Von Neumann architecture
주제 : 컴퓨터 구조 중 하나인 폰노이만 구조와, 관련된 기초에 대해 학습한다.
컴퓨터 구조 중 하나
거의 모든 컴퓨터는 폰노이만의 구조를 따른다.
개요
- 폰노이만 구조는 중앙처리장치 (CPU), 메모리, 프로그램으로 구성된다.- 폰노이만 구조 이전에는 스위치를 설치하고 전선을 연결하여 데이터를 전송하고 신호를 처리하는 식으로 프로그래밍하였다.
입출력 메커니즘
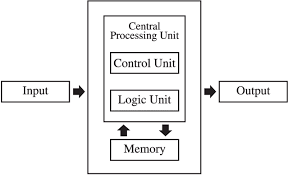
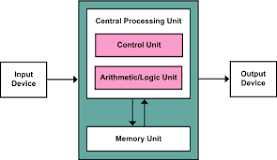
프로그램 내장방식 (Stored program)
- 중앙처리장치 (CPU) 옆에 기억장치 (memory)를 붙인 것-
최초의 프로그램이 내장된 컴퓨터 방식이다.
-
먼저 연산의 수행과 관련된 명령어를 실행하고, 프로그램과 자료를 메모리에 저장해 놓았다가 사람이 실행시키는 명령어에 따라 순차적으로 작업을 차례로 불러내어 처리하는 방식이다.
-
기존(에니악 컴퓨터)에는 작업을 할 때마다 전기회로를 교체해야 했었다.
실행 사이클
- 명령어 가져오기 (IF, Instruction Fetch)
메모리로부터 명령어를 가져온다.- 명령어 해석 (ID, Instruction Decode)
가져온 명령어가 어떤 명령어인지 해석한다.- 피연산자 인출 (OF, Operands Fetch)
명령어를 실행하기 위한 피연산자를 메모리로부터 가져온다.- 명령어 실행 (EX, Instruction Execution)
가져온 피연산자와 데이터를 가지고 명령어를 수행하고 저장한다.- 인터럽트 체크
잘 실행되었는지 체크한다.
주의 : 명령어와 프로그램의 실행은 반드시 메모리에서 진행되어야 하고, CPU에서 명령어는 한번에 하나씩만 처리할 수 있다.
단점 (폰노이만 병목현상)
-
CPU는 메모리에서 명령과 데이터를 불러와야 하지만, RAM과 CPU의 속도 차이로 인해 병목 현상 (CPU가 메모리의 응답까지 기다리게 된다.)이 발생하는 것을 폰노이만 병목현상이라 한다.
-
폰노이만 구조에서는 주기억장치로 DRAM을 사용하고 있는데, DRAM은 값이 싼 대신에 CPU의 동작 속도보다 현저히 느리다.
-
또한 CPU에서 메모리는 떨어져 있고 이 둘은 버스 (데이터나 전력을 전달하는 회로)로 연결되는데, 마치 외나무다리처럼 한 버스에서는 CPU가 명령어와 데이터에 동시에 접근할 수 없다.
-
위의 단점을 개선한 구조가 하버드 구조인데, 하버드 구조는 제어신호와 명령어, 데이터를 각각의 전용버스로 나눔으로써 버스의 혼잡을 줄였다.
상세구조
1. CPU (Central Processing Unit)
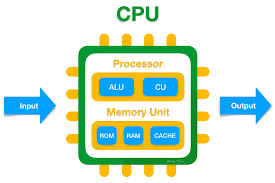
- 컴퓨터에서 기억, 해석, 연산, 제어라는 4대 주요 기능을 관할하는 장치- CU와 ALU, 레지스터들로 구성되어 있다.
1.1 CU (Control Unit)
- 명령어를 해석하고, 명령의 실행을 위한 제어신호를 발생시킨다.
1.2 ALU (Ariethematic Logic Unit)
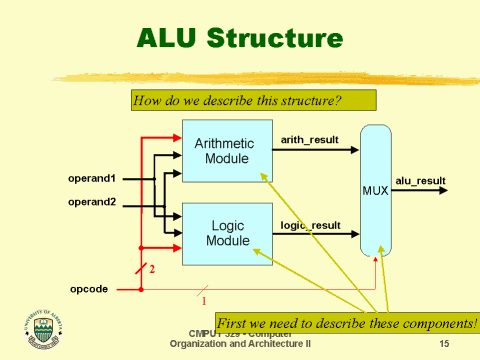
- ALU는 CU의 신호에 따라 산술, 논리연산이 일어나는 산술논리장치이다.
- 지정된 출발 레지스터의 내용을 ALU의 입력으로 전달한다.
- ALU에서 그 연산을 실행한다.
- 그 결과가 도착 레지스터에 전송된다.
-
연산 모듈은 사칙연산을, 논리 모듈은 논리연산 (AND, OR, XOR 등...)을 수행하는 부분이다.
-
MUX는 여러개의 입력중에 하나를 선택하여 출력하는 회로이다.
-
ALU에는 출력전/후의 값을 임시로 기억해주는 레지스터가 있다.
1.3 레지스터
- CPU가 요청을 처리하는데 필요한 데이터를 일시적으로 보관하는 기억장치-
문제 없이 명령을 처리하기 위해 주소와 명령의 종류를 보관하기 위해서는 속도가 빨라야 한다.
-
레지스터는 크기는 작지만 CPU와 직접적으로 연결되어 있어, 연산속도가 메모리에 비해 매우 빠르다.
-
CPU는 자체적으로 데이터를 저장할 수 없기 때문에 메모리로 직접 데이터를 보낼 수 없다.
-
때문에 연산을 위해서는 반드시 레지스터를 거쳐야 하며, 이를 위해 레지스터는 특정 주소를 가리키거나 값을 읽어올 수 있다.
1.3.1 명령 처리에 필수적인 레지스터
-
MAR (Memory Address Register)
메모리의 주소(번지)를 저장한다. -
MBR (Memory Buffer Register) == MDR
메모리로부터 읽어왔거나, 메모리에 기록할 데이터를 저장한다. -
PC (Program Counter)
다음번에 실행할 명령어의 위치 (번지)를 지정한다.
PC는 독특하게 한번 읽힐 때마다 값이 1씩 증가하여 특별한 일이 없다면 순차적으로 다음 메모리에 접근할 수 있도록 되어있다. -
IR (Instruction Register)
현재 실행중인 명령어를 보관한다. -
ACC (Accumulator) == 누산기
ALU에서의 연산의 결과값을 일시적으로 보관한다.
1.4 x86, x64
- x86 이라는 단어의 뜻은 인텔(INTEL)의 CPU 시리즈 이름이자 그 CPU의 명령체계 아키텍쳐 이름이다.
1.4.1 16비트 CPU (x86-IA16) 8086, 8088
-
1978년 Intel 인텔이 최초의 16bit CPU인 8086을 발표했고, 다음 해에 좀 더 저렴한 8088 CPU를 발표했는데 미국 IBM에서 공개형 표준 PC(Personal Computer)인 IBM-PC XT 의 메인 CPU로 인텔의 8088을 채택하였다.
-
8086과 8088 중에서 CPU내부의 8086 명령어 체제를 x86 아키텍쳐(x86-IA16)라고 하였다.
-
IA라는 약자는 Intel Architecture 를 뜻하고 16은 16비트라는 뜻이다.
1.4.2 32비트 CPU (x86-IA32) 80386
- 80386 은 기존 16bit 인 8086, 80286 체계와의 호환성을 버리고 32bit CPU 명령세트 및 기초를 새롭게 만든 것이며, 이것을 x86-IA32 (Intel Architecture-32) 라고 공식적으로 명명하였다.
1.4.3 64비트 CPU (IA-64, x64)
-
인텔은 2001년에 차세대 64bit CPU에 대한 개발을 계속 진행 중이었는데 최종적으로는 기존 32bit x86 호환체계를 버리고 새로운 설계를 하기로 결정한다.
-
즉, x86이라는 시리즈 꼬리표를 버리고 기존 32bit 80386 CPU의 x86-IA32와 호환되지 않는 완전히 새로운 64비트 CPU 명령세트 구조를 설계하였고 이를 IA-64 (Intel Architecture-64) 라고 호칭하였다.
-
그리고 Microsoft가 Intel에 IA-64를 간단하게 x64라고 부르는 것을 제안하면서 windows os 버전을 발표할 때 x64를 사용하기 시작했다.
1.4.4 32, 64비트 CPU (x86-64, AMD64)
-
AMD는, 1999년에 기존의 인텔 32비트 x86 IA-32와 호환되는 확장형 64비트 명령세트를 설계하여 이것을 x86-64 라고 발표하고, AMD64로 이름을 바꾸면서 홍보함.
-
현재까지도 대다수의 개인용 PC에서 사용되고 있는 64bit 아키텍쳐이다.
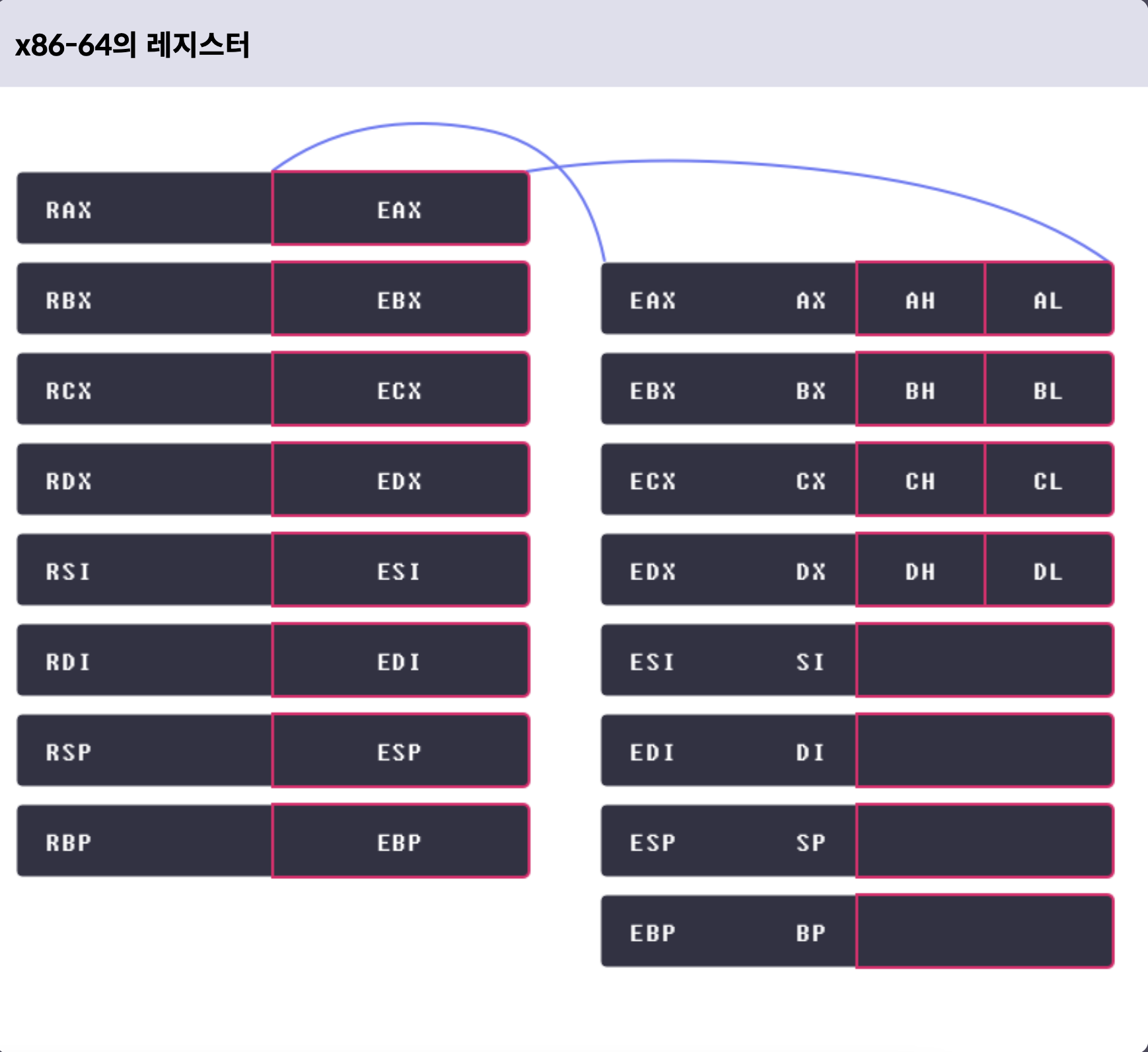
x86-64 아키텍쳐 레지스터
-
범용 레지스터
rax ( accumulator register ) 함수의 반환 값
rbx ( base register ) 주된 용도 없음
rcx ( counter register ) 반복문의 반복 횟수 , 각종 연산의 시행 횟수
rdx ( data register ) 주된 용도 없음
rsi ( source index ) 데이터를 옮길 때 원본을 가르키는 포인터
rdi ( destination index ) 데이터를 옮길 때 목적지를 가르키는 포인터
rsp ( stack pointer ) 사용중인 스택의 위치를 가르키는 포인터
rbp ( stack base pointer ) 스택의 바닥을 가르키는 포인터 -
세그먼트 레지스터
Stack Segment (SS). 스택을 가리킨다.
Code Segment (CS). 코드를 가리킨다.
Data Segment (DS). 데이터를 가리킨다.
Extra Segment (ES). 추가적인 데이터를 가리킨다 ('Extra'의 첫 글자 'E').
F Segment (FS). 많은 추가적인 데이터를 가리킨다 ('E' 다음은 'F').
G Segment (GS). 더 많은 추가적인 데이터를 가리킨다 ('F' 다음은 'G').
( 현대의 x64 아키텍처에서는 cs, ds, ss 레지스터는 코드 영역과 데이터, 스택 메모리 영역을 가르킬 때 사용한다.)
-
명령어 포인터 레지스터
CPU가 어느 부분을 실행할지 가르키는 레지스터이다.x64 아키텍처의 명령어 레지스터는 rip 이며 , 크기는 8바이트이다.
-
플래그 레지스터
프로세서의 현재 상태를 저장하고 있는 레지스터CF ( Carry Flag ) 부호 없는 수의 연산 결과가 비트의 범위를 넘을 경우 설정
ZF ( Zero Flag ) 연산의 결과가 0일 경우에 설정
SF ( Sign Flag ) 연산의 결과가 음수일 경우에 설정
OF ( Overflow Flag ) 부호 있는 수의 연산 결과가 비트 범위를 넘을 경우 설정 -
레지스터의 호환
x86-64 아키텍처는 IA-32의 64비트 확장 아키텍처이며, 호환이 가능하다.
추가적으로
-
windows와 Linux에서 보통 x86 이라고 부르면 32bit CPU용 OS이고, x64라고 부르면 64bit CPU용 OS 라고 통용된다.
-
Linux에서 CPU가 64bit 를 지원하는데 굳이 일부러 x86용 32bit OS 윈도우나 리눅스를 설치할 필요는 없다.
-
그런데 32bit로 OS를 설치하면 레지스터 입출력이 32bit로만 동작하므로 성능이 하락하고, 더 심각한 문제는 메모리 용량 최대 4GB 한계가 발생한다.
-
왜냐하면 시스템이 처음 시작될 때 메모리를 사용하기 위해서 시스템에 장착된 모든 메모리 공간의 주소 정보를 담은 지도인 PAM (Physical Address Map) 을 만드는데, 이렇게 만들어진 PAM정보를 Windows나 Linux에 넘겨준다.
-
OS는 이렇게 넘겨받은 PAM에 그 주소가 할당된 메모리만을 사용할 수 있어서 PAM에 포함되지 못한 메모리 공간은 OS에서 인식할 수도 없고, 결국 사용할 수도 없어진다.
-
여기서 32비트 체계의 할당할 수 있는 전체 메모리 공간의 개수는 2^32 * Byte = 4GB 이므로 결론적으로 32bit는 PAM에 전체 메모리 주소의 크기가 4GB의 크기를 가지게 되었다.
2. 기억장치 (메모리)
- 전자회로에서 데이터나 상태, 명령어 등을 기록, 기억하는 장치- CPU에서 나온 결과물을 레지스터를 통해 데이터를 메모리에 저장한다.(하드디스크 같은 보조기억장치는 해당X)
2.1 Segment
- 적재되는 데이터의 용도별로 메모리의 구획을 나눈 것- 리눅스에서는 프로세스의 메모리를 크게 5가지의 Segment로 구분
2.1.1 Code Segment == Text Segment
- 실행 가능한 기계 코드가 위치하는 영역-
주어지는 권한은 읽기 및 실행이다.
왜냐하면, 프로그램이 동작하려면 코드를 실행할 수 있어야하기 때문이다. -
만약 쓰기 권한이 있다면?
공격자가 악의적인 코드 삽입하기 쉬움.
그래서 대부분의 현대 운영체제는 Code Segment에 쓰기 권한 부여 X
2.1.2 Data Segment
- 컴파일 시점에 값이 정해진 전역 변수 및 전역 상수-
주어지는 권한은 읽기 및 쓰기이다. (쓰기는 일부)
-
읽기는 CPU가 이 Segment의 Data를 읽을 수 있어야하기 때문이다.
- 가능 : 전역 변수와 같이 프로그램이 실행되면서 값이 변할 수 있는 데이터들이 위치 (Data Segment)
- 불가능 : 프로그램이 실행되면서 값이 변하면 안되는 데이터들이 위치 (read-only data = rodata)
o 전역으로 선언된 상수가 여기에 포함된다.
2.1.3 BSS Segment
- 컴파일 시점에 값이 정해지지 않은 전역 변수가 위치-
개발자가 선언만 하고 초기화하지 않은 전역변수 등이 포함됨.
-
BSS Segment 는 프로그램이 시작될 때, 모두 0으로 값이 초기화 됨.
-
주어지는 권한은 읽기 및 쓰기이다.
2.1.4 Stack Segment
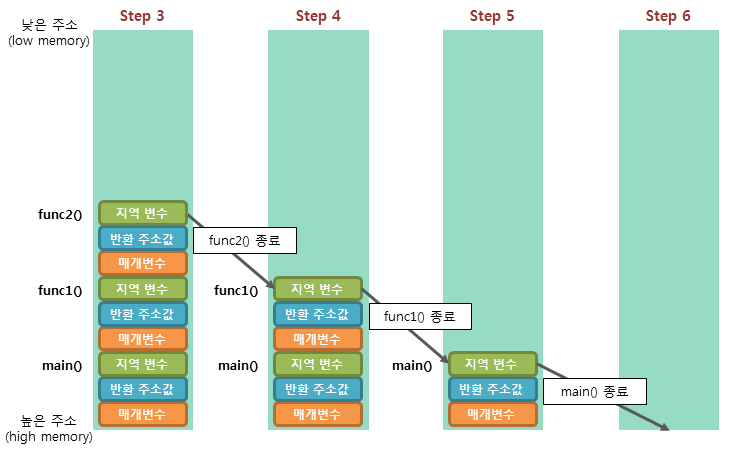
- 프로세스의 스택이 위치하는 영역- 함수의 인자나 지역 변수와 같은 임시 변수들이 실행중에 이곳에 저장.
- Stack Frame은 함수가 호출될 때 생성되고, 반환될 때 해제된다.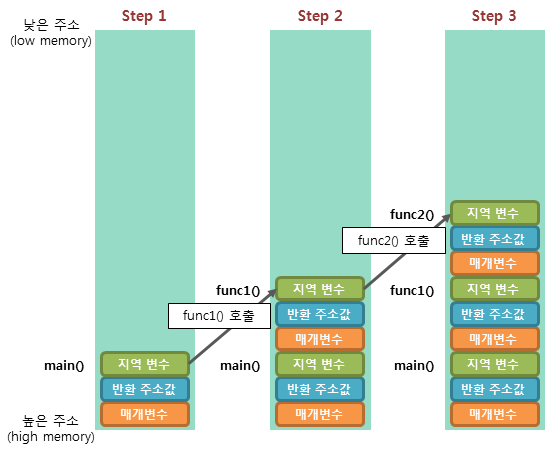
-
프로그램의 전체 실행 흐름은 사용자의 입력을 비롯한 여러 요인에 영향을 받음.
-
따라서, 어떤 프로세스가 실행될 때, 이 프로세스가 얼만큼의 Stack Frame을 사용하게 될지 예상하는 것은 일반적으로 불가능하다.
-
그래서 운영체제는 프로세스 시작 시 작은 크기의 Stack Segment 를 먼저 할당하고, 부족해질 때 마다 이를 확장한다.
-
Stack은 확장될 때, 기존 주소보다 낮은 주소로 확장된다.
-
printf() 라든지, scanf() 라든지, strcpy()와 같이 기본적으로 헤더파일 내부에서 제공해주는 함수들은 라이브러리 라는 영역에 있다.
-
주어지는 권한은 읽기와 쓰기이다.
추가적으로) 스택이란?
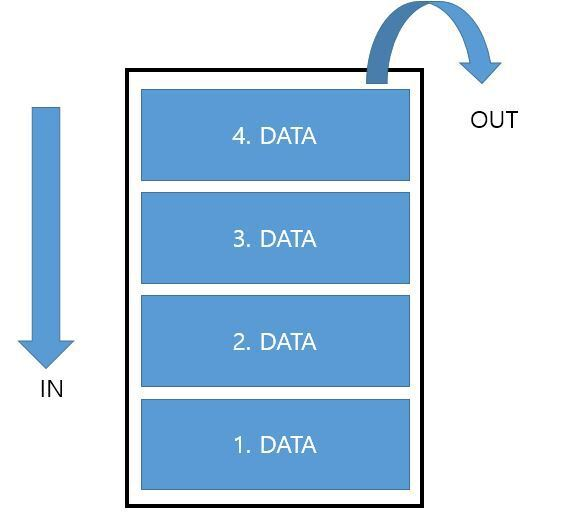
- 자료구조의 한 종류로 후입선출(Last In First Out) 이다. == LIFO
- PUSH
PUSH는 스택에 자료를 삽입하기 위해서 사용하는 명령으로,
스택의 가장 위(1.DATA)에 자료가 쌓이게 된다.
스택의 위, 아래가 헷갈리다면 Stack Frame 그림 참고.
- POP
POP은 스택에 쌓인 자료를 꺼내기 위해서 사용하는 명령으로,
스택의 가장 위에 있는 자료를 꺼낸다.
- PEEK
PEEK은 스택에 샇인 자료 중
가장 위에 쌓인 자료를 읽기 위해서 사용하는 명령이다.
POP 명령은 데이터를 꺼냄과 동시에 삭제하는 반면에,
PEEK 명령은 데이터를 꺼내기만 하고 삭제는 하지 않는다.
- EMPTY
EMPTY는 스택이 비어 있다면 TRUE, 비어있지 않다면 FALSE를 리턴하는 명령이다.
- Stack Overflow
Stack Overflow는 스택이 가득차 있을 때 PUSH 명령을 수행하면 발생하는 오류이다.
- Stack Underflow
Stack Underflow는 스택이 비어있을 때 POP 명령을 수행하면 발생하는 오류이다.
2.1.5 Heap Segment
- Heap Data 가 위치하는 Segment.-
Stack 과 마찬가지로 실행중에 동적으로 할당될 수 있음
-
C언어에서 malloc(), calloc() 등을 호출해서 할당받는 메모리 = Heap Segment에 위치.
-
주어지는 권한은 읽기와 쓰기이다.
2.2 Segment와 Section의 구분
- 프로그램이 실행될 때 비슷한 기능끼리 나눈 부분을 Segment라고 한다.
- 실행 가능한 파일의 속의 나눈 부분을 Section라고 한다.
