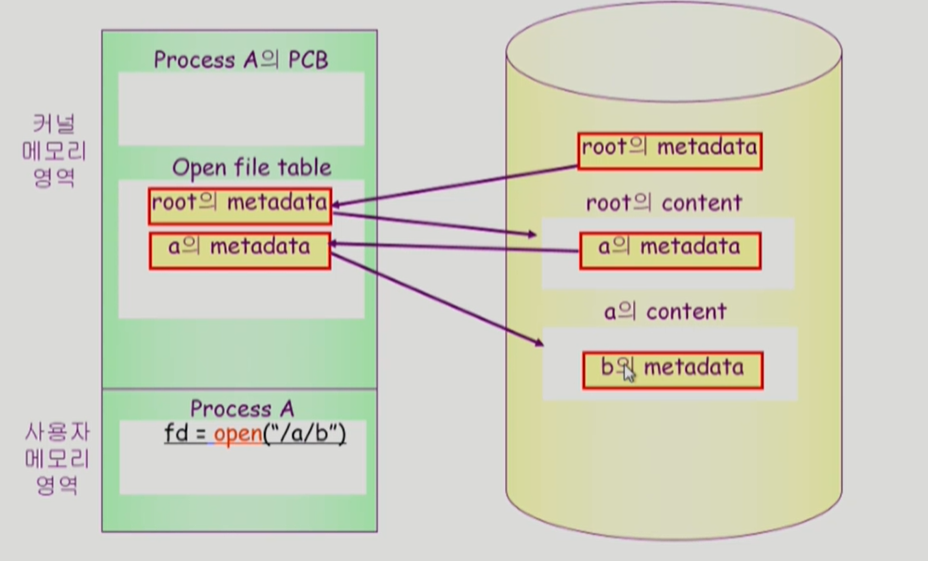

사용자 프로그램이 시스템 콜을 하면 cpu가 운영체제에게 넘어간다. 운영체제에는 루트 디렉토리의 메타데이러를 알고 있기 때문에 메모리에 올린다. 그걸로 root의 content 를 알고 a의 metada를 알게 돼서 메모리에 올리고... 재귀적 반복.
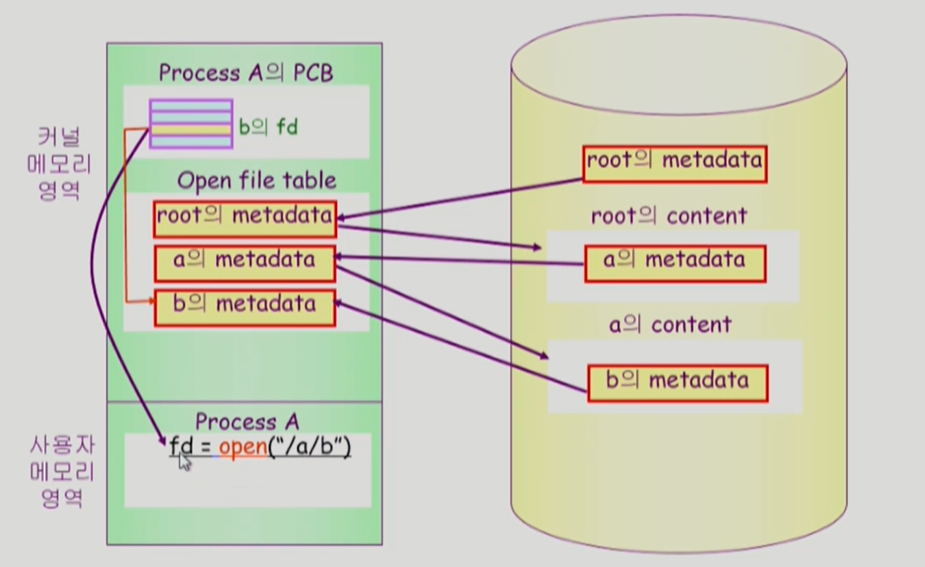
각 프로세스마다 각 프로세스가 오픈한 메타데이터의 포인터를 가지고 있는 배열 같은 것들이 있다. 그 배열에서 몇번째 인덱스냐가 그 팡리의 descriptor가 된다.
b의 metadata를 얽고 사용자에게 바로 전달하는 것이 아닌, copy해서 운영체제가 가지고 있고 준다. 이렇게 하는 이유는 다른 프로그램이 동일한 요청을 하면 바로 줄 수 있기 때문이다. 일종의 버퍼 캐쉬이다. 여기에서는 운영체제에게 넘어가있으므로 clock algorithm이 아닌 lru를 쓸 수 있다.
여러 프로그램이 하나의 파일에 접근하고 있을 때, 각 프로그램이 어느 위치에 접근하고 있는지 offset을 관리해야한다.
File Protection

일반적인 운영체제에서는 grouping을 쓰고 있다.
File System의 Mounting
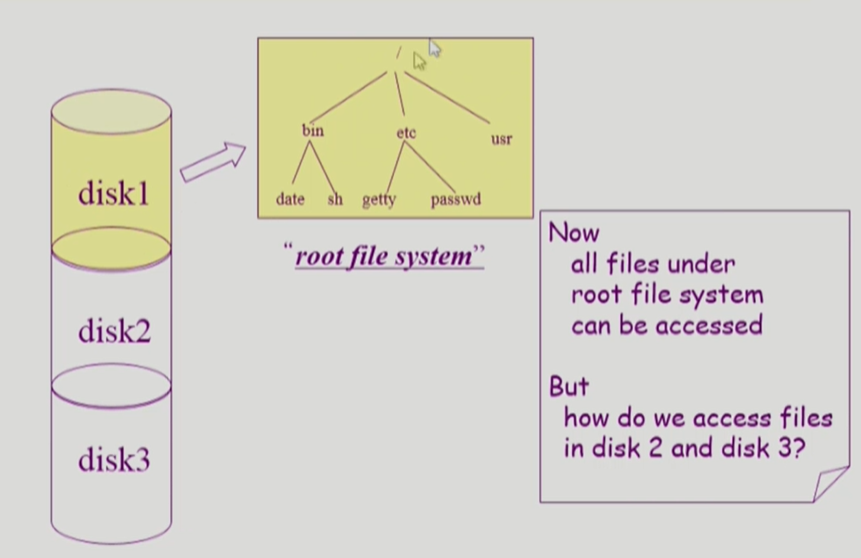
만약 루트 파일 시스템이 다른 파티션에 설치되어있는 파일에 접근해야 한다면 mounting을 해야 한다.
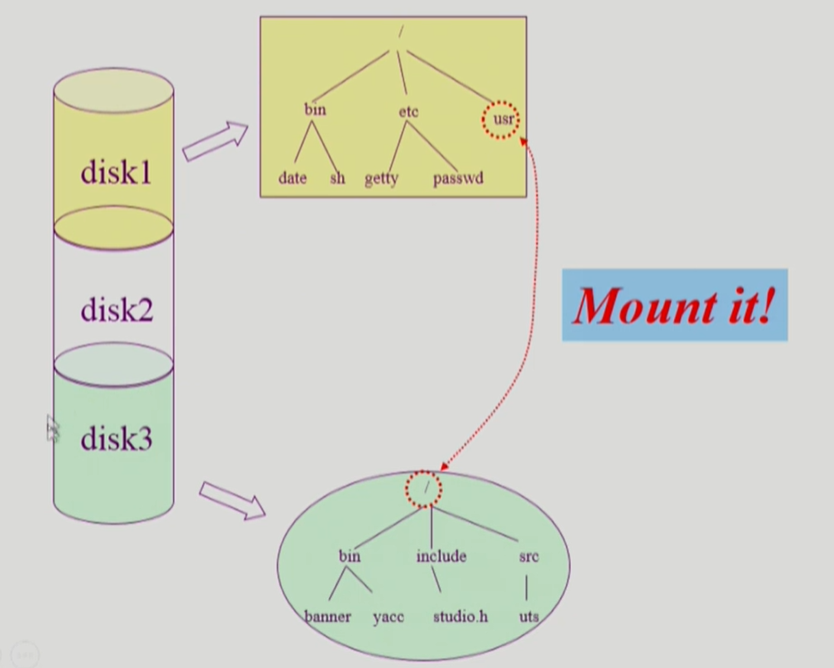
서로 다른 파티션에 있는 파일에 접근하는 것이다.
Access Methods

Allocation of File Data in Disk

Contiguous Allocaiton
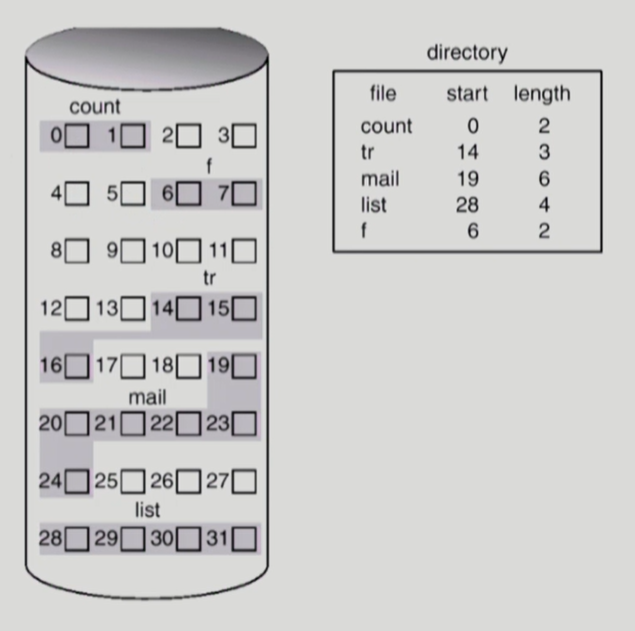
디렉토리는 메타데이터를 가지고 있다.
이런 방식에서 단점은 외부조각이 발생한다는 점이다. 즉 파일이 길이가 3이면 17, 18이 free block이어도 들어가지 못한다. 또한 파일의 크기를 키우는데도 제한이 있다. 미리 너무 크게 잡으면 내부조각이 발생한다.
장점은 빠른 IO다. 하드디스크에서 대부분의 시간은 헤드가 이동하는데에서 발생한다. direct access가 가능하다는 것은 크기를 아니 인덱스로 접근이 가능하다는 것이다.

Linked Allocation
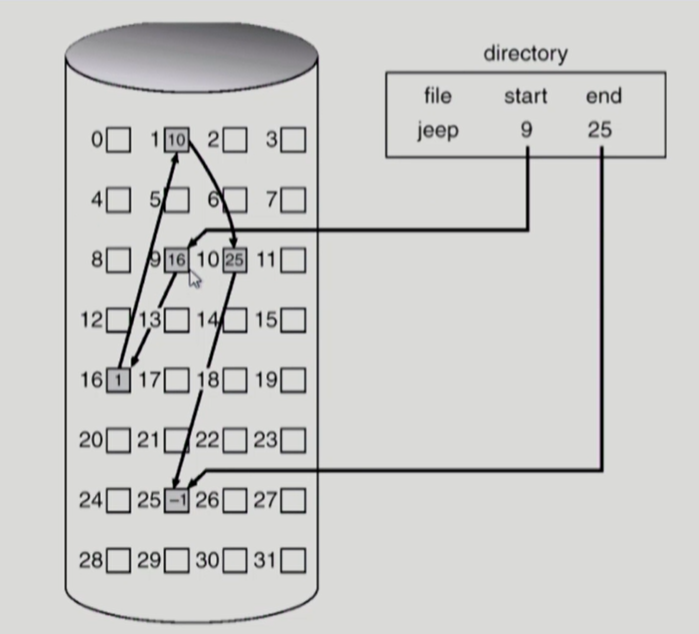

FAT 파일 시스템은 포인터를 별도의 위치에 보관한 것이다.
Indexed Allocation
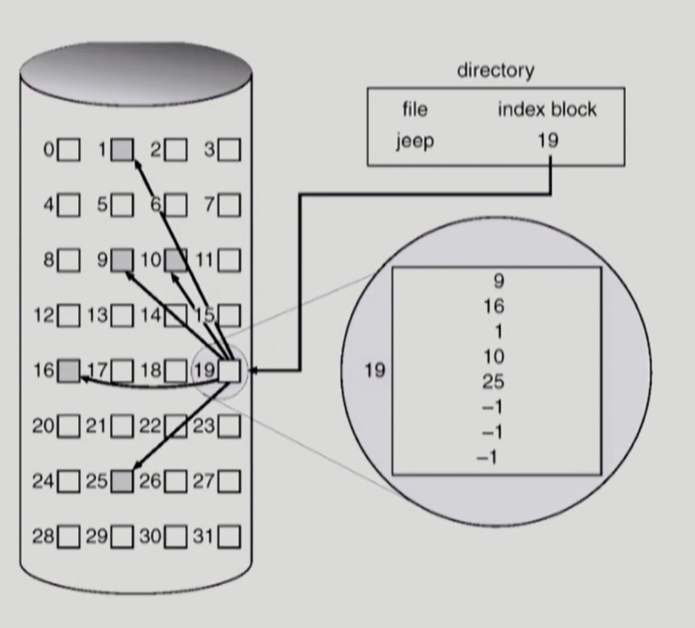
파일이 어디 어디에 나눠져있는지 인덱스 블록에다가 적어두는 것이다.
인덱스 블록만 보면 direct access가 가능하다. 중간 중간 hole이 생기는 문제도 해결 가능하다.

UNIX 파일시스템의 구조
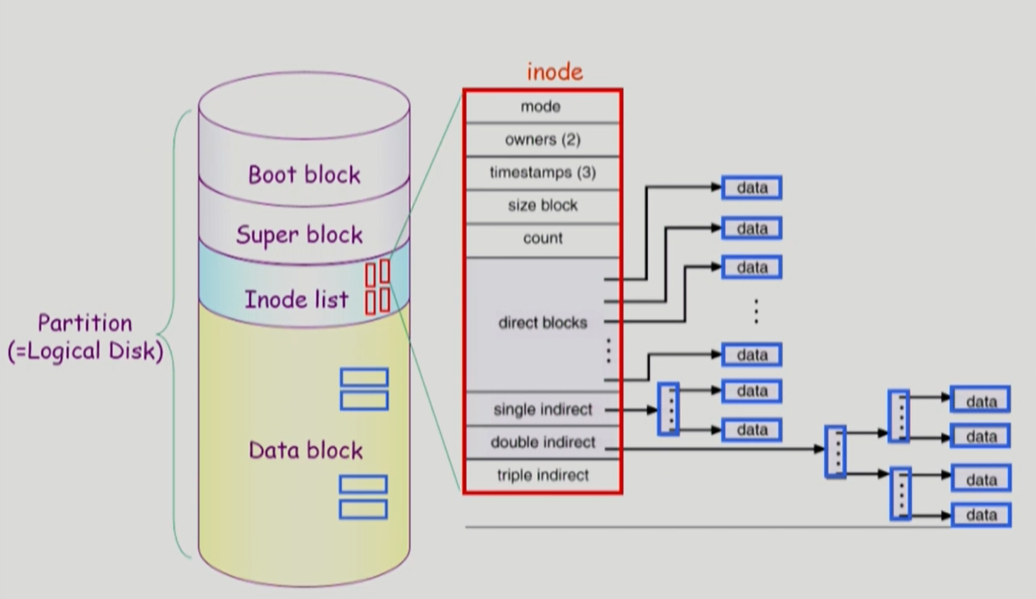
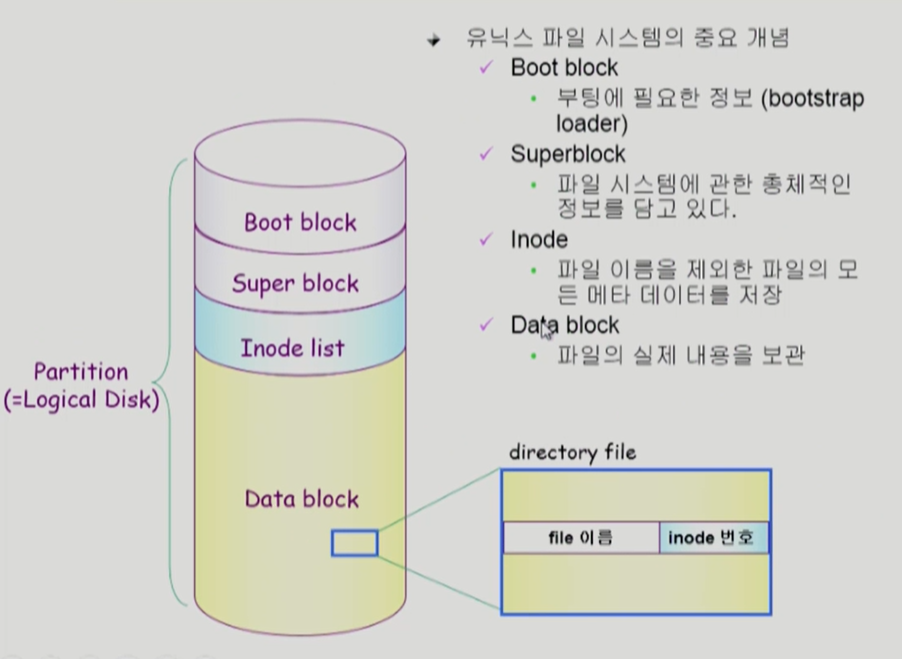
컴퓨터의 모든 파일시스템은 항상 0번 블록은 boot block이다. 부팅하기 위해 필요한 기본 정보이다.
디렉토리는 메타데이터의 일부분만 가지고 있고, 메타 데이터의 대부분은 inode에 저장된다. 파일의 이름은 directory가 가지고 있다. 나머지 메타 정보는 inode 번호를 가지고 있다.
UNIX 시스템은 indexed allocation을 변형해서 쓰고 있다. 파일의 크기가 작으면 direct blocks에 ... 아주 크면 triple indrect에 저장한다.
FAT File System
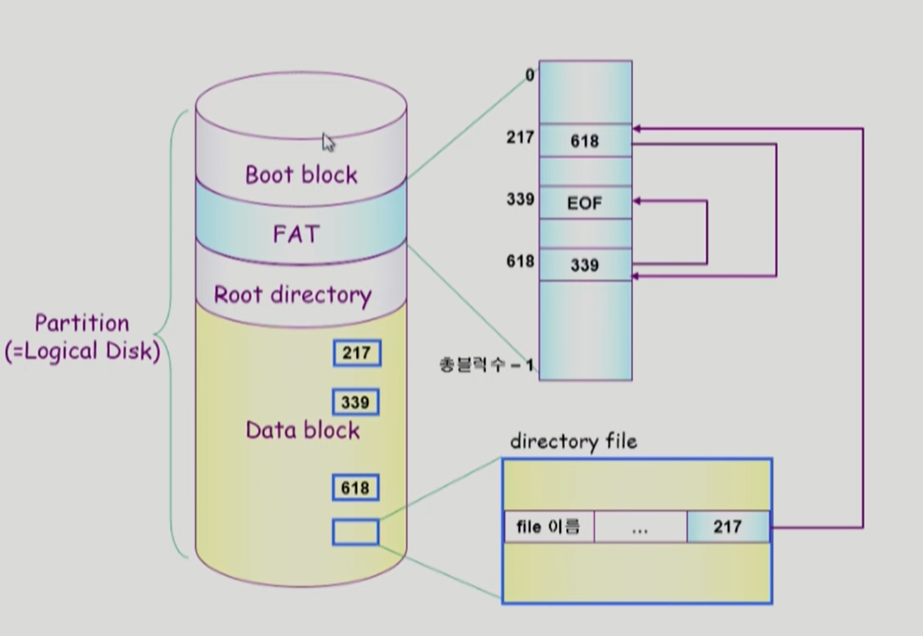
여기서도 0번 블록은 boot block이라는 것을 알 수 있다. FAT 파일 시스템은 윈도우즈 계열에서 사용된다.
파일의 메타데이터의 일부(위치 정보)를 FAT에 저장한다. 나머지 정보는 디렉토리에 가지고 있다(파일 이름, 접근권한, 소유주, 첫번째 위치..).
217번이 여기서 첫번째 블럭인데, 다음 블럭의 위치를 FAT에 별도로 관리한다. FAT 테이블 전체를 메모리에 올려놓으므로, linked allocation의 단점을 전부 극복했다. FAT은 중요한 정보이기에 두 카피 이상을 저장하고 있다.
Free-Space Management
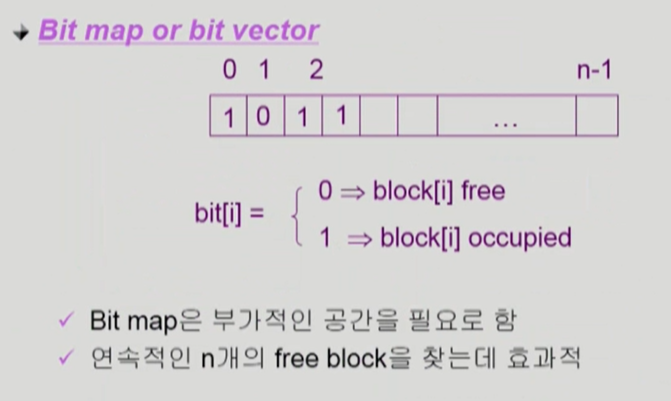
각각의 블록에 번호를 메기고 사용중인지 아닌지를 구분하는 것이다. UNIX 파일 시스템의 경우 super block에 정보를 저장한다.
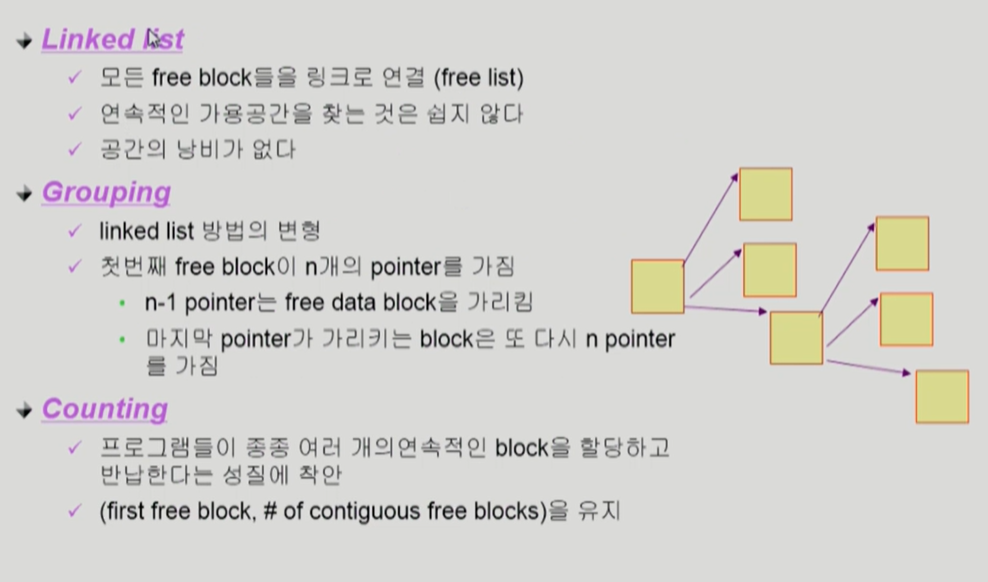
linked list나 grouping 모두 연속적인 빈 공간을 찾기에 효율적이지 않다. counting은 연속적인 블록을 찾는데 효율적이다. 첫번째 빈블록과, 그 뒤 몇개가 연속적인지를 유지한다.
Directory Implementation

파일 이름과 메타 데이터 크기를 고정한 것이다.

파일이름이 길어지면 따로 빼서 저장을 한다.
VFS and NFS

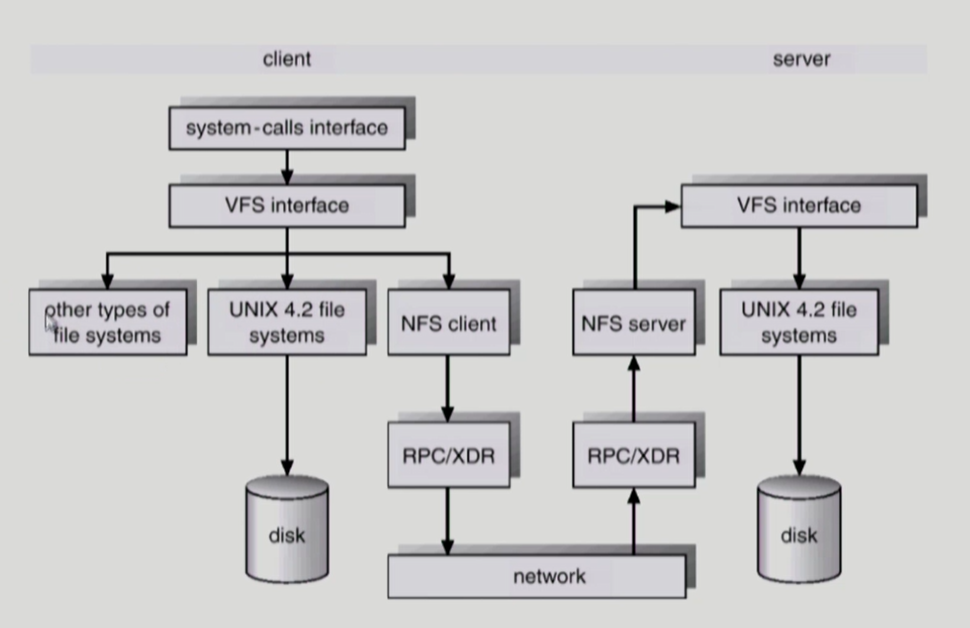
어떤 파일 시스템을 쓰든 상관 없이 VFS interface를 사용한다.
분산 시스템에서는 네트워크를 통해 파일을 공유하는데 NFS client와 NFS server가 이용된다.
Page Cache and Buffer Cache
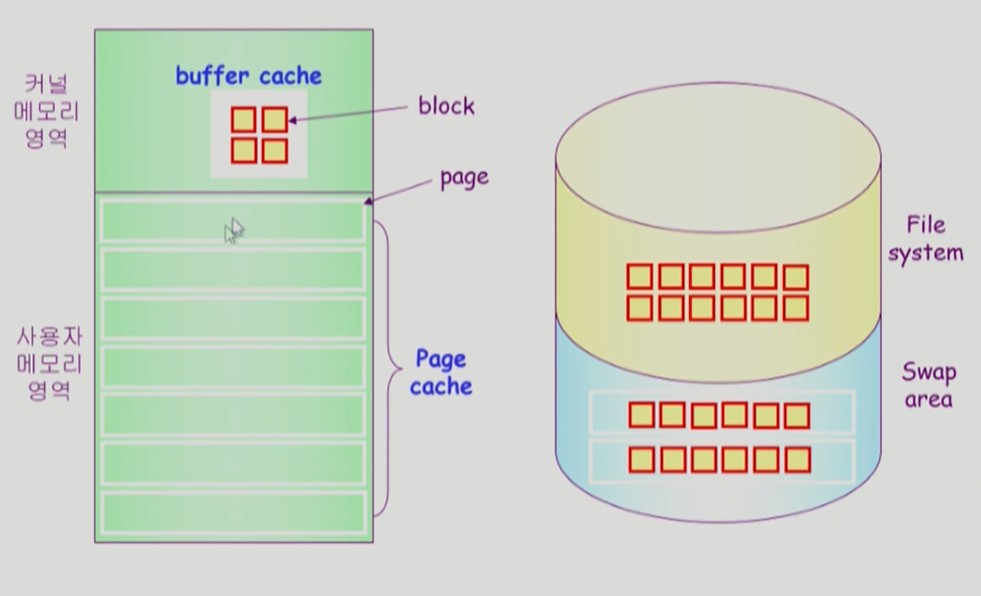
여기서는 상대적으로 빠른 영역을 캐쉬라하는데, 메모리는 디스크의 swap area보다 빠르므로 page cache라고 적혀있다.
운영체제는 요청한 파일을 우선 buffer cache에 저장해놓고 복사해서 준다. 다음에 똑같은 요청이 오면 buffer cache에서 바로 꺼내 준다.

page cache에는 lru를 쓸 수 없는 이유가, 올려 놓고나면 사용자 프로그램이 운영체제를 거치지 않고 직접 접근한다. 따라서 메모리에 올라온 이후에 마지막으로 사용된 시간을 모른다. 그래서 hardware의 도움을 받아 clock algorithm을 사용한다.
file system의 buffer cache는 운영체제는 사용자한테 시스템콜을 받기 때문에 사용시점을 알 수 있다.
최근 운영체제는 unified buffer cache로 통합을 했다. 리눅스가 대표적이다.
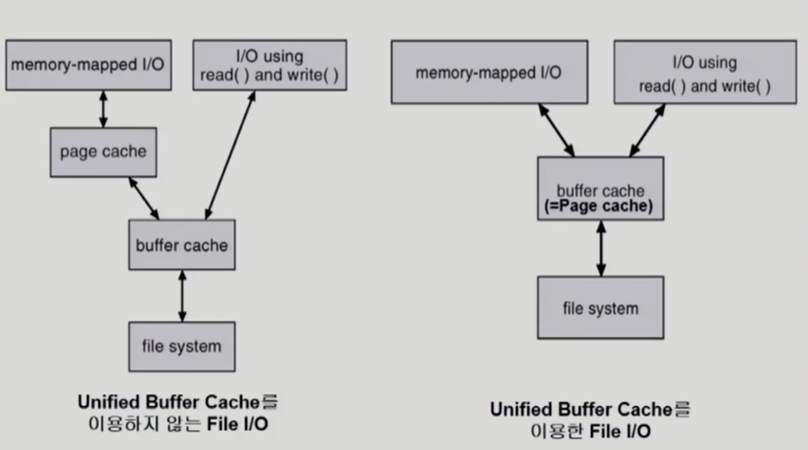
Unified Buffer Cache를 사용하면 바로 page cache에 매핑하는 것이다.
프로그램의 실행
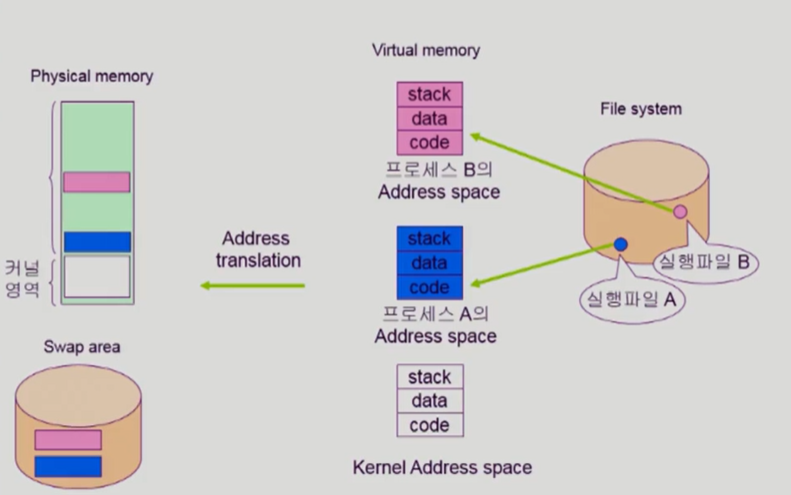
프로그램이 실행되면 실행파일이 스왑 메모리를 거쳐서 프로세스만의 독자적인 주소 공간이 만들어진다. 이 공간은 코드, 데이터, 스택으로 구분되며 당장 사용될 부분은 물리적 메모리에 올라가고 당장 사용안되는 부분은 swap area에 내려간다. 코드 부분은 이미 파일 시스템에 있기 때문에 swap area에 내리지 않고 필요없으면 그냥 지운다. 필요하면 file system에서 가져오면 된다.
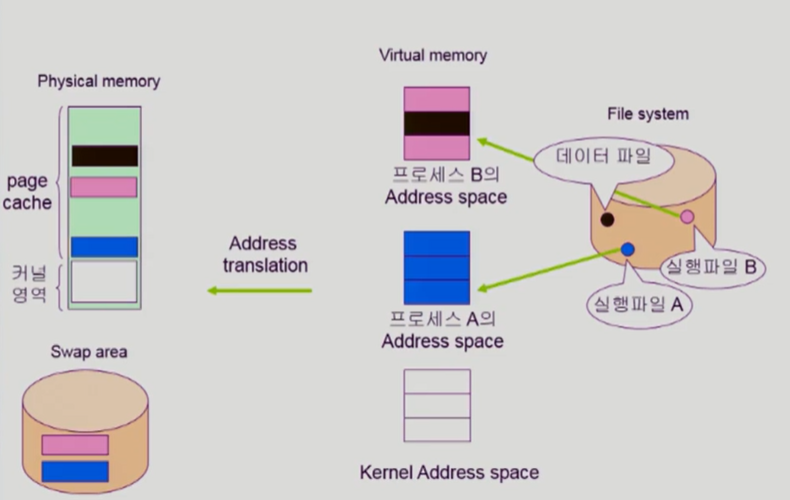
memory mapped I/O에 대해 정리할 것
