
검색 쿼리를 누가 그렇게 쓰냐🤦🏻♂️
멋대로 검색 쿼리 만들었다가 욕 먹음ㅎ 키워드 검색 기능을 만들기 위해 처음엔 next.js의 file convention 부분을 보면서 시작했다. a=1&a=2라고 되어있길래…
'옹 그러면 search를 키로 하고, 1,2에 내가 원하는걸 넣으면 되겠네?'
라는 단순한 생각으로 코드를 짜기 시작했고…
결국 중복된 키를 가지는 신기한 욕먹는 코드가 등장했다ㅎㅎㅎㅎㅎ

“너 해시 테이블하지 않았어?”
...응 그러네.
쿼리스트링 만들기
암튼 쿼리는 불필요한 중복을 없앴고 검색어 간에는 &이 아닌 +를 활용해서 엮었다.
예를 들어, 조선과 제도라는 키워드를 검색한다고 생각해보자.
클라이언트에서 작성한 queryString를 출력하면 search=조선+제도가 출력되고,
서버에서 request.args.get('search')로 쿼리 파라미터에 엑세스하면 다음과 같이 출력된다. "조선 제도"
🤔 +는 어디갔나?
url 인코딩 방식에서 만약 공백을 입력할 경우, 유효하지 않으니 +기호로 표시하는데 대표적인 인코딩된 공백은 +와 %20이 있다.
공백기준으로 쿼리 파라미터를 나누기 위해서 .split(" ")를 한다.
그리고 이것을 데이터베이스로 넘겨 조선 OR 제도의 결과를 리턴해야 한다.
Supabase에서는 JOIN을 어떻게 하나?
테이블 두 개를 엮어 JOIN을 때려야 하는데 Supabase에서는 JOIN을 어떻게 할 수 있는지 찾을 수 없었다. (나의 검색력 부족일 수도…)
계속 postgresl 함수를 커스텀하라고 하는데…그냥 코드로 JOIN할 수 있는 방법을 찾다가 없어서 결국 supabase에서 함수 만들어 쓰기로 했다.
일단 OR 검색을 위해 서버에서 검색어들을 '|' 연산자로 묶어 두었다.
Supabase에서 Postgresql 함수 작성하기
Supabase에 프로젝트를 생성하게 되면 왼쪽에 사이트 메뉴에서 SQL Editor를 확인할 수 있다.
해당 에디터에서 함수를 작성하고 테스트 케이스를 파라미터로 전달한 뒤에 RUN을 클릭하면 결과값이 아래에 리턴된다.
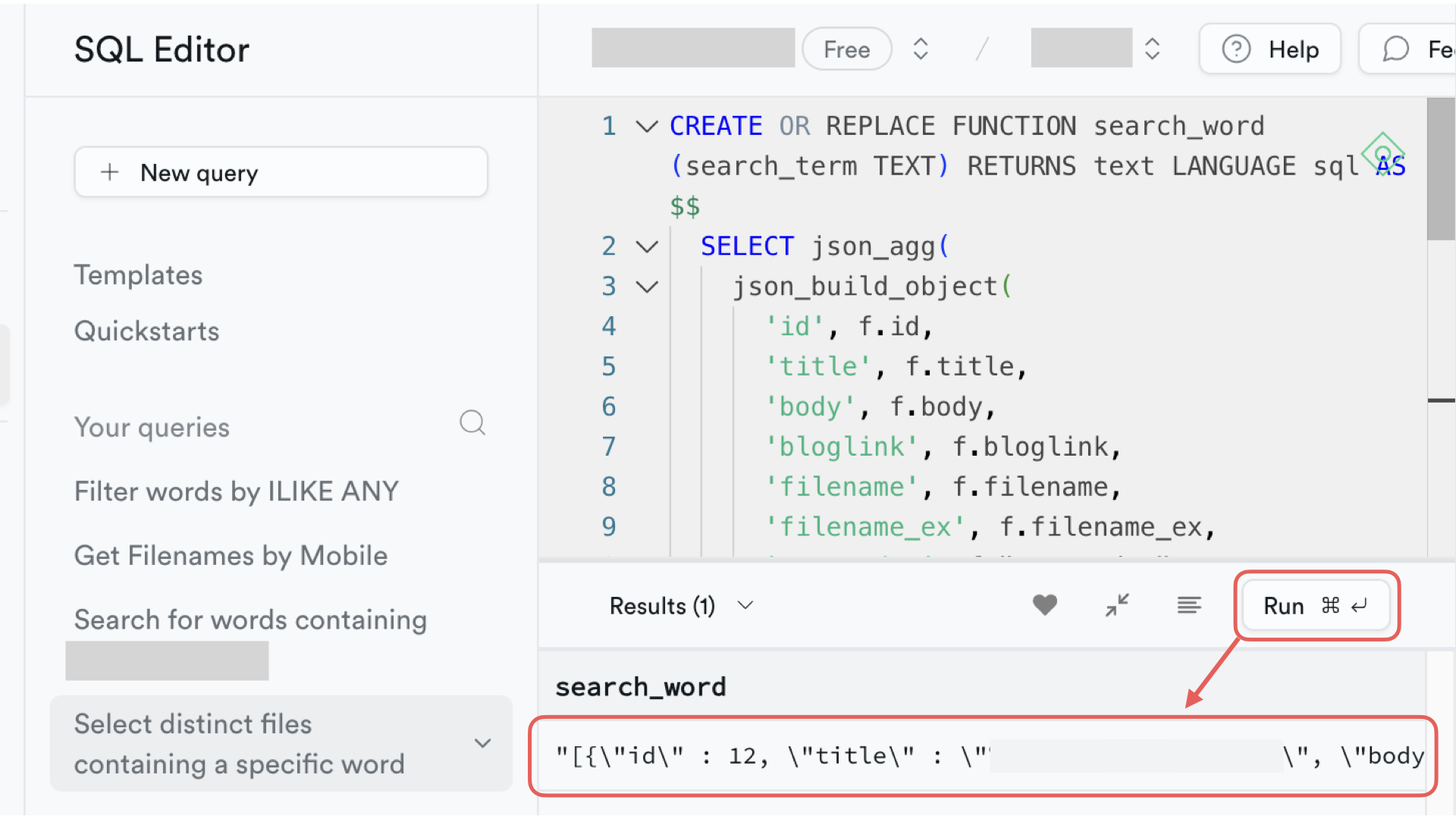
이렇게 supabase에 작성한 postgresql 함수는 서버 코드에서 rpc(remote procedure calls)로 호출할 수 있다.
예시1) 테이블 간 JOIN 구현하기
아래는 실제로 supabase에 적용한 함수 두 가지이다.
사실 정확한 테이블 구조를 알지 않고서 아래 함수를 이해하기는 어려울 수 있지만 함수의 뼈대는 반복적으로 사용할 수 있기 때문에 line by line으로 살펴보자.
CREATE OR REPLACE FUNCTION search_word(search_term TEXT) RETURNS text LANGUAGE sql AS $$
SELECT json_agg(
json_build_object(
'id', f.id,
'title', f.title,
'body', f.body,
'bloglink', f.bloglink,
'filename', f.filename,
'filename_ex', f.filename_ex,
'createdAt', f."createdAt",
'isPaid', f."isPaid",
'price', f.price
)
)
FROM words
JOIN files f ON words."fileId" = f."id"
WHERE words."word" ILIKE ANY (SELECT unnest(string_to_array(search_term, ' | ')));
$$;
-- SELECT search_word('조선 | 제도')굉장히 복잡해보이지만 뜯어보면 쉽다.
함수 선언
CREATE OR REPLACE FUNCTION search_word(search_term TEXT) RETURNS text LANGUAGE sql AS $$CREATE OR REPLACE FUNCTION: 새 함수를 만들거나 데이터베이스의 기존 함수를 바꾸겠다search_word(search_term TEXT): text타입을 갖는 search_term이라는 파라미터 하나를 받는 search_word라는 함수를 선언한다RETURNS text: 함수가 텍스트 데이터를 반환할거고,LANGUAGE sql: 함수가 SQL로 작성되었다.$$: 이제 함수 본문을 시작!
함수 본문
SELECT json_agg(
json_build_object(
'id', f.id,
'title', f.title,
'body', f.body,
'bloglink', f.bloglink,
'filename', f.filename,
'filename_ex', f.filename_ex,
'createdAt', f."createdAt",
'isPaid', f."isPaid",
'price', f.price
)
)
FROM words
JOIN files f ON words."fileId" = f."id"
WHERE words."word" ILIKE ANY (SELECT unnest(string_to_array(search_term, ' | ')));
$$;json_agg: 레코드 값을 JSON 배열로 합치는(집합) PostgreSQL 함수인데,json_build_object: 키-값 페어로 JSON 객체를 만들거야.FROM words JOIN files f ON words."fileId" = f."id":words테이블에서 선택해서words의fileId열이files의id열과 일치하는files테이블(f)과 조인해줘.WHERE문장은words테이블의word열을 기준으로 레코드를 필터링한다.ILIKE는 대소문자를 구분하지 않는 패턴 일치를 의미한다.ANY (SELECT unnest(string_to_array(search_term, ' | ')));:search_term을' | '로 분할하고 결과로 나온 배의 각 요소(unnest)에ILIKE를 적용하여 검색한다.PostgreSQL의
unnest함수
배열 인풋으로 받아서 row의 집합으로 확장하는 데 사용된다. 각 행은 배열의 요소를 나타냅니다. 이 함수는 SQL 쿼리 내에서 배열의 개별 요소에 대해 연산을 수행하려는 경우에 유용하다.$$;: 함수 바디 끝!
함수 호출(주석)
-- SELECT search_word('조선 | 제도')SELECT를 통해서 sql 함수를 호출 할 수 있다.--는 주석을 의미
예시2) 고객 주문서에서 상품명 추출해서 상품에 포함되는 제품 리스트 가지고 오기
말이 조금 어려운데, 고객은 상품을 주문하고 해당 상품이 세트 상품인 경우 상품에 포함되는 제품 리스트를 가지고 오는 함수가 필요했다.
(결제 api 연동을 위해서 테이블 구조를 조금 바꿨음)
주문 항목을 가져오기 위한 함수는 아래와 같다.
CREATE OR REPLACE FUNCTION get_filenames_by_mobile(mobile TEXT) RETURNS JSONB LANGUAGE plpgsql AS $$
DECLARE
product_id int;
filenames JSONB;
BEGIN
SELECT p.id INTO product_id
FROM orders o
JOIN products p ON o.product = p.name
WHERE o.mobile = get_filenames_by_mobile.mobile;
SELECT json_agg(pf.filename_ex) INTO filenames
FROM paid_files pf
WHERE pf."productId" = product_id;
RETURN filenames;
END;
$$;
-- select get_filenames_by_mobile('test')RETURNS JSONB: 이 함수는 PostgreSQL에서 JSON의 바이너리 표현인 JSONB 유형의 데이터를 반환합니다.LANGUAGE plpgsql: Postgresql의 procedure 언어인 PL/pgSQL로 작성했다.
함수 본문
DECLARE
product_id int;
filenames JSONB;- 이 함수에서 쓰일 정수 타입
product_id, JSONB타입filenames두 변수를 선언할게.
-- productId 찾기
SELECT p.id INTO product_id
FROM orders o
JOIN products p ON o.product = p.name
WHERE o.mobile = get_filenames_by_mobile.mobile;WHERE o.mobile = get_filenames_by_mobile.mobile;:orders테이블에서mobile열이 인풋으로 들어온 파라미터mobile와 일치하면FROM orders o JOIN products p ON o.product = p.name:orders테이블이랑products테이블과 조인되는데products테이블의name열과orders테이블의product열이 일치하는 걸 찾아서SELECT p.id INTO product_id:products테이블에서id를product_id변수에 저장한다.
-- filenames 가지고 오기
SELECT json_agg(pf.filename_ex) INTO filenames
FROM paid_files pf
WHERE pf."productId" = product_id;FROM paid_files pf:paid_files테이블에서WHERE pf."productId" = product_id;product_id에 저장해 둔값과paid_files의productId값이 일치하는 것을 찾아서SELECT json_agg(pf.filename_ex) INTO filenames:paid_files테이블에서filename_ex의 값을filenames에 저장한다.
사실, files테이블로 관리하려고 했으나 이미 너무 코드가 복잡해져버리는 바람에 부득이 하게 유료 자료를 보관하는 paid_files테이블을 새로 생성했다.
위의 함수를 실행하면,
유저가 주문 시에 넣은 핸드폰 번호를 통해서 주문자 목록을 조회하고(비로그인 주문이라서) 주문자 목록의 상품이름과 상품 테이블의 이름을 확인한 뒤, 상품 테이블의 id값을 가진 paid_files 테이블의 자료 이름을 가지고 온다.
꽤나 복잡한…테이블 3개가 엮인 함수라 사실 gpt의 도움을 크게 받았…ㅎ
파이썬에서 supabase sql 함수 실행해서 데이터 가져오기: rpc()
이제 함수를 작성했으니 실제 호출을 하고 그 결과를 사용하자.
서버 코드로 돌아왔다. 서버는 파이썬 flask로 서버를 만들었다.
후…근데 여기서 빠져나오는 데까지 정말 한참 걸렸다. supabase-python 문서는 좀…불친절하다. 이렇다 할 명확한 설명도 없고. 더군다가 rpc() 부분은 여기저기 다 타고 들어가야 찾을 수 있게 해뒀다. 그것도 postgresql관련 함수 작성만 해두고, rpc() 관련해서는 그닥..
앞으로 개발에 쓸 툴을 먼저 정하게 되면 관련 공식문서 보고 예제 잘 나와있는 언어로 시작해야겠다고 결심했다.
response = supabase.rpc("함수이름", {'파라미터 이름': 넘겨줄 친구 }).execute().data마지막 data를 안붙였는데 이걸 알려주는 곳이 없엉(내가 못찾았을 수도 있음)… data 꼭 붙이시길.
자 이제 다시, 예시1의 함수로 돌아가서 서버에서 조선|제도를 넣어줬다. 근데 None이 리턴된단 말이지. 다른 sql 쿼리를 작성해서 테스트했는데 분명 자료는 있다.
'ㅇㅇ이건 그럼 데이터 베이스 함수 문제임.'
...이라고 생각했는데 진짜 그럴까?
공백 하나로 결과의 유무가 달라진다.
처음 정상적으로 코드를 작성했을 때 계속 None이 리턴되었다. 아니 도대체 어떻게 그럴 수 있냐. 그래서 계속 코드를 쳐다보고… 밥먹고 쳐다보고… 산책 갔다가 쳐다보고…
그러다 DB에 있는 함수에서 발견했다. 공백을.
'아...진짜 이거 때문이겠다'싶었다.
WHERE words."word" ILIKE ANY (SELECT
unnest(string_to_array(search_term, ' | ')));# search=word1+word2+word3
@app.route('/posts', methods=['GET'])
def get_posts():
search_terms = request.args.get('search').split(" ")
if search_terms:
search_query = ' | '.join(search_terms)
response = supabase.rpc("search_word", {'search_term': search_query}).execute().data
return response
else:
print("search_terms is empty")
response = supabase.table("files").select("*").execute().data
return response…ㅎ…결과가 나오네? 결과가 나와서 좋은데 안좋아요😭
알고보니 내가 분리 기준인 파이프 양쪽으로 공백을 두었다. 그래서 조선 | 제도와 조선|제도를 했을 때 결과가 완전히 다르게 나온다.
아래 코드에서는 string_to_array('조선|제도', ' | ')이 함수가 ' | '를 구분 기호로 사용하여 문자열 '조선|제도'를 분할하려고 시도한다. 문제는 내가 넣은 '조선|제도'의 | 주위에 공백이 없으므로 이 함수는 문자열을 분할하지 않고 전체 문자열을 단일 배열 요소로 처리하게 된다.
SELECT *
FROM words
WHERE words."word" ILIKE ANY (SELECT
unnest(string_to_array('조선|제도', ' | ')));아래의 경우는 그런 점에서 기준으로 정확하게 구분이 가능하다. string_to_array('조선 | 제도', ' | ')는 구분 기준이 되는 기호와 정확히 일치하므로 문자열 '조선 | 제도'를 두 요소('조선', '제도')로 올바르게 분할하고 결과로 나온 배열의 각 요소가 ILIKE 비교에 사용된다.
SELECT *
FROM words
WHERE words."word" ILIKE ANY (SELECT
unnest(string_to_array('조선 | 제도', ' | ')));결국 데이터베이스 함수가 문제였던 것이 아니라 내가 서버에서 |로 검색어들을 묶어주는 과정에서 발생한 문제였다.
결론 = 손이 무의식적으로 움직이면 나중에 겉잡을 수 없이 후회한다ㅎ
참고한 자료
- postgresql 문서: https://www.postgresql.kr/docs/10/sql-createfunction.html
- 함수 관련 Supabase 문서: https://supabase.com/docs/guides/database/functions
- rpc() 관련 내용: https://supabase.com/docs/reference/javascript/rpc
애증의 데이터베이스.
하지만 결국은 내 잘못.
