Cache Stampede란?

조회가 빈번하게 발생하는 서비스의 경우 캐시를 이용해서, DB를 직접 조회하는 쿼리 개수를 최소화하고 DB 부하를 줄인다. 하지만 우연의 일치로 한참 트래픽이 높은 시간에 캐시가 만료되어있다면 어떻게 될까?
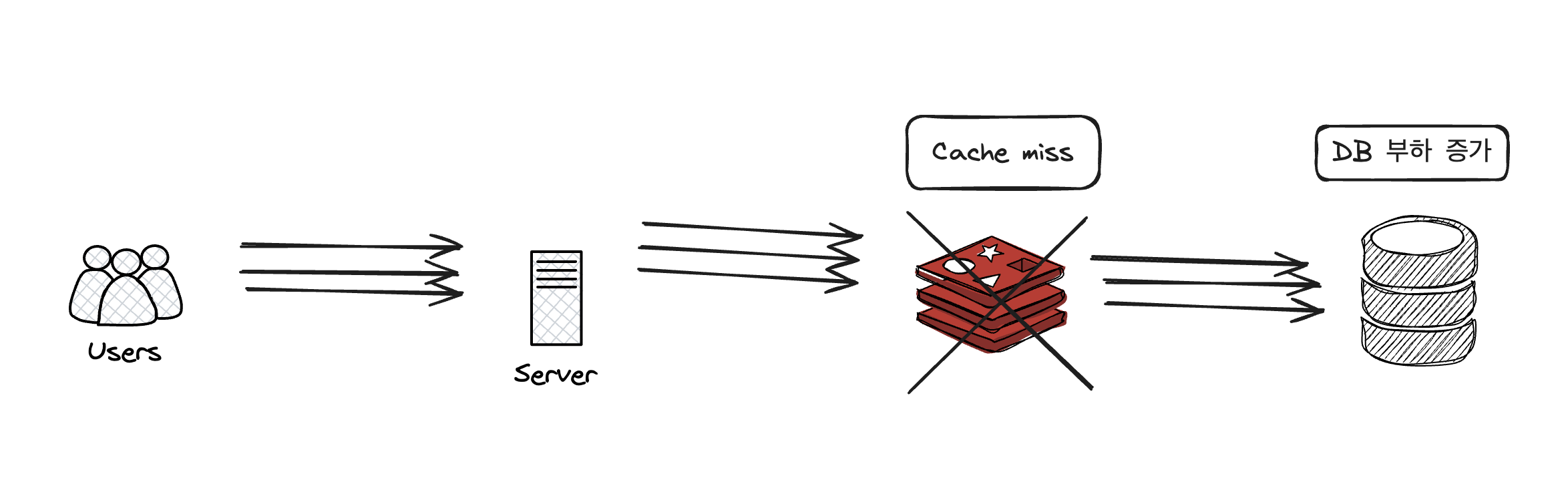
트래픽이 많지 않다면 캐시 미스가 났을 경우 하나의 요청이 db를 조회한 다음, 그 다음 요청들은 캐시 히트를 하게된다. 하지만 트래픽이 정말 많은 경우 캐시 미스가 난 찰나의 순간, 많은 요청들이 db에 쿼리를 보내게되고 부하를 준다. 이에 따라 몇몇 요청들은 timeout exception을 맞을 수도 있다. Cache stampede는 이렇게 여러 클라이언트가 캐시 히트를 하지 못해 캐시 항목을 재계산하려고 할 때 발생하는 현상이다.
증권 도메인에서는 장이 열리는 시간에 트래픽이 한꺼번에 몰려서 쏟아져 들어온다. 특히 삼성전자, 엔비디아, 마이크로소프트 같은 hotkey들은 만약 트래픽이 몰릴 때 캐시 미스가 난다면 많은 유저들이 중요한 순간에 안좋은 경험을 하게 될 것이다.
해결책
1. Lock
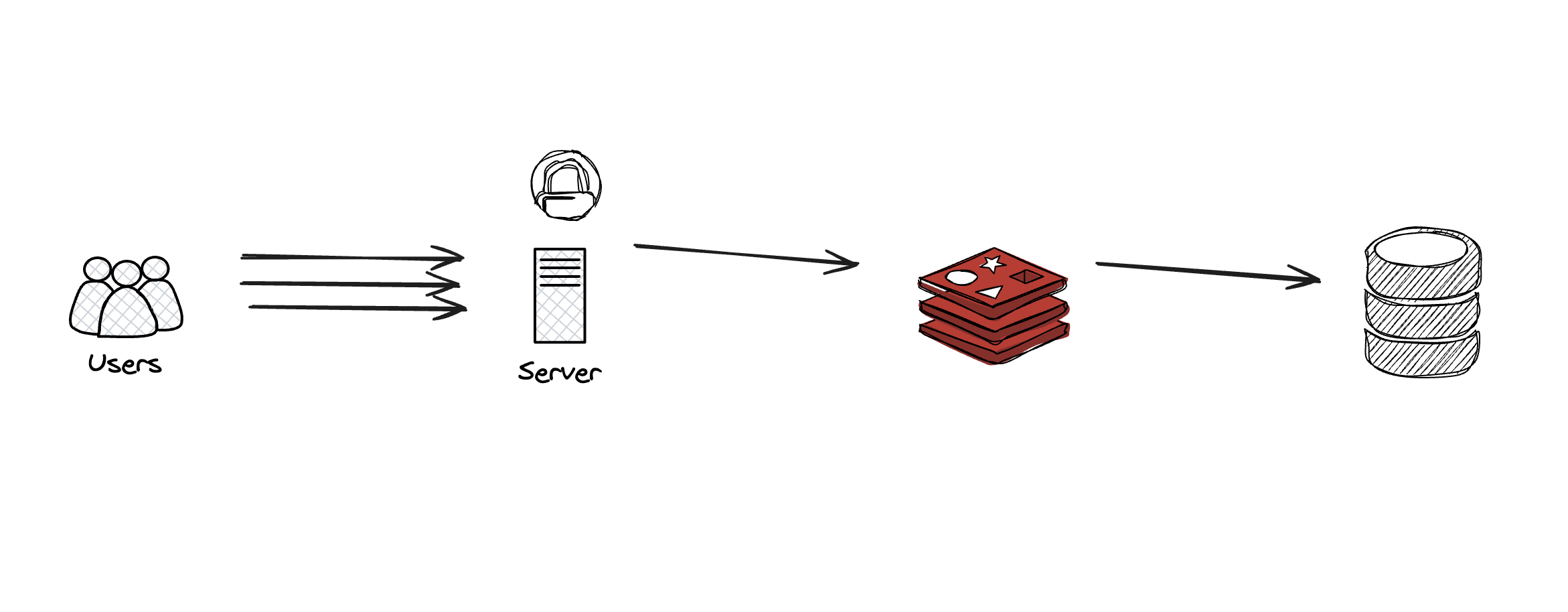
캐시 조회를 할 때 요청들을 한번에 다 보내는게 아니라 lock을 잡고 하나씩 조회한다면, cache stampede 문제를 피할 수 있다. 하지만 대다수의 방법들이 그러하듯 1번 해결 방안이 최선은 아니다. lock을 잡는다면 나머지 요청들은 대기해야하므로 성능이 저하될 우려가 있다.
2. 캐시 확률 분산
같은 캐시내의 모든 캐시들이 일시에 만료되는 것은 Cache Stampede 현상을 심화시킨다. 예를 들어 삼성전자, 엔비디아, 마이크로소프트 키들이 일시에 만료되는 것이 아니라 , 각 키들이 만료되는 시간을 분산시킨다면 db 부하를 덜 수 있을 것이다.
하지만 성능을 조금이라도 더 좋게 하기 위해서 캐시 구성이 로컬 - 레디스를 이용한 ChainedCacheable을 쓰면서 일시 만료 전략을 쓰고 있었다. 로컬 캐시를 쓰는 이유는 레디스 캐시를 조회하기 위한 네트워크 비용도 아끼려 하기 위함이다. 하지만 로컬 캐시를 쓸 때 생길 수 있는 문제는, 캐시 만료가 일시에 되지 않을 경우 인스턴스 별로 다르게 캐싱이 되어있을 수 있다는 점이다. 그러면 A 인스턴스를 찌른 경우와 B 인스턴스를 찌른 결과값이 다를 수 있고, 이는 사용자 경험에 치명적일 수 있다. 따라서 성능 최적화와 데이터 정합성 둘 다를 잡기 위해 로컬 캐싱이면서 일시 만료를 쓰고 있다. (ex. xx시 x0분이 되면 만료)
3. 캐시 워밍
다른 대안은 캐시가 만료되기 전 미리 캐시에 적재 해서 캐시 워밍을 하는 것이다. 증권 도메인의 경우 주식의 개수가 많지 않기 때문에 (5만 이하) 모든걸 미리 캐시에 적재하는데도 부담이 없다. 만약 커뮤니티 같은 도메인이라면 인기글만 캐시에 적재해도 db 부하가 많이 줄어들 것 같다.
코드 예시
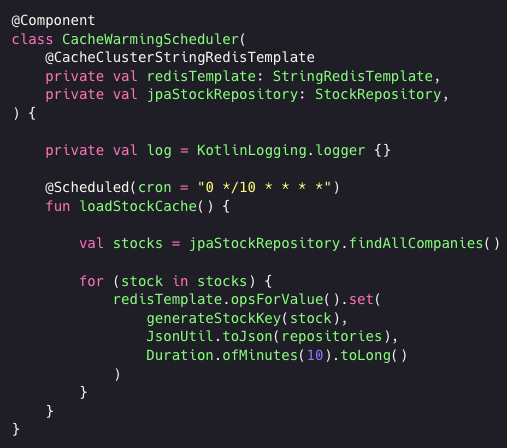
회사 코드를 올릴 수는 없어, 구체적인 정보가 드러나지 않으면서 개념만 코드로 기록하려했다.
여기서는 구현하지 않았지만캐시 키에 만약 시간 정보까지 포함해서 생성한다면, 다음 시간대의 키를 생성해서 캐시가 만료되기 전 미리 캐시에 적재를 할 수도 있다.
더 나아가기
지금대로라면 매 10분마다 모든 파드(인스턴스)에서 캐시를 적재하기 위해 db를 조회할 것이다. 이것도 아끼려면 파드 하나에서만 조회하도록 구현을 해볼 수도 있을 것이다.
참고
https://meetup.nhncloud.com/posts/251
https://engineering.linecorp.com/ko/blog/atomic-cache-stampede-redis-lua-script
