[클린코드]
1.[클린코드] 2장. 의미있는 이름

Product라는 클래스가 있다고 가정하자. 다른 클래스를 ProductInfo 혹은 ProductData라고 부른다면 개념을 구분하지 않은 채 이름만 달리한 경우다. Info나 Data는 a, an, the 와 마찬가지로 의미가 불문명한 불용어다. a나 the와 같은
2.[클린코드] 3장. 함수
함수는 한 가지를 해야 한다. 그 한가지를 잘 해야 한다. 그 한가지 만을 해야 한다.단순히 다른 표현이 아니라 의미 있는 이름으로 다른 함수를 추출할 수 있다면 그 함수는 여러 작업을 하는 셈이다.getHtml()은 추상화 수준이 아주 높다. 반면, String pa
3.[클린코드] 4장. 주석
주석은 필요악이다. 코드로 의도를 표현하지 못해, 실패를 만회하기 위해 주석을 사용한다.주석이 나쁜 이유는 시간이 지날수록 코드와 멀어지기 때문이다. 코드는 변화하고 진화하지만, 주석은 코드를 언제나 따라다니지 않는다.
4.[클린코드] 5장. 형식 맞추기
일련의 행 묶음은 완결된 생각 하나를 표현한다. 생각 사이에는 빈 행을 넣어 분리해야 한다.서로 밀접한 개념은 세로로 가까이 둬야 한다. 타당한 근거가 없다면 서로 밀접한 개념은 한 파일에 속해야 한다. 이게 바로 protected 변수를 피해야 하는 이유 중 하낟.변
5.[클린코드] 6장. 객체와 자료구조
변수를 비공개로 정의하는 이유가 있다. 남들이 변수에 의존하지 않게 만들고 싶어서다. 그렇다면 왜 조회 함수와 설정 함수를 공개해 비공개 변수를 외부에 노출하는가?구체적인 클래스다.추상적이다. 추상적인 이 클래스는 직교 좌표계를 사용하는지 극좌표계를 사용하는지 알 길
6.[클린코드] 7장. 오류 처리
오류가 발생하면 예외를 던지는 편이 낫다. 그러면 호출자 코드가 더 깔끔해진다. 논리가 오류 처리 코드와 뒤섞이지 않으니까.예외가 발생할 코드를 짤 때는 try-catch-finally 문으로 시작하는 편이 낫다. 그러면 try 블로그에서 무슨 일이 생기든지 호출자가
7.[클린코드] 8장. 경계
Map과 같은 경계 인터페이스를 이용할 때는 이를 이용하는 클래스나 클래스 계열 밖으로 노출되지 않도록 주의한다.
8.[클린코드] 9장. 단위 테스트
첫째 법칙: 실패하는 단위 테스트를 작성할 때까지 실제 코드를 작성하지 않는다.둘째 법칙: 컴파일은 실패하지 않으면서 실행이 실패하는 정도로만 단위 테스트를 작성한다.셋째 법칙: 현재 실패하는 테스트를 통과할 정도로만 실제 코드를 작성한다.테스트는 유연성, 유지보수성,
9.[클린코드] 10장. 클래스
클래스를 정의하는 표준 자바 관례에 따르면, 가장 먼저 변수 목록이 나온다. 정
10.[클린코드] 11장. 시스템
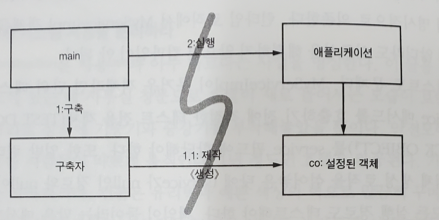
이것은 초기화 지연 혹은 계산 지연이라는 기법이다. 실제로 필요할 때 까지 객체를 생성하지 않으므로 불필요한 부하가 걸리지않고, null 포인터를 반환하지 않는 장점이 있다.하지만 getService 메서드가 MyServiceImpl 생성자 인수에 명시적으로 의존한다.
11.[클린코드] 12장. 창발성
모든 테스트를 실행한다.중복을 없앤다.프로그래머 의도를 표현한다.클래스와 메서드 수를 최소로 줄이자.위 목록은 중요도 순이다.
12.[클린코드] 13장. 동시성
동시성은 결합을 없애는 전략이다. 즉, 무엇과 언제를 분리하는 전략이다. 스레드가 하나인 프로그램은 무엇과 언제가 서로 밀접하다. 그래서 호출 스택을 살펴보면 프로그램 상태가 곧바로 드러난다. 흔히 단일 스레드 프로그램을 디버깅하는 프로그래머는 정지점을 정한 후 어느
13.[클린코드] 14장. 점진적인 개선
리팩터링을 하다보면 코드를 넣었다 뻈다 하는 사례가 아주 흔하다. 단계적으로 조금씩 변경하며 매번 테스트를 돌려야 하므로 코드를 여기저기 옮길 일이 많아진다. 리팩터링은 루빅 큐브 맞추기와 비슷하다. 큰 목표 하나를 이루기 위해 자잘한 단계를 수없이 거친다. 각 단계를
14.[클린코드] 17장. 냄새와 휴리스틱
주석은 빨리 낡는다. 쓸모 없어질 주석은 아예 달지 않는 편이 가장 좋다. 쓸모 없어진 주석은 빨리 삭제하자.빌드는 간단히 한 단계로 끝나야 한다. 아무리 열악한 환경이라도 셸에서 명령 하나로 테스트가 가능해야 한다.코드에서 중복을 발견할 때마다 추상화할 기회로 간주하
15.[클린코드] 부록. 동시성 II
시스템 작업 처리량을 테스트했는데 실패한다면 어떻게 해야할까? 이벤트 폴링 루프를 구현한다면 모를까, 단일스레드 환경에서 속도를 끌어올릴 방법은 거의 없다. 먼저 애플리케이션이 어디서 시간을 보내는지 알아야 한다. 가능성은 두 가지다.I/O: 소켓 사용, 데이터베이스