웹 애플리케이션과 스토리지
데이터는 업로드된 사진 데이터나 블로그 본문과 같이 본질적으로 없어질 수 없는 원본 데이터부터, 원본 데이터를 가공함으로써 생성된 액세스 랭킹이나 검색용 인덱스 데이터 등 재생성 가능한 가공 데이터, 캐시와 같이 사라져도 성능상의 문제 이외에는 다른 문제가 없는 데이터까지 다양한 특성이 있다.
특히 원본 데이터는 가장 중요해서 서비스의 근본적인 신뢰성과 관계되어 있다. 그만큼 상응하는 비용을 들여서 최상급 신뢰성을 확보해야 한다. 반면, 캐시와 같은 데이터는 신뢰성은 그다지 중요하지 않고 성능을 높이거나 비용을 줄일 필요가 있다.
스토리지 선택의 전제가 되는 조건
스토리지를 선택할 때에는 애플리케이션의 액세스 패턴을 이해하는 것이 중요하다.
- 평균 크기
- 최대크기
- 신규추가빈도
- 갱신빈도
- 삭제빈도
- 참조빈도
또한 크기에 요구되는 신뢰성, 허용할 수 있는 장애 레벨, 사용할 수 있는 예산 등도 중요한 포인트다.
스토리지의 종류
- RDBMS: MySQL, PostgreSQL 등
- 분산 key-value 스토어: memcached 등
- 분산 파일시스템: MogileFS, GlusterFS, Lustre
- 그 밖의 스토리지: NFS 계열 분산 파일 시스템, DRBD, HDFS
RDBMS
MySQL
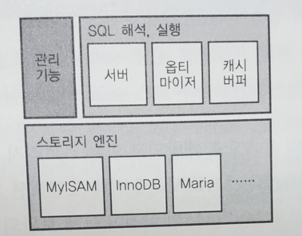
MySQL의 아키텍처는 아래 그림과 같이 되어있으며 SQL을 해석해서 실행하는 기능 블록과 실제로 데이터를 보관하는 기능 블록이 분리되어 있다. 후자는 스토리지 엔진이라 불리며, 다양한 종류가 개발, 구현되고 있다. 주요한 스토리지 엔진은 MyISAM과 InnoDB가 있으며, 현재 개발 중인 것으로는 Maria가 있다.
MyISAM
MyISAM은 MySQL 5.1의 표준 스토리지 엔진으로 되어있다. MyISAM은 심플한 구조를 한 스토리지 엔진으로, 1개의 테이블의 실제 파일 시스템 상에 3개의 파일(정의, 인덱스, 데이터)로 표현된다. 과거에 update나 delete를 한 적이 없는 테이블에 대해 insert 조작을 빠르게 할 수 있다. 또한 시작, 정지도 빠르며 테이블 이동이나 이름변경을 파일시스템 조작으로 직접 할 수 있는 등 DB 운용은 용이하다.
반면, DB 프로세스가 비정상 종료하면 테이블이 파손될 가능성이 높거나 트랜잭션 기능이 없고 update, delete, insert가 테이블 락으로 되어있다 갱신이 많은 용도로는 성능적으로 불리하다.
InnoDB
스토리지 엔진 전체에서 사전에 정의한 소수의 파일에 데이터를 저장하고, 트랜잭션을 지원하며, 비정상 종료 시 복구 기능이 있고, 데이터 갱신이 row lock으로 되어있는 등 장점이 있다.
다만 데이터량에 따라서는 시작, 정지가 수 분 정도가 걸린다거나 테이블 조작을 모두 db를 경유해서 수행해야 하는 등의 단점도 있다.
Maria
Maria는 MyISAM 후속으로 개발되고 있는 엔진으로, 트랜잭션 기능과 비정상 종료 시 복구 기능을 추가한 것이다.
MyISAM vs InnoDB

분산 Key-value 스토어
key-value 스토어는 key와 value 쌍을 저장하기 위한 심플한 스토리지이고, 분산 key-value 스토어는 key-value 스토어에 네트워크를 지원함으로써 다수의 서버로 확장시키는 기능을 지닌 것이다. key-value 스토어는 RDBMS에 비해 기능적으로는 부족하지만, 성능이 10~100배 이상이라는게 특징이다.
key-value 스토어로 가장 유명한 것은 memcached다. 메모리 상에서 동작하므로 매우 빠르게 동작하며, 메모리 상에서 동작하기 때문에 재시작할 때 데이터가 모두 사라져버린다.
memcached
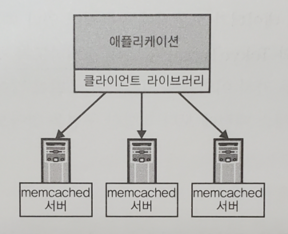
memcached는 심플한 구현의 분산 key-value 스토어로 분산 알고리즘을 클라이언트 라이브러리로 구현하고 있다는 점이 특징적이다. 분산 알고리즘은 key의 해시값을 서버대수로 나눈 나머지를 사용하는 단순한 것에서부터 Consistent Hashing과 같은 비교적 복잡한 것까지 존재한다. 사용하는 측에서는 다수의 서버 중 1대가 다운되더라도 안전하며, 서버 증감의 영향을 비교적 받지 않는다는 점이 바람직하다.
Memcached는 메모리 상에서 동작하고 있으므로 매우 빠르지만 프로세스를 재시작하면 데이터가 모두 사라져버린다. 따라서 원본 데이터 저장으로는 당연히 부적합하며, 재생성 시에 시간이 걸리는 가공 데이터 저장에도 적합하지 않은 경우가 있다. memcached의 특성을 가장 잘 활용할 수 있는 데이터는 캐시 데이터디. 전형적인 예로는 RDBMS에서 읽어들인 데이터를 일시적으로 저장해두고 또다시 참조할 때는 먼저 memcached를 참조해서 찾지 못한 경우에만 RDBMS를 참조하는 방법이 있다. RDBMS 이외에도 외부 리소스에 질의한 결과를 캐싱하는 등 다양한 캐시용 스토리지로 활용할 수 있다.
캐시로 한정할 경우에는 서버에는 메모리만 충분히 탑재해두면 되며, CPU나 I/O 성능은 그다지 요구되지 않는다. 따라서 저가 하드웨어를 나열해서 대량의 캐시풀을 구축하고 고가 하드웨어를 요구하는 RDBMS 대수를 줄이는 구성이 가능해진다.
분산 파일시스템
분산 파일시스템도 스토리지의 유력한 후보가 된다. 분산 파일시스템은 파일시스템의 특성상 보통은 어느 정도 이상인 크기의 데이터를 저장하는데 적합하다.
그 밖의 스토리지
NFS 계열 분산 시스템
NFS는 특정 서버의 파일시스템을 다른 서버에서 마운트해서 해당 서버의 로컬 파일시스템과 마찬가지로 조작할 수 있도록 하는 기술이다.
