Join의 동작 방식들인 Nested Loop Join, Sort Merge Join, Hash Join에 대해 알아보자. 유튜브 영상을 참고하여 간단히 작성하였다.
Nested Loop Join
Nested Loop Join은 가장 단순히 Join을 구현한 방법이다. 두 개의 테이블을 조인한다고 가정하면 (이 때, 조인하는 테이블을 Driving Table, 당하는 테이블을 Driven Table이라고 한다. 혹은 R, S 라고 한다.)
for (driving_table: driving_tables) {
for (driven_table: driven_tables) {
if(is_match(driving_table, driven_table) join(driving_table, driven_table)
}
}와 같이 단순히 두 개의 테이블에 대해 이중 반복문을 통해 일치 여부 파악 후 Join을 진행한다.
장점으로는 가장 단순하며, 별도의 사전 준비과정이 필요없다는 것이다. 즉, 두 테이블의 크기가 작을 경우 효과적이다.
단점으로는 두 테이블의 크기를 |R|, |S|라고 했을 때 O(|R|*|S|) 이 시간복잡도가 소모된다는 점이다.
Sort Merge Join
Nested Loop Join 방식은 두 테이블을 비교하면서 이미 원하는 결과를 얻었음에도 계속하여 반복하는 경우가 잦다. 위 코드를 보더라도 매칭되는 테이블을 찾았음에도 별도의 break문이 없다. 이처럼 매칭되는 테이블을 찾더라도 탈출하지 못하는 이유는 매칭되는 테이블이 여러 개 존재할 수 도 있고, 어느 범위까지 존재할지 모르기 때문이다.
따라서, 매칭되는 테이블이 어느 범위까지만 존재한다는 것을 확인하여 효율적으로 검사하는 방법이 Sort Merge Join이다. 이름 그대로 정렬하여 탐색함으로써, 중간에 더이상의 원하는 테이블이 없음을 확인하고 탈출할 수 있다.

(Nested Loop Join이 비효율적으로 동작하는 모습)
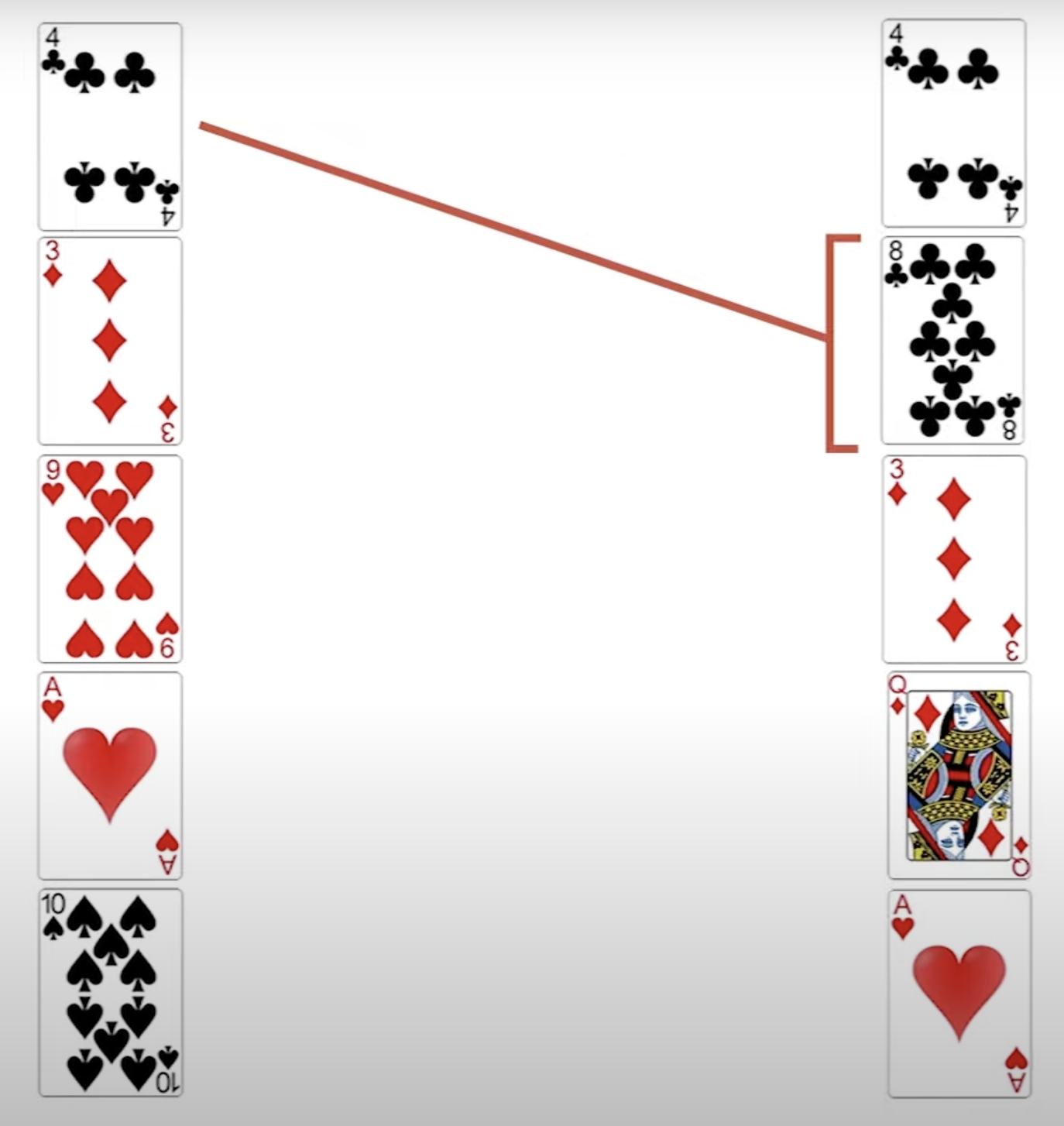
(정렬을 하여, 더이상의 순회없이 탈출하는 모습)
두 테이블을 정렬하는데 시간복잡도 O(|R|log|R| + |S|log|S|)가 소모되며, 정렬 후 탐색하는데 O(|R|+|S|)가 소모된다. (이전 탐색 결과 이후부터 탐색하므로 탐색 비용이 낮다.)
장점으로는 NL(Nested Loop) 방식에 비해 빠른 시간복잡도를 갖는다는 점이고, 단점으로는 Driving Table이 적을 경우 NL 방식에 비해 정렬 비용이 상대적으로 크게 느껴질 수 있다는 점이다. (극단적으로 |R|가 1인 경우, S를 정렬하는 비용은 굉장히 크다.)
Hash Join
해시 테이블에 데이터들을 등록해놔 매칭 여부를 판단하는 방법이다.
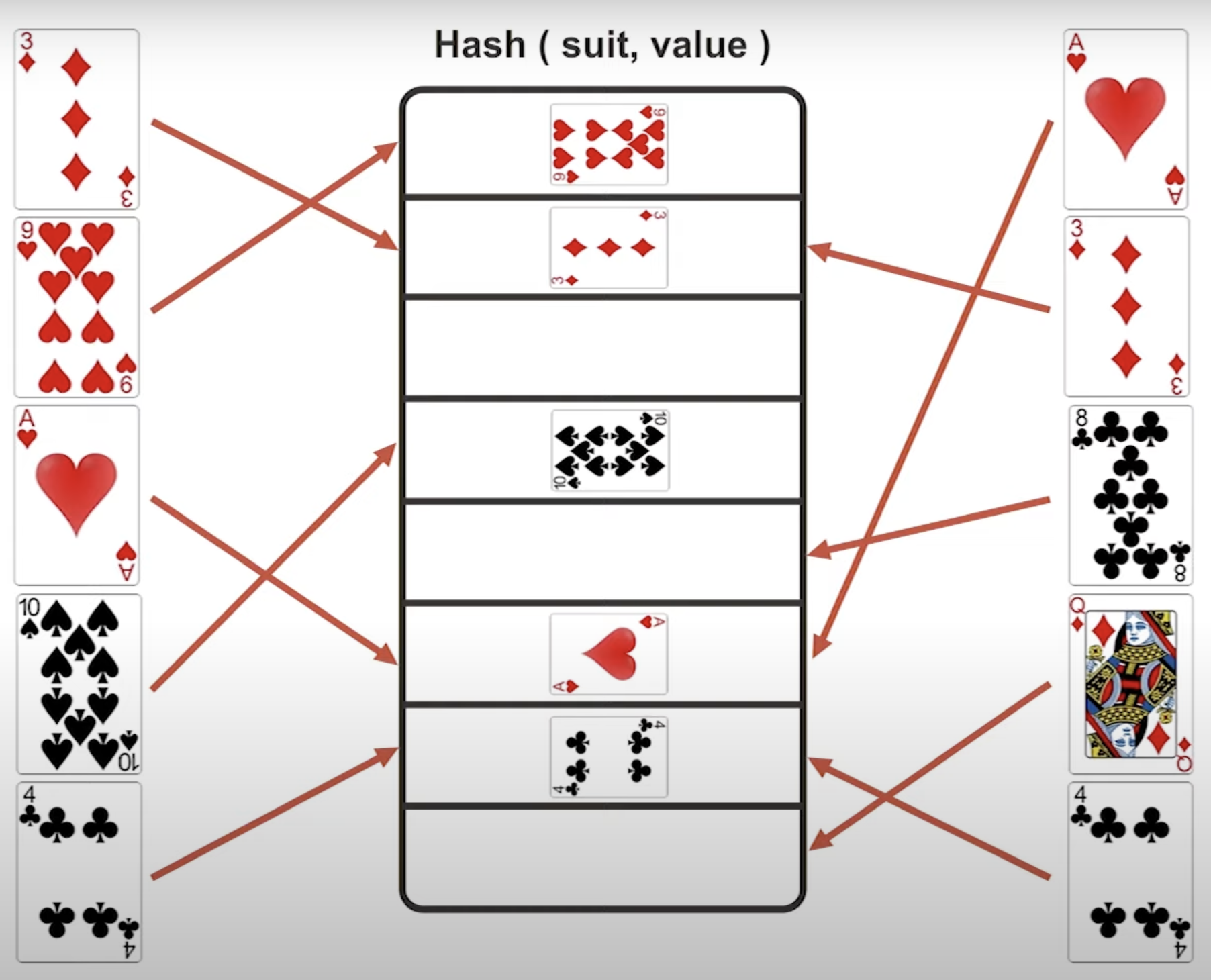
(해시 조인의 모습)
동등 연산이 가능한 경우에만 사용할 수 있으며, 시간복잡도는 O(|R|+|S|)로 가장 적게 소모된다.
장점으로는 가장 뛰어는 시간효율이 있고, 단점으로는 적은 데이터에 대해 실행될 경우 상대적으로 해시 테이블을 만드는 비용이 크다는 점이다.
많은 양의 데이터에 대해 사용할 경우 생일 파라독스에 의한 해시 충돌이 가능할 수도 있을 것이다.
인덱스의 사용
위의 경우만을 고려하면 해시 조인의 성능이 가장 우수하다. 하지만 해시 조인은 인덱스를 사용할 수 없다는 단점도 존재한다. NL 조인의 경우 인덱스를 활용하여 효율적으로 탐색이 가능하며, Sort Merge 조인의 경우 인덱스가 존재한다면, 시스템에 따라 정렬을 하지 않는 경우도 있어 효율적으로 동작할 수 있다.
참고
자세한 설명이 필요하면 아래를 참고하자.
