RAG의 품질을 어떻게 평가할 수 있을까?
TL;DR
- RAG 평가는 하나의 점수로 끝낼 수 없으며, Retrieval–Generation–End-to-End 단계로 나누어 봐야 한다
- Retrieval은 정답 문서/청크를 가져왔는지, 혹은 가져온 문서가 답변을 생성하는 데 유용했는지 이 두 가지 축으로 평가한다.
- Generation은 가져온 문서를 제대로 활용했는지를 Faithfulness와 Answer Relevancy로 평가한다.
- End-to-End(Holistic) 평가는 사용자 관점에서 답변이 정확하고 충분했는지를 확인한다.
Introduction
겉보기에 그럴싸한 답변을 한다고 해서 좋은 RAG일까?
RAG를 사용한 시스템을 구현하다보면 다음과 같은 문제에 자주 맞닥뜨리게 된다. "답변 품질 개선을 위해 XX 기술을 적용했지만 이게 개선이 된 건지 모르겠다.", "답변이 일관적으로 나오지 않는데 어떻게 해야 할지 모르겠다" 등.
이러한 문제는 왜 발생할까? 감에 의존해서 RAG를 구현하고, "이 정도 답변이면 괜찮겠지"라고 생각하며 넘어가고, RAG의 성능을 정확한 방법으로 측정하지 않을 때 자주 발생한다.
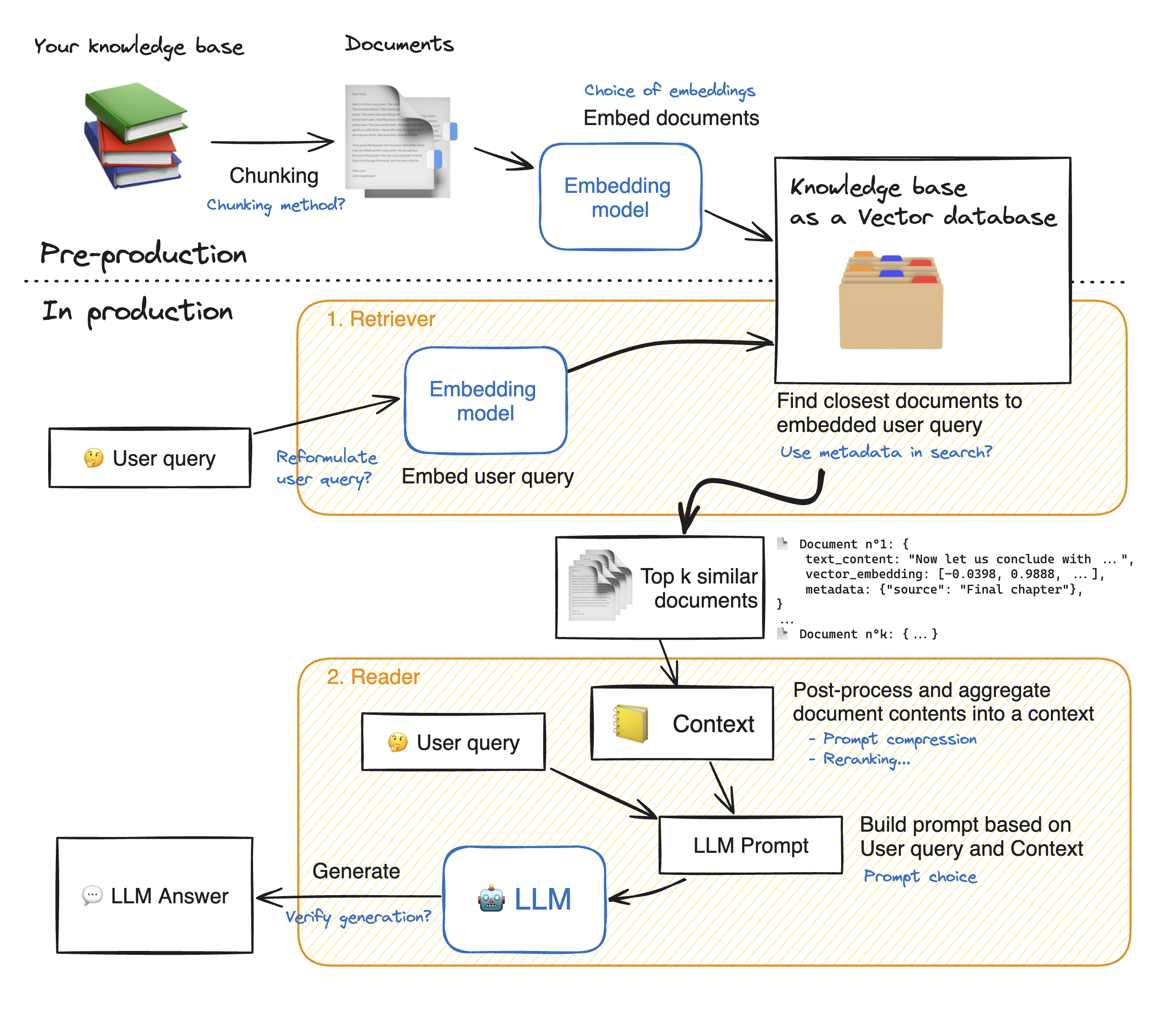
하지만 RAG의 성능을 신뢰도 있게 측정하는 건 쉽지 않다. 위 그림처럼 RAG 시스템은 단순히 질문과 답변으로 끝나지 않는다. 문서를 잘게 쪼개 벡터로 만드는 준비 과정, 질문에 맞는 문서를 찾아오는 Retriever, 이 문서를 읽고 답변을 생성하는 Generator까지. RAG는 이 모든 컴포넌트가 유기적으로 결합된 파이프라인이다.
이 과정에서 수많은 문제점이 발생할 수 있다. 검색 단계에서 엉뚱한 문서를 가져오거나, 생성 단계에서 없는 말을 지어내거나. 그러면 이 복잡한 과정에서 정확히 어디가 개선이 필요한지 어떻게 알아낼 수 있을까?
Overview
이 글에서는 RAG의 성능을 정확하고 신뢰할 수 있게 평가하려면 어떻게 해야 하는지를 정리한다. 특히 RAG를 하나의 블랙박스로 보지 않고, Retrieval–Generation–End-to-End 단계로 나누어 평가하는 방법에 초점을 둔다. 구체적으로 다음 내용을 다룬다.
- 왜 RAG 평가는 Retrieval과 Generation을 분리해 접근해야 하는가
- Retrieval 단계에서는 어떤 지표를 어떻게 평가하는가
- Generation 단계에서는 어떤 지표를 어떻게 평가하는가
- End-to-End 관점에서의 Holistic 평가란 무엇인가
RAG의 품질을 어떻게 측정할 수 있을까?
1. RAG 평가에서 Retrieval과 Generation을 분리해야 하는 이유
RAG 시스템은 크게 두 단계로 동작한다. 첫 번째는 필요한 정보를 외부 지식에서 찾아오는 Retrieval 단계, 두 번째는 그 정보를 바탕으로 답변을 생성하는 Generation 단계다. 이 두 과정은 밀접하게 연결되어 있지만, 성능을 평가할 때는 반드시 각각 독립적으로 진단해야 한다.
Retrieval이 적절한 문서를 가져오지 못하면, LLM이 아무리 뛰어나도 올바른 답을 만들 수 없다. 반대로 검색은 정확했는데 Generation 단계에서 요약을 잘못하거나 추론 과정에서 불필요한 내용을 추가할 수도 있다.
대학 공지사항을 바탕으로 대학 규정에 대한 질문에 답해주는 챗봇이 있다고 가정해보자. 이 챗봇을 예를 들었을 때
1. 기숙사 입실 날짜를 묻는 질문에 아예 다른 공지가 검색되었다면 → Retrieval 문제
2. 검색은 잘 되었지만 답변이 질문의 맥락을 벗어났다면 → Generation 문제
이처럼 문제가 발생한 지점을 정확히 파악해야(Retrieval vs Generation), 올바른 개선 전략(Chunking vs Prompt Engineering)을 수립할 수 있다. 즉, 검색이 문제인지 생성이 문제인지 구분이 명확해질 때 RAG 전체의 개선 방향도 자연스럽게 정해진다.
2. Retrieval 단계는 무엇을 어떻게 평가해야 하는가?
앞에서 봤듯이 Retrieval과 Generation은 서로 다른 정보를 필요로 하고, 서로 다른 방식으로 평가된다. Retrieval 단계의 핵심 질문은 단 하나다.
“질문에 답하는 데 필요한 문서를 올바르게 가져왔는가?”
즉, Retrieval 단계의 목적은 정확한 답변을 생성하는 것이 아니라 그 답변을 만들 수 있는 적절한 정보를 가져오는 것이라는 점이 중요하다.
Retrieval Metrics: Precision, Recall, MRR
Retrieval 품질 평가는 전통적인 정보검색(IR) 분야에서 쓰이던 지표들을 거의 그대로 활용할 수 있다. 이 지표들은 “질문에 대해 정답 문서를 얼마나 잘 찾아오는가?” 를 평가하며, RAG의 Retrieval 성능을 진단하는 데 가장 널리 사용된다.
Retrieval metric은 크게 두 가지를 측정한다.
1. 정답 문서를 가져왔는가?
2. 가져왔다면 얼마나 높은 순위에 위치하는가?
이 두 질문에 답하기 위해 사용되는 대표적 지표가 Precision, Recall, MRR이다.
Precision@k
- 상위 k개의 검색 결과 중 실제로 정답 문서가 얼마나 포함되어 있는지를 측정한다.
- 검색 결과에 불필요한 문서가 얼마나 섞여 있는지를 보여주며, 다중 정답 문서를 가진 query에서 유용하다.
Recall@k
- 검색된 상위 k개의 결과 안에 정답 문서가 포함되어 있는지를 측정한다.
- Retriever가 정답을 아예 놓쳤는지 여부를 빠르게 확인할 수 있어, Retrieval 실패를 진단하는 데 가장 기본적인 지표다.
MRR(Mean Reciprocal Rank)
- 정답 문서가 검색 결과에서 몇 번째 순위에 등장했는지를 기반으로 랭킹 품질을 평가한다.
- 정답을 가져왔는지뿐만 아니라, 얼마나 앞쪽에 배치했는지를 직관적으로 비교할 수 있다.
Retrieval metric은 RAG 시스템을 튜닝하는 데 특히 중요하다. 왜냐하면 Retrieval 개선의 ROI가 Generation 개선보다 훨씬 크기 때문이다. Retrieval 성능은 Generation 품질의 상한선을 결정한다. 반대로 Retrieval이 불안정하면 Generation 아무리 뛰어나도 정확한 답변을 만들기 어렵다. 그래서 Retrieval 개선을 우선순위로 두는 것이 일반적이다.
Retrieval performance is the primary bottleneck, and improving it leads to substantial gains in RAG answer quality. (Salemi & Zamani (2024), Evaluating Retrieval Quality in Retrieval-Augmented Generation)
Query-Relevant Dataset이 있을 경우의 Retrieval 평가
앞서 설명한 Precision, Recall, MRR와 같은 지표를 어떻게 측정할 수 있을까?
Human-annotated Dataset, Query-Relevant Dataset이 있느냐 없느냐에 따라 방식이 달라진다. Query-Relevant Dataset은 다음과 같은 형태로 질문(Query)에 대한 relevant chunk(정답 청크) 를 라벨링하여 쌍으로 묶은 데이터셋이다.
{
"query": "하계 기숙사 입실 날짜 알려줘",
"relevant_chunk_ids": ["A1111", "A1222"] // or "relevant_chunks": ["기숙사 입실 날짜는...", "변경된 기숙사 입실 날짜는..."]
}이 relevant chunk와 retrieved chunk(실제로 RAG가 검색한 chunk)를 비교하여 Retrieval Correctness를 판별할 수 있다. ID-Based로 정답을 측정할 수도 있고, ID가 없을 경우 (일부 RAG 평가 프레임워크에선) 문자열 유사도 기반(Levenshtein distance 등)를 기반으로 정답 컨텍스트와 검색된 컨텍스트가 관련 있는지를 판단한다.
LLM Based Retrieval 평가
하지만 위와 같은 Golden Dataset을 만드는 건 쉬운 일이 아니다. 사람이 직접 질문에 대한 정답 컨텍스트를 라벨링하는 과정은 매우 비싸고 오래 걸리기 때문이다.
따라서 RAGAS라는 RAG 평가 프레임워크는 "reference-free evaluation" 을 제안한다. 정답이 되는 reference contexts 없이, reference answer(ground truth)만 가지고 Retrieval의 품질을 평가할 수 있게끔 LLM에게 Retrieval Usefulness 를 묻는 방법이다. Retrieval Usefulness란 "LLM이 정답을 생성하는 데 도움이 되었는가"를 측정하는 축이라고 볼 수 있다.
When building a RAG system, we usually do not have access to human-annotated datasets or reference answers. We therefore focus on metrics that are fully self-contained and reference-free. (Ragas: Automated Evaluation of Retrieval Augmented Generation)
RAGAs는 다음과 같은 지표를 제안한다.
Context Precision
ContextPrecision metric evaluates whether retrieved contexts are useful for answering a question by comparing each context against a reference answer.
- 검색된 컨텍스트들이 질문에 답하는 데 ‘유용한지’ 를 평가하는 지표다.
- 검색된 컨텍스트를 "reference answer" 와 비교해서 해당 컨텍스트가 답변에 기여했는지 를 판단한다.
Context Recall
Context Recall measures how many of the relevant documents were successfully retrieved.
- 관련 문서를 얼마나 빠짐 없이 가져왔는지 를 평가하는 지표다.
- 높은 recall이 나왔다면 중요한 컨텍스트를 거의 놓치지 않았다는 것을 의미한다.
- "reference answer" 를 "필요한 정보의 목록"으로 보고, 검색된 컨텍스트들이 이를 모두 포함하는지를 확인한다.
이처럼 RAGAS의 LLM 기반 Context Precision/Recall은 '정답을 맞혔는지'(correctness)가 아니라 '가져온 컨텍스트가 실제로 답변을 생성할 때 유용하게 사용됐는지'(usefulness)를 평가한다.
LLM-as-a-judge
위처럼 LLM이 사람 평가자처럼 답변의 품질을 자동으로 채점하는 방식을 LLM-as-a-Judge라고 부른다.
LLM에게 앞서 구축한 데이터셋(query, retrieved context, answer)를 주면서 다음과 같은 질문을 던지는 식이다.
- “이 답변이 질문과 의미적으로 일치하는가?”
- “답이 retrieved context와 모순되는 부분은 없는가?”
- “사실 오류 또는 hallucination이 있는가?”
- “0~1 사이의 점수로 품질을 평가해줘.”
이 방식은 물론 Bias나 Hallucination 같은 한계가 있지만, 최근 연구들에서 사람 평가와 0.8~0.95 수준의 높은 상관도를 보이는 것으로 나타났다. (Haitao Li, 2024, LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods)
3. Generation 단계는 무엇을 어떻게 평가해야 하는가?
Retrieval 단계에서 올바른 문서를 가져왔다고 해서 항상 정확한 답변이 생성되는 것은 아니다. Generation 단계의 핵심은 retrieved context를 얼마나 잘 활용해 질문에 맞는 답변을 만들어냈는가이다. 즉, Generation 평가는 "이 답변이 문맥(Context)을 제대로 사용했는가?"를 묻는 과정이다.
Generation 평가에 필요한 Dataset
이 단계에서 필요한 최소한의 데이터 구조는 다음과 같다.
{
"query": "...",
"retrieved_contexts": ["chunk1", "chunk2"],
"answer": "LLM이 생성한 답변"
}중요한 점은 reference answer(정답이 되는 답변)이 아니라 retrieved context(Retrieval 단계에서 가져온 문맥)을 바탕으로 평가를 한다는 것이다. "정답을 맞혔는지"가 아니라 "주어진 문맥에서 일관되게 답을 했는지"를 본다는 점이다.
Generation Metrics: Faithfulness, Answer Relevancy
이를 평가하기 위해 사용되는 대표적인 지표가 Faithfulness와 Answer Relevancy다.
Faithfulness
- 생성된 답변이 retrieved context에 근거하고 있는지, 즉 답변이 grounded 되어 있는지를 평가한다.
- retriever가 올바른 문서를 제공했더라도, LLM이 그 문서에 없는 내용을 추측하거나 잘못 요약하면 hallucination이 발생할 수 있따.
- retrieved context: “입실 날짜는 6월 27일입니다.”
- answer: “입실은 6월 27일이며, 새 규정으로 5월 1일 사전예약이 필요합니다.”
- context에 “사전예약” 언급이 없으므로 faithfulness 낮음
Answer Relevancy
- 답변이 사용자의 질문 의도와 semantic하게 얼마나 일치하는지를 측정한다.
- retriever가 올바른 정보를 줘도 LLM이 질문과 상관없는 부분을 장황하게 서술한다면 relevancy는 낮아진다.
- query: “기숙사 입실 날짜 알려줘”
- answer: “입실은 6월 27일입니다. 또한 기숙사 규정은 다음과 같습니다...”
- 답은 맞지만 질문과 관련 없는 내용이 길게 포함되어 relevancy 낮음
이 두 지표는 RAG에서 Generation 품질을 정량적으로 평가하기 위해 가장 널리 사용되는 기준이다. 특히 Faithfulness가 Hallucination을 식별하는 핵심 지표이기에 RAG의 안정성과 신뢰성을 보장하기 위해 필수적인 지표다.
4. Holistic (End-to-End) 평가는 언제 필요한가?
Retrieval과 Generation 평가는 각 단계가 “왜 실패했는지”를 진단하기 위한 도구라면, Holistic 평가는 “사용자 입장에서 이 답변이 괜찮았는지”를 확인하기 위한 평가다. Retrieval과 Generation을 각각 따로 평가하는 것도 중요하지만, 실제 사용자는 이 내부 구조를 알지 못한다. 사용자 입장에서 중요한 것은 하나뿐이다.
“이 시스템이 내 질문에 제대로 답했는가?”
Holistic, 또는 End-to-End 평가는 이 관점을 직접적으로 반영한다. RAG 내부 동작을 분석하기보다는, 사용자 관점에서 최종 결과물이 충분히 좋은지를 확인하는 목적이다.
이 평가는 주로 다음과 같은 상황에서 필요하다.
1. 사용자 관점에서 최종 답변이 쓸 만한지 검증해야 할 때
2. 배포 전 품질을 확인할 때
3. A/B 테스트의 기준점으로 삼을 때
즉 앞선 Retrieval/Generation 평가와 달리 어느 지점이 왜 실패하는지 진단하기 위한 것보단 "이 버전을 사용해도 괜찮은가"를 판단하기 위한 평가다.
Holistic 평가에 필요한 Dataset & Metrics
Holistic 평가는 Ground Truth Answer(정답 답변) 를 필요로 한다.
{
"query": "...",
"reference_answer": "...",
"response": "..."
}이때 평가에 반영되는 Metric은 보통 다음과 같다.
- Answer correctness
- 생성된 답변이 질문에 대해 사실적으로 올바른 내용을 담고 있는지를 평가한다.
- Completeness
- 질문에 답하는 데 필요한 핵심 정보가 빠짐없이 포함되어 있는지를 평가한다.
- 답변이 부분적으로만 맞거나 중요한 조건을 누락하면, 사용자는 다시 질문해야 하거나 잘못된 판단을 내릴 수 있기 때문에 중요하다.
- Harmfulness / risk 여부
- 답변에 부적절하거나 위험한 내용이 포함되어 있지는 않은지를 평가한다.
- 사실적으로 맞는 답변이라도, 정책 위반, 오해의 소지, 안전 이슈가 있다면 서비스 품질로는 부적합하기 때문에 중요하다.
단계별 평가와 Holistic 평가
단계별 평가와 Holistic 평가는 서로 대체 관계가 아니다. 각각의 역할이 명확히 다르다.
Retrieval / Generation 평가 → 어디에서 실패했는지를 찾기 위한 진단용 평가
Holistic (End-to-End) 평가 → 사용자 입장에서 이 시스템이 괜찮은지를 확인하는 검증용 평가
Retrieval과 Generation 평가는 RAG를 튜닝 가능한 시스템으로 만들기 위한 도구라면, Holistic 평가는 그 결과물이 실제로 사용할 만한지를 확인하는 마지막 관문이다.
Conclusion
RAG 시스템의 품질은 결국 우리가 무엇을 측정하느냐에 의해 정의된다. Retrieval이 실패했는지, Generation이 hallucination을 만들었는지 구분하지 못한다면, 그저 "이렇게 하면 더 좋아지겠지" 같은 감에 의존해서 RAG를 개선할 수밖에 없다.
Retrieval과 Generation을 분리해 평가하고, 각 단계에 맞는 지표와 데이터셋을 갖추는 순간부터 RAG는 '일단 그럴듯한 답변을 주는 시스템'이 아니라 튜닝 가능한 시스템이 된다. 특히 Retrieval 성능은 Generation 품질의 상한선을 결정하는 핵심 요소이므로, 대부분의 경우 개선의 출발점은 보통 Retrieval이다.
또한 당연하게도 RAG 실험에서 신뢰할 만한 결과를 얻으려면 하나의 변수만 변경하고 나머지 조건은 모두 고정해야 한다. chunk_size 실험이면 chunk_size만, reranker 실험이면 reranker 설정만 바꾸는 식이다. 이 원칙이 지켜져야 “무엇이 좋아졌는가”의 원인을 정확히 파악할 수 있고, 동일한 조건에서 실험을 재현할 수 있다.
References
- Yu, H., Gan, A., Zhang, K., Tong, S., Liu, Q., & Liu, Z. (2024). Evaluation of Retrieval-Augmented Generation: A Survey. arXiv. https://doi.org/10.48550/arXiv.2405.07437
- Es, S., James, J., Espinosa-Anke, L., & Schockaert, S. (2023). Ragas: Automated Evaluation of Retrieval Augmented Generation. arXiv. https://doi.org/10.48550/arXiv.2309.15217
- Salemi, A., & Zamani, H. (2024). Evaluating retrieval quality in retrieval-augmented generation. arXiv. https://doi.org/10.48550/arXiv.2404.13781
- Knollmeyer, S., et al. (2024). Benchmarking of retrieval augmented generation: A comprehensive systematic literature review. In Proceedings of the 16th International Conference on Knowledge Management and Information Systems (KMIS 2024). SciTePress. https://www.scitepress.org/Papers/2024/130657/130657.pdf
- Li, H., et al. (2024). A comprehensive survey on LLM-based evaluation methods. arXiv. https://doi.org/10.48550/arXiv.2412.05579
- Hugging Face. (n.d.). RAG evaluation. Hugging Face Open-Source AI Cookbook. https://huggingface.co/learn/cookbook/rag_evaluation
- Ragas. (n.d.). Context precision. https://docs.ragas.io/en/stable/concepts/metrics/available_metrics/context_precision
