특정한 값을 기준으로 데이터를 순서대로 배치하는 작업을 정렬이라고 한다. 프로그래밍을 통해 퀵정렬, 병합 정렬, 버블정렬 등이 있다고 배워왔다. 당연하게도 이러한 정렬 작업은 주기억장치에서 실행된다. 하지만 데이터의 크기가 너무 커, 주기억장치에서 정렬을 진행할 수 없다면 어떻게 될까?
이와 같이 대규모 데이터를 주기억장치 뿐만이 아니라, 보조기억장치까지 이용해 정렬하는 방식을 외부 정렬이라고 한다.
병합 방법의 종류
이는 정렬 단계와 병합 단계로 나뉜다. 정렬 단계에서는 런이라는 단위로 데이터들을 파일로 분리한 후 정렬한다. 병합 단계에서는 정렬된 런들을 반복적으로 병합하여 하나의 런인 최종 결과물을 만든다.
병합 단계에는 m-원 합병, 균형 합병, 다단계 합병등의 방법이 있다.
구현
m-원 합병을 구현하려고 한다.
m-원 합병은 런들을 m개씩 병합하는 작업을 반복하여 결과물을 만들어 내는 방식이다.

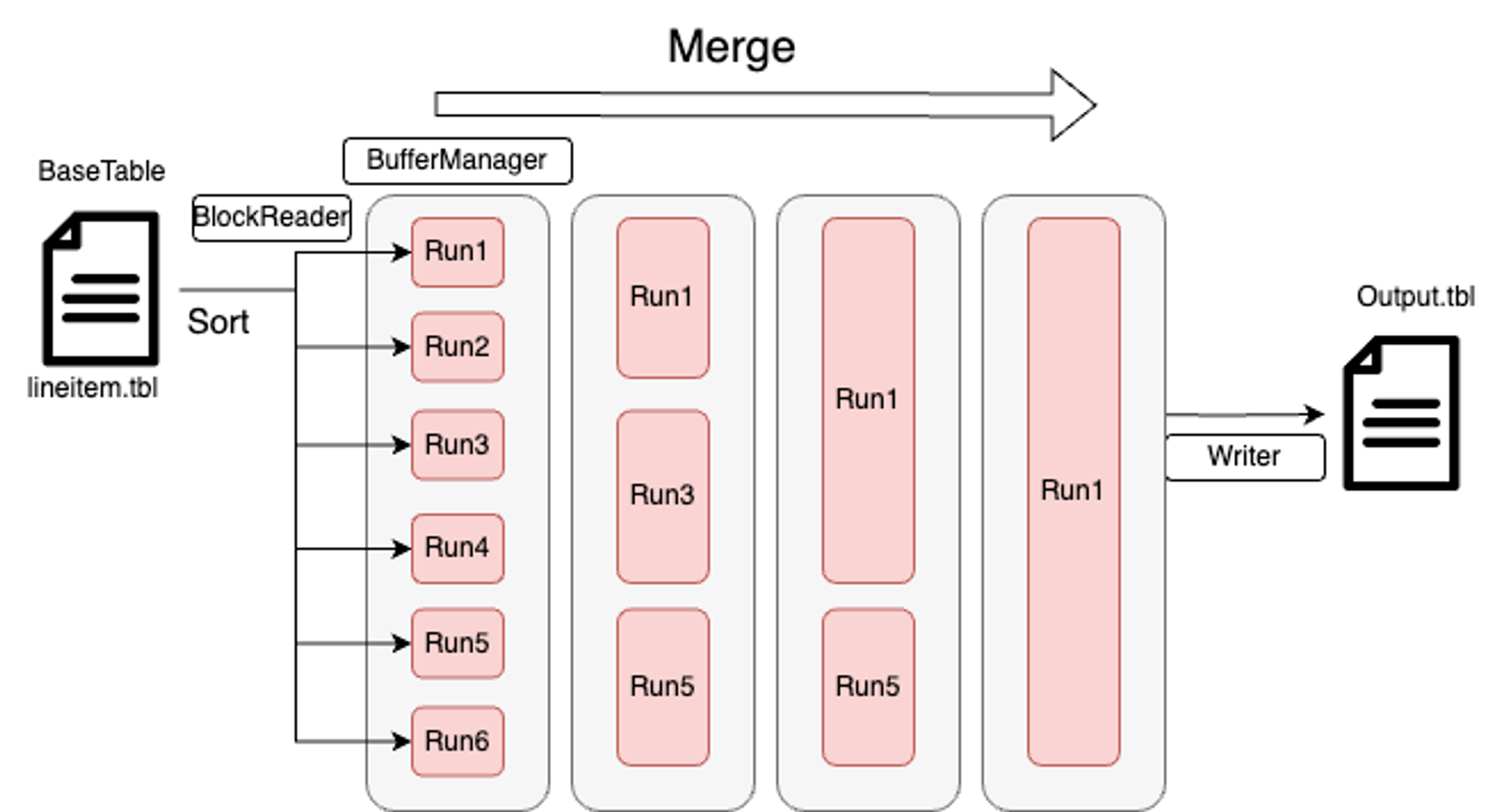
위의 이미지는 2-원 합병을 통해 하나의 결과물을 만들어내는 과정을 나타낸 것이다.
설계

BlockReader: 레코드들을 블럭 단위로 읽어오도록 하는 객체이다.BufferManager: 레코드들을 정렬하여 파일로 저장하는 객체이다.BlockWriter: 레코드들을 고정길이-블럭단위로 파일에 출력하는 객체이다.
lineitem.tbl을BlockReader로 읽는다.BufferManager에 저장한 후, 설정한 버퍼 크기가 되면 정렬한 후 런 파일로 저장한다.- 정렬 기준은
parsePartKey()을 통해PARTKEY를 기준으로 오름차순 정렬하였다. - 이 때는 c++ 내장 정렬인 퀵정렬을 활용하였다.
- 정렬 기준은
- (1), (2)를
lineitem.tbl을 다 읽을 때까지 실행한다. - 입력한 m에 대해 m-원 병합을 실행한다.
- 실행된 최종 결과(
run1)을output.tbl에 저장한다.
(m-원 병합을 진행할 인덱스들[어느 런부터 어느런까지 병합하는지, 현재 병합 깊이가 어떻게 되는지]를 조정하는 것이 어려웠다.)
설명
- 목표: 가상 메모리 사용량(vm)과 프로세스의 메모리 사용량(rss)의 합이 10MB가 넘지않는 선에서 최적의
- 변인: 하나의 런에 담을 레코드의 개수(B), 사용할 원(M)
- 참고: 테이블의 총 크기(N)
- 시간 복잡도: 마스터 정리에 의해
O(NlogN)일 것이다.- 추가적으로 시간소요에 런의 개수와 깊이에 의한 I/O이 영향을 줄 것이다.
- 공간 복잡도: 정렬을 하기 위해 유지하는 런의 크기와 병합을 위해 메모리에 유지하는 원의 크기에 의존할 것이다. 즉
O(B+M)이다.
예측
- 병합의 깊이가 깊어질 수록 여러 파일에 대한 I/O 작업이 생겨 시간 소모가 클 것이다.
- 따라서 런에 빈 공간이 없도록 하는 경우인 Bn= N/M,
N % M == 0이 되는 M과 B가 최적해일 것이다.
- 따라서 런에 빈 공간이 없도록 하는 경우인 Bn= N/M,
- 런이 유지하는 레코드의 수(B) 역시 커지면 메모리 유지를 위한 공간 소모가 크지만, 그 만큼 I/O 작업이 줄어들어 시간 소모는 줄 것이다.
결과
- Ubuntu 18.04
- lineitem.tbl의 길이 6000개 (고정길이)
- 블록 크기 20
- 5원 합병
에 대해 실행하였다. - 메모리가 8500kb보다 작은 경우들 중의 최소 실행 시간을 찾고자 하였다.
결과 표
| 버퍼 크기 | 최대 메모리 크기 | 실행 시간 (ms) |
|---|---|---|
| 1 | 6188KB | 639.806 |
| 750 | 8252KB | 108.542 |
| 1250 | 8264KB | 106.633 |
| 1375 | 8420KB | 104.22 |
| 1382 | 8500KB | 110.425 |
| 1390 | 8512KB | 110.772 |
| 1406 | 8544KB | 104.824 |
| 1437 | 8568KB | 103.345 |
| 1500 | 8664KB | 82.733 |
| 3000 | 9308KB | 87.237 |
| 6000 | 10324KB | 98.386 |
| 7500 | 10440KB | 85.734 |
- MaxMemoryUsage는 VM,RSS의 합이 가장 높을 때를 기준으로 측정하였다.
- 예상대로 버퍼 크기가 작을수록 메모리 소비는 작고 시간 소모는 컸다. 버퍼 크기가 커질수록 시간 소모는 줄었고, 메모리 소모는 늘었다.
- 8500KB 이내일 때, 버퍼 크기가 1375인 경우 최소 실행 시간이 나타났다.
- 이는 이분탐색을 이용하여 도출하였다.
