🥙 MST가 무엇이고, 어떻게 구할 수 있을지 설명해 주세요.
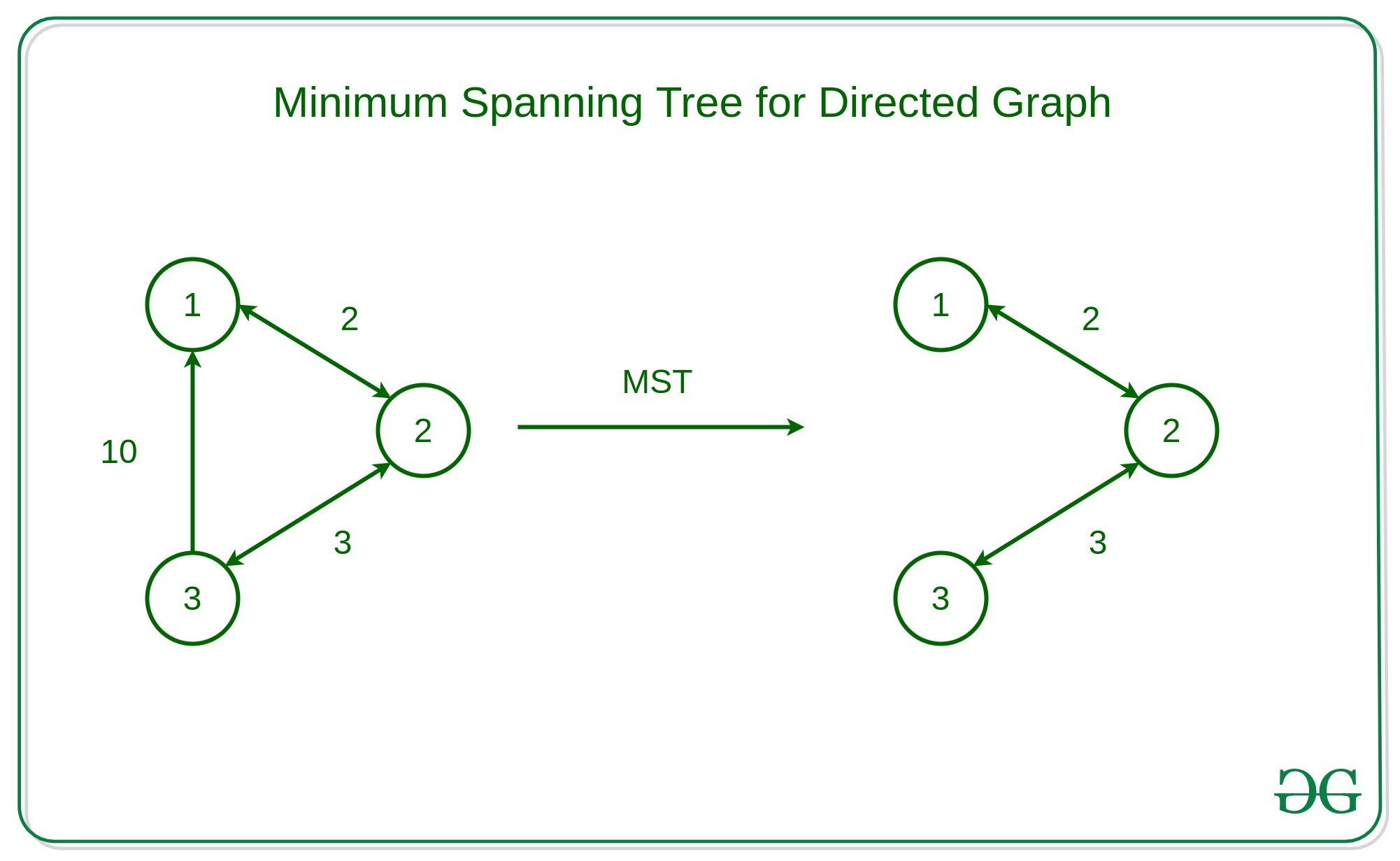
MST(최소 스패닝 트리, Minimum Spanning Tree)는 가중치가 있는 연결 그래프에서 모든 정점을 연결하는 부분 트리 중 간선의 가중치 합이 최소가 되는 트리를 의미합니다.
즉, 그래프의 모든 정점을 포함하면서 사이클이 없고, 간선들의 가중치 총합이 최소가 되는 트리입니다.
MST를 구하는 알고리즘에는 대표적으로 크루스칼 알고리즘(Kruskal's Algorithm)과 프림 알고리즘(Prim's Algorithm)이 있습니다.
크루스칼 알고리즘 개요
- 간선 정렬: 모든 간선을 가중치의 오름차순으로 정렬합니다.
- Union-Find 자료구조: 사이클 생성을 방지하기 위해 각 정점을 서로소 집합(Union-Find)으로 관리합니다.
- 간선 선택: 정렬된 간선을 순회하며, 해당 간선이 서로 다른 집합에 속하는 정점들을 연결한다면(즉, 사이클이 형성되지 않는다면) 간선을 선택하고 두 집합을 합칩니다.
- 종료 조건: MST는 정점의 개수가 ( V )일 때, ( V-1 )개의 간선을 선택하면 완성됩니다.
프림 알고리즘 개요
- 시작 정점 선택: 임의의 정점을 시작 정점으로 선택합니다.
- 우선순위 큐(혹은 자료구조) 준비: 현재까지 선택된 정점과 연결되면서, 선택되지 않은 정점으로 갈 수 있는 간선 중 가중치가 가장 작은 간선을 빠르게 찾기 위해 우선순위 큐(최소 힙 등)를 사용합니다.
- 간선 선택 반복:
- 우선순위 큐에서 가중치가 가장 작은 간선을 꺼냅니다.
- 해당 간선이 아직 MST(최소 스패닝 트리)에 포함되지 않은 정점을 연결한다면(즉, 새로운 정점을 확장할 수 있다면) 그 간선을 MST에 추가하고 새로 연결된 정점에서 뻗어나가는 모든 간선을 우선순위 큐에 추가합니다.
- 종료 조건:
- 모든 정점이 MST에 포함되면 알고리즘을 종료합니다.
- 결과적으로 MST의 간선 수는 (V - 1)개이며, 여기서 (V)는 정점의 개수입니다.
프림 알고리즘은 이미 선택된 정점 집합에서 새로 연결할 수 있는 정점을 찾아 나가는 방식이므로, 한 번에 한 정점씩 MST에 포함시키는 접근 방식입니다.
크루스칼 알고리즘
// Edge 클래스 예시: (u, v, w)는 정점 u와 v를 연결하는 가중치 w의 간선
class Edge {
int u, v, w;
Edge(int u, int v, int w) {
this.u = u;
this.v = v;
this.w = w;
}
}
// Union-Find 자료구조 (Disjoint Set)
class UnionFind {
int[] parent, rank;
UnionFind(int n) {
parent = new int[n];
rank = new int[n];
for(int i = 0; i < n; i++) parent[i] = i;
}
int find(int x) {
if(parent[x] == x) return x;
return parent[x] = find(parent[x]);
}
void union(int x, int y) {
int rx = find(x);
int ry = find(y);
if(rx != ry) {
if(rank[rx] < rank[ry]) parent[rx] = ry;
else if(rank[rx] > rank[ry]) parent[ry] = rx;
else {
parent[ry] = rx;
rank[rx]++;
}
}
}
}
List<Edge> kruskalMST(List<Edge> edges, int V) {
// 1. 간선들을 가중치 오름차순으로 정렬
edges.sort((e1, e2) -> e1.w - e2.w);
// 2. Union-Find(서로소 집합) 구조 초기화
UnionFind uf = new UnionFind(V);
List<Edge> MST = new ArrayList<>();
int edgeCount = 0;
// 3. 간선을 순회하며, 두 정점이 다른 집합이면 연결(사이클 방지)
for (Edge e : edges) {
if (uf.find(e.u) != uf.find(e.v)) {
uf.union(e.u, e.v);
MST.add(e);
edgeCount++;
// 모든 정점을 연결했다면 종료
if (edgeCount == V - 1) break;
}
}
return MST;
}
프림 알고리즘
// Edge 클래스 (u -> v, 가중치 w)
// 그래프는 보통 인접 리스트(graph[u] 안에 (v, w) 형태의 Edge 리스트가 있다고 가정)
List<Edge> primMST(List<Edge>[] graph, int V, int start) {
// 방문 여부 체크
boolean[] visited = new boolean[V];
// 최소 가중치 간선을 빠르게 추출하기 위한 우선순위 큐
PriorityQueue<Edge> minHeap = new PriorityQueue<>((e1, e2) -> e1.w - e2.w);
List<Edge> MST = new ArrayList<>();
int edgeCount = 0;
// 1. 시작 정점 방문 후, 연결된 간선들을 우선순위 큐에 추가
visited[start] = true;
for (Edge e : graph[start]) {
minHeap.offer(e);
}
// 2. 우선순위 큐에서 가중치가 가장 낮은 간선을 뽑아,
// 아직 방문하지 않은 정점이라면 MST에 추가
while (!minHeap.isEmpty() && edgeCount < V - 1) {
Edge e = minHeap.poll();
// e.v가 새로 방문할 수 있는 정점이라면
if (!visited[e.v]) {
visited[e.v] = true;
MST.add(e);
edgeCount++;
// 새로 방문한 정점과 연결된 간선을 큐에 추가
for (Edge next : graph[e.v]) {
if (!visited[next.v]) {
minHeap.offer(next);
}
}
}
}
return MST;
}크루스칼 알고리즘 vs 프림 알고리즘
| 항목 | 크루스칼 알고리즘 | 프림 알고리즘 |
|---|---|---|
| 알고리즘 방식 | 전체 간선을 가중치 기준으로 정렬한 후, 간선을 하나씩 선택하며 사이클을 방지 (Union-Find 사용) | 시작 정점에서부터 인접한 정점들 중 최소 가중치 간선을 선택해 확장 (우선순위 큐 사용) |
| 자료구조 | 정렬된 간선 리스트, Union-Find | 인접 리스트, 우선순위 큐 |
| 적용 방식 | 간선 중심 알고리즘 | 정점 중심 알고리즘 |
| 그래프 특성 | 희소 그래프와 밀집 그래프 모두 사용 가능 | 주로 밀집 그래프에서 효율적 |
| 시간 복잡도 | (O(E log E)) (E: 간선 수) | (O(E log V)) (V: 정점 수) |
| 구현의 난이도 | 비교적 단순한 구현, 사이클 판별이 핵심 | 우선순위 큐 관리가 필요하여 구현이 약간 복잡할 수 있음 |
🥙 Kruskal 알고리즘에서 사용하는 Union-Find 자료구조에 대해 설명해 주세요.
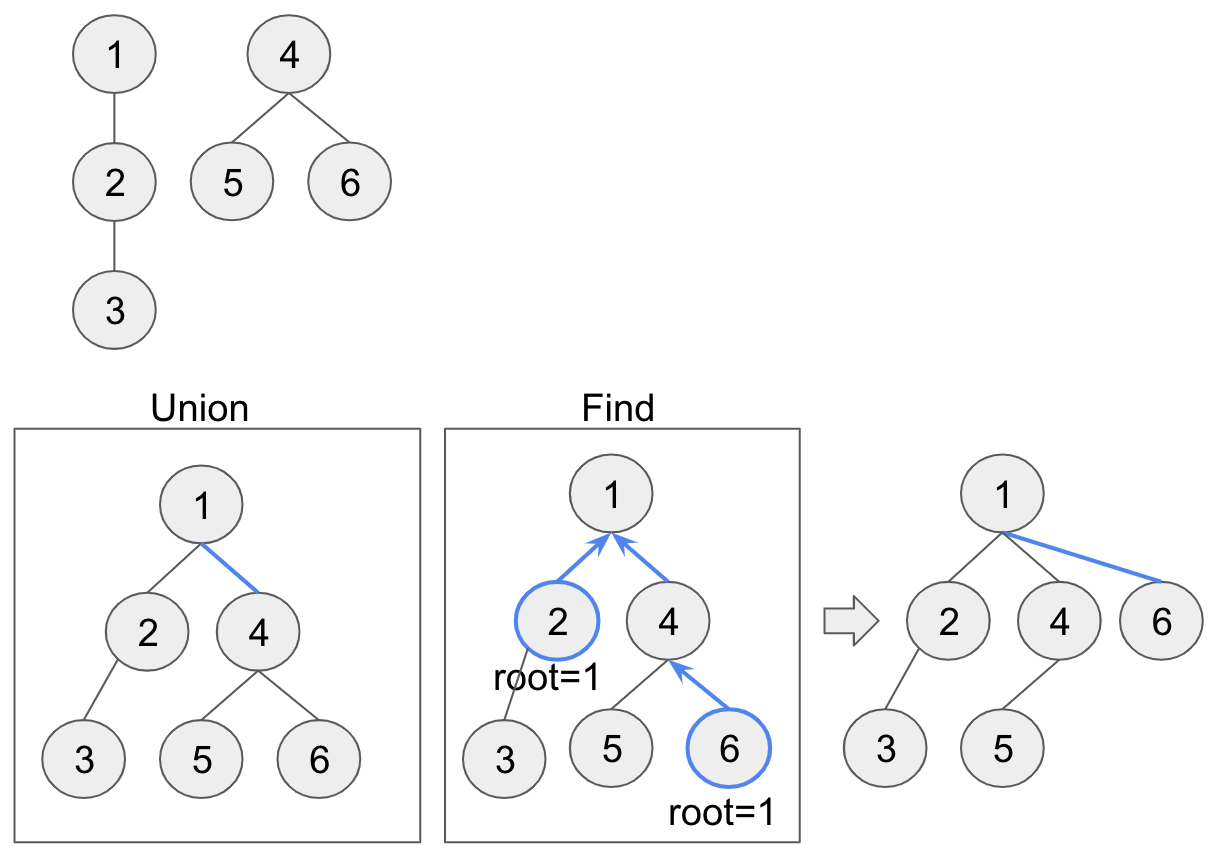
Union-Find 자료구조는 서로소 집합을 관리하기 위한 자료구조입니다. Kruskal 알고리즘에서는 그래프의 정점들이 서로 어떤 집합에 속하는지 관리하여, 새로운 간선을 선택할 때 사이클이 형성되는지를 빠르게 판별하는 데 사용됩니다.
주요 기능
- find:
주어진 원소가 속한 집합(대표 원소 혹은 루트)을 찾습니다. 이 과정에서 경로 압축(Path Compression) 기법을 사용하면 이후의 검색 시간이 단축됩니다. - union:
두 원소가 속한 집합을 하나로 합칩니다. 합칠 때는 보통 두 집합의 크기나 높이를 고려하는 방법(Union by Rank 또는 Union by Size)을 사용하여 효율적으로 합집합을 구성합니다.
동작 과정
-
초기화:
모든 정점을 각각 독립된 집합으로 초기화합니다. 즉, 각 정점의 부모(parent)는 자기 자신이 됩니다. -
find 연산:
두 정점을 연결하는 간선을 고려할 때, 각 정점의 루트(대표)를 찾습니다.- 만약 두 정점의 루트가 같다면, 이 간선을 추가하면 사이클이 발생합니다.
- 루트가 다르다면, 두 정점은 서로 다른 집합에 속하므로 해당 간선을 MST에 추가하고 두 집합을 union 연산으로 합칩니다.
-
union 연산:
두 집합의 대표를 찾은 후, 두 집합을 합칩니다. 이때, 경로 압축과 union by rank 기법을 함께 사용하면 전체 연산의 시간 복잡도를 거의 상수에 가깝게 개선할 수 있습니다.
🥙 Kruskal과 Prim 중, 어떤 것이 더 빠를까요?
그래프의 특성과 사용되는 자료구조에 따라 달라집니다.
-
희소 그래프 (간선 수 E가 정점 수 V에 비해 적은 경우):
- Kruskal: 간선을 정렬하는 데 (O(E log E)) 시간이 소요되며, 이는 보통 (O(E log V))와 비슷합니다.
- Prim: 인접 리스트와 이진 힙을 사용할 경우 (O(E log V))의 시간 복잡도를 가집니다.
- 결론: 희소 그래프에서는 두 알고리즘 모두 비슷한 성능을 보입니다.
-
밀집 그래프 (간선 수 E가 (O(V^2))에 가까운 경우):
- Kruskal: 간선의 총 개수가 많아지면서 (O(E log E))의 비용이 매우 커질 수 있습니다.
- Prim: 인접 행렬을 사용할 경우 (O(V^2))로 구현할 수 있으며, 또는 이진 힙이나 피보나치 힙을 사용하면 더 나은 성능을 기대할 수 있습니다.
- 결론: 밀집 그래프에서는 일반적으로 Prim 알고리즘이 더 효율적으로 동작할 가능성이 높습니다.
아래 표는 간단히 정리한 비교입니다.
| 그래프 종류 | Kruskal 알고리즘 | Prim 알고리즘 |
|---|---|---|
| 희소 그래프 | (O(E log V)) – 비슷한 성능 | (O(E log V)) – 비슷한 성능 |
| 밀집 그래프 | (O(E log E)), 즉 (O(V^2 log V)) – 상대적으로 느림 | 인접 행렬: (O(V^2)), 효율적 구현 시 더 빠름 |
따라서, 어떤 알고리즘이 더 빠른지는 그래프의 밀집도와 구현 방식에 달려 있습니다.
- 희소 그래프에서는 두 알고리즘의 성능 차이가 크지 않으나,
- 밀집 그래프에서는 Prim 알고리즘이 더 유리할 수 있습니다.
또한, 구현 시 사용하는 자료구조(이진 힙, 피보나치 힙, 인접 리스트/행렬)에 따라 실제 성능 차이가 발생할 수 있습니다.
🥙 Kruskal과 Prim 알고리즘을 통해 얻어진 결과물은 무조건 트리인가요? 만약 그렇다면 증명해 주세요. 그렇지 않다면, 반례를 설명해 주세요.
GPT 답변두 알고리즘(연결된 그래프가 입력인 경우)이 반환하는 결과물이 트리임을 증명하려면, 결과 집합이 "스패닝 트리"의 세 가지 조건을 만족함을 보이면 됩니다. 즉, 결과 집합이
- 모든 정점을 포함(스패닝)
- 사이클이 없다(acyclic)
- 정점의 수가 (V)일 때 간선의 수가 (V-1)이다
는 것을 보여야 합니다.
Kruskal 알고리즘 증명
가정: 입력 그래프 (G=(V,E))는 연결된 그래프입니다.
-
초기 상태:
- 알고리즘은 각 정점을 독립적인 집합으로 보고, 빈 간선 집합 (T = {})를 초기화합니다.
- (T)는 빈 집합이므로 사이클이 없습니다.
-
간선 선택 과정(유도법 사용):
- 귀납적 가정: 지금까지 선택한 간선 집합 (T)가 사이클이 없고, 여러 개의 작은 연결 컴포넌트(서로 겹치지 않는 트리)를 이루고 있다고 가정합니다.
- 간선 추가: 알고리즘은 가중치가 낮은 순으로 간선을 고려하는데, 두 정점이 서로 다른 컴포넌트(즉, 서로 연결되지 않은 상태)에 있다면 해당 간선을 추가합니다.
- 이때, 추가하면 두 컴포넌트가 하나로 합쳐지지만 사이클은 생기지 않습니다.
- 만약 두 정점이 이미 같은 컴포넌트에 있다면, 추가하지 않으므로 사이클이 발생하지 않습니다.
- 결과: 이 과정을 반복하면 (T)는 항상 사이클이 없는 상태로 유지됩니다.
-
스패닝(연결성)과 간선의 개수:
- 연결성: 입력 그래프가 연결되어 있으므로, 최종적으로 (T)가 모든 정점을 하나의 연결된 컴포넌트로 합칠 수 있습니다.
- 간선 수: 각 간선 추가는 두 개의 분리된 컴포넌트를 합치는 역할을 하며, 시작에는 (V)개의 분리된 컴포넌트가 있습니다. 컴포넌트 하나로 합쳐지려면 (V-1)번의 합병이 필요합니다.
- 따라서 최종 (T)는 (V-1)개의 간선을 포함하고, 모든 정점을 연결하며 사이클이 없으므로 스패닝 트리의 정의를 만족합니다.
요약 증명 (Kruskal):
- (T)는 초기부터 사이클이 없으며,
- 각 간선 추가는 두 개의 컴포넌트를 합치므로,
- 최종적으로 (T)는 모든 정점을 연결하는 (V-1)개의 간선 집합이 되어 스패닝 트리임을 보일 수 있습니다.
Prim 알고리즘 증명
가정: 입력 그래프 (G=(V,E))는 연결된 그래프입니다.
-
초기 상태:
- 알고리즘은 임의의 시작 정점 (s)에서 시작합니다. 초기 트리 (T)는 ({s})로 구성되며, 이때 (T)는 사이클이 없는 상태입니다.
-
정점 확장 과정:
- 반복적 선택: 매 단계마다, (T)에 포함된 정점과 (T)에 포함되지 않은 정점 사이에서 최소 가중치 간선을 선택합니다.
- 사이클이 없는 이유:
- 선택하는 간선은 항상 (T)에 속한 정점과 (T)에 속하지 않은 정점을 연결하므로, 이미 (T) 내에 두 정점 모두 존재하지 않습니다.
- 따라서 간선을 추가해도 사이클이 형성될 수 없습니다.
- 반복: 이 과정을 반복하면 (T)에 새로운 정점이 하나씩 추가되어, 최종적으로 모든 정점을 포함하게 됩니다.
-
간선의 개수:
- 시작 정점 1개에서 시작하여, 매번 하나의 정점을 추가하므로 최종적으로 (V-1)개의 간선이 선택됩니다.
- 따라서 (T)는 (V)개의 정점을 (V-1)개의 간선으로 연결하는, 사이클이 없는 연결 그래프, 즉 트리가 됩니다.
요약 증명 (Prim):
- (T)는 시작 시 단일 정점으로 사이클이 없으며,
- 각 단계에서 (T)에 없는 정점을 최소 간선으로 추가하므로 사이클이 생길 수 없고,
- 최종적으로 (T)는 (V)개의 정점을 (V-1)개의 간선으로 연결한 스패닝 트리가 됩니다.
연결된 그래프와 스패닝 트리
-
연결된 그래프(connected graph):
그래프 내 임의의 두 정점 사이에 경로가 존재하는 그래프입니다.
이 경우, 모든 정점을 하나의 트리로 연결하는 스패닝 트리를 항상 구성할 수 있습니다. -
결과의 성질:
- 두 알고리즘 모두 연결된 그래프에 대해 모든 정점을 포함하고, 사이클이 없으며, 간선의 수가 (V-1)인 결과를 반환하므로 트리임을 증명할 수 있습니다.
반례: 입력 그래프가 연결되어 있지 않은 경우
-
만약 입력 그래프가 연결되어 있지 않다면,
-
Kruskal 알고리즘: 각 연결 컴포넌트마다 스패닝 트리를 구성하여 스패닝 포레스트를 반환합니다.
-
Prim 알고리즘: 시작 정점이 속한 컴포넌트에 대해서만 스패닝 트리를 구성합니다.
이 경우 결과물은 단일 트리가 아니라 여러 개의 트리(포레스트)이므로 "무조건 트리"라고 할 수 없습니다.
하지만 보통 MST 알고리즘은 연결된 그래프를 가정합니다.입력 그래프가 연결되어 있지 않은 경우
만약 두 정점이 서로 다른 연결 컴포넌트에 속한다면, 그 두 정점을 직접 연결하는 간선은 물론, 다른 정점들을 통해 간접적으로 연결하는 경로도 존재하지 않습니다.
즉, 두 컴포넌트 사이에는 어떤 형태의 연결(간선이나 경로)도 존재하지 않는 경우입니다..
-
결론
연결된 그래프를 입력으로 하면,
-
Kruskal 알고리즘과 Prim 알고리즘 모두 선택된 간선 집합 (T)가
- 모든 정점을 포함하고,
- (V-1)개의 간선을 가지며,
- 사이클이 없음을 보일 수 있으므로,
이는 (T)가 스패닝 트리임을 증명합니다.
이와 같이 알고리즘의 선택 과정과 최종 결과의 성질(연결, 사이클 없음, (V-1)개의 간선)을 통해 두 알고리즘이 연결된 그래프에 대해 항상 트리를 구성함을 증명할 수 있습니다.
Kruskal 알고리즘
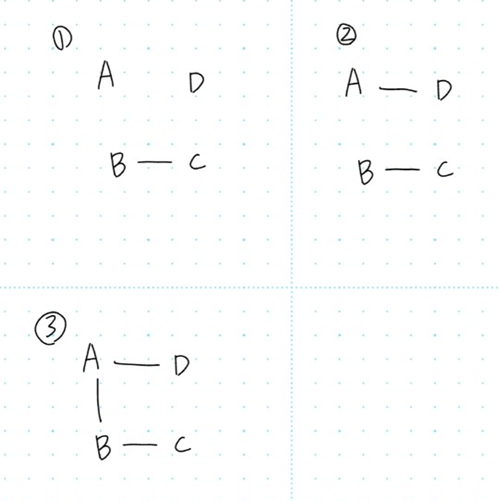
- 정점 A, B, C, D가 있고, 간선과 가중치가 다음과 같다고 가정합니다.
A-B (3), B-C (1), C-D (4), A-D (2)
-
초기 상태 – 모든 정점은 분리되어 있음
A B C D -
간선 선택 – 사이클을 만들지 않는 간선만 선택
-
첫 번째 간선 (B-C, 1):
B와 C가 다른 집합이므로 선택합니다.집합 1: {B, C} 집합 2: {A} 집합 3: {D} -
두 번째 간선 (A-D, 2):
A와 D가 다른 집합이므로 선택합니다.집합 1: {B, C} 집합 2: {A, D} -
세 번째 간선 (A-B, 3):
A는 집합 {A, D}에, B는 집합 {B, C}에 속해 있으므로 선택하면 두 집합이 연결됩니다.통합 집합: {A, B, C, D} -
네 번째 간선 (C-D, 4):
이 시점에서 A, B, C, D는 모두 같은 집합에 속하므로 추가하면 사이클이 생기므로 선택하지 않습니다.이 간선들은 모든 정점을 연결하며 (V-1) (4-1 = 3)개의 간선이므로, 사이클이 없고 트리의 조건을 만족합니다.
-
Prim 알고리즘
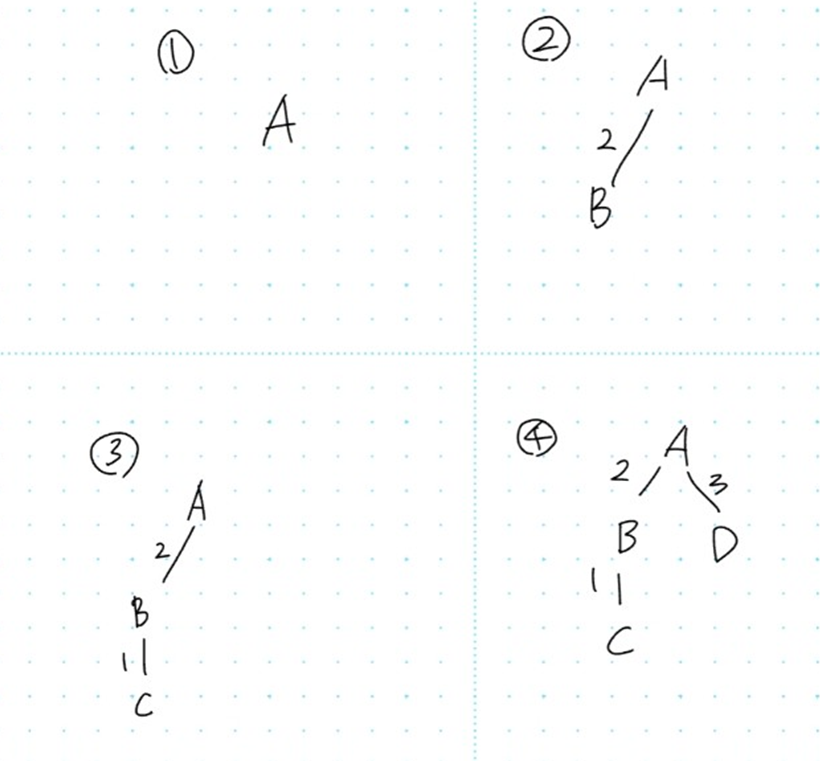
- 정점 A, B, C, D가 있고, 간선과 가중치가 다음과 같다고 가정합니다.
A-B (2), B-C (1), C-D (4), A-D (3)
정점 A에서 시작한다고 가정해봅니다.
-
초기 상태
-
초기 트리: A
[A]
-
-
가장 가중치가 낮은 간선 선택
-
A와 인접한 간선 중 가장 가중치가 낮은 간선을 선택합니다.
[A]—2—[B] -
현재 트리: {A, B}
-
-
트리 확장 – 트리에 인접한 최소 가중치 간선 선택
-
트리 {A, B}에 인접한 간선 중 가장 낮은 가중치를 선택합니다.
A | (2) B | (1) C -
현재 트리: {A, B, C}
-
-
마지막 정점 추가
-
이제 남은 정점 D에 연결된 간선 중 최소 가중치를 선택합니다.
A / \ (2) (3) B D | (1) C
-
정리
- Kruskal 알고리즘은 간선을 가중치 순으로 선택하며, 각 단계마다 서로 다른 집합에 속한 정점들을 연결합니다.
- 독립된 정점들이 간선을 통해 하나의 집합으로 합쳐지는 과정을 보여줍니다.
- Prim 알고리즘은 시작 정점에서부터 인접한 최소 간선을 선택해 점진적으로 트리를 확장합니다.
- 하나의 정점에서 시작하여 매 단계마다 새로운 정점을 추가하는 "팽창"하는 모양을 가집니다.
두 경우 모두 최종 결과는 모든 정점을 포함하고, 간선 수가 (V-1)이며, 사이클이 없으므로 스패닝 트리임을 알 수 있습니다.
