역 인덱스의 구조
역 인덱스의 내부구조는 크게 Dictionary와 Postings라는 두 파트로 나뉜다.
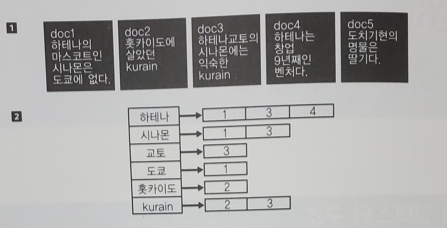
위쪽에 있는 [1]이 검색하고자하는 대상 문서라고 하자. 각 문서에는 번호가 달려있다. 각각의 문서는 문장을 담고 있다.
문서를 인덱스화한 것이 아래쪽에 있는 [2]다. 인덱스에서 좌측 사각형에 나열되어 있는 단어를 "term"이라고 한다. term의 집합이 Dictionary다.
그리고 각 term을 포함하고 있는 문서는 몇번인지를 나타내는 것이 우측에 있는 배열이다. 이것이 Postings다.
이것이 역 인덱스다. 역 인덱스 = Dictionary + Postings.
Dictionary 만드는 법
미리 정해 놓은 사전을 사용하는 방법, AC법 사용하기, 형태소 분석을 사용하는 방법 등이 있다. 또한 n-gram이라는 기법으로 문자를 적당한 단위로 나누고, 이를 term으로 다루는 방법도 있다.
사전과 AC법을 이용하는 방버
이 경우에는 사전이 곧 검색 시스템의 단어공간이 된다. 즉, 사전에 들어 있는 단어만 검색할 수 있다.
형태소 분석을 이용하는 방법(형태소를 단어로 간주해서 term으로 한다)
문장을 형태소로 나눠서 품사를 추정한다.
n-gram을 term으로 다루기
n-gram은 k-gram이라고도 한다. 텍스트를 n자씩 잘라낸 것이다. 예를 들어 abracadabra의 3-gram이라면 abr, bra, rac ... 등이 있다.
이 잘라낸 그램들이 어느 문서에 포함되어 있는지 역 인덱스를 만들 수 있다.
쿼리도 동일한 규칙으로 분할하기
n-gram을 Dictionary로서 사용할 경우, 쿼리도 동일한 규칙으로 분할한다. '하테나'로 검색하고자 할 경우 쿼리를 '하테'와 '테나'로 분할한다. 이 두 가지 쿼리로 역 인덱스를 조회하면 두 개의 Postings가 얻어진다. 그 결과 양쪽에 포함된 공통 문서 번호가 '하테나'를 포함하는 문서다.
n-gram 분할 문제와 필터링
하지만 ABC라는 단어가 있을 때 "AB와 BC"라는 문서를 인덱싱했다고 하자. 이것을 "ABC"로 검색하면 검색된다. 이는 오류다. 문서 내에 "ABC"는 없다. 따라서 직접 검색결과를 조사해서 확인해서 유효한지 확인해야 한다.
이것은 결과가 커지면 grep형과 동일한 검색시간이 소요되므로 문제다.
재현율(Recall)과 적합률(Precision)
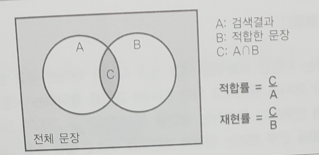
검색의 타당성에대한 평가기준 중 하나로 어느 정도의 양, 결과를 반환하는지가 '재현률'이고, 검색 결과로 반환한 것 중 명백히 타당한 결과를 얼마나 반환하고 있느냐를 '적합률'이라고 한다.
둘은 상반관계에 있다.
