
머신러닝 프로젝트
주제 : Google Analytics Customer Revenue Prediction
개요
- 구글 스토어 마케팅팀은 타겟 프로모션을 진행하기 위해 준비중입니다.
- 구글 스토어의 2년의 훈련 데이터를 활용하여 모델을 만들고 앞으로의 2개월 고객의 수익을 예측하여 프로모션 매출에 기여할 타겟을 예측하라.
목표
데이터 크기
- train : 2016/08/01 ~ 2018/04/30 동안의 로그데이터(23.67GB)
- test : 2018/05/01 ~ 2018/10/15 동안의 로그데이터(7.1GB)
샘플링
- train(40%, row=683,334, col=62)
- test(100%, row=401,589, col=62)
데이터 정보
- 고객들의 로그 데이터
- 구매자는 약 1.1%, 극심한 편향 데이터
절차
- 데이터 이해 및 처리
1-1. 데이터 수집
1-2. 용량 감소
- 피처 엔지니어링
2-1. 전처리
2-2. 파생변수 생성
2-3. 라벨인코딩
2-4. 수익 로그 스케일링
- 분류 모델
3-1. LGBM_CLF
- 회귀 모델
4-1. RF_REG
- RFM 모델
5-1. VIP 세그먼트
세부 내용
1. 데이터 이해 및 처리
데이터 이해
용량감소
- 데이터가 굉장히 큰 대용량 데이터라서 전체를 사용할 수 없다.
- 샘플링을 사용하여 train(40%), test(100%)를 사용하고 csv가 아닌 pickle를 사용한다
- downcasting 사용하여 메모리를 압축한다
2. 피쳐 엔지니어링
전처리
- Json파일을 파싱한 127개 피쳐 중 EDA를 통해 실제 수익 totals_transactionRevenue와 연관성이 매우 떨어지는 칼럼을 배제함 -> 46개 선정
파생변수 생성
- 이커머스 데이터 특성을 활용하여 중요한 파생피처를 생성(상품관심도, 재방문주기, 총 생애주기, 충성도 등)
- 시계열 피쳐(연, 월, 요일, 주) 생성
- 분류모델의 label이 될 구매여부 피처 생성
라벨인코딩
- 대부분의 범주데이터가 명목형이어서 원핫인코딩이 적합하지만 대규모이기 때문에 불가능
- 따라서 라벨인코딩을 사용하고 영향을 덜 받는 트리계열 모델을 사용하기로 결정
수익 로그 스케일링
- 모델에 적용한 수익이 대부분이 매우 낮은 값에 위치해있는 극단적인 Right Skewed분포를 가지고 있었다.
- 왜도 완화를 해결하기 위해 로그스케일링을 적용함
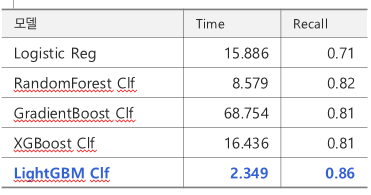
3. 분류모델
LGBM_CLF
- 실제 수익을 그대로 사용하면 모델을
- 극심한 불균형 데이터에서 중요한 것은 구매자를 분류하는 것이므로 recall_1을 평가지표로 결정한다.
- 모든 모델을 비교하였을 때, 트리계열의 성능은 모두 비슷해서 속도에 초점을 두었다.
- LGBM은 스케일러 미적용, Standard, MinMax의 성능도 큰 차이가 없지만, 스케일러를 미적용했을 때 가장 좋았다.
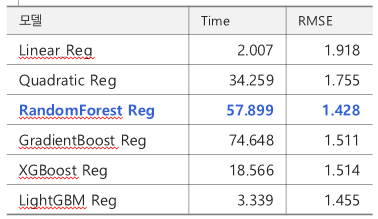
4. 회귀모델
RF_REG
- 분류모델의 TOP10 칼럼과 샘플링데이터로 학습하고 분류모델을 거치고 얻은 데이터 여러 회귀모델을 사용해서 최고의 모델을 선정하였다.
- 예측값과 실제값의 최소 차이를 얻기 위하여 RMSE를 평가지표로 활용했다.
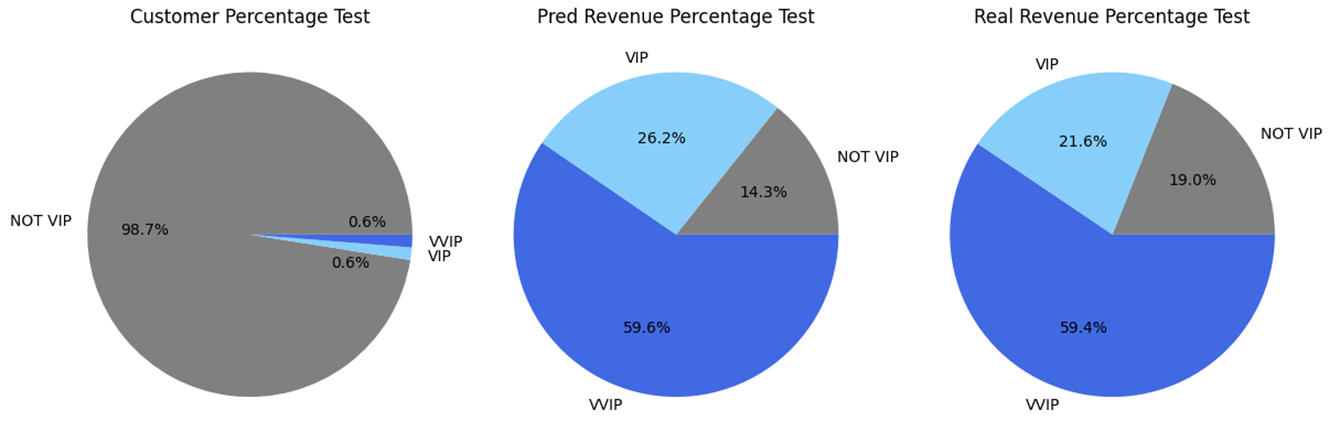
5. RFM 모델
VIP 세그먼트
- 고객별로 R(최근성), F(빈도수), M(구매금액)으로 점수를 매겨서 Not VIP, VIP, VVIP 총 3개의 세그먼트로 분류
- 전체 고객의 실제 수익 합계에서 VIP,VVIP가 80% 이상 차지함을 검증하였다
6. 느낀점
- 이번 프로젝트를 통해서 대용량데이터를 다루는 방법, 스케일링과 Encoder 사용법, 파생변수의 중요성, 각 모델별 강점과 약점, RFM분석에 대해서 학습하였다.
- 강사님께서 온라인 강의로 배운 것보다 프로젝트 하나의 가치가 훨씬 크다고 했는데 그 이유를 몸소 체험한다.
- 타인과 소통하고 정보를 공유하는 것이 굉장히 값진 것이고 모든 단계를 처음부터 기획하는 것이기에 흐름이나 적극성이 단순 온라인 강의보다 차원이 다르다.
- 프로젝트를 진행하면서 막히는 구간이 있으면 책을 사거나 구글링을 통해서 새로 학습하였다. 이러한 방식으로 얻은 지식은 잊혀지지 않고 계속 남을 것이다.
- 다른 건 몰라도 프로젝트는 꼭 하는 것이 나에게 도움이 된다.
