UTF-8
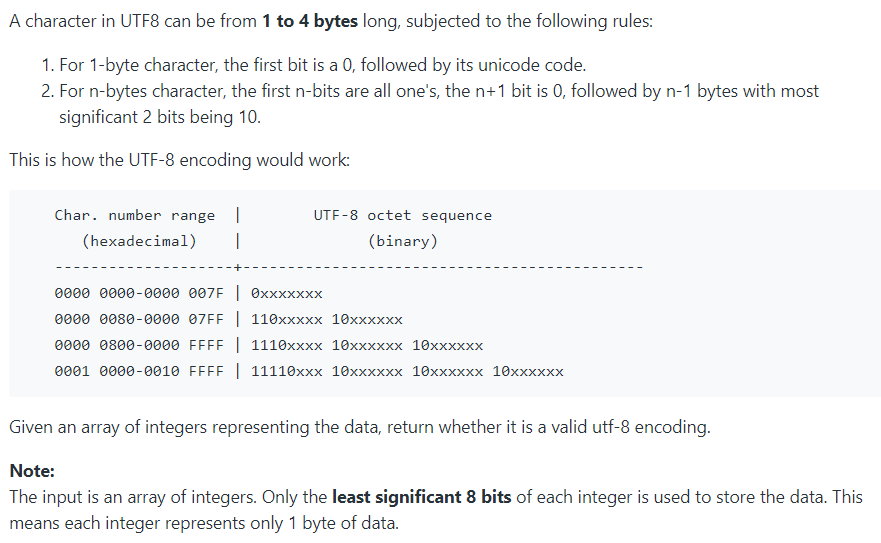
초기에 문자를 표현하던 대표적인 방식은 ASCII 인코딩 방식으로, 1바이트에 모든 문자를 표현했다. 게다가 1비트는 체크섬으로 제외하여 7비트, 즉 128 문자를 표현했다. 하지만 이는 부족했고, 이를 해결하기 위해 2~4바이트 공간에 여유있게 문자를 할당하고자 등장한 방식이 바로 유니코드이다. 그러나 유니코드 자체는 1바이트로 표현이 가능한 영문자도 2바이트이상의 공간을 사용하기 때문에 메모리 낭비가 심하다. 이를 해결하기 위해 UTF-8이 등장했다.
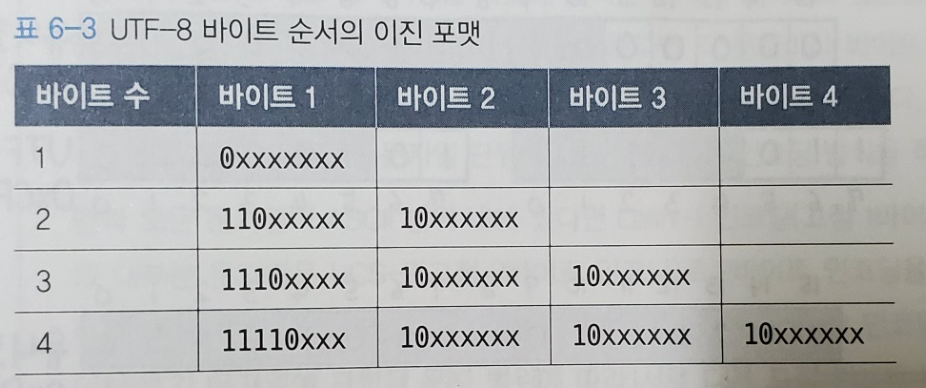
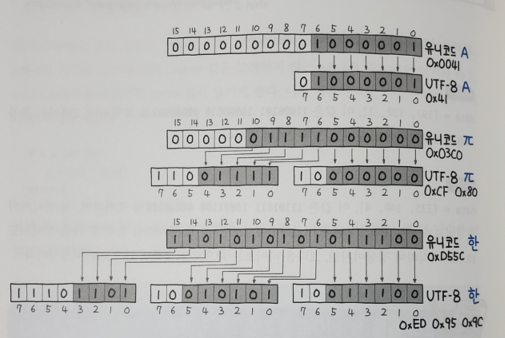
시작 비트를 보면 문자의 전체 바이트를 결정할 수 있다. 첫 바이트의 맨 앞 비트를 확인해서 0인 경우 1바이트 문자, 10인 경우 특정 문자의 ㅈ우간 바이트, 110인 경우 2바이트, 1110인 경우 3바이트, 11110인 경우 4바이트이다.
책 풀이
def validUtf8(self, data: List[int]) -> bool:
# 문자바이트만큼 10으로 시작 판별
def check(size):
for i in range(start+1, start+size+1):
if i >= len(data) or (data[i] >> 6) != 0b10:
return False
return True
start = 0
while start < len(data):
# 첫 바이트 기준 총 문자 바이트 판별
first = data[start]
if (first >> 3) == 0b11110 and check(3):
start += 4
elif (first >> 4) == 0b1110 and check(2):
start += 3
elif (first >> 5) == 0b110 and check(1):
start += 2
elif (first >> 7) == 0:
start += 1
else:
return False
return True