[Computers and Electronics in Agriculture 2022] Reinforcement learning for crop management support: Review, prospects and challenges
Paper Review-Biology&Agriculture
이번에 소개드릴 논문은 Computers and Electornics in Agriculture에 몇 달 전 게제된 따끈따끈한 리뷰 논문입니다. <Reinforcement learning for crop management support: Review, prospects and challenges>라는 제목인데요, 말 그대로 농업 의사결정 시스템에 대한 강화학습 기반 접근을 다루고, 현재의 한계점과 앞으로 나아가야 할 문제들을 제시합니다.
(Abstract) Reinforcement learning (RL), including multi-armed bandits, is a branch of machine learning that deals with the problem of sequential decision-making in uncertain and unknown environments through learning by practice. While best known for being the core of the artificial intelligence (AI) world’s best Go game player, RL has a vast range of potential applications. RL may help to address some of the criticisms leveled against crop management decision support systems (DSS): it is an interactive, geared towards action, contextual tool to evaluate series of crop operations faced with uncertainties. A review of RL use for crop management DSS reveals a limited number of contributions. We profile key prospects for a human-centered, real-world, interactive RL-based system to face tomorrow’s agricultural decisions, and theoretical and ongoing practical challenges that may explain its current low uptake. We argue that a joint research effort from the RL and agronomy communities is necessary to explore RL’s full potential.
Introduction
머신 러닝의 한 분야인 강화학습은 불확실하고(Uncertain), 알려지지 않은(Unknown) 환경에 대한 통제를 목적으로 하게 됩니다.
저자는 강화학습이 작물 의사결정 시스템에 Potentially Well Suited Paradigm이라 제시하며 리뷰를 시작합니다.
본 논문은 Agronomist와 RL Researcher들이 연구 방향을 공유하며, 현재의 병목(bottleneck)을 이해하며 미래의 합동 연구를 낳을 수 있는 Mutual Understanding을 전달합니다.
이를 위해, 본 논문은 아래와 같이 구성되었습니다.
- Crop Management Decision Problem을 정의합니다
- 현재의 Decision Support System이 어떻게 구성되는지 설명합니다
- RL Paradigm을 소개합니다
- RL applications on Crop Management를 소개합니다
- 최종적으로 남은 연구 과제들과 Challenges를 소개합니다
Crop Management DSS
Crop Management
Crop management is the logical and ordered combination of agricultural practices or operations applied to a field in order to obtain a particular crop production
(Sebillotte, 1974, 1978)
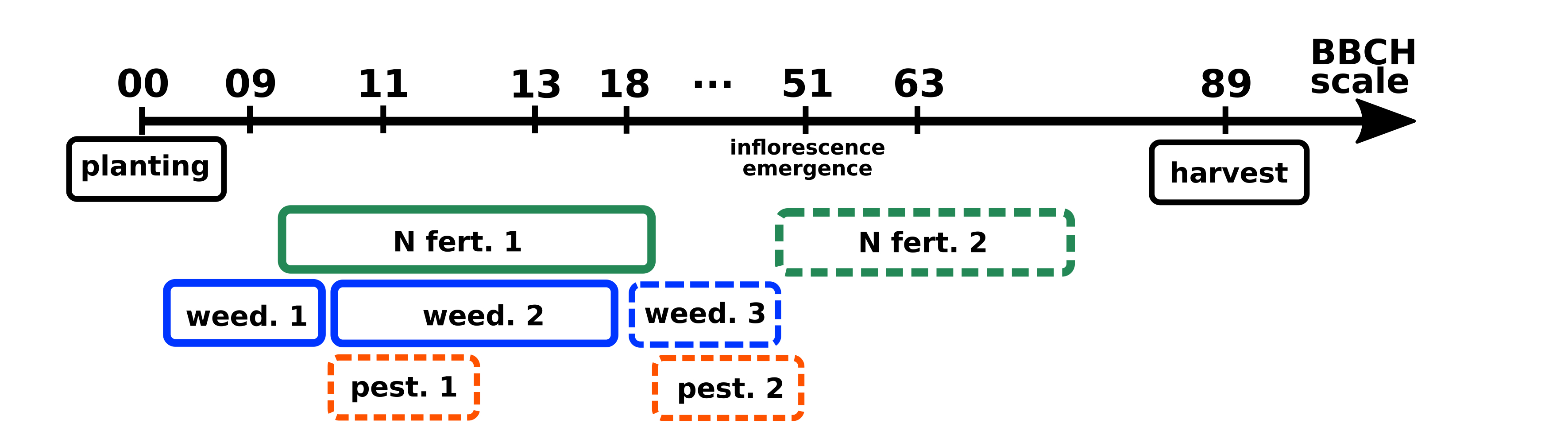
작물 관리; Crop management는 특정한 목적(생산량, 품질)을 위한 논리적, 시계열적 의사결정과 수행의 집합체입니다. 생물학적인 부분과 비-생물학적인 부분(토양과 대기 등)으로 구성되고, 불확실한 사건들을 지속적으로 마주칩니다; 주로 Climatic Events.
아래는 작물 관리의 간소화된 예시입니다.
Farm Decision Making Levels 의사결정의 레벨은 시간적, 공간적 레벨로 인해 달라집니다.시간, 일, 월 단위에서 연 단위, 농가 단위에서 지역, 지구 단위로 다양하게 변화할 수 있습니다.
Descision Support System
의사결정 보조 시스템; Descision Support System(이하 DSS)는 비구조화 혹은 반-구조화된 문제를 해결하는 의사결정자를 보조하기 위해 개발된 컴퓨터 기반 솔루션입니다.
DSS는 인간의 의사 결정을 보조하기 위해 증류된 정보를 증거로서 제안합니다 (ex: 환경, 토양 정보에서 증류된 예상 생산량 지표)
Crop management DSS
작물을 위한 DSS는 주로 시비(비료), 관개(물), 병충해, 제초 등의 이슈를 다룹니다.
널리 쓰이는 작물 DSS는 아래와 같은 것들이 있습니다.
- DSSAT
- APSIM
- STICS
- WOFOST
작물 DSS는 주로 기저에 이전에 개발된 수치 모델들을 사용합니다, 예를 들어 토양-질소 밸런스를 모델링하거나(Hebert, 1969),지식 베이스를 사용하는 등(Lemmon, 1986) 다양한 형태로 통합되어 있습니다.
많은 수의 작물 DSS가 존재함에도 불구하고, 농가들 사이에서의 이용률은 아직 낮습니다 (McCown, 2002)
또한 최종 사용자들은 아직 DSS가 제공하는 정보를 그대로 적용하지 못한다고 생각합니다
따라서 저자는 작물 DSS가 개인 농가 단위가 아닌 지역 단위로 확장되어 적용돼야 한다고 주장합니다.
Reinforcement Learning
본 논문에서는 강화학습에 대해서 자세하게 다루고 있으나, 리뷰의 취지에 맞지 않아 많은 부분을 생략하고 참고하기 좋은 다른 글을 첨부합니다.
https://jeinalog.tistory.com/20
Reinforcement Learning Loop
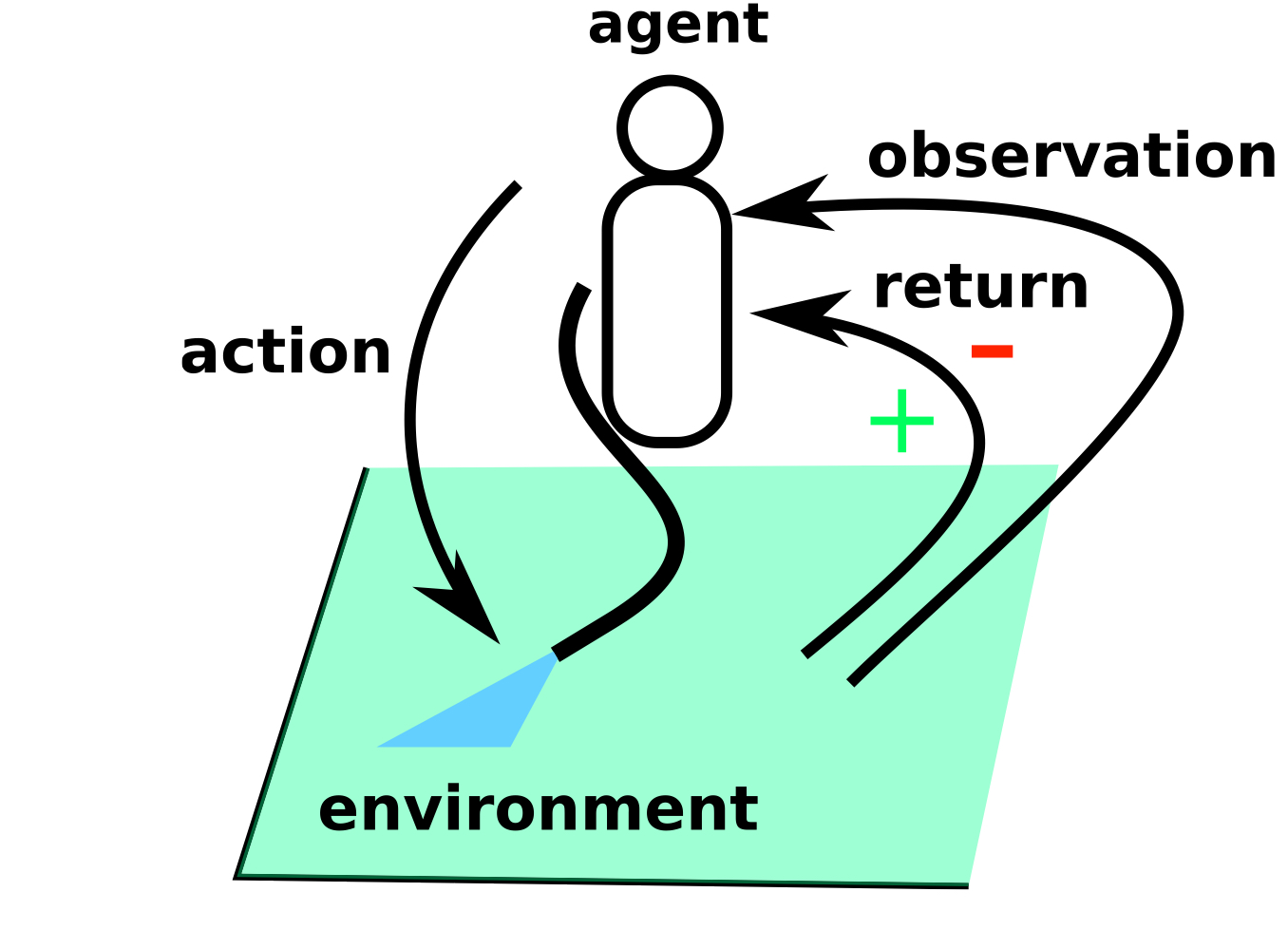
강화학습; RL은 특정한 Environment 안에서, Agent가 Action을 취하고, 그 Action에서 나오는 Return(Reward)를 최대화하기 위한 Policy를 최적화하는 문제로 정의할 수 있습니다.
강화학습은 Markov Decision Process라는 특정한 상황을 가정하고 이루어집니다

아래의 Figure은 관개를 간단한 강화학습 문제로 나타낸 도식입니다.
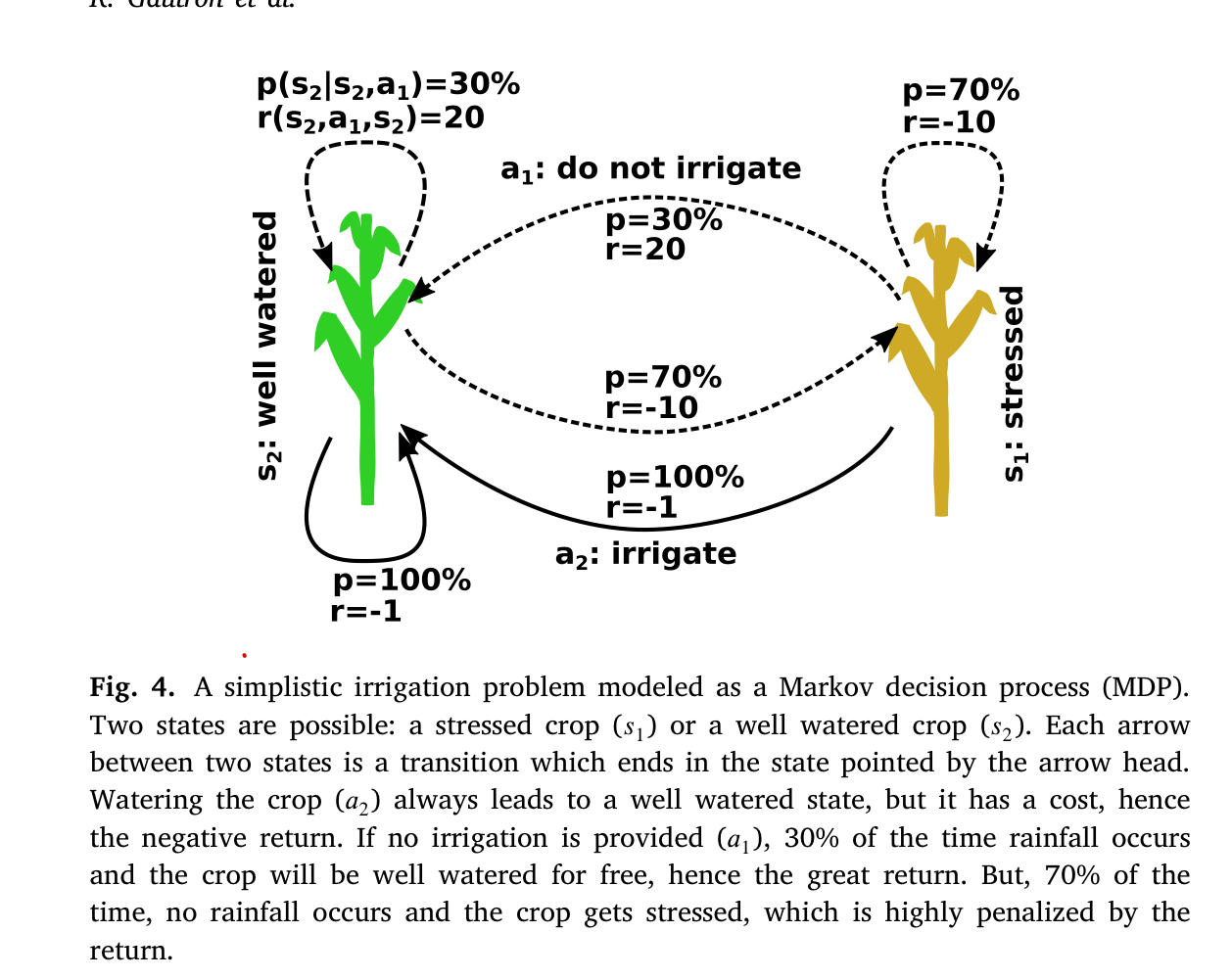
강화학습의 대표적인 알고리즘으로는 Q-Learning 등이 있습니다.
본 리뷰에서는 이 정도의 컨셉만을 전달하고 넘어갑니다.
(S)OC
저자는 RL의 개념을 소개하며 같이 (S)OC; (Stochastic) Optimal Control을 함께 전달합니다. 이는 known MDP, 즉 MDP 상황에서 다음 상태로 넘어가는 전환 확률과 가치를 계산하는 함수를 알고 있을 때 사용할 수 있는 알고리즘들입니다.
(S)OC에는 우리가 흔히 알고 있는 DP; Dynamic Programming과 몬테카를로 트리 탐색 등이 포함됩니다.
현대에 와서는 SOC와 RL 모두 한 방향으로 수렴되어가는 중입니다 (SOC가 주로 풀던 연속계 상황을 RL이 풀게 되는 등..)
Multi-armed Bandit
Review; RL Application on Crop DSS
저자는 SOC가 지금까지 주로 농가 수준 의사결정을 지원하도록 적용되었고, RL을 사용하려는 시도들은 아직까지 적을 뿐더러 시뮬레이션 환경에서만 구성되었다고 요약하였습니다
Early Attempts
Tinter(1955), Freund(1956)에 의한 확률적 선형계획법이 제한된 자원 하에서 농가의 알짜 소득을 최대화하기 위해 제안되었고, Hildreth(1957)에 의해 게임이론이 제안되었습니다.
Aliison(1963)에 의해 어떤 작물을 키울지 선택하는 문제가 MDP로 정의되었고, 동적 계획법과 벨만 방정식을 통해 이를 풀어내었습니다 (이는 현대 RL의 원형이 됩니다)
이 이후 SOC를 이용해 농업 의사결정을 풀어내려는 시도들이 다수 있었습니다.
- Dynamic Programming: Applications to Agriculture and Natural Resources. Springer Science & Business Media.
- Norton, Roger D., Hazell, Peter B.R., 1986. Mathematical Programming for Economic Analysis in Agriculture. Macmillan, New York, NY, USA.
- Glen, John J., 1987. Mathematical models in farm planning: A survey. Oper. Res. 35 (5), 641–666.
- Lowe, Timothy J., Preckel, Paul V., 2004. Decision technologies for agribusiness problems: A brief review of selected literature and a call for research. Manuf. Serv.
Oper. Manag. 6 (3), 201–208.- Dury, Jérôme, Schaller, Noémie, Garcia, Frédérick, Reynaud, Arnaud, Bergez, Jacques Eric, 2012. Models to support cropping plan and crop rotation decisions. A review. Agron. Sustain. Dev. 32 (2), 567–580.
- Weintraub, Andrés, Romero, Carlos, 2006. Operations research models and the man- agement of agricultural and forestry resources: a review and comparison. Interfaces 36 (5), 446–457.
Seminal Works using RL in agriculture
농업 의사결정에 RL을 도입하려는 시도는 아래의 테이블에 정리되어 있습니다.
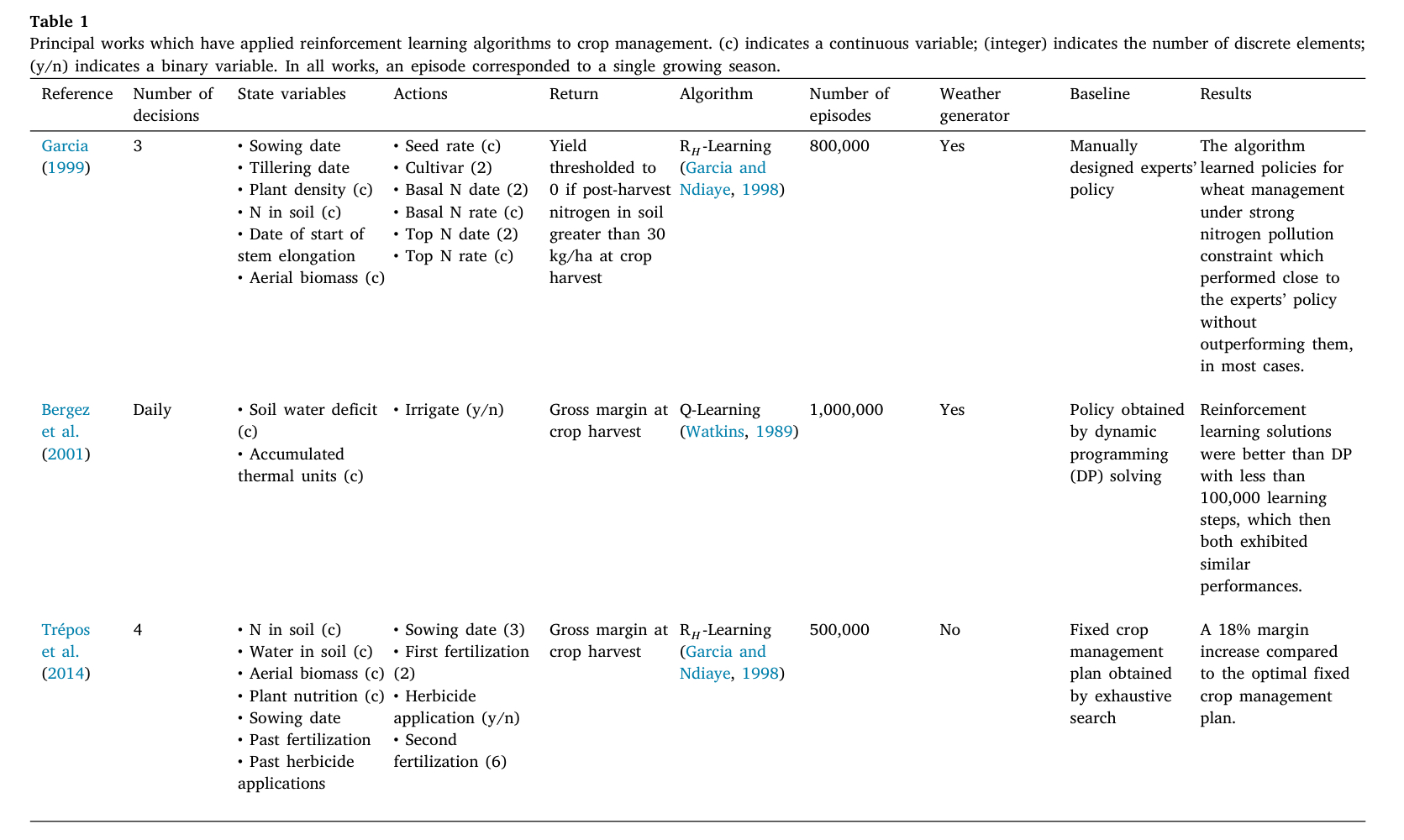
Garcia(1999)와 Bergez(2001), Trepos(2014)의 연구가 대표적인데, 셋 다 오른쪽에 기재된 Baseline 보다 높거나 비슷한 성적을 거두었다. Trepos와 Garcia의 경우 Reward에 할인율을 적용하지 않는 R_h Learning 알고리즘을 사용하였고, Bergez는 일반적인 Q Learning을 적용하였습니다.
게제된 세 연구 모두 아래와 같은 공통점을 갖습니다
- Crop Model을 시뮬레이션 환경으로 사용하였음
- RL에서 얻어진 Policy가 Crop Model Bias에 의존하게 됨
- Real World의 농부들과의 피드백을 통한 교정이 존재하지 않음
- 그러나 연구에 사용된 에피소드 모두 500k~1000k 정도의 에피소드를 사용
저자는 추가로 Tepos(2014)에 대해 이와 같은 비판을 가했습니다: 연구에 사용한 Weather Record의 개수가 너무 제한적이었고, 훈련 에피소드와 같은 날씨 집합을 검증에 사용했기 때문에 필연적으로 오버피팅을 불러일으켰다고. 또한 평가에도 만나지 못한(unseen) 날씨 집합이 아닌 훈련에 사용한 집합을 사용했기 때문에 Trepos(2014)의 성과가 Overly Optimistic 하다고 전합니다.
반대로, Gracia(1999)와 Bergez(2001)에 적용된 확률적 날씨 생성기는 더욱 날씨의 무작위성에 강건(Robust)한 결과를 얻어내게 하였습니다.
추가로 주목할 점은 Gracia(1999)가 자신의 연구를 정리한 방식인데, 학습된 에이전트의 Policy에서 "P하면 Q하라"의 형식으로, 유저-친화적으로 룰을 추출하여 정리하였습니다.
Deep RL Applications
Recently, 새로운 시도들이 많이 도입되고 있습니다.
Bu, Fanyu, Wang, Xin, 2019. A smart agriculture IoT system based on deep reinforcement learning. Future Gener. Comput. Syst. 99, 500–507.
Bu, Wang(2019)는 Deep Q Learning(이하 DQN) 기반 스마트 농업 의사결정을 위한 범용적인 IOT 아키텍처를 제안하였습니다. DQN은 Q-Learning에 NN을 결합한 모델입니다. Bu와 Wang은 해당 논문에서 Transfer Learning을 통해 학습 효율성을 높였습니다.
(해당 논문은 ASAP 같은 시리즈에서 리뷰하도록 하겠습니다)
Binas, Jonathan, Luginbuehl, Leonie, Bengio, Yoshua, 2019. Reinforcement learning for sustainable agriculture. In: ICML Workshop Climate Change: How Can A.I. Help?
Binas et al. (2019)는 지속가능한 농업을 위해 Wang과 유사한 해결책을 제안하였고,이는 CSM을 이용해 모델을 사전 학습하고, in-situ (즉, 필드 위에서) 상황에서, 생애주기가 짧은 작물들을 Fine-Tuning 하자는 제안이었습니다. 이 와중에 Bengio, Yoshua 교수님 익숙한 이름이..
Deep RL을 적용하려 한 많은 시도들은 주로 시뮬레이션 환경 위에서 이루어졌습니다
Wang et al. (2020)은 RL+Transfer Learning을 통해 CO2 Concentration과 습도를 모의된 온실에서 조절하여 오이의 생구중을 최대화하고자 하였습니다.
Sun et al. (2017), Yang et al. (2020), Chen et al. (2021)은 노지 관개 태스크에 Deep RL을 적용하고자 하였습니다.
Chen et al. (2021)은 7일 예보를 State에 포함시켜 접근하였습니다.
상기된 연구들 모두 Superior Performance를 기록하였으나
- 시뮬레이션 환경에서만 이루어졌음
- 훈련, 검증, 평가에 단일 연도 단일 장소의 날씨 집합만 사용음
- 기존의 RL 알고리즘에 비해 증가한 유연성은 과적합을 초래할 수 있음
와 같은 점은 주의해야 한다고 저자는 주장합니다.
저자는 적합한 RL+Agriculture 연구는 CSM을 이용해 굉장히 많은 수의 날씨 집합을 생성하고, 훈련 과정에서 사용하지 않은 날씨 집합에서 테스트를 진행해야 한다고 밝힙니다.
Multi Armed Bandits
MAB를 활용한 연구는 잘 이어지지 않고 있습니다. Krischener(2019)는 일반적인 MAB 알고리즘을 엮어서 생산량을 극대화하는 작물 세부 품종(Cultivar) 선택 문제를 해결하였습니다
Baudry (2021)는 Crop Management를 위한 리스크테이킹 Bandit 예시를 제안하였고, DSSAT을 사용하여 Maize 파종 일자 결정 문제를 풀어 알고리즘을 평가했습니다.
모든 시뮬레이션에는 WGEN을 통해 생성된 날씨 집합이 사용되었습니다 (Richardson and. right, 1984)
Baudry가 제안한 알고리즘은 해당 문제에 대한 SoTA를 기록하였고, 현재 배치 추천 형태로 Adoptation을 개발하고 있습니다. 예를 들어, 해당 지역의 파종 일자 추천 등이 있습니다.
Potential and Challenges
RL-Based Crop Management DSS
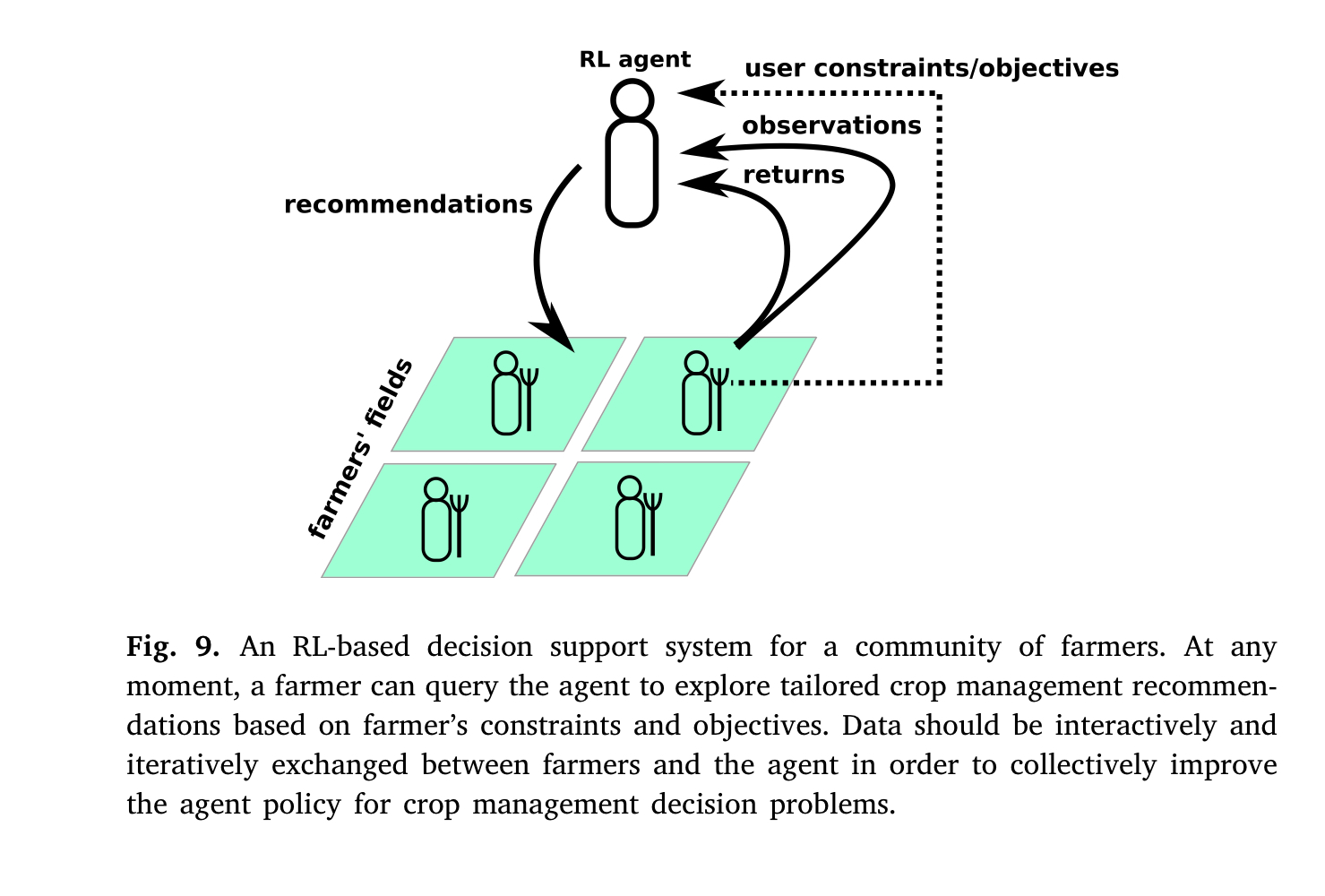
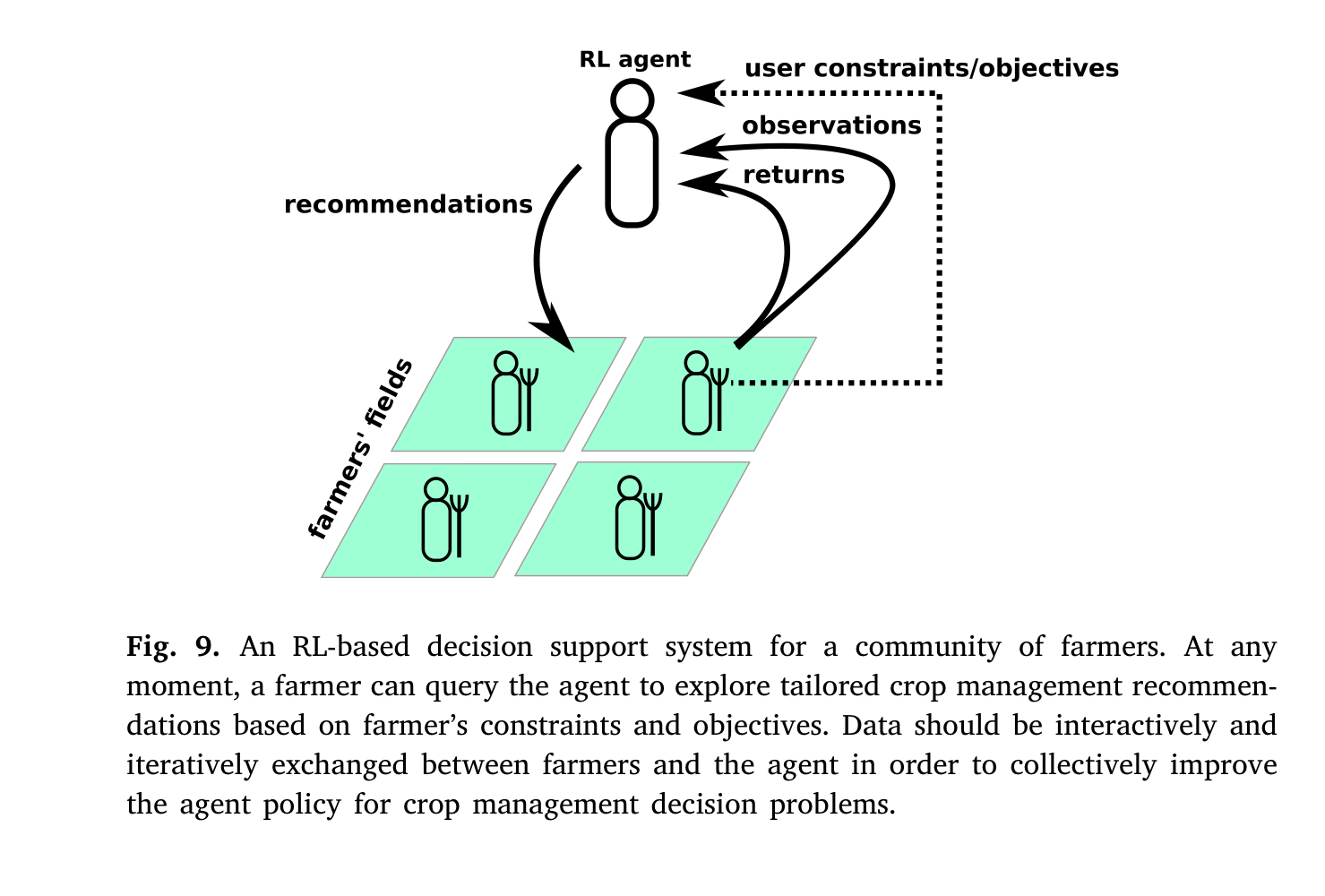
저자는 Crop Management DSS가 Human-Centre, 즉 인간 중심적인 설계로 나아가야 한다고 주장합니다. 예를 들어, 농부가 시스템에 질의를 하면 그 질의에 맞는 대답을 하는 설계로 가야지, 농업 사이클 전체에 대한 의사결정을 미리 내리면 안 된다고 제안합니다. 이에 대한 이유로 농부들이 DSS의 결정을 그대로 따르지 않으며 (이가 기존의 강화학습 모델과 다른, not fully control, 부분이라고 밝힙니다) 이로 인해 Toxic한 결과를 낳을 수 있다고 주장했습니다.
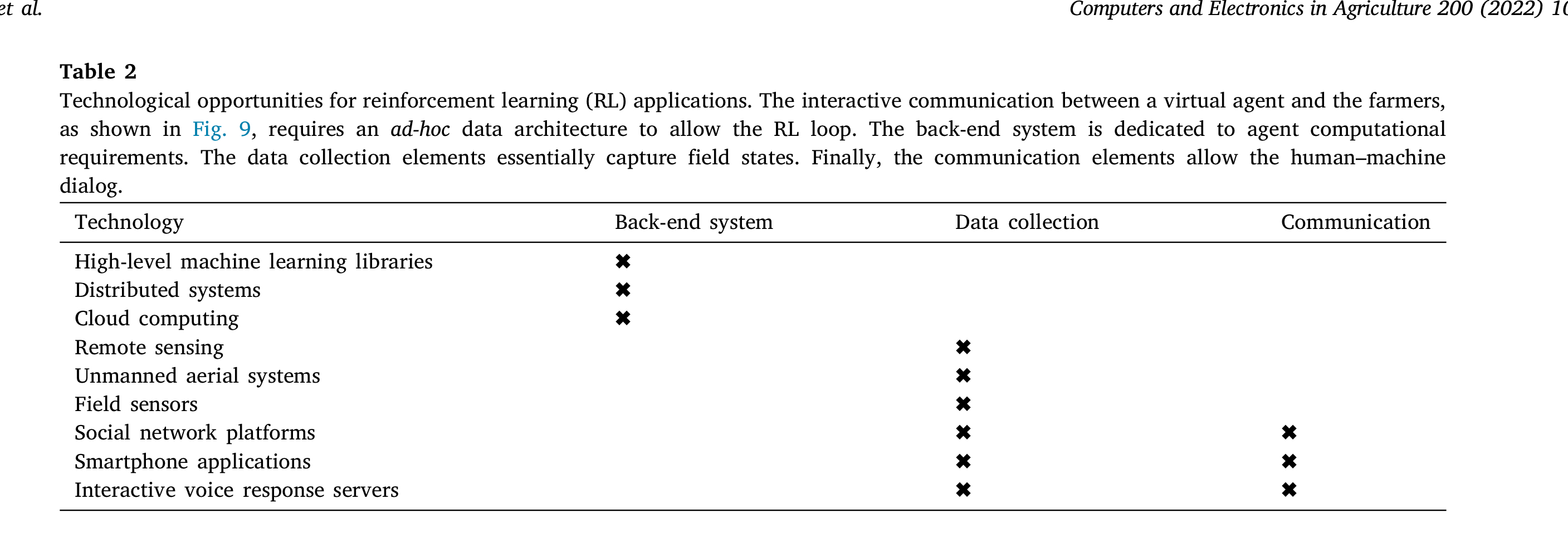
Data Collection
저자는 이와 같은 DSS를 제작하기 위해선 아래와 같은 장비들이, 각 단계에 맞게 필요할 것이라 주장했습니다.
Challenges
저자는 기후 변화에 따른 기후 불확실성, 병충해와 혼작에 대한 시뮬레이션 구현이 필요하다고 주장합니다
Learning is Costly
RL은 Active Data Collection이 필요합니다. Action과 결과들이 훈련 중에 상호작용할 수 있는 환경이 필요합니다. 이것은 농업 분야에 특히 취약합니다. 농업에서의 실험은 굉장히 Costly 하기 때문입니다.
따라서 Agent의 학습 효율을 높이기 위해 Trasnfer Learning이 필요합니다.
Testbed is needed
In RL, the first step to address real-world problems is generally to create simulated environments to explore the use of candidate algorithms.
CSM이 많음에도 불구하고, 적은 수의 오픈 소스 농업을 위한 RL 환경만이 존재합니다. OpenAI Gym은 일반적인 RL 환경을 만들기 위한 툴킷입니다.
Overweg et al. (2021)은 PCSE의 (LUNTUL-3)를 이용해 밀을 위한 CropGym을 제작하였습니다. Gautron et al. (2022)는 DSSAT(Hoogenboom et al., 2019)의 포트란 모델을 gym-DSSAT으로 제작하였습니다. 이는 옥수수에 대한 N 시비와 관개 태스크를 포함합니다
Conclusion
본 논문을 통해 강화학습 기술을 이용해 농업 의사결정 문제를 해결하기 위해 연구한 이들의 접근을 정리할 수 있었습니다. RL은 Uncertainity가 포함된 Sequential Decision Making 문제 해결에 적합합니다. 이는 RL이 Crop Management를 지원하기에 적합한 알고리즘일 가능성을 크게 시사합니다.
그러나 본 리뷰는 Agronomy Community에 RL을 적용하려는 노력이 제한되었다고 밝힙니다. Crop Management는 많은 수의 도메인 지식과 이론적인 Challenges를 내포하기 때문입니다.
저자는 Decision Support는 절대 Algorithmic 최적화 문제로 환원될 수 없다고 밝히고, 사용자를 충분히 고려해야 한다고 밝힙니다.
또한 데이터가 비싸고 희박하며, 잘못된 결정이 Deleterious(특히 식량안보 문제에)하기 때문에, Explainable한 Policy를 도출하는 것이 중요하고, Multiple Objectives를 최적화하기를 학습해야 한다고 (예를 들어 Maximum yield와 low pollution) 주장합니다.
저자는 마지막으로 MAB가 in-situ learning에 제일 적합한 알고리즘임을 적은 복잡성과 다재다능함을 근거로 다시 주장하며 이를 마무리합니다.
