
해당 글은 제로베이스데이터스쿨 학습자료를 참고하여 작성되었습니다
1. 얼굴 검출(face detection)
영상에서 얼굴의 위치를 검출하는 기법
- 얼굴 인식(face recognition) : 검출된 얼굴이 누구인지를 판결하는 기법
- 얼굴 랜드마크 검출(face landmark detection) : 눈, 눈썹, 코, 입 등의 형태까지 찾는 기법
얼굴 검출 역사
- 1900년대 얼굴 검출 기법
- 눈, 코, 입의 에지 성분 검출 및 위치 관계 분석
- 살색 영역 검출
- 초기 신경망 기법
- 2000년대 초반: Viola - Jones 얼굴 검출기
- 다수의 얼굴 영상과 얼굴이 아닌 영상을 이용한 머신 러닝 기법을 도입하여
빠르고 정확하게 얼굴 영역을 검출 - 기존 방법과의 차별점
- 유사 하르(Haar-like) 특징을 사용
- AdaBoost에 기반한 강한 분류 성능
- 캐스케이드(cascade) 방식을 통한 빠른
- 기존 얼굴 검출 방법보다 약 15배 빠르게 동작
- 다수의 얼굴 영상과 얼굴이 아닌 영상을 이용한 머신 러닝 기법을 도입하여
- 2010년대 중반 이후의 얼굴 검출 기법
- 딥러닝(deep learning) 객체 검출 기법을 응용한 얼굴 검출
- 기존의 Viola-Jones 얼굴 검출 방법보다 정확하고 안정적인 얼굴 검출 가능
- OpenCV에서는 딥러닝 기법으로 학습된 모델을 사용하는 예제 파일을 제공함(OpenCV Github)
2. OpenCV DNN
OpenCV DNN 모듈
- 미리 학습된 딥러닝 모델을 실행하는 기능
- 모델학습은 PyTorch, Tensorflow를 사용해야 함
얼굴 검출 예제
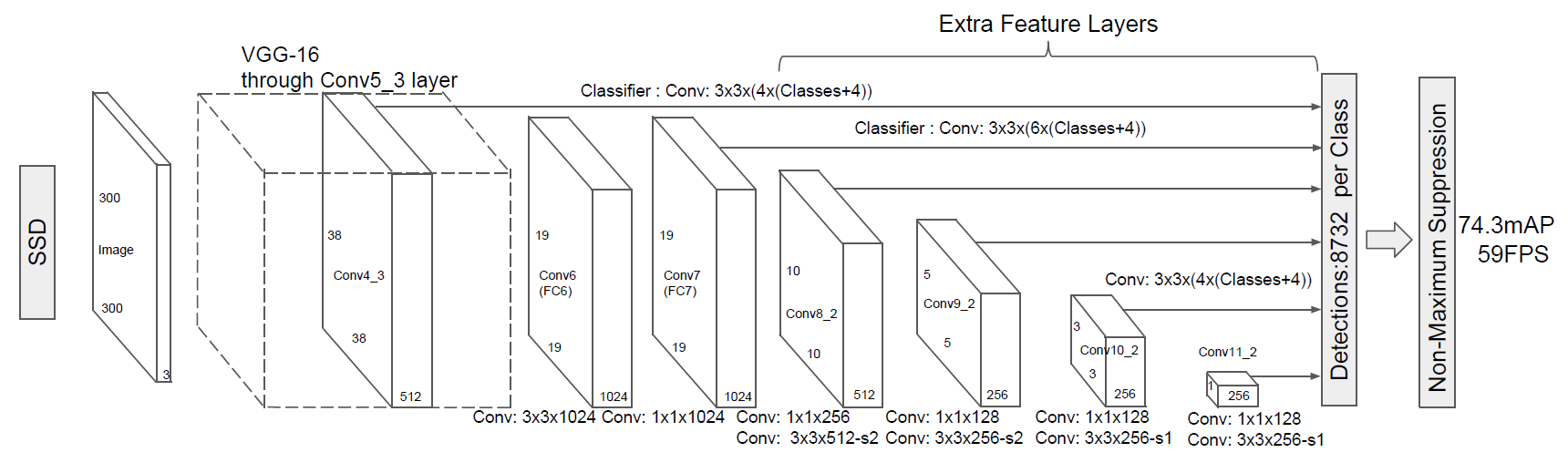
OpenCV DNN 얼굴 검출기 입력
- 입력 영상 크기: 300x300
- 픽셀 값 범위: 0 ~ 255
- 색상 채널 순서: BGR
- 평균 픽셀 값: (104, 177, 123)
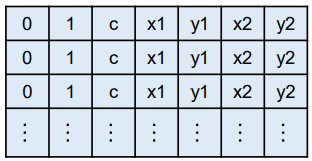
OpenCV DNN 얼굴 검출기 출력
- shape=(1, 1, 200, 7), dtype=float32
- detect = out[0, 0, :, :]
모델 불러오기
net = cv2.dnn.readNet(model, config)
- model : 학습된 딥러닝 모델
- config : 모델의 구성 정보
모델에 사용할 이미지 생성
blob = cv2.dnn.blobFromImage(image, scalefactor, size, mean)
- blob은 모델에 사용할 이미지(dims=4)를 생성한다
- image : 입력 이미지(dims=2)
- scalefactor : 스케일링 계수, 1을 기준으로 이미지 확대&축소
- size : 출력 이미지 크기
- mean : BGR 채널의 평균값
모델에 이미지 입력
net.setInput(blob)
- "net"이라는 모델에 이미지 입력
모델 실행
out = net.forward()
- "net"이라는 모델의 얼굴 검출 실행
- index[:,2] = 예측값
- x1,y1,x2,y2는 바운딩박스의 좌우 꼭짓점 좌표
얼굴 검출
- 해당 모델은 사람을 판단하는 기준이 눈이라는 것을 알게 됨
import sys
import numpy as np
import cv2
model = './data/opencv_face_detector/res10_300x300_ssd_iter_140000_fp16.caffemodel'
config = './data/opencv_face_detector/deploy.prototxt'
#model = 'opencv_face_detector/opencv_face_detector_uint8.pb'
#config = 'opencv_face_detector/opencv_face_detector.pbtxt'
# 카메라 열기
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print('Camera open failed!')
sys.exit()
# 모델 불러오기
net = cv2.dnn.readNet(model, config)
if net.empty():
print('Net open failed!')
sys.exit()
while True:
# 카메라 읽기
ret, frame = cap.read()
# 이미지 좌우 반전
frame = cv2.flip(frame, 1)
if not ret:
break
# 2차원 -> 4차원 이미지 생성
blob = cv2.dnn.blobFromImage(frame, 1, (300, 300), (104, 177, 123))
# 모델에 이미지 입력
net.setInput(blob)
# 모델 실행
out = net.forward()
detect = out[0, 0, :, :]
(h, w) = frame.shape[:2]
for i in range(detect.shape[0]):
confidence = detect[i, 2]
if confidence < 0.5: # 예측값이 0.5 이하면 무시
break
# 바운딩 박스의 좌표
x1 = int(detect[i, 3] * w)
y1 = int(detect[i, 4] * h)
x2 = int(detect[i, 5] * w)
y2 = int(detect[i, 6] * h)
# 바운딩 박스 그리기
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0))
# 예측값 출력
label = f'Face: {confidence:4.2f}'
cv2.putText(frame, label, (x1, y1 - 1), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 1, cv2.LINE_AA)
cv2.imshow('frame', frame)
if cv2.waitKey(1) == 27: # ESC누르면 종료
break
cap.release()
cv2.destroyAllWindows()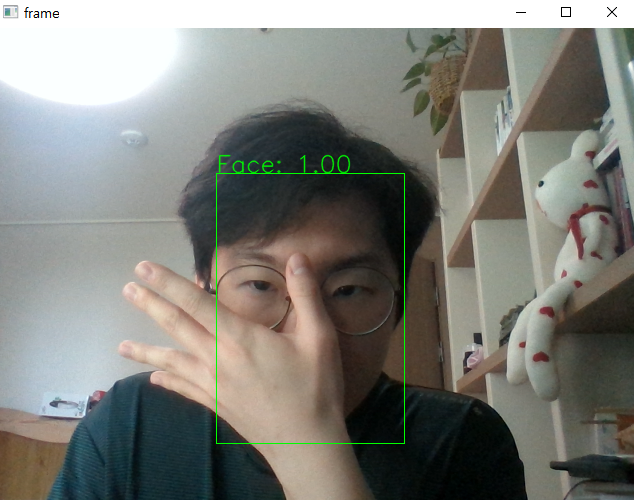

3. 얼굴 검출 응용: 모자이크
얼굴 모자이크 개요
- 촬영을 하다보면 타인의 개인정보(얼굴, 자동차 번호판, 주민번호 등)을 습득하게 된다.
- 개인정보를 보호하기 위해 이를 모자이크 처리할 필요성이 있다
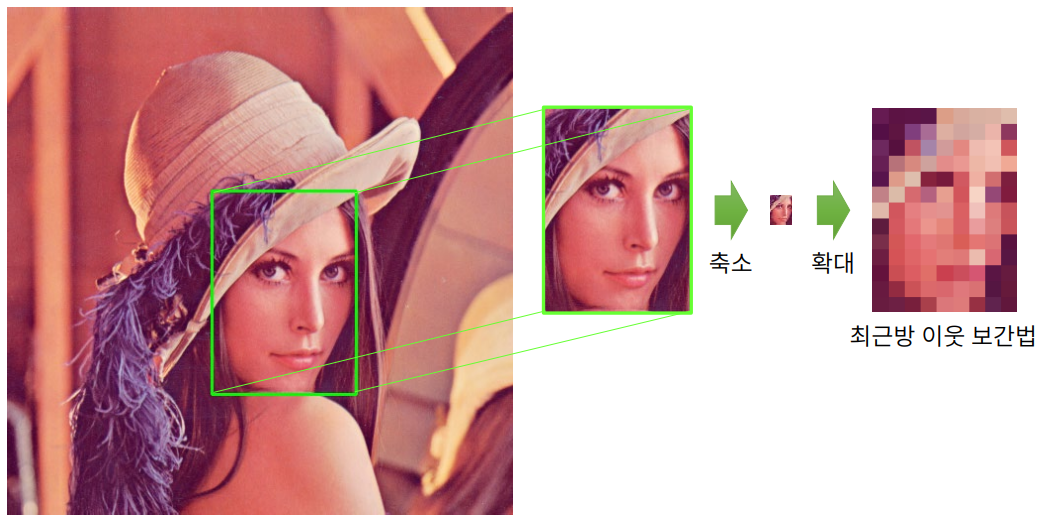
영상 크기 변환
cv2.resize(src, dsize, dst=None, fx=None, y=None, interpolation=None) -> dst
- src: 입력 영상
- dsize: 결과 영상 크기. (w, h) 튜플. (0, 0)이면 fx와 fy 값을 이용하여 결정.
- dst: 기존 출력 영상에 적용하는 경우 dst 인자 활용
- fx, fy: x와 y방향 스케일 비율(scale factor). dsize 값이 0일 때 유효)
- interpolation: 보간법 지정
- cv2.INTER_NEAREST : 최근방 이웃 보간법(Default)
- cv2.INTER_LINEAR : 양성 현 보간법(2x)
- cv2.INTER_CUBIC : 3차 회귀 보간법
- cv2.INTER_LANCZOS4 : Lanczos 보간법
- cv2.INTER_AREA : 영상 축소 시 효과적
모자이크 처리
import sys
import numpy as np
import cv2
model = './data/opencv_face_detector/res10_300x300_ssd_iter_140000_fp16.caffemodel'
config = './data/opencv_face_detector/deploy.prototxt'
#model = 'opencv_face_detector/opencv_face_detector_uint8.pb'
#config = 'opencv_face_detector/opencv_face_detector.pbtxt'
# 카메라 열기
cap = cv2.VideoCapture(0)
if not cap.isOpened():
print('Camera open failed!')
sys.exit()
# 모델 불러오기
net = cv2.dnn.readNet(model, config)
if net.empty():
print('Net open failed!')
sys.exit()
while True:
# 카메라 읽기
ret, frame = cap.read()
# 이미지 좌우 반전
frame = cv2.flip(frame, 1)
if not ret:
break
# 2차원 -> 4차원 이미지 생성
blob = cv2.dnn.blobFromImage(frame, 1, (300, 300), (104, 177, 123))
# 모델에 이미지 입력
net.setInput(blob)
# 모델 실행
out = net.forward()
detect = out[0, 0, :, :]
(h, w) = frame.shape[:2]
for i in range(detect.shape[0]):
confidence = detect[i, 2]
if confidence < 0.5: # 예측값이 0.5 이하면 무시
break
# 바운딩 박스의 좌표
x1 = int(detect[i, 3] * w)
y1 = int(detect[i, 4] * h)
x2 = int(detect[i, 5] * w)
y2 = int(detect[i, 6] * h)
face_img = frame[y1:y2, x1:x2]
fh, fw = face_img.shape[:2]
# 모자이크 처리
face_img2 = cv2.resize(face_img, (0, 0), fx=1./16, fy=1./16)
cv2.resize(face_img2, (fw, fh), dst=face_img, interpolation=cv2.INTER_NEAREST)
#frame[y1:y2, x1:x2] = cv2.resize(face_img2, (fw, fh), interpolation=cv2.INTER_NEAREST)
# 바운딩 박스 그리기
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0))
# # 예측값 출력
label = f'Face: {confidence:4.2f}'
cv2.putText(frame, label, (x1, y1 - 1), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 0), 1, cv2.LINE_AA)
cv2.imshow('frame', frame)
if cv2.waitKey(1) == 27: # ESC누르면 종료
break
cap.release()
cv2.destroyAllWindows()

