Index를 쓰는 이유
Member Table
| id | last_name | first_name | password | created_at | uuid |
|---|
SELECT *
FROM member
WHERE uuid = 'uuid'Case 1. 만약 uuid에 index가 걸려있지 않다면?
full scan으로 찾아야 한다.
Time Complexity: O(N)
Case 2. 만약 uuid에 index가 걸려있다면?
Time Complexity: O(logN) (B-tree based index)
Index를 쓰는 이유는 특정 조건을 만족하는 데이터들을 빠르게 조회하기 위해서이다.
또한 데이터들을 빠르게 ordering, grouping 할 수 있다.
Index를 적용하는 법
Player Table
| id | name | team_id | backnumber |
|---|
1. 이미 생성된 테이블에 indexing
# 1. 이름으로 선수 조회. 동명이인이 있을 수도 있다. 유니크한 조회 x
SELECT * FROM player WHERE name = 'name'
# 2. team_id, backnumber로 선수 조회, 같은 팀에서는 등번호가 유니크하게 배정된다. 아래의 조건으로 인해 선수를 유니크하게 조회 가능
SELECT * FROM player WHERE team_id = 105 and backnumber = 7
# 1. CREATE INDEX {index_nmae} ON {table_name} (attribute_name);
CREATE INDEX player_name_idx on player (name);
# 2. CREATE UNIQUE INDEX {index_nmae} ON {table_name} (attribute_name1, attribute_name2);
*CREATE UNIQUE INDEX* team_id_backnumber_idx ON player (team_id, backnumber);2. 테이블을 생성할 때 indexing
CREATE TABLE player (
id INT PRIMARY KEY,
....
INDEX player_nmae_idx (name),
UNIQUE INDEX team_id_backnumber_idx (team_id, backnumber)
);🔎 추가 참고
- primary key에는 index가 자동 생성 된다.
- multicolumn index/composite index: 두개 이상의 attribute로 구성된 index
B-tree 기반의 index가 동작하는 방식
INDEX(attribute1)
| attribute1 | ptr |
|---|---|
| 1 | |
| 2 | |
| 2 | |
| 3 | |
| 5 | |
| 7 | |
| 7 | |
| 7 | |
| 9 | |
| 13 |
MEMBERS
| attribute1 | attribute2 | attribute3 |
|---|---|---|
| 3 | ||
| 7 | ||
| 1 | ||
| 2 | ||
| 9 | ||
| 7 | ||
| 13 | ||
| 5 | ||
| 7 | ||
| 2 |
MEMBERS의 attribute1에 대해 index를 만들게 되면 위쪽 테이블과 같은 INDEX table이 생성된다.
- attribute1에 대한 값들이 정렬이 된 상태로 저장이 된다.
- pointer은 실제 Members table에 있는 튜플을 가리키고 있다.
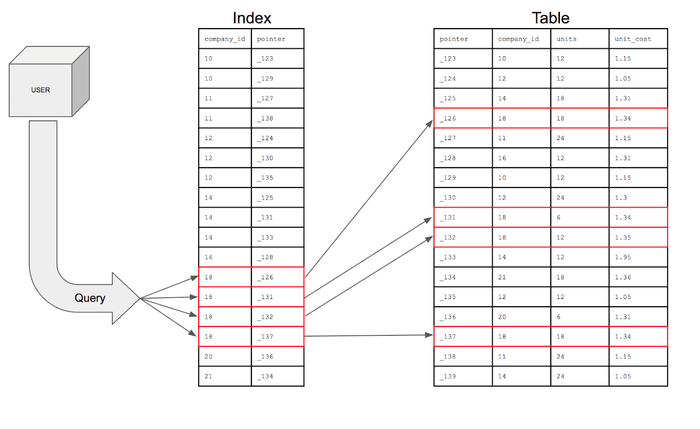
- WHERE attribute1 = 9;
위와 같은 조건을 가진 튜플을 찾을 때 일어나는 과정
- Index 테이블에서 binary search하여 조건을 만족하는 튜플을 찾아간다.
- Index 테이블의 가운데 값을 잡아 조건과 비교한다. (5와 9 비교)
- 9가 5보다 더 크기 때문에 5이하의 값은 찾아야 하는 범위에서 제외한다.
- 남은 부분에서 가운데 값을 다시 골라 조건과 비교한다 (7과 9를 비교한다. )
- 9가 7보다 더 크기 때문에 7이하의 값은 찾아야 하는 범위에서 제외한다.
- Index 테이블의 가운데 값과 9를 비교 (9와 9 비교)
- 만족 하는 조건을 찾았으므로 포인터를 사용하여 실제 Members 테이블에 있는 튜플이 선택된다
- attribute1 = 9인 또다른 튜플이 있을 수도 있기 때문에 9위쪽의 값을 확인하다.
- 9위의 값은 13으로 위쪽을 다시 확인할 필요가 없어진다.
- WHERE attribute1 = 7 AND attribute2 = 95;
위와 같은 조건을 가진 튜플을 찾을 때 일어나는 과정
- Index 테이블에서 binary search하여 조건을 만족하는 튜플을 찾아간다.
- Index 테이블의 가운데 값을 잡아 조건과 비교한다. (5와 7 비교)
- 7이 5보다 더 크기 때문에 5이하의 값은 찾아야 하는 범위에서 제외한다.
- Index 테이블의 가운데 값과 7를 비교 (7와 7 비교)
- attribute2와도 같은지 확인이 필요하기 때문에 포인터를 사용하여 실제 테이블에 있는 튜플의 attribute2값과 비교한다.
- 조건을 만족하는 튜플이 여러개가 있을 수 있기 때문에 위/아래로 다시 확인이 필요하다
❗attribute1에 대해서는 index로 인한 빠른 검색이 가능하지만, attribute2에 대해서는 full scan이 일어난다.
실제 서비스를 운영할 때, 2번 조건의 앞조건을 만족하는 데이터들이 수천 수만개가 될 수 있다 → 성능저하 발생
해결책: attribute1, attribute2를 하나로 묶은 index를 추가해야 한다.
INDEX(attribute1, attribute2)
| attribute1 | attribute2 | ptr |
|---|---|---|
| 1 | 92 | |
| 2 | 92 | |
| 2 | 93 | |
| 3 | 100 | |
| 5 | 81 | |
| 7 | 78 | |
| 7 | 80 | |
| 7 | 95 | |
| 9 | 80 | |
| 13 | 100 |
MEMBERS
| attribute1 | attribute2 | attribute3 |
|---|---|---|
| 3 | 100 | |
| 7 | 78 | |
| 1 | 92 | |
| 2 | 93 | |
| 9 | 80 | |
| 7 | 95 | |
| 13 | 100 | |
| 5 | 81 | |
| 7 | 80 | |
| 2 | 92 |
1차적으로 attribute1를 기준으로(첫번째 순서) 정렬 후, 값이 같다면 attribute2 기준으로 정렬한다.
WHERE attribute1 = 7 AND attribute2 = 95;
Rtry: 위와 같은 조건을 가진 튜플을 찾을 때 일어나는 과정
-
Index 테이블에서 binary search하여 조건을 만족하는 튜플을 찾아간다.
-
Index 테이블의 가운데 값을 잡아 조건과 비교한다. (5와 7비교)
-
7이 5보다 더 크기 때문에 5이하의 값은 찾아야 하는 범위에서 제외한다.
-
Index 테이블의 가운데 값과 7를 비교 (7와 7 비교)
일치 하므로 다시 index의 attribute2값과 조건의 attribute2값을 비교 (95와 95 비교)
일치 하기 때문에 포인터를 이용하여 실제 테이블의 튜플이 선택된다.
-
조건을 만족하는 다른 튜플들이 있을 수 있으므로 위/아래로 다시 확인한다.
-
위쪽은 9로 7보다 크기 때문에 검색대상에서 제외한다.
-
아래쪽 값과 조건의 값이 7로 동일하므로 attribute2을 비교한다.
index의 값 (80)이 조건의 값(95) 보다 작으므로 아래의 영역을 검색조건에서 제외한다.
WHERE attribute2 = 95;
위의 조건은 INDEX(attribute1, attribute2)로 검색해도 의미가 없다.
INDEX(attribute1, attribute2)는 attribute1기준으로 정렬되어 있기 때문에 attribute2는 사실상 정렬이 안 되어 있다.
→ B에 대한 index가 따로 필요하다.
Index 주의 사항
index를 생성할 때마다 그 index를 위한 부가적인 데이터들이 생성이 된다.
이로 인해 발생하는 문제점
- 실제 table에 write(insert/update/delete)할 때마다 index도 변경이 된다.
즉 변경에 따른 재정렬로 인한 오버헤드가 발생한다. - 추가적인 저장 공간을 차지한다. 따라서 불필요한 index를 만들지 말아야 한다.
Covering index
| team_id | backnumber | ptr |
|---|
SELECT team_id, backnumber FROM player WHERE team_id = 5;조회하는 attribute(s)를 index가 모두 cover할 때 조회 성능이 더 빠르다. (실제 테이블까지 갈 필요가 없어짐)
English version
https://www.notion.so/CS-1cb670a451c64ba9ac54b0723c58f5c0?p=f101bc664c2046039f8d78f6cbcb09b7&pm=s
📁 Reference
https://youtu.be/IMDH4iAQ6zM?si=g-UuKKcRULxFcxHD
