
📌12주차 학습내용 요약
1. 로지스틱 회귀
- 데이터의 스케일을 시그모이드 함수를 이용하여 0~1 사이로 스케일 설정
- 특정기준으로 데이터를 이진분류(0 or 1)로 결정하는 회귀방식
- ex) 확률이 0.5보다 크면 악성(1), 낮으면 양성(0)

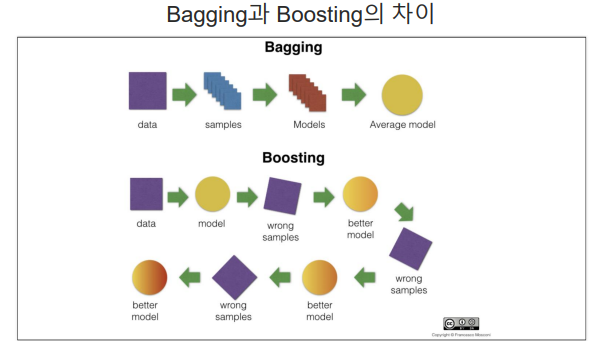
2. 앙상블 - 보팅&배깅
앙상블(Ensemble)
-
여러 개의 분류기를 생성하고 그 예측을 결합하여 정확한 최종 예측을 기대하는 기법
-
다양한 분류기의 예측 결과를 결합함으로써 단일 분류기보다 신뢰성이 높은 예측 값을 얻는 것
보팅(Voting)
-
각기 다른 방식으로 얻은 결과를 통합하여 최종 결정을 함
-
성능이 좋지 않아서 사용하지 않음

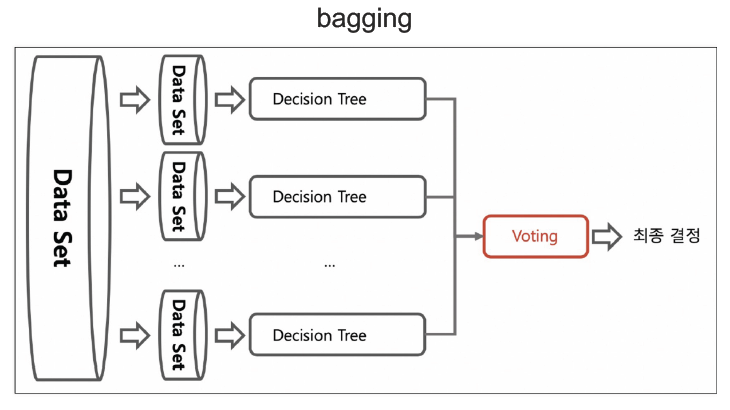
배깅(Bagging=Bootstrap AGGregatING)
-
부스트랩 집계라는 뜻으로, 하나의 방식으로 얻은 결과를 통합하여 최종 결정을 함
-
각각의 분류기에 데이터를 각각 샘플링해서 추출하는 부트스트래핑 방식을 사용함(중복 허용)
최종 결정 방식
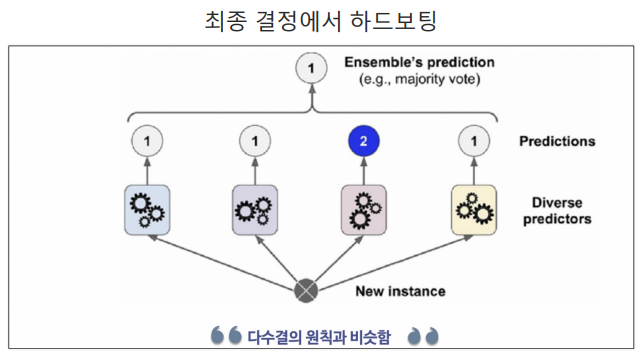
하드보팅(=다수결의 원칙)
- 결과의 갯수가 많은쪽으로 최종결정을 하는 방식
- ex) '1'이 3개, '2'가 1개이므로 최종값은 '1'이다
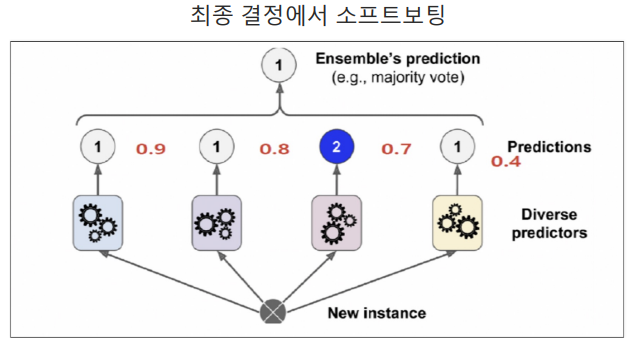
소프트보팅(=확률평균화)
-
각 카테고리의 확률을 산술평균하여 최종결정을 하는 방식
-
단, 동률인 경우 다수결을 따른다.
-
ex) '1'의 확률은 (0.9+0.8+0.4)/3=0.7이고 '2'의 확률은 0.7이므로 동률이므로 다수결에 의해 최종값은 '1'이다.
랜덤포레스트(RandomForest)
-
의사결정나무(DecisionTree)의 집합
-
배깅의 대표적인 방법
-
앙상블 방법 중에서 비교적 속도가 빠르며 다양한 영역에서 높은 성능을 보여주고 있다.
-
최종 결정은 소프트보팅

3. 앙상블 - 부스팅
-
여러 개의 (약한)분류기를 순차적으로 학습을 하면서, 앞에서 틀린 데이터에 대해 학습하고 해당 가중치를 이어 받아서 다음 분류기에 영향을 주는 방식
-
"약한"은 성능은 떨어지지만, 속도가 매우 빠른 것을 의미함
-
에이다부스트(Adaboost), 그래디언트부스트, XGBoost(eXtra Gradient Boost),LightGBM(Light Gradient Boost)등이 있음

Adaboost(Adaptive Boosting)
- 순차적으로 다른 가중치를 부여하여 결과를 도출

GBM(Gradient Boosting Machine)
- AdaBoost 기법과 비슷하지만, 가중치를 업데이트할 때 경사하강법(Gradient Descent)을 사용
XGBoost(eXtra Gradient Boost)
-
GMB에서 PC의 파워를 효율적으로 사용하기 위한 다양한 기법에 채택되어 빠른 속도와 효율을 가짐(GPU사용)
-
트리 기반의 앙상블 학습에서 가장 각광받는 알고리즘 중 하나
-
GBM 기반의 알고리즘인데, GBM의 느린 속도를 다양한 규제를 통해 해결
-
병렬학습이 가능하도록 설계됨
-
반복수행할 때 마다 내부적으로 학습데이터와 검증데이터를 교차검증함
-
교차검증을 통해 최적화되면 반복을 중단하는 조기 중단 기능이 있음
LightGBM
-
XGBoost보다 빠른 속도를 가짐
-
XGBoost와 함께 부스팅 계열에서 각광받는 알고리즘
-
단, 적은 수의 데이터에는 적합하지 않음(일반적으로 10000건 이상의 데이터가 필요함)
-
GPU버전도 존재함
4. SMOTE OverSampling
- 데이터의 불균형이 극심할 때 불균형한 두 클래스의 분포를 강제로 맞추는 작업
- 오버샘플링
- 원본데이터의 피처 값들을 변경하여 증식
- SMOTE(Synthetic Minority Over-sampliing Technique) 방법이 있음
- 적은 데이터 세트에 있는 개별 데이터를 KNN방법으로 찾아서 데이터의 분포 사이에 새로운 데이터를 만드는 방식
- imbalanced-learn 활용
5. Natural Language Processing
- 사람이 사용하는 자연어를 컴퓨터가 이해하고 처리할 수 있도록 하는 기술
- 기계번역, 텍스트 분류, 감성 분석, 정보 추출, 질문 응답 등에 다양한 분야에서 사용됨
- 텍스트 분석, 언어 모델링, 형태소 분석, 구문 분석, 의미 분석, 담화 분석등의 기술을 포함하고 있음
KoNLPy
- Korean Natural Language processing in Python
- 쉽고 간결한 한국어 정보처리 파이썬 패키지
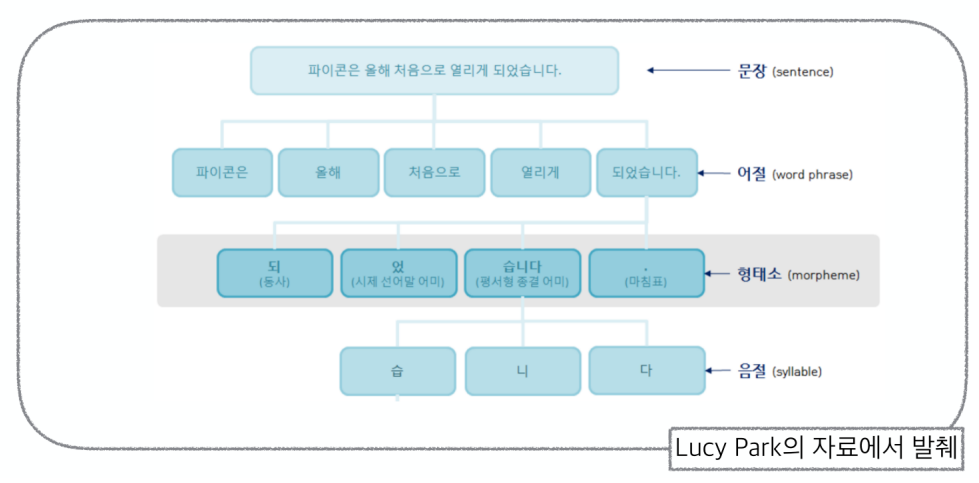
형태소 분석
- 단어의 구조와 형성을 분석하는 데 사용되는 언어학적 방법
- 단어를 형태소라고 하는 의미 있는 가장 작은 단위로 분해하고 이들이 결합하여 다양한 형태의 단어를 만드는 방법을 분석하는 것
워드클라우드
- 특정 텍스트의 단어빈도수를 글자크기로 표현함

감성분석
- 텍스트에서 의견, 감정, 태도와 같은 주관적인 정보를 식별하고 추출
- 기계 학습 알고리즘을 사용하여 긍정적, 부정적 또는 중립적일 수 있는 감정을 기반으로 텍스트 데이터를 분석하고 분류
나이브 베이즈 분류
특성들 사이의 독립을 가정하는 베이즈 정리를 적용한 확률 분류기
문장의 유사도
CountVecotrize
- 문장을 수치 벡터로 변환
- 각 벡터의 거리를 측정하여 유사도 검사
TF-IDF
- Term Frequency-Inverse Document Frequency
- 여러 문서에서 어떤 단어가 문서 내에서 얼마나 중요한 것인지를 나타내는 통계적 수치
중요성에 따른 가중치 부여 - 한 문서에서 자주 등장하는 단어는 중요성 상승
- 모든 문서에서 자주 등장하는 단어는 중요성 하락
6. Principal Component Analysis
- 데이터 집합 내에 존재하는 각 데이터의 차이를 가장 잘 나타내주는 요소를 찾아내는 방법
- 통계데이터 분석(주성분 찾기), 데이터 압축(차원감소), 노이즈 제거 등 다양한 분야에서 사용
- 차원축소와 변수추출 기법으로 사용
- 데이터의 분산을 최대한 보존하면서 서로 직교하는 새 기저(축)을 찾아, 고차원 공간의 표본들을 - 선형 연관성이 없는 저차원 공간으로 변환하는 기법
- 변수추출은 기존 변수를 조합해 새로운 변수를 만드는 기법(변수 선택과 구분됨)
- 기존의 칼럼을 참고하여 주성분을 생성
주성분 1개

주성분 2개

주성분 3개 3D 시각화

PCA eigenface
- 얼굴 사진을 기반으로 주성분 이미지를 도출하고 각 주성분의 가중치로 이미지를 구현할 수 있음
원본데이터

PCA X_inv

주성분 이미지

PCA 가중치 부여로 이미지 구현

7. 추천시스템
콘텐츠 기반 필터링 추천 시스템
- 사용자가 특정 아이템을 선호하는 경우, 그 아이템과 비슷한 아이템을 추천하는 방식
최근접 이웃 협업 추천 시스템
- 축적된 사용자 행동 데이터를 기반으로 사용자가 아직 평가하지 않은 아이템을 예측 평가
- 사용자 기반 : 당신과 비슷한 고객들이 다음 상품도 구매했음
- 아이템 기반 : 이 상품을 선택한 다른 고객들은 다음 상품도 구매했음
- 일반적으로는 사용자 기반보다는 아이템 기반 협업 필터링이 정확도가 더 높음
잠재 요인 협업 필터링
- 사용자-아이템 평점 행렬 데이터를 이용해서 "잠재요인"을 도출하는 것
- 주요인과 아이템에 대한 잠재요인에 대해 행렬 분해를 하고 아직 평점을 부여하지 않은 아이템에 대한 예측 평점을 생성하는 것
