Web
-
CLIENT (Front-End)
HTML, CSS, JavaScript
Browser가 실행, 해석하는 언어
-
WEB SERVER (Back-End)
PHP, JSP, ASP 등
SERVER가 실행, 해석하여 CLIENT에게 응답한다.
웹 서버와 브라우저 작동 방식
Client ← → Web Server ← → Web Application Server ← → DB
Web Server
- 정적 페이지
변하지 않는 페이지 (html, img)
Web Application Server
- 동적 페이지
사용자 요청에 맞게 동적으로 변하는 페이지 (PHP, JSP, ASP)
Proxy Server
프록시 서버는 클라이언트에서 서버로 접속을 할 때 직접적으로 접속하지 않고 중간에 대신 전달해주는 서버를 의미한다.
- Proxy Tool 웹 브라우저와 서버 사이에 위치해 request와 response를 처리하며 데이터를 수정, 관찰할 수 있다. 대표적인 도구로
Burp Suite가 있다.
접속의 시작 : URL 입력부터
인터넷에 접속하기 위해 가장 먼저 할 일은 브라우저에 URL을 입력하는 것이다.
브라우저
웹서버에 접속하는 기능, 파일 업로드 기능, 메일 송수신 기능 등을 가지고 있는
복합적인 클라이언트 소프트웨어
URL (Uniform Resource Locator)
네트워크 상에서 자원이 어디 있는지를 알려주기 위한 경로이며 http://, ftp:, file:, mailto: 등의 형식을 사용한다.
모든 URL은 http:, ftp:, file:, mailto: 부분에서 엑세스 방법을 나타낸다.
엑세스 대상이 웹 서버라면 HTTP프로토콜을 사용하고 FTP 서버라면 FTP프로토콜을 사용한다.
# 엑세스 할 때 네트워크를 사용하지 않는 것도 있어 프로토콜을 나타낸다 생각하면 안된다. 엑세스 방법의 종류라 생각해야 한다.
URL 해독
URL을 입력하면 브라우저는 웹 서버에 보내는 리퀘스트 메시지를 작성하기 위해 URL을 해독한다.
URL 요소
http://www.lab.cyber.co.kr/dir1/file1.html
⬇
protocol://computer_name:port/directory_name/document_name?parameters
⬇
protocol: + // + computer_name:port + / + directory_name + / + document_name?parameters
protocol : 문서를 접근하기 위해 사용하는 프로토콜 이름
computer_name : 문서가 있는 컴퓨터(서버)의 도메인 이름
port : 서버가 어떤 포트 숫자를 바라보고 있는지 (생략 가능)
document_name : 서버 컴퓨터에 있는 특정 문서의 이름
parameters : 페이지에 넘기는 변수 (생략 가능)
http://www.lab.cyber.co.kr/dir1/file1.html
위 URL의 의미는 아래와 같다.
- http 프로토콜을 이용해서
- www.lab.cyber.co.kr 도메인 명을 가진 서버에 접속한다.
- 접속한 서버에 dir1 디렉토리의
- file1.html파일을 엑세스한다.
파일명을 생략한 경우
http://www.lab.cyber.co.kr/dir/
URL 끝이 " / " 로 끝나는 것은 /dir/ 다음에 써야 할 파일명을 생략한다는 의미다.
파일명을 생략하면 브라우저는 어느 파일에 엑세스해야 할 지 모른다.
이런 경우를 대비해 'index.html', 'default.html' 이름의 파일을 미리 서버에 설정해둔다.
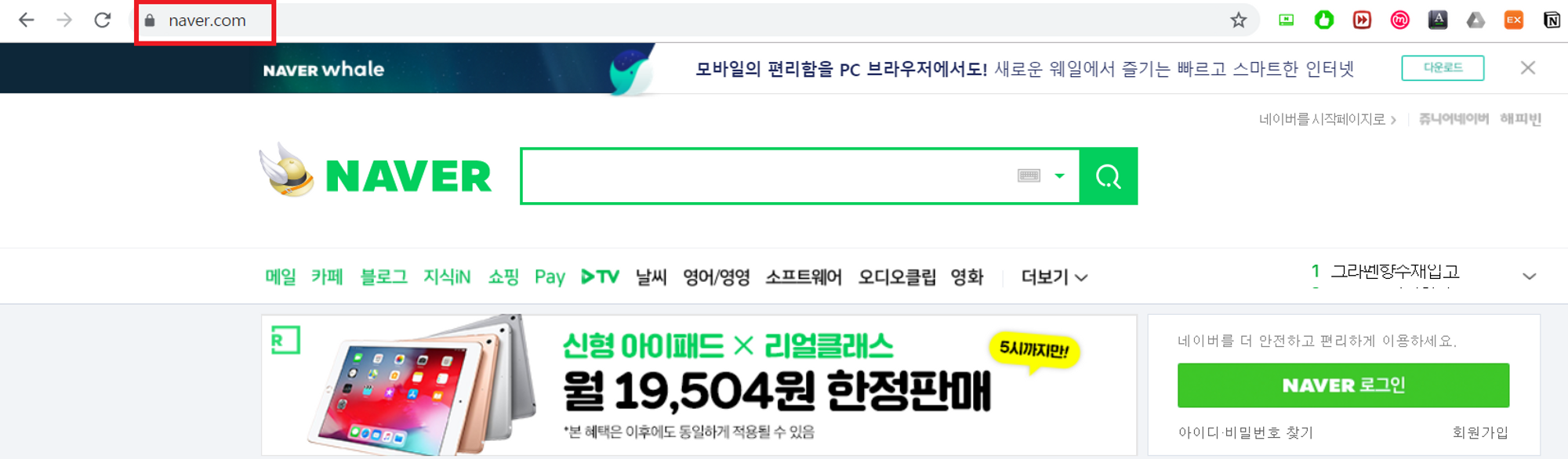
https://www.naver.com/ URL을 이용해 네이버에 접속하면 index.html 파일이 생략되어있다.
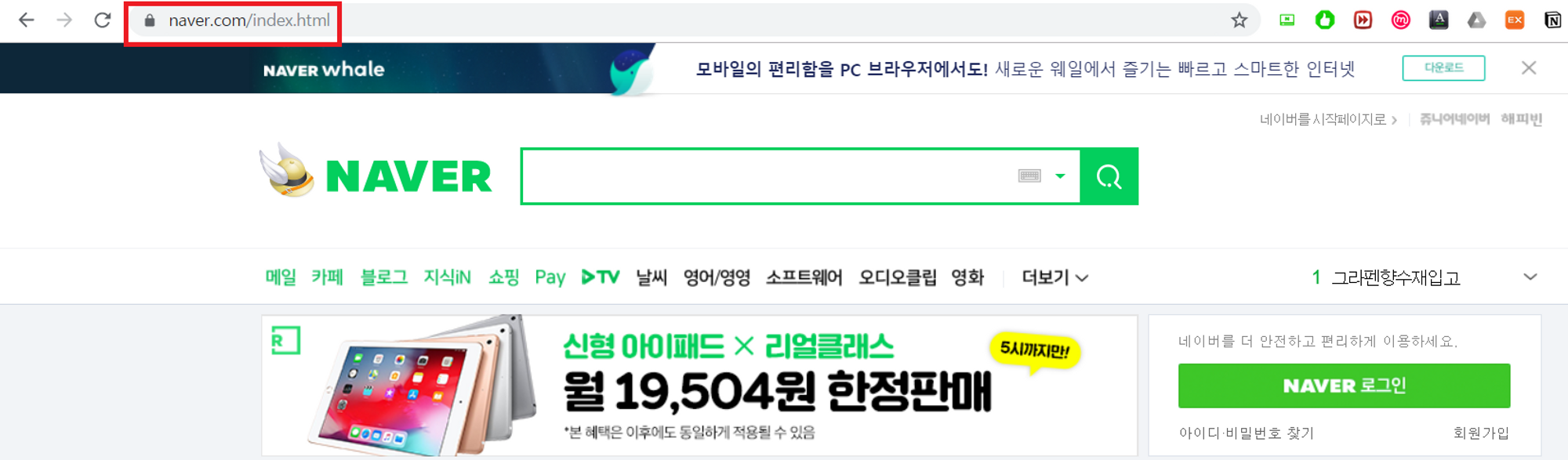
생략된 index.html을 추가해도 문제없이 네이버에 접속되고 URL 끝의 /를 생략해 접속해도 문제없다.
https://www.naver.com/ 는 루트디렉토리를 의미하며 'index.html', 'default.html' 이름의 파일이 미리 설정되었기 때문이다.
HTTP
HTTP는 서버와 클라이언트가 인터넷상에서 데이터를 주고받기 위한 프로토콜(protocol)이다.
작동방식
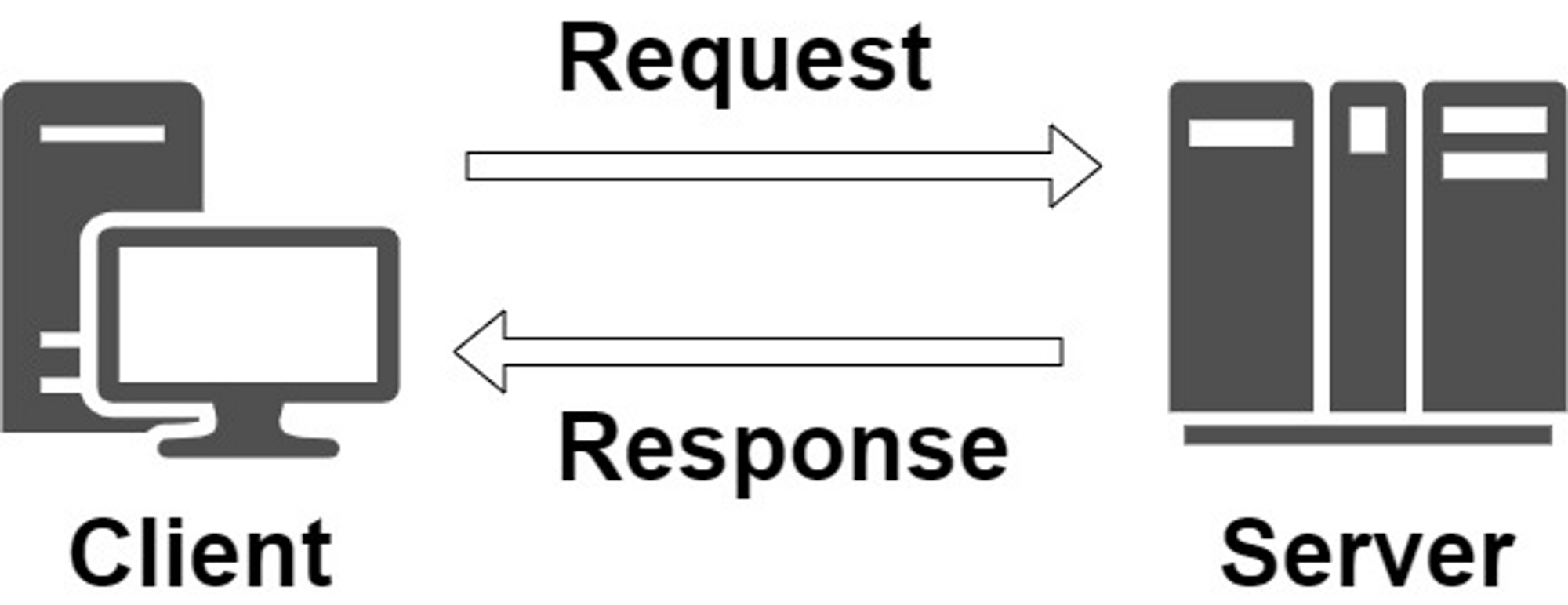
특징
- 비연결 지향(Connectionless)
클라이언트가 request를 서버에 보내고, 서버가 클라이언트에 요청에 맞는 response를 보내면 바로 연결을 끊는다. - 무상태(Stateless)
연결을 끊는 순간 클라이언트와 서버의 통신은 끝나며 상태 정보를 유지하지 않는다.
장점
- 불특정 다수를 대상으로 하는 서비스에는 적합하다.
- 클라이언트와 서버가 계속 연결된 형태가 아니기 때문에 클라이언트와 서버 간의 최대 연결 수보다 훨씬 많은 요청과 응답을 처리할 수 있다.
단점
- 연결을 끊어버리기 때문에, 클라이언트의 이전 상황을 알 수가 없다.
- 이러한 특징을 무상태(Stateless)라고 말한다.
- 이러한 특징 때문에 정보를 유지하기 위해서 Cookie와 같은 기술을 사용한다.
HTTP Request
클라이언트(브라우저)는 서버에게 Request 메시지를 보낸다.
Request 메시지 내부에는 '무엇을', '어떻게 해서' 라는 내용이 쓰여져 있다.
'무엇을'에 해당하는 것을 URI라 하고 '어떻게 해서' 에 해당하는 것은 메소드라 부른다. 이 메소드를 사용해 웹 서버에 어떤 동작을 할 것인지 전달한다.
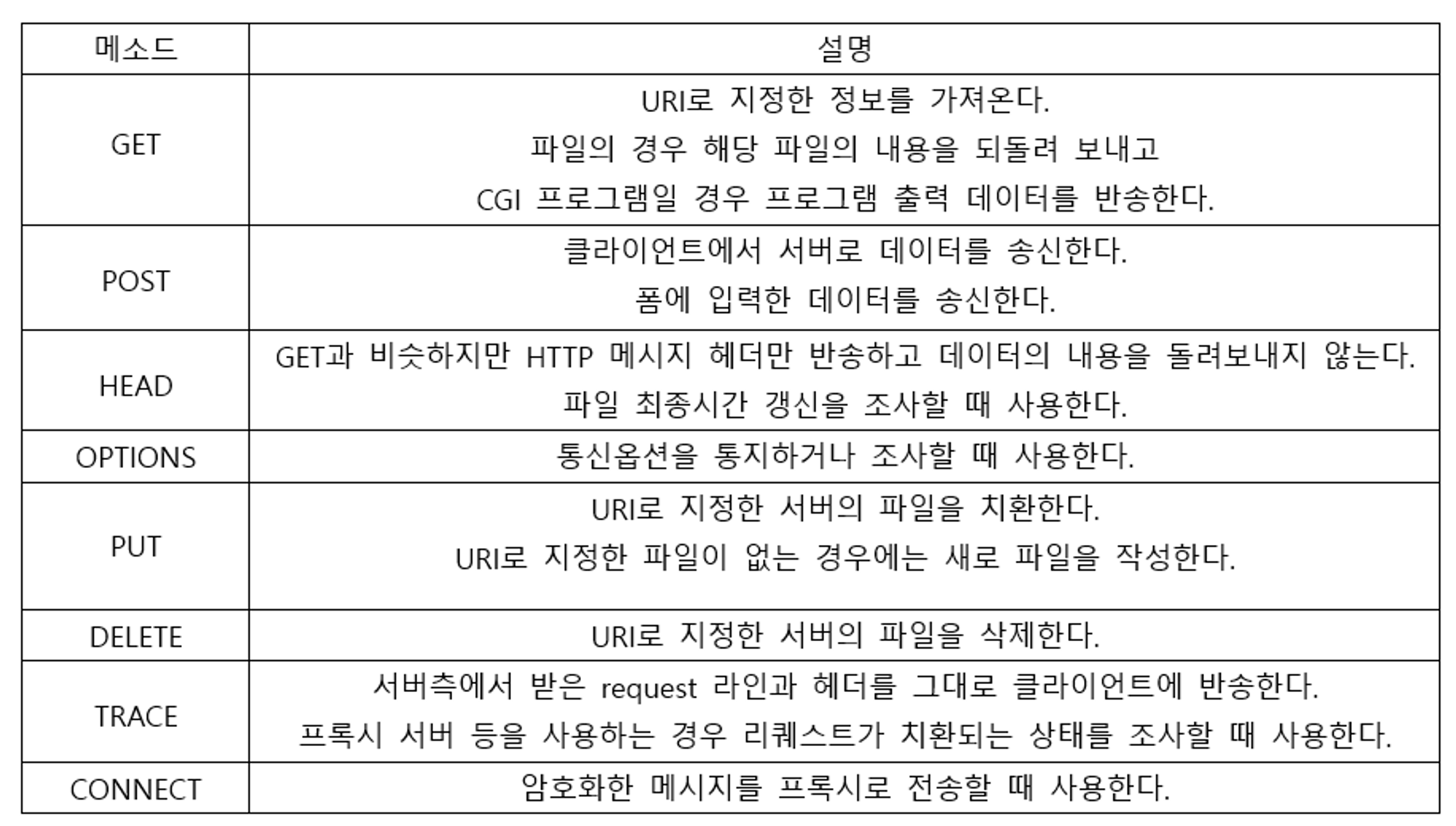
대표 Method
- GET : 문서를 요청. 서버가 클라이언트에 상태 정보와 복제된 문서를 보냄으로써 응답을 함. (조회)
- HEAD : 상태 정보를 요청. GET 과 동일한 형태로 응답을 하지만, 문서를 복제하지는 않는다.
- POST : 데이터를 서버로 송신. 서버는 해당 데이터를 특정 아이템에 덧붙인다. (생성)
- PUT : 데이터를 서버로 송신. 서버가 특정 아이템을 완전히 대체한다. (수정)
HTTP Response
request 메시지를 받은 서버는 메시지를 해독해 URI와 Method 요구사항을 처리한다.
그런 다음 Response 메시지에 Status Code(상태 코드)를 첨부해 클라이언트에게 전송한다.
Response 메시지를 받은 클라이언트는 데이터를 추출해 화면에 표시하면 HTTP의 동작이 끝난다.
Status Code(상태 코드)
- 응답 메시지의 맨 앞부분에 존재한다.
- 실행 결과가 정상 종료되었는지, 이상이 발생했는지 나타냄
- 처리한 데이터 결과를 나타내는 코드
Status Code는 5개의 클래스(분류)로 구분하며 코드의 첫 번째 숫자는 응답 클래스를 정의한다.
- 1xx (정보): 요청을 받았으며 프로세스를 계속한다
- 2xx (성공): 요청을 성공적으로 받았으며 인식했고 수용하였다
- 3xx (리다이렉션): 요청 완료를 위해 추가 작업 조치가 필요하다
- 4xx (클라이언트 오류): 요청의 문법이 잘못되었거나 요청을 처리할 수 없다
- 5xx (서버 오류): 서버가 명백히 유효한 요청에 대해 충족을 실패했다
Status Code의 더 많은 정보를 원하면 아래 링크를 참조바랍니다.
https://ko.wikipedia.org/wiki/HTTP_상태코드https://ko.wikipedia.org/wiki/HTTP
HTTP method
GET
GET은 서버의 데이터를 가져오는 역할을 한다.
URL 에 사이트 주소를 입력하고 확인을 누르면, 브라우저에서 GET 요청으로 서버에 페이지를 요청하고 요청한 페이지 파일을 가져온다.
GET 예시
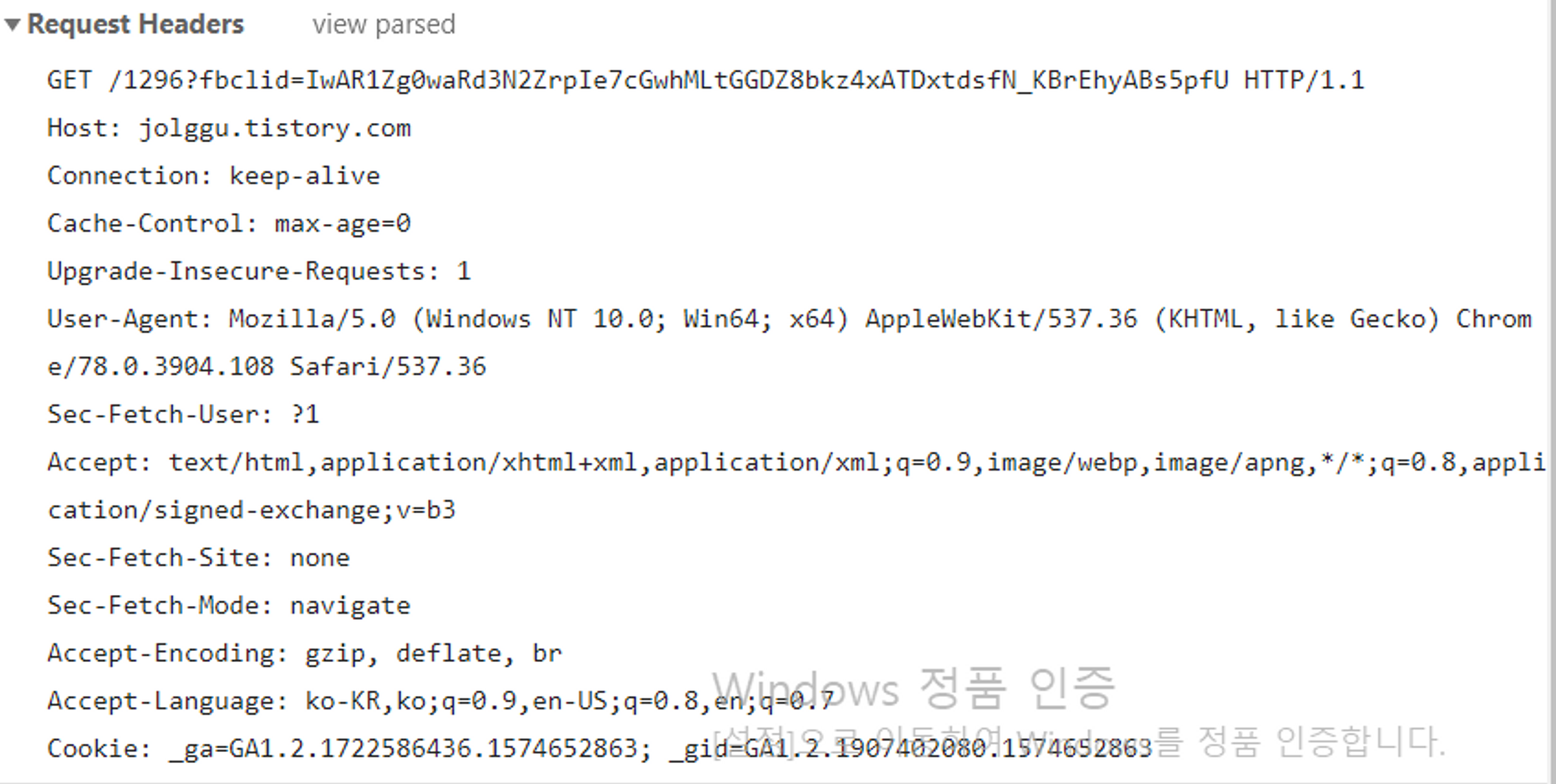
Request Headers
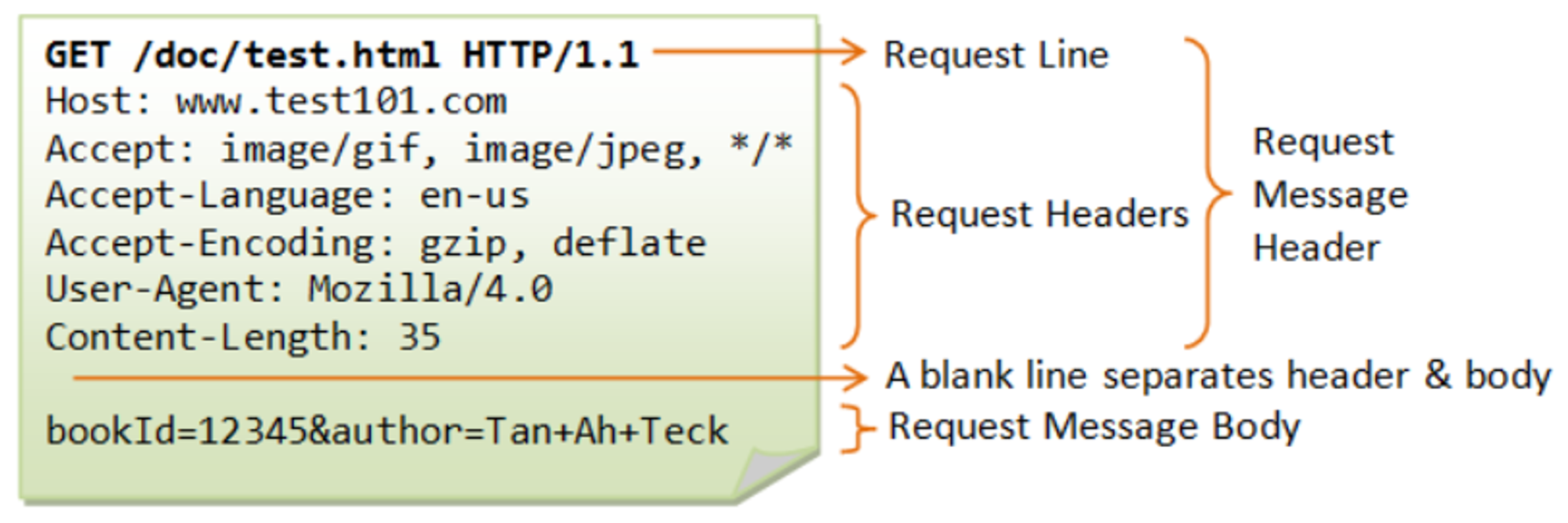
GET /doc/test.html HTTP/1.1 이 라인을 Request Line이라 부르고 세가지 요소로 구성된다.
- 메소드
- GET, POST, HEAD, PUT 등
- 요청한 문서 경로
- URL 또는 프로토콜, 포트, 도메인의 절대 경로로 나타낸다.
- origin 형식: 끝에 '?'와
Query String이 붙는 절대 경로
GET, POST, HEAD, OPTIONS 메서드와 함께 사용한다.
POST / HTTP 1.1
GET /background.png HTTP/1.0
HEAD /test.html?query=alibaba HTTP/1.1
OPTIONS /anypage.html HTTP/1.0 - absolute 형식 : 완전한 URL 형식
프록시에 연결하는 경우 대부분 GET과 함께 사용된다.
ex) https://developer.mozilla.org/ko/docs/Web/HTTP/Messages - authority 형식 : 도메인 이름 및 옵션 포트(':'가 앞에 붙음)로 이루어진 URL의
authority component이다.
HTTP 터널을 구축하는 경우에만 CONNECT와 함께 사용한다.
CONNECT developer.mozilla.org:80 HTTP/1.1 - asterisk 형식 :
OPTIONS와 함께*하나로 간단하게 서버 전체를 나타낸다. ex) OPTIONS * HTTP/1.1
- HTTP 버전
Request 주요 헤더필드
HOST : 리퀘스트를 받은 서버의 URL
User-Agent : 클라이언트 소프트웨어의 명칭이나 버전 정보를 의미
예시의 클라이언트는 크롬 브라우저, Windows NT 10.0을 사용한다.
Accept-Encoding : 클라이언트가 Content-Encoding으로 받은 인코딩방식 주로 데이터압축을 나타낸다.
if-Unmodified-since : 클라이언트 파일과 서버의 파일과 비교해 최신파일이 아니면 최신 파일을 보내주고 최신파일이면 보내지 않는다.
메시지 헤더 이후에는 공백 행이 오고 그 뒤에 송신할 데이터가 위치한다.
이 부분이 메시지 body이며 메시지 실제 데이터가 담긴다.
GET은 URI와 메소드만으로 서버가 무엇을 할지 판단하므로 body에 데이터를 작성하지 않고 queryString으로 데이터를 조회한다.
POST는 폼에 입력한 데이터들을 body에 작성한다.
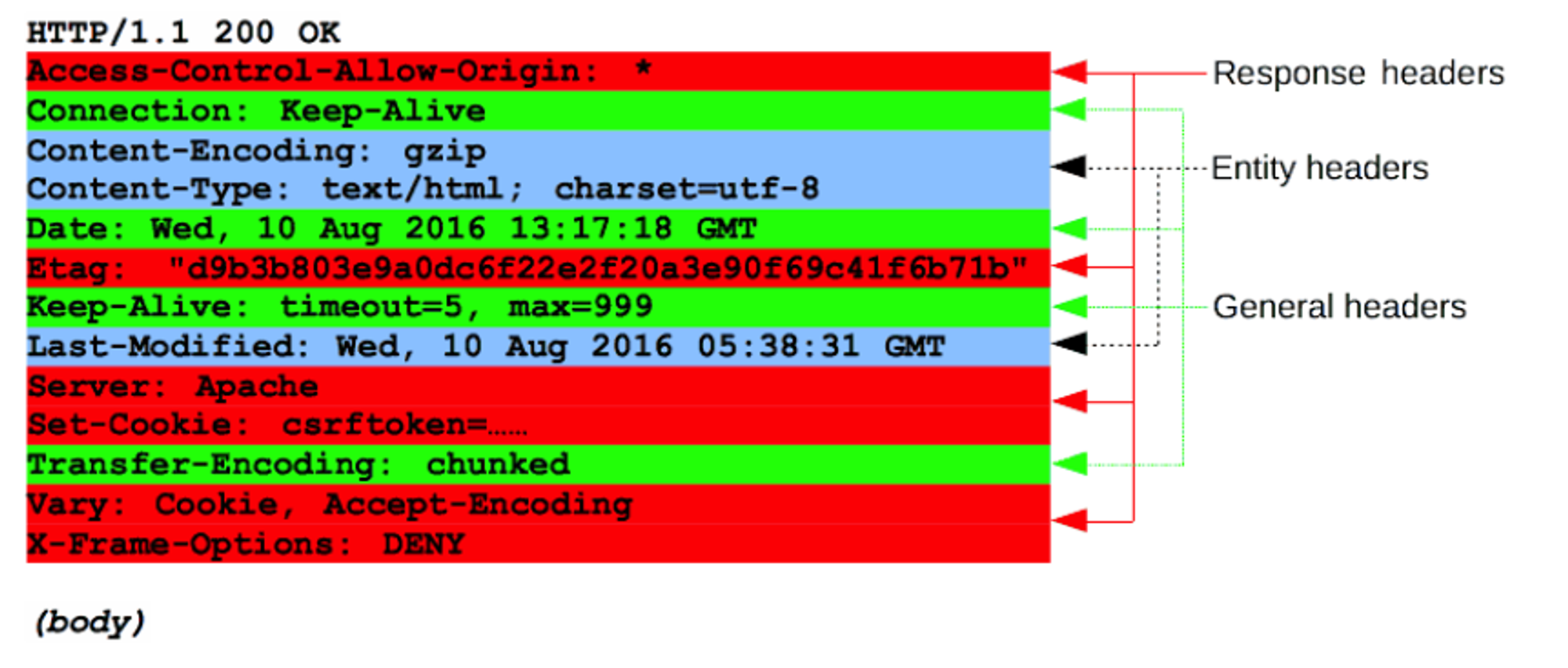
Response header
HTTP 응답의 시작 줄은 상태 줄(status line)이라고 불리며, 아래 정보를 가진다.
HTTP/1.1 200 OK
- 프로토콜 버전
보통 HTTP/1.1입니다. - 상태 코드
요청의 성공 여부를 나타냅니다. 200, 404 혹은 302입니다. - 상태 텍스트
짧고 간결하게 상태 코드에 대한 설명을 글로 나타내어 사람들이 HTTP 메시지를 이해할 때 도움이 됩니다.
다양한 종류의 응답 헤더가 있는데, 이들은 몇몇 그룹으로 나뉜다.
- General 헤더
Via와 같은 헤더는 메시지 전체에 적용된다. - Response 헤더
Vary와 Accept-Ranges와 같은 헤더는 상태 줄에 미처 들어가지 못했던 서버에 대한 추가 정보를 제공한다. - Entity 헤더
Content-Length와 같은 헤더는 요청 본문에 적용된다.
요청 내에 본문이 없는 경우 entity 헤더는 전송되지 않는다.
요청 페이지가 문장, 영상, 이미지 등으로 구성되어 있다면 각각의 리퀘스트 메시지를 보낸다.
리퀘스트에 쓰는 URI는 1개 만으로 결정되어 한 번에 파일 한개 씩 읽어야 한다.
만약 페이지에 문장과 영상이 3개 존재하면 총 4번의 리퀘스트 메시지를 보내야 한다.
그럼 웹 서버는 4번의 리퀘스트 메시지에 대해 4번의 응답 메시지를 보낸다.
그림에서 보듯이 html문서, 이미지 파일, JS 파일 각각 따로 응답한 걸 알 수 있다.
reference
성공과 실패를 결정하는 1%의 네트워크 원리 (이도희 역)
https://www.edwith.org/boostcourse-web/lecture/16661/
https://ko.wikipedia.org/wiki/HTTP_상태코드
https://ko.wikipedia.org/wiki/HTTP
https://doooyeon.github.io/2018/09/10/cookie-and-session.html
https://jeong-pro.tistory.com/80
https://joshua1988.github.io/web-development/web-protocols/#
http-hyper-text-transfer-protocol
https://ko.wikipedia.org/wiki/URL
https://gmlwjd9405.github.io/2019/04/17/what-is-http-protocol.html
https://opentutorials.org/course/3385
https://joshua1988.github.io/web-development/web-protocols/
https://developer.mozilla.org/ko/docs/Web/HTTP/Messages
https://gmlwjd9405.github.io/2019/04/17/what-is-http-protocol.html
