🎯 목표
- 로컬 LLM 서버 구축
- ollama-webui 를 사용하여 ChatGPT 와 같은 GUI 환경 구축
⚙️ 환경 정보
내 개인 홈서버 환경은 다음과 같다.
| 정보 | 설명 |
|---|---|
| CPU | Intel(R) Core(TM) i7-4578U CPU @ 3.00GHz |
| RAM | 16GB |
| OS | Ubuntu 24.04 LTS |
내 환경은 맥미니 2014 버전에 OS 만 우분투로 돌린다.
거대 언어 모델을 사용하기에는 굉장히 힘들다.
외장그래픽 카드도 없어, CPU로만 돌려볼려고 한다.
어쨌든 돌아가는 것에 의의를 두고 진행해보자.
🤷 사전 조건
- Linux 환경
- Docker 설치
- Git 설치
✨ 1. Git Clone
작업을 시작하기 전, 도커 컴포즈 파일이 필요하다.
valiantlynx 라는 github 유저가 미리 만들어 둔 것이 있으니, 사용해보도록 하자.
다만, GPU 환경이라면 최초 환경 구축 방법이 약간 다르다.
아래 깃허브 주소 내, README 에 있는 GPU 지원 방법을 따라가면 된다.
valiantlynx/ollama-docker
📌 1. 리눅스에서 작업할 부모 디렉토리 위치로 이동
cd <git clone 할 디렉토리 위치>
ex) cd /docker📌 2. Git Clone
git clone https://github.com/valiantlynx/ollama-docker.git📌 3. clone 한 디렉토리 내부로 이동
cd ./ollama-docker✨ 2. docker-Compose.yml 수정
다른 Docker 가 올라간 것이 없다면, 이 단계를 건너뛰어도 상관 없다.
📌 1. 편집기를 연다.
CPU 환경과 GPU 환경이 각기 다르니 파일명에 주의해서 열자.
# CPU 환경으로 진행할 경우
vi ./docker-compose.yml
# GPU 환경으로 진행할 경우
vi ./docker-compose-ollama-gpu.yaml
# i 를 눌러 수정모드 진입📌 2. Docker network Bridge를 기존에 사용하고 있다면 수정해주자.
해당 내용을 모르거나, 기존에 사용하지 않았다면 넘어가자.
모든 network 환경 값을 다음과 같이 변경한다.
service가 3개니, 3번 변경해주어야 한다. (app, ollama, ollama-webui)
networks:
- <당신이 사용하는 브릿지명>
ex)
networks:
- npmnetworks:
<당신이 사용하는 브릿지명>:
external:
name: <당신이 사용하는 브릿지명>
ex)
networks:
npm:
external:
name: npm📌 3. ollama-webui 서비스 외부포트 변경
이 항목은 필요한 사람만 진행하면 된다.
ollama-webui 는 ChatGPT 와 비슷한 GUI 환경을 제공해준다.
해당 서비스의 외부포트는 현재 8080 을 사용 중이라, 다른 서비스가 올라가 있다면 포트 충돌이 발생할 수 있다.
# 변경해야 될 것
version: '3.8'
services:
ollama-webui:
ports:
- 8080:8080
# 위에서 왼쪽 8080을 아래와 같이 변경한다.
ports:
- <원하는 외부포트 번호>:8080
ex)
ports:
- 9040:8080📌 4. 저장하고 나오기
# 1. esc 를 누르고
# 2. :wq 를 입력하고 엔터✨ 3. Docker Compose 실행
이제 Docker 컨테이너를 생성해보자
# CPU 환경으로 진행할 경우
sudo docker compose -f ./docker-compose.yml up -d
# GPU 환경으로 진행할 경우
sudo docker compose -f ./docker-compose-ollama-gpu.yml up -d아래처럼 서비스 3개가 Started로 나온다면 정상이다.
$ /docker/ollama-docker$ sudo docker compose -f ./docker-compose.yml up -d
WARN[0000] network npm: network.external.name is deprecated. Please set network.name with external: true
[+] Running 1/1
✔ ollama Pulled 2.1s
[+] Building 0.0s (0/0)
[+] Running 3/3
✔ Container ollama Started 0.4s
✔ Container ollama-webui Started 0.7s
✔ Container ollama-docker-app-1 Started 문제가 생겨서 Docker 컨테이너를 내리고 싶다면 아래처럼 하면 된다.
# CPU 환경으로 진행할 경우
sudo docker compose -f ./docker-compose.yml down
# GPU 환경으로 진행할 경우
sudo docker compose -f ./docker-compose-ollama-gpu.yml down번외) docker-compose 와 docker compose 차이
기존 python 으로 작성되었던 docker-compose 에 기능을 추가하여 go 언어로 작성한 것이 docker compose 이다.
결론만 본다면 다음과 같다.
docker-compose 는 V1, 즉 이전 버전의 Docker Compose
docker compose 는 V2, 신규 버전이다.Compose V1과 달리 Compose V2는 Docker CLI 플랫폼에 통합되었으며,
2023년 7월부터 Compose V1은 지원이 종료되었다.
docker document따라서 앞으로는 docker compose 를 사용하도록 하자.
✨ 4. 언어모델 선택
언어모델을 설치하기 전, 아래 주소로 들어가 사용할 언어모델을 선택하자.
https://ollama.com/library
개인 환경에 따라 선택하면 된다.
내 환경에서는 qwen2의 에서 1.5b 가 그나마 제일 팬 소음이 덜한 것 같다.
CPU로 돌릴거면 parameters 항목이 2.0b 이하인 것으로 하는게 좋을 것 같다.
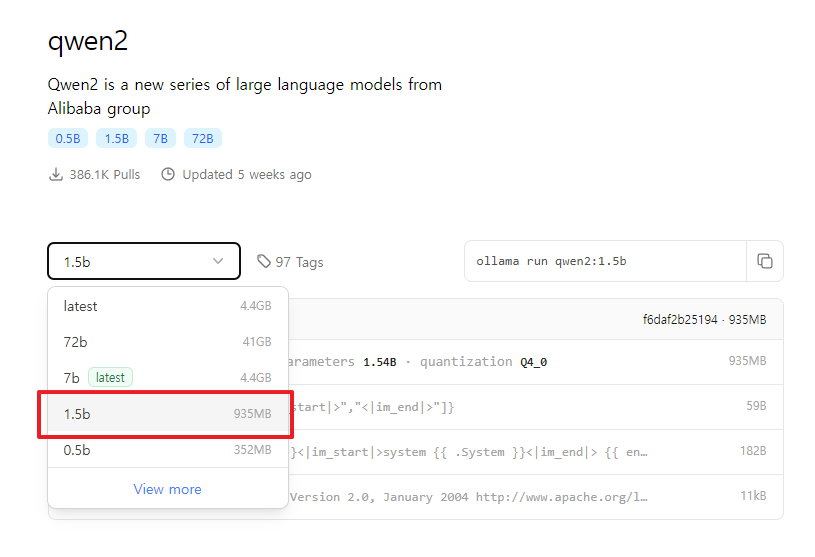
사용할 모델을 결정했다면 아래 사진에 표시해둔 버튼을 누르고 다른 곳에 붙여넣기 해두자.
나중에 언어모델 설치 시 사용할 것이다.
✨ 5. 언어모델 설치
언어모델은 ollama 도커 컨테이너 내부에 설치한다.
이전 compose.yml 파일에서 ollama 서비스의 컨테이너명을 ollama로 지정해두었다.
컨테이너 내부로 진입해 ollama 명령어를 사용해 모델을 설치한다.
📌 1. bash를 사용해 컨테이너 내부로 진입
docker exec -it ollama /bin/bash📌 2. 컨테이너 내부에서 ollama 명령어로 언어모델 설치
4번에서 복사해둔 텍스트를 붙여넣기 하면 된다.
ollama run qwen2:1.5bollama run 은 언어모델을 실행하는데, 언어모델이 없으면 자동으로 받는다.
언어모델이 다 설치되면 이후 자동으로 실행한다.
이것 말고 단순 설치만 하려면 아래처럼 하면 된다.
ollama pull qwen2:1.5b📌 3. 언어모델 설치 대기
인터넷 환경에 따라 설치가 오래될 수 있다.
아래처럼 success 가 뜨면 성공이다.
root@6b2e5bb34042:/# ollama run qwen2:1.5b
pulling manifest
pulling 405b56374e02... 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 934 MB
pulling 62fbfd9ed093... 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 182 B
pulling c156170b718e... 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 11 KB
pulling f02dd72bb242... 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 59 B
pulling c9f5e9ffbc5f... 100% ▕███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success
>>>✨ 6. CLI로 언어모델 사용하기
여기까지 왔으면 목표의 대부분은 성공한 것이다.
아래처럼 >>> 이 표시되면 CLI 입력모드 상태이다.
이제 타이핑하여 언어모델에게 물어보면 된다.
root@6b2e5bb34042:/# ollama run qwen2:1.5b
>>> hello! 라고 입력해보았다.
root@6b2e5bb34042:/# ollama run qwen2:1.5b
>>> hello!
Hello! How can I help you today? Are you looking for information or assistance with a particular topic? Please let me know and I'll do my best to assist you.이어서 안녕! 이라고 입력해보았다.
>>> 안녕!
안녕하세요! 어떻게 도와드릴까요?입력 모드를 종료하려면 Ctrl + D 를 누르자.
그리고 다음 단계 진행을 위해, ollama 컨테이너 바깥으로 나오도록 하자.
✨ 7. GUI로 언어모델 사용하기
내부 IP 주소, 혹은 외부 IP 주소는 당연히 알고 있을 것이라 생각한다.
📌 1. 홈서버 로컬 IP
로컬 IP가 기억이 나지 않는다면, 아래 명령어를 입력한다.
ip -4 addr show | grep -oP '(?<=inet\s)\d+(\.\d+){3}' | grep -v '127.0.0.1'외부 IP로 접속하려면 공유기 포트포워딩을 하던지, Nginx 등으로 리버스프록시 환경 구성을 해야한다.
외부 IP 부분은 생략.
📌 2. ollama-webui 서비스 포트 번호
위에서 ✨ 2. Docker Compose 파일 수정 항목을 수정할 때로 되돌아가 보자.
ollama-webui 서비스의 외부 포트 변경을 하라고 했던 것이 기억 날 것이다.
ports:
- <원하는 외부포트 번호>:8080📌 3. 브라우저 접속
이제 브라우저 주소창에 다음과 같이 입력한다.
다른 PC에서 작업한다면, 꼭 홈서버와 WIFI 나 LAN 연결이 되어있어야 한다.
http://<당신의 서버 로컬서버 IP>:<당신이 입력했던 외부포트 번호>이제 다음과 같은 채팅 UI가 우리를 반겨준다.
사실 레퍼 찾아보면서 webui 처음 접속하면 사용자 등록부터 해야한다고 다른 글에서 봤다.
근데 valiantlynx 가 그 작업은 안하도록 사용자 등록까지 다 끝내놓은 것 같다.
📌 4. 언어모델 가져오기
이제, 방금 전에 ollma 내부 컨테이너에 설치했던 언어모델을 가져오도록 하자.
좌측 하단의 User를 눌러 컨텍스트 메뉴를 연다.
설정 버튼을 눌러 팝업창을 호출하자.
팝업창이 열리면 좌측 메뉴 중 관리자 설정 항목을 누른다.
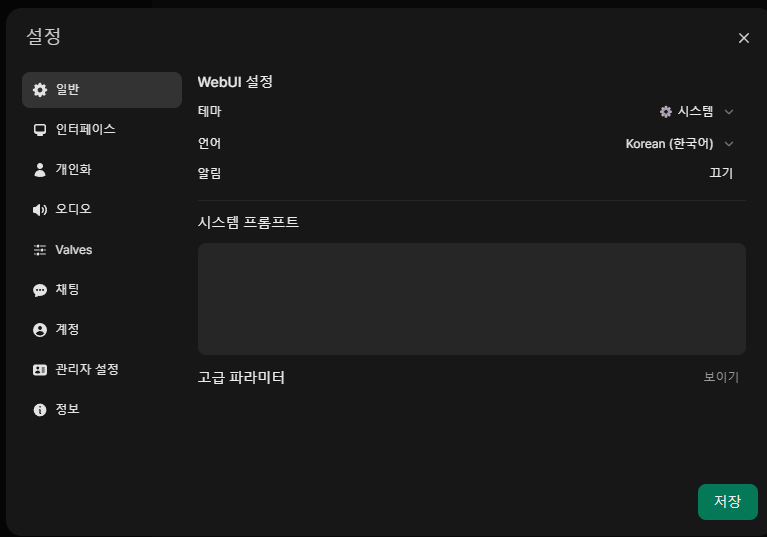
이제 관리자 패널 이 열리면 연결 탭을 누른다.
지금은 스크린샷 찍으려고 좌우 폭을 줄여놔서 상단에 메뉴탭이 보이는데,
정상적인 상태면 좌측에 메뉴탭이 나올 것이다.
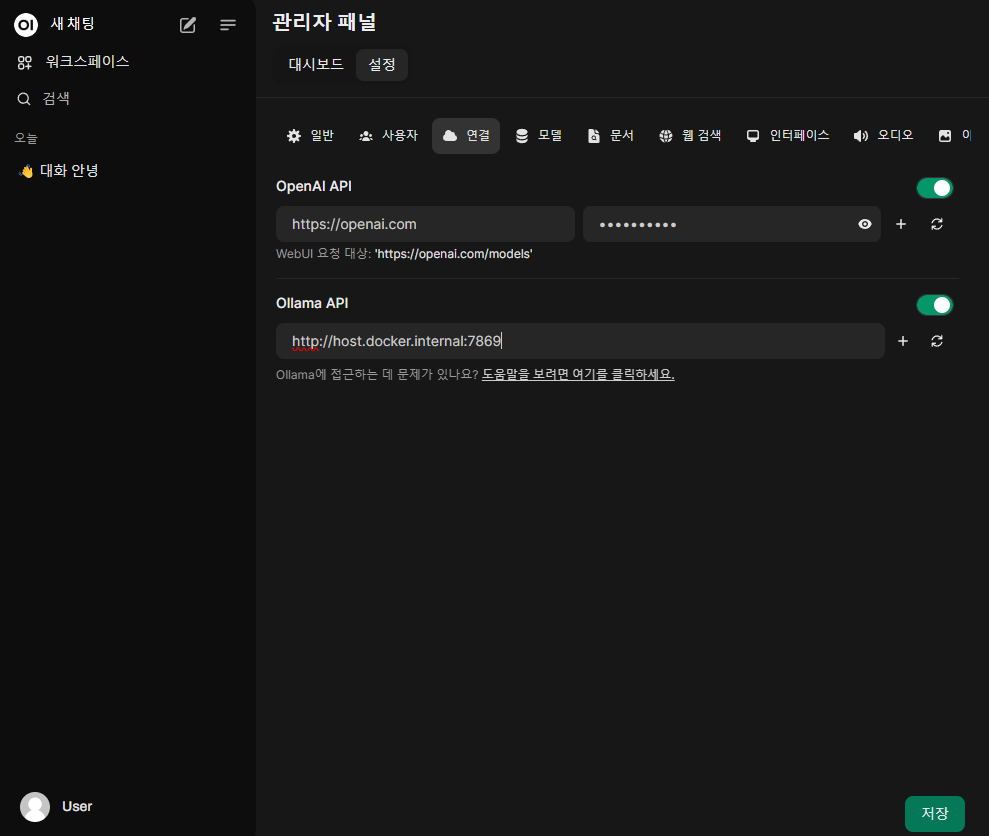
Ollama API 항목을 수정한다.
해당 항목에 넣을 값은 다시 docker-compose.yml 로 돌아가 확인할 수 있다.
...
version: '3.8'
services:
...
ollama-webui:
...
environment:
- OLLAMA_BASE_URLS=http://host.docker.internal:7869
...바로 OLLAMA_BASE_URLS 키 값을 입력해주면 된다.
입력하고, 좌측 하단의 저장 버튼을 누르자.
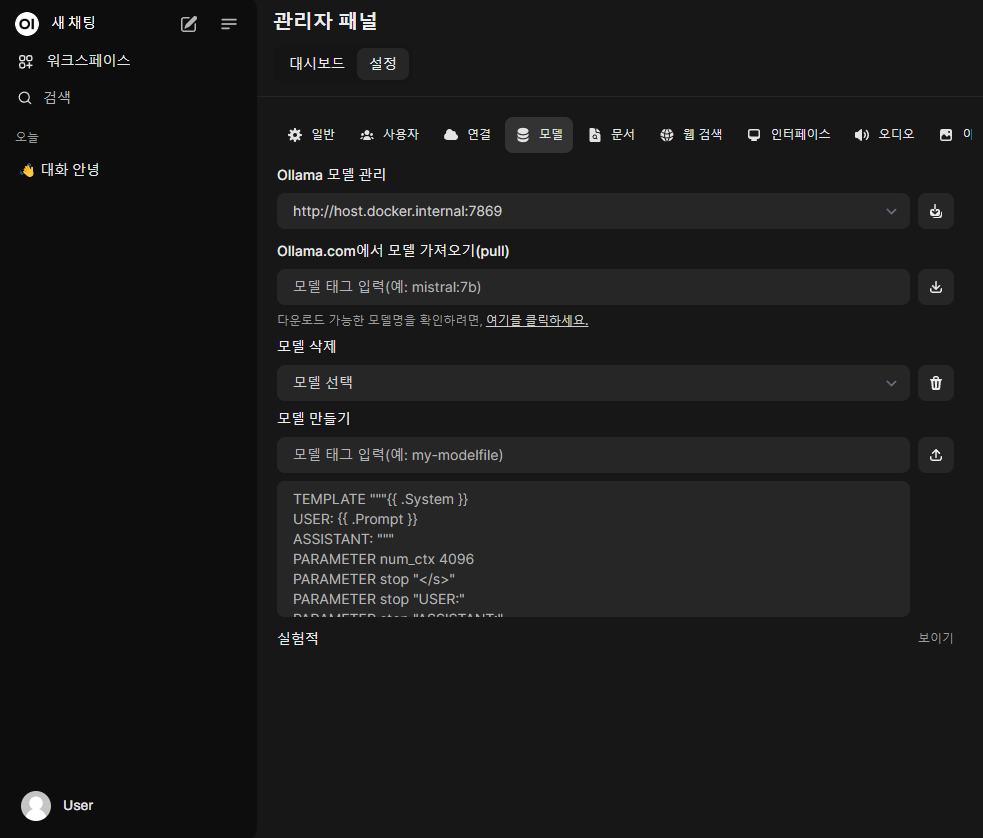
이제 모델 탭으로 넘어간다.
이전 탭에서 저장까지 눌렀다면 Ollama 모델 관리 항목이 입력했던 키값으로 나올 것이다.
http://host.docker.internal:7869
다음으로, Ollama.com에서 모델 가져오기(pull) 항목에 언어모델명을 입력하면, 설치했던 언어모델을 webui 로 가져올 수 있다.
작성한대로 동일하게 따라왔다면 qwen2:1.5b 를 입력하고 우측의 다운로드 버튼을 눌러 가져온다.
📌 5. 언어모델 기본값 설정
좌측 메뉴 중 새 채팅 버튼을 눌러 메인 화면으로 돌아오자.
나는 지금 언어모델 기본 값을 설정해놔서 언어모델명이 바로 화면상에 표시된다.
우선 아래 화살표 버튼을 눌러 사용할 언어모델을 선택해두자.
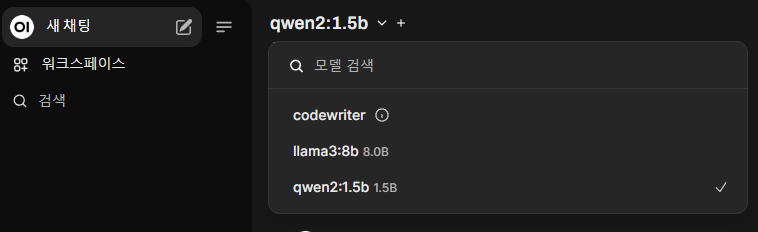
📌 6. 언어모델 사용
이제 하단의 메시지 보내기 입력창에 ChatGPT를 사용하는 것처럼 LLM 과 대화하면 된다.
✨ 8. GUI 사용 예시
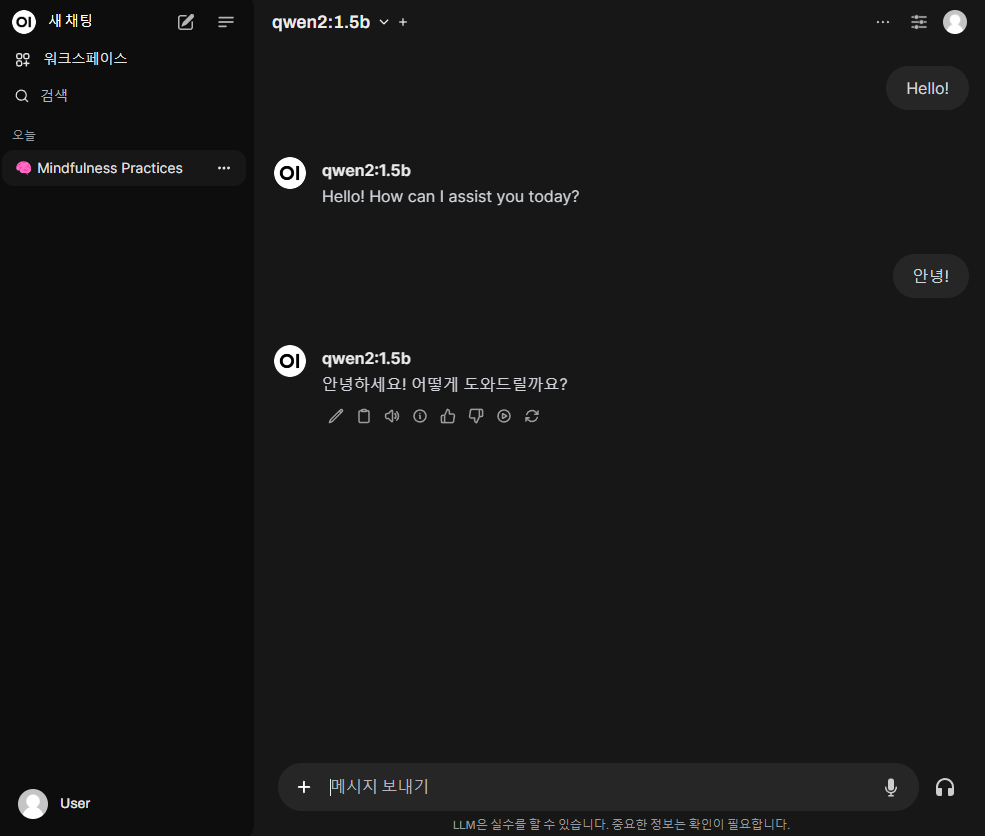

안녕하세요! 로컬LLM구축에 대한 글 잘 보았습니다. 서버 스펙이 저와 비슷해서 혹시
현 시점에서 사용하시는데에 무리는 없으셨는지와 어느정도 작업까지 정확성있게 해내는지 궁금한데요!
혹시 리뷰를 살짝 해주실 수 있나요?