
학습영상: 메타코드-딥러닝 강의 컴퓨터 비전 인식모델 개발 1편
출처: 메타코드M
AI
- 인간의 학습 능력, 추론능력, 지각능력 등을 인공적으로 구현한 컴퓨터 시스템
ML
- 컴퓨터에게 인간의 능력을 학습시키는 알고리즘
- 주로 정형 데이터
DL
- 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화를 시도하는 기계학습 알고리즘의 집합
- 주로 비정형 데이터
ML/DL 프레임워크
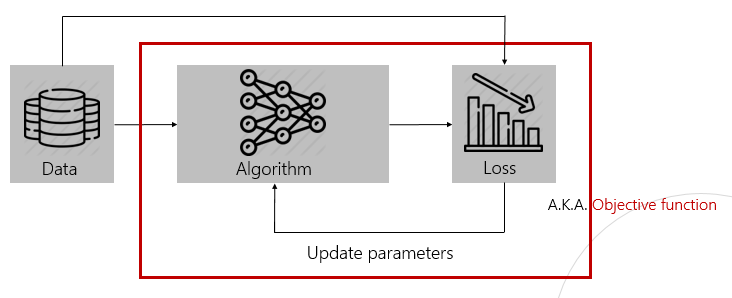
Neural Network
- 활성화 함수 을 통해서 비선형화
- 참값과 예측값을 비교하여 loss 계산
- optimizer 적용
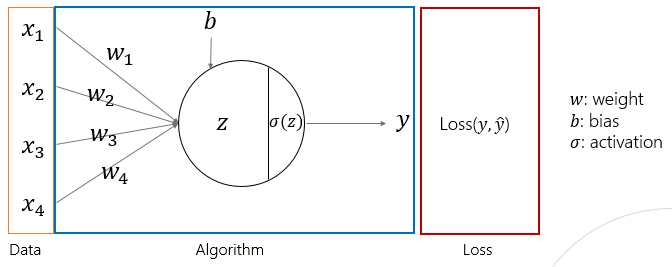
Activation Function
- 역할 : 비선형화
- 주로 ReLU 사용

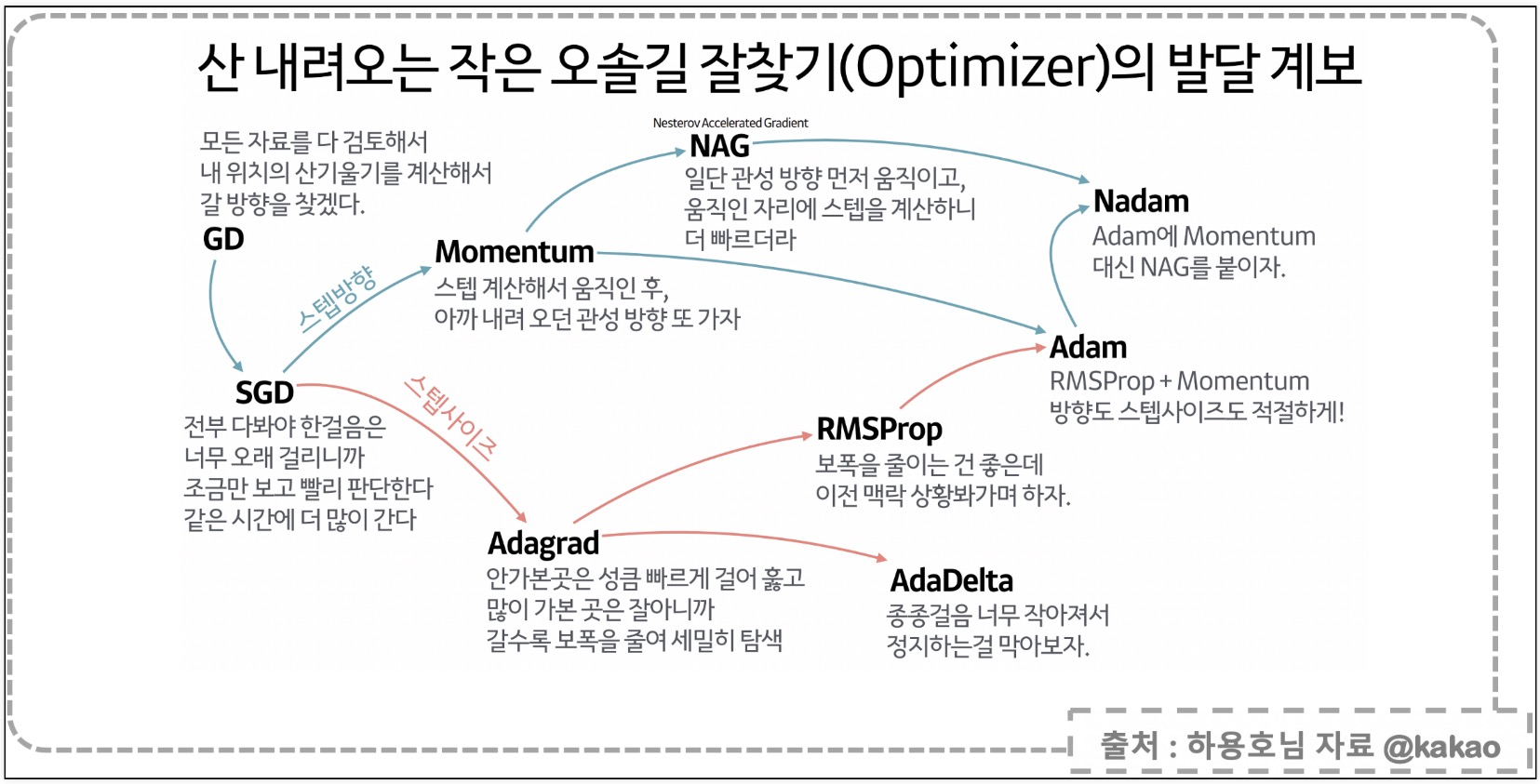
Optimizer
- loss를 최소화 하는 weights를 구하는 optimizer
Gradient Descent
- Loss Function이 아래로 볼록한 형태가 이상적인 경우이고, 이 때, weights를 최적화하기 가장 좋다
- Loss function을 미분하여 weights를 갱신한다
- Learning rate가 너무 큰 경우, 진동이 발생
- 반대로 너무 작은 경우, 굉장히 긴 시간의 학습이 필요


Stochastic Gradient Descent (SGD)
- 기존의 GD는 모든 기울기를 계산했었다
- SGD는 확률적으로 기울기를 계산한다
Momentum
- 기울기 일부를 누적하여 관성을 추가함
velocity = momentum * velocity - learning_rate * gradient
w = w + velocityRoot Mean Square Propagation (RMSProp)
- AdaGrad는 처음에 크게 학습하고, 점점 작게 학습하는데 과거의 기울기를 제곱하기 때문에 갱신값이 점차 0으로 수렴하는 문제가 있었다
- RMSProp은 기하급수적으로 감소하는 평균 제곱 기울기를 사용
- 각 매개변수의 학습률을 이전 기울기의 평균 제곱근(RMS)으로 나누어 큰 기울기에서는 학습률을 낮추고 작은 기울기에서는 높임
cache = decay_rate * cache + (1 - decay_rate) * gradient^2
w = w - (learning_rate / sqrt(cache + epsilon)) * gradientAdaptive Moment Estimation (Adam)
- Momentum과 RMSProp의 결합
- 적응형 학습 속도 및 관성, 효율적인 수렴
- 딥러닝에서 주로 사용하는 optimizer
m = beta1 * m + (1 - beta1) * gradient
v = beta2 * v + (1 - beta2) * gradient^2
m_hat = m / (1 - beta1^t)
v_hat = v / (1 - beta2^t)
w = w - (learning_rate / (sqrt(v_hat) + epsilon)) * m_hat