
SELECT > 여러 기준으로 정렬하기
SELECT ANIMAL_ID, NAME, DATETIME
FROM ANIMAL_INS
ORDER BY NAME, DATETIME DESC;- NAME은 오름차순, DATETIME만 따로 내림차순
SELECT > 상위 n개 레코드
SELECT NAME
FROM ANIMAL_INS
ORDER BY DATETIME
LIMIT 1- ✨
LIMIT사용
SUM, MAX, MIN > 중복 제거하기
SELECT COUNT(DISTINCT NAME) AS "count"
FROM ANIMAL_INS
WHERE NAME IS NOT NULL- NAME을 중복 없이 세야 하므로 ✨
DISTINCT를 붙인 후COUNT - NULL인 경우 세지 말아야 하므로 ✨
IS NOT NULL
GROUP BY > 동명 동물 수 찾기
SELECT NAME, COUNT(NAME) as "COUNT"
FROM ANIMAL_INS
WHERE NAME IS NOT NULL
GROUP BY NAME
HAVING COUNT(NAME)>=2
ORDER BY NAMEHAVING은GROUP BY이후에 실행 됨
GROUP BY > 입양 시간 구하기 (1)
SELECT HOUR(DATETIME) HOUR, COUNT(DATETIME) COUNT
FROM ANIMAL_OUTS
GROUP BY HOUR(DATETIME)
HAVING HOUR>=9 AND HOUR<=19
ORDER BY HOUR- ✨
HOUR(DATETIME)을 이용해 DATETIME에서 시간만 추출!
GROUP BY > 입양 시간 구하기 (2)
SET @hour := -1; -- 변수 선언
SELECT (@hour := @hour + 1) as HOUR,
(SELECT COUNT(*) FROM ANIMAL_OUTS WHERE HOUR(DATETIME) = @hour) as COUNT
FROM ANIMAL_OUTS
WHERE @hour < 23처음 보는 개념이라 솔루션 찾았다.
- 데베에 존재 하지 않는 모든 시간대(0시~23시)를 추출해야 함!
- ✨
SET을 이용해 변수명과 초기값 설정 - 변수 선언 뒤에는 ✨
;세미콜론 붙여줘야 함 @: 프로시저가 종료되어도 유지되므로 값을 누적할 수 있음@hour의 초기값을 -1로 설정
-:=대입 연산자SELECT (@hour := @hour + 1)@hour 값을 1씩 증가시키면서 SELECT문 전체를 실행WHERE @hour<23일 때까지 @hour 값이 1씩 증가- ✨ 단일 결과 집계함수를 또 하나의 SELECT 인자로 넣었음
IS NULL > NULL 처리하기
SELECT ANIMAL_TYPE, IFNULL(NAME, "No name"), SEX_UPON_INTAKE
FROM ANIMAL_INS
ORDER BY ANIMAL_ID;- ✨
IFNULL을 이용해서NULL값일 경우 "No name" 출력
ISNULL(칼럼,칼럼이 NULL일경우 대체할 값)
JOIN > 없어진 기록 찾기 (LEFT OUTER JOIN)
OUT에는 있는데 INS에는 없는 것을 찾아야 하므로
OUT을 기준으로 INS와 LEFT OUTER JOIN을 하면 (ANIMAL_ID기준), OUT의 데이터들은 무조건 가져오고 INS에 동일한 ANIMAL_ID가 없는 경우엔 INS 필드관련한 것들은 모두 NULL값으로 나온다.
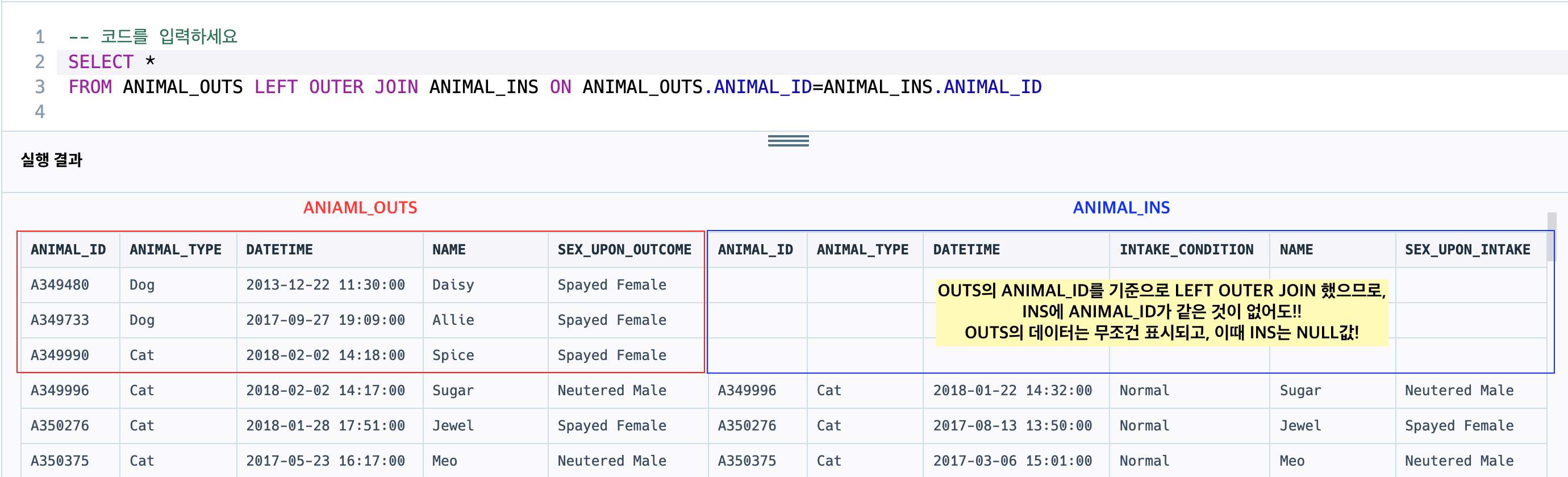
SELECT OUTS.ANIMAL_ID ANIMAL_ID, OUTS.NAME NAME
FROM ANIMAL_OUTS OUTS LEFT OUTER JOIN ANIMAL_INS INS ON OUTS.ANIMAL_ID=INS.ANIMAL_ID
WHERE INS.ANIMAL_ID IS NULL
ORDER BY ANIMAL_IDString, Date > IN
SELECT ANIMAL_ID, NAME, SEX_UPON_INTAKE
FROM ANIMAL_INS
WHERE NAME IN ("Lucy", "Ella", "Pickle", "Rogan", "Sabrina", "Mitty")WHERE 절 내에서 ✨IN을 이용해 특정값 여러개를 선택하는 것이 가능하다!
String, Date > LIKE
SELECT ANIMAL_ID, NAME
FROM ANIMAL_INS
WHERE NAME LIKE '%EL%' AND ANIMAL_TYPE="Dog"
ORDER BY NAME-
'-' : 글자숫자를 정해줌(ex 컬럼명 LIKE '홍_동')
-
'%' : 글자숫자를 정해주지않음(ex 컬럼명 LIKE '홍%')
String, Date > CASE
CASE문법
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
CASEWHENTHENEND기억!
SELECT ANIMAL_ID, NAME,
CASE
WHEN SEX_UPON_INTAKE LIKE '%Neutered%' OR
SEX_UPON_INTAKE LIKE '%Spayed%'
THEN 'O'
ELSE 'X'
END AS 중성화
FROM ANIMAL_INS
ORDER BY ANIMAL_ID
SEX_UPON_INTAKE IN ('%Neutered%' ,'%Spayed%')
이건 안 된다. %, _을 쓰려면LIKE가 있어야 함!
String, Date > DATETIME에서 DATE로 형 변환
- ✨
DATE_FORMAT(DATETIME, '%Y-%m-%d')
SELECT ANIMAL_ID, NAME, DATE_FORMAT(DATETIME, '%Y-%m-%d') as '날짜'
FROM ANIMAL_INS
ORDER BY ANIMAL_IDRank 관련
SELECT empNo, empName, salary,
RANK() OVER (ORDER BY salary DESC) RANK등수
FROM employee;
SELECT empNo, empName, salary,
DENSE_RANK() OVER (ORDER BY salary DESC) DENSE_RANK등수
FROM employee;SELECT empNo, empName, salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) ROW_NUMBER등수
FROM employee;SELECT empName, job, salary,
RANK() OVER (PARTITION BY job ORDER BY salary DESC) RANK등수
FROM employee;-> job 별로 구분 해서 순위 매기기.

👩🏻💻