작년에 sqld 준비할 때 계층형 쿼리 처음 공부했었다. 계층형 쿼리를 이해하더라도 명확하게 설명하는 건 쉽지 않은 것 같다. sqld 준비할 때 직접 계층형 쿼리로 실습해보면서 이해했다. 인터넷이나 유튜브에서 설명을 아무리 들어도 원리 이해가 확 되지 않았기 때문이다. 한번 내식대로 최대한 쉽고 명료하게 정리해봤다.
📖 쿼리
SELECT EMPLOYEE_ID, FIRST_NAME, LAST_NAME, MANAGER_ID
FROM employees;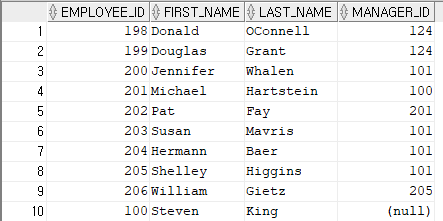
SELECT LEVEL, EMPLOYEE_ID, FIRST_NAME, LAST_NAME, MANAGER_ID
FROM employees
START WITH MANAGER_ID IS NULL
CONNECT BY PRIOR EMPLOYEE_ID = MANAGER_ID
ORDER SIBLINGS BY EMPLOYEE_ID ASC;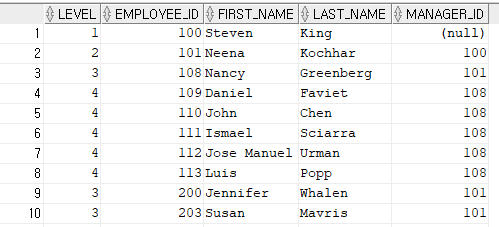
📖 원리
규칙 #0
규칙에 따라 row를 한줄씩 뽑아서 위에서부터 놓는다고 생각한다. 이미 뽑힌 row는 또 뽑히지 않는다.
규칙 #1
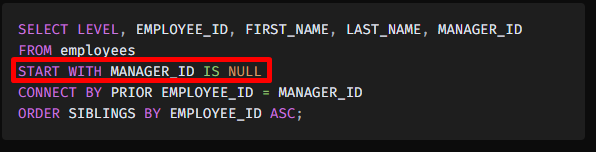
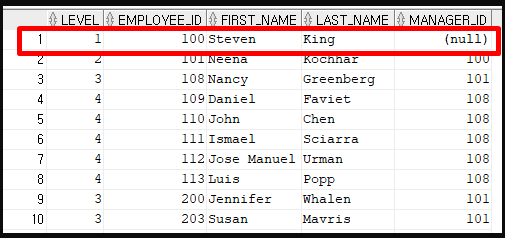
처음에 START WITH 조건에 부합하는 row를 뽑는다.
규칙 #2
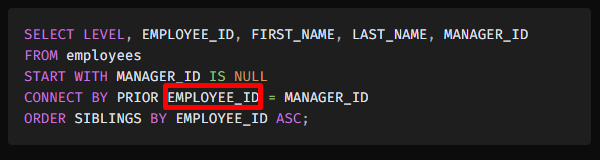
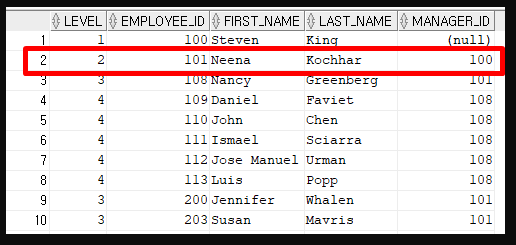
PRIOR 쪽 컬럼 자리에 뽑은 row의 컬럼 값을 넣는다.
그러고나서 해당 조건을 만족하는 row을 다음으로 뽑는다.
이 경우에는 100 = MANAGER_ID가 된다.
규칙 #3
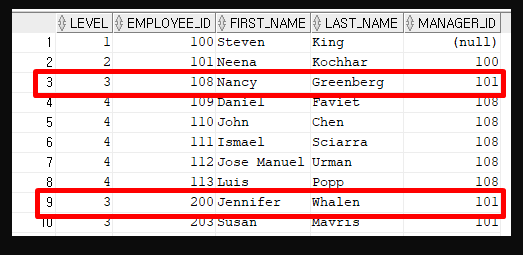
위의 과정을 반복하는데 조건을 만족하는 row가 여러개일 경우가 있다. 이럴 때에는 ORDER SIBLINGS BY 조건에 따라 다음에 뽑을 row를 결정한다.
규칙 #4
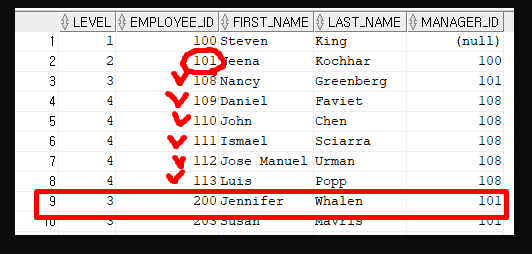
규칙 #2를 만족하는 row가 없을 시에는 기준이 되는 row를 한줄 위로 올려서 찾는다.
위 이미지는 8번째 row까지 뽑고 9번째 row를 뽑는 상황이다.
9번째 row는 8번째 row의 employee_id인 113을 manager_id로 갖는 row가 되어야하지만 해당 row가 없으므로 7번째 row를 기준으로 뽑는다. 하지만 7번째 row의 employee_id인 112를 manager_id로 갖는 row도 존재하지 않으므로 기준 row를 한줄 올린다. 이런식으로 올려서 2번째 row까지 가게 된다.
그렇게 2번째 row의 employee_id인 101을 manager_id로 갖는 row가 9번째 row로 뽑히게 된다.
