Thread Safe이란?
데이터 타입이나 정적 메서드가 Thread-Safe하다는 것은 여러 스레드에서 사용될 때, 스레드가 어떻게 실행되든 간에(여러 프로세서에서 실행되거나 같은 프로세서에서 시간 분할로 실행되거나) 올바르게 동작하며, 호출 코드에서 추가적인 조정(coordination)을 요구하지 않는다는 것을 의미합니다.
- “올바르게 동작한다” 는 해당 사양을 만족하고 표현 불변식을 유지함을 의미합니다.
- “스레드가 어떻게 실행되든” 은 스레드가 여러 프로세서에서 실행되거나 같은 프로세서에서 시간 분할로 실행될 수 있음을 의미합니다.
- “추가적인 조정을 요구하지 않는다” 는 데이터 타입이 호출자에게 타이밍과 관련된 전제를 걸지 않아야 함을 의미합니다. “set()이 진행되는 동안 get()을 호출할 수 없습니다”와 같은 전제를 걸면 안 됩니다.
참고로 Iterator는 주로 단일 스레드 환경에서 컬렉션을 효율적으로 순회하기 위해 설계되었기 때문에 Thread-Safe하지 않습니다. 만약 여러 스레드가 동시에 Iterator를 사용하여 컬렉션을 순회하려고 하면, 각 스레드가 Iterator의 내부 상태(예: 현재 인덱스)를 독립적으로 변경하게 됩니다. 이로 인해 순회 과정에서 인덱스가 꼬이거나 잘못된 요소에 접근하게 되어 예기치 않은 동작이 발생할 수 있습니다.
🧶 Thread Safe한 자료구조가 있을까요? 없다면, 어떻게 Thread Safe하게 구성할 수 있을까요?
-
기본적으로 Thread Safe한 자료구조 => Vector / Hashtable / Stack
Java 초기부터 제공되던 자료구조로, 내부 메서드가 synchronized 처리되어 있어 기본적으로 멀티스레드 환경에서 안전하게 동작합니다.
하지만 이들은 오래된 구현이며, 멀티스레드 환경에서 효율적이지 못하고 병목이 발생하기 쉬우며, 새로운 동시성 컬렉션에 비해 성능이 떨어집니다. -
java.util.concurrent 패키지의 동시성 컬렉션(Concurrent Collections)
병렬 처리를 고려한 내부 구현을 갖추고 있어, 단순히 객체를 생성하는 것만으로도 Thread Safe한 연산을 수행할 수 있습니다.ConcurrentHashMap: 내부적으로 락을 세분화(Segment-level locking, Java 8 이후는 CAS 기반)하여 동시에 읽기-쓰기에 강한 성능을 보장합니다.CopyOnWriteArrayList/CopyOnWriteArraySet: 쓰기 연산 시 내부 배열을 복사하는 방식으로 읽기 시 Lock이 필요 없는 구조를 취해, 읽기 위주의 환경에서 높은 성능을 기대할 수 있습니다.ConcurrentLinkedQueue/ConcurrentLinkedDeque: Non-blocking 알고리즘을 통해 CAS 연산을 활용하는 Lock-Free 큐/덱 구현체입니다.BlockingQueue구현체: 내부적으로 Lock 또는 조건 변수를 통해 Thread-Safe하게 동작하며, 생산자-소비자 패턴을 쉽게 구현할 수 있습니다.
Thread-Safe하게 구성하는 전략
Confinement (격리)
특정 자원을 하나의 스레드 안에만 머물게 함으로써, 다른 스레드가 해당 자원에 접근하지 못하도록 하는 전략입니다.
변할 수 있는(mutable) 데이터에 대한 경쟁 조건(race condition)을 피하기 위해 그 데이터를 단일 스레드(스레드 로컬)에 한정시킵니다. 다른 스레드가 데이터에 직접 읽기 또는 쓰기할 수 있는 권한을 주지 않는 것입니다.
로컬 변수는 항상 thread confined 됩니다. 로컬 변수는 스택에 저장되며, 각 스레드는 고유한 스택을 가지고 있습니다. 메서드가 여러 번 호출될 수 있는데(다른 스레드에서 실행되거나, 메서드가 재귀적으로 호출될 경우 단일 스레드의 스택 여러 레벨에서 실행될 수 있음), 각 호출은 변수의 고유한 사본을 가지므로 변수 자체가 한정됩니다.
하지만 변수는 thread confined 되어있어도, 객체 참조(object reference)라면,
다른 스레드에서 접근할 수 있는 참조가 없어야 하기 때문에 참조하는 객체도 confined 되어있는 지 확인해야 합니다.
public class Factorial {
/**
* Computes n! and prints it on standard output.
* @param n must be >= 0
*/
private static void computeFact(final int n) {
BigInteger result = new BigInteger("1");
for (int i = 1; i <= n; ++i) {
System.out.println("working on fact " + n);
result = result.multiply(new BigInteger(String.valueOf(i)));
}
System.out.println("fact(" + n + ") = " + result);
}
public static void main(String[] args) {
new Thread(new Runnable() { // create a thread using an
public void run() { // anonymous Runnable
computeFact(99);
}
}).start();
computeFact(100);
}
}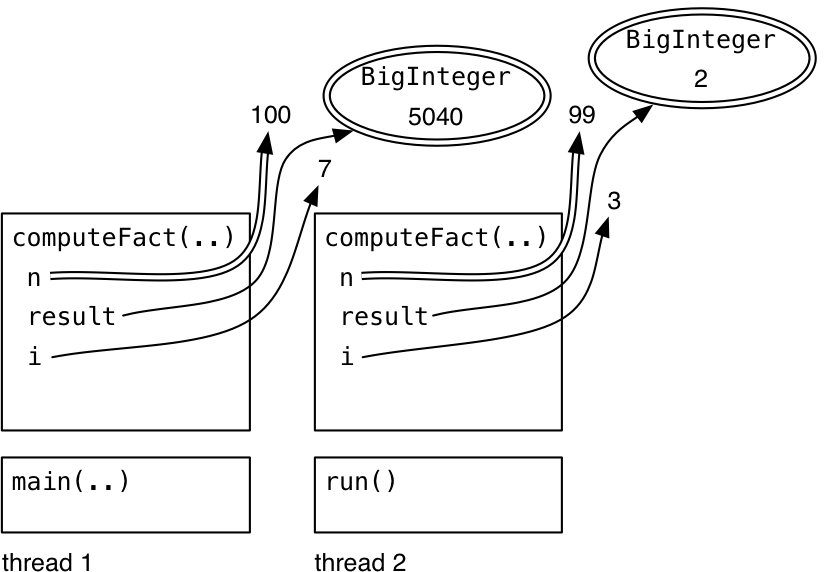
1. 프로그램을 시작할 때, 하나의 스레드가 main을 실행하며 시작합니다.
2. main은 익명 Runnable 방식으로 두 번째 스레드를 생성하고, 그 스레드를 시작합니다.
3. 이 시점에서, 두 개의 동시 실행 스레드가 있지만 각각의 실행 순서는 알 수 없습니다! 스레드 1이 computeFact에 진입하는 가능성이 있기 때문에 얘를 먼저 보겠습니다.
4. 그런 다음, 스레드 2도 computeFact에 진입할 수 있습니다.
5. 이 시점에서, 각 computeFact의 실행은 고유한 n, i, 그리고 result 변수를 가지고 있습니다. 이들이 참조하는 객체는 변경 가능(mutable)하지 않습니다. 만약 변경 가능하다면, 다른 스레드에서 해당 객체에 접근할 수 없도록 별도로 확인해야 합니다.
6. computeFact 계산은 각각 독립적으로 진행되며, 각자의 변수를 업데이트합니다.
그렇다면 아래의 함수는 Thread-Safe일까요?
/**
* @param x integer to test for primeness; requires x > 1
* @return true if and only if x is prime
*/
public static boolean isPrime(int x) {
if (cache.containsKey(x)) return cache.get(x);
boolean answer = BigInteger.valueOf(x).isProbablePrime(100);
cache.put(x, answer);
return answer;
}
private static Map<Integer,Boolean> cache = new HashMap<>();Thread-Safe가 아닙니다.
그 이유는 static 변수인 cache가 모든 isPrime() 호출에 의해 공유되기 때문이며, HashMap은 threadsafe하지 않기 때문입니다. 여러 스레드가 동시에 cache.put()을 호출하여 맵을 변경하면, 맵이 마지막 읽기에서 본 것과 같은 방식으로 손상될 수 있습니다.
Immutability (불변성)
한 번 생성된 객체의 상태가 절대 변하지 않도록 만드는 전략입니다. 불변 참조(immutable references)와 데이터 타입을 사용하는 것입니다. 불변성은 공유 가능한 변경 가능한 데이터(shared-mutable-data)가 경쟁 상태(race condition)의 원인이 되는 문제를 해결하며, 단순히 공유 데이터를 변경 불가능하게 만들어 이를 해결합니다.
-
Final 변수는 불변 참조입니다.
따라서final로 선언된 변수는 여러 스레드에서 안전하게 접근할 수 있습니다. 변수는 읽기만 가능하고, 쓰기는 불가능합니다. 하지만 주의할 점은 이 안전성이 변수 자체에만 적용된다는 것이며, 변수들이 참조하는 객체가 불변인지 여부도 별도로 확인해야 한다는 것입니다. -
불변 객체는 보통 threadsafe합니다.
여기서 "보통"이라고 말하는 이유는 현재의 불변성 정의가 동시성 프로그래밍에 너무 느슨하기 때문입니다. 타입이 불변이라는 것은, 그 타입의 객체가 전체 수명 동안 항상 동일한 추상 값을 나타내는 경우를 말합니다.
그러나 이는 benevolent mutation(자비로운 변경) 과 같이 타입이 내부 표현을 변경할 자유를 허용하는데, 이러한 변경이 클라이언트에게는 보이지 않는다면 가능합니다.
예를 들어, 클라이언트가 처음으로 리스트의 길이를 요청할 때, 불변 리스트가 그 길이를 변경 가능한 필드에 캐싱하는 경우가 있습니다. 캐싱은 전형적인 benevolent mutation 입니다. -
그러나 동시성에서는 이러한 변경은 안전하지 않습니다.
그러므로 benevolent mutation을 사용하는 불변 데이터 타입은 Thread-Safe를 보장하기 위해 락을 사용해야 합니다(변경 가능한 데이터 타입에서처럼!).
불변성의 강력한 정의
따라서 락 없이 불변 데이터 타입이 threadsafe하다는 것을 확신하려면, 불변성에 대한 더 강력한 정의가 필요합니다:
-
변경자(set) 메서드가 없다
-
모든 필드는
private및final이다 -
표현 노출(representation exposure)이 없다
// birthDate 라는 내부 필드 존재한다는 가정 public Date getBirthDate() { return birthDate; // 직접 참조를 반환하여 내부 표현 노출 } public Date getBirthDate() { // 내부 객체를 직접 반환하지 않고 복사본을 반환 return new Date(birthDate.getTime()); } -
표현(rep)에 있는 변경 가능한(mutable) 객체의 변경이 없다
–> benevolent mutation 까지도 포함 X
// 필드 표현에 변경 가능한 객체
public final class Team {
private final String name;
private final List<String> members;
public Team(String name, List<String> members) {
this.name = name;
this.members = members; // 외부에서 변경 가능한 리스트 참조
}
public List<String> getMembers() {
return members; // 직접 참조를 반환하여 내부 리스트가 변경 가능
}
} public Team(String name, List<String> members) {
this.name = name;
// defensive copy 및 불변 리스트로 변환
this.members = Collections.unmodifiableList(new ArrayList<>(members));
}
public List<String> getMembers() {
return members; // 불변 리스트를 반환하여 변경 불가
}Threadsafe data type (스레드 안전한 자료형)
기존의 threadsafe 데이터 타입에 공유 가능한 변경 가능한 데이터를 저장하는 것입니다. Java의 ConcurrentHashMap 같이 이미 스레드 안전성을 보장하는 자료구조를 활용하는 경우가 있겠습니다. 다만, 데이터 타입의 불변성 유지와 올바른 동기화가 중요합니다.
StringBuilder 와 StringBuffer 처럼 같은 기능을 하는 Thread-Safe와 Non Thread-Safe 데이터 타입이 존재하며, 그 이유는 Thread-Safe 데이터 타입은 보통 안전하지 않은 타입에 비해 성능 저하를 초래하기 때문입니다.
Threadsafe Collections
List, Set, Map은 기본 구현이 Thread-Safe하지 않으며 ArrayList, HashMap, HashSet 등의 구현은 여러 스레드에서 안전하게 사용할 수 없습니다.
컬렉션을 Thread-Safe하게 만들면서도 여전히 변경 가능하게 만드는 또 다른 래퍼 메서드도 제공합니다.
이러한 래퍼는 사실상 컬렉션의 각 메서드를 다른 메서드에 대해 원자적으로 만듭니다. 원자적(atomic)인 작업은 사실상 한 번에 일어나며, 내부 작업이 다른 작업과 섞이지 않고, 작업의 전체가 완료될 때까지 그 효과가 다른 스레드에 보이지 않기 때문에 절대 부분적으로 완료된 것처럼 보이지 않습니다.
/**
* @param x integer to test for primeness; requires x > 1
* @return true if and only if x is prime
*/
public static boolean isPrime(int x) {
if (cache.containsKey(x)) return cache.get(x);
boolean answer = BigInteger.valueOf(x).isProbablePrime(100);
cache.put(x, answer);
return answer;
}
private static Map<Integer,Boolean> cache =
Collections.synchronizedMap(new HashMap<>());여기서 중요한 점이 있습니다.
-
wrapper 우회 금지
기본적인 Thread-Safe하지 않은 컬렉션에 대한 참조 말고, 동기화된 래퍼를 통해서만 접근하도록 해야 합니다. 위 코드에서는 새로운HashMap이synchronizedMap()에만 전달되고 다른 곳에 저장되지 않기 때문에 자동으로 이 규칙이 지켜집니다. -
Iterator는 여전히 Thread-Safe하지 않습니다.
컬렉션 자체에 대한 메서드 호출(get(),put(),add()등)은 이제 Thread-Safe하지만, 컬렉션에서 생성된iterator는 여전히 Thread-Safe하지 않습니다. 따라서iterator()나for루프 구문을 사용할 수 없습니다. 해결책은 반복이 필요할 때 컬렉션의 락을 획득하는 것으로 아래 동기화 파트에서 다루겠습니다. -
원자적 작업만으로는 경쟁 조건을 방지하기에 충분하지 않습니다.
동기화된 컬렉션을 사용하더라도 여전히 경쟁 조건이 있을 수 있습니다.
//리스트에 최소 하나의 요소가 있는지 확인하고 그 요소를 가져옴
//여전히 경쟁 조건 보유
if ( ! lst.isEmpty()) { String s = lst.get(0); ... }
//`isEmpty()` 호출과 `get()` 호출 사이에 다른 스레드가 요소 변경 가능-
isPrime()메서드에도 여전히 잠재적인 경쟁 조건이 있습니다if (cache.containsKey(x)) return cache.get(x); boolean answer = BigInteger.valueOf(x).isProbablePrime(100); cache.put(x, answer);동기화된 맵은
containsKey(),get(),put()을 이제 원자적으로 보장하므로, 여러 스레드에서 호출하더라도 맵의 표현 불변식이 손상되지 않습니다. 하지만 이 세 가지 작업은 여전히 임의의 방식으로 서로 섞일 수 있으며, 이는isPrime이 캐시에서 필요로 하는 불변식을 깨뜨릴 수 있어 잘못된 결과를 반환할 수 있습니다.따라서
containsKey(),get(),put()사이의 경쟁이 이 불변식을 위협하지 않는지 확인해야합니다.-
containsKey()와get()사이의 경쟁은 괜찮습니다.
왜냐하면 캐시에서 항목을 제거하지 않기 때문입니다 -
containsKey()와put()사이에 경쟁이 있습니다.
두 스레드가 동시에 동일한x의 소수 여부를 테스트하고, 둘 다put()을 호출할 수 있습니다. 그러나 두 스레드 모두 동일한 답을put()에 전달하므로, 누가 이기든 상관없이 결과는 동일합니다.
-
Synchronization (동기화)
synchronized 키워드, Lock 객체 등 개발자가 직접 synchronized 키워드를 사용하여 동기화 코드를 작성하는 전통적인 동기화 메커니즘을 사용하여, 한 번에 하나의 스레드만 특정 자원에 접근하게 만드는 전략입니다. 즉, 명시적인 락을 통해 스레드들의 접근을 순서대로 제어하여 스레드 안전성을 확보합니다.
자바는 기본 컬렉션(ArrayList, HashMap 등)이 Thread Safe하지 않지만, Collections.synchronizedList(), Collections.synchronizedMap() 같은 동기화 래퍼를 제공하여 스레드 안전성을 확보할 수 있습니다.
동기화 래퍼가 기존 데이터 구조를 단순히 synchronized 블록으로 감싼 것으로 자체적으로 Lock-Free나 CAS 같은 별도의 구현 전략을 사용하지 않기 때문에 이 전략과 유사하다고 생각하였습니다.
예시 : Thread-Safe 한Iterator
Collections.synchronizedList()로 감싼 리스트의 메서드 호출은 스레드 안전하지만, 리스트를 순회(iterate)할 때는 별도의 동기화가 필요합니다. 이는 Iterator가 내부적으로 리스트의 상태를 변경할 수 있기 때문에 발생하는 문제를 방지하기 위함입니다.
해결 방법
리스트를 순회할 때는 외부에서 명시적으로 동기화 블록을 사용하여 리스트의 락을 획득해야 합니다. 이렇게 하면 순회하는 동안 다른 스레드가 리스트를 수정하지 못하게 되어 안전하게 순회할 수 있습니다.
public class IteratorSynchronizedExample {
public static void main(String[] args) {
// Thread Safe한 리스트 생성
List<String> synchronizedList = Collections.synchronizedList(new ArrayList<>());
// 리스트에 항목 추가
synchronizedList.add("Apple");
synchronizedList.add("Banana");
synchronizedList.add("Cherry");
// 리스트를 순회할 때 동기화 블록 사용
synchronized (synchronizedList) {
for (String item : synchronizedList) {
System.out.println(item);
}
}
// 또는 Iterator를 사용할 경우
synchronized (synchronizedList) {
Iterator<String> iterator = synchronizedList.iterator();
while (iterator.hasNext()) {
String item = iterator.next();
System.out.println(item);
}
}
}
}리스트를 안전하게 순회하려면 항상 동기화 블록을 사용하여 리스트의 락을 획득해야 합니다.
주의
- 동기화 블록 내에서만 순회: 리스트를 순회할 때는 항상 동기화 블록을 사용하여 리스트의 락을 획득해야 합니다. 그렇지 않으면 다른 스레드가 리스트를 수정하는 동안 순회가 일어나 데이터 불일치나 예외가 발생할 수 있습니다.
- 동기화 범위: 동기화 블록의 범위를 가능한 작게 유지하여 성능 저하를 최소화해야 합니다. 불필요하게 긴 동기화 블록은 다른 스레드의 접근을 지연시킬 수 있습니다.
- Iterator 자체는 동기화되지 않음:
Iterator객체 자체는 스레드 안전하지 않으므로, 이를 사용할 때는 반드시 외부에서 동기화해야 합니다.
Synchronization과 Threadsafe Data Type의 차이점 요약
| 특징 | Synchronization (동기화) | Threadsafe Data Type (스레드 안전 데이터 타입) |
|---|---|---|
| 관리 방식 | 개발자가 직접 synchronized 키워드를 사용하여 동기화 코드를 작성 | 데이터 타입 자체가 내부적으로 동기화를 처리 |
| 사용 편의성 | 동기화 코드를 신중하게 작성해야 하므로 다소 복잡 | 이미 구현된 스레드 안전 클래스를 사용하여 간편하게 적용 |
| 유연성 | 필요한 부분에만 동기화를 적용할 수 있어 성능 최적화 가능 | 데이터 타입에 따라 동기화 방식이 고정되어 있음 |
| 성능 | 동기화 범위와 방법에 따라 성능 저하 가능 | 일부 threadsafe 데이터 타입은 고성능을 위해 최적화되어 있음 |
| 코드 복잡성 | 동기화 블록이나 메서드 작성으로 코드가 복잡해질 수 있음 | 코드가 간결해지며, 스레드 안전성을 보장받기 위해 별도의 코드 작성 불필요 |
🧶 배열의 길이를 알고 있다면, 조금 더 빠른 Thread Safe한 연산을 만들 수 있을까요?
"배열의 길이를 알고 있다" => 정적인 자료구조와 같이 자료구조를 구현할 때 사용되는 내부 배열의 크기가 고정적이고, 실행 시간 동안 크기 조정을 하지 않는 상황이라고 가정하겠습니다.
이러한 상황에서는 런타임에 배열 크기를 재조정하거나 동적 메모리 할당으로 인한 오버헤드가 줄어들고, 인덱스를 통한 접근 방식이 단순해지므로 미리 할당된 고정 크기 배열을 기반으로 인덱스 계산을 통해 Lock-Free / Wait-Free 알고리즘을 구현하기 용이합니다.
개념 설명
- Lock-Free
어떤 스레드가 멈추더라도(중단되더라도) 전체 시스템이 계속 진행되는 구조입니다.
모든 연산이 최소한 한 스레드는 계속 진행한다는 보장을 가지며, 한 스레드의 지연이 전체 시스템 정지로 이어지지 않습니다. - Wait-Free
모든 연산이 무한히 지연되지 않고, 유한한 단계 안에 완료되는 구조를 말합니다.
즉, 어느 스레드도 무기한 대기하지 않습니다.
구현 방법
- 이들 구조는 보통
CAS(Compare-And-Set)와 같은 원자적 연산을 통해 구현합니다.
CAS는 "현재 값"과 "예상 값"을 비교해서 일치하면 "새 값"으로 원자적으로 교체하는 연산입니다. 자바에서는AtomicInteger,AtomicReference,AtomicReferenceArray등에서compareAndSet()메서드를 통해 CAS를 수행할 수 있습니다. - 고정된 길이의 배열을 큐나 스택 형태로 사용하려면, 인덱스를 원자적으로 증가시키면서 접근해야 합니다. 이 때, CAS로 인덱스를 업데이트하고, 배열 셀 접근도 원자적으로 처리합니다.
- Ring Buffer(원형 버퍼)나 Circular Array 구조에서는 인덱스가 배열 범위를 초과하면 다시 0으로 돌아가도록 모듈로 연산(
index = index % capacity)을 수행합니다. 이로써 고정된 크기 내에서 계속 데이터를 넣고 빼는 구조를 유지합니다.
Lock-Free Single-Producer, Single-Consumer 큐
단일 생산자(Single Producer)와 단일 소비자(Single Consumer)를 가정한 매우 단순한 Lock-Free 큐입니다.
import java.util.concurrent.atomic.AtomicInteger;
public class LockFreeRingBuffer<E> {
private final E[] buffer;
private final int capacity;
private final AtomicInteger head = new AtomicInteger(0); // 소비자가 데이터를 꺼내는 위치
private final AtomicInteger tail = new AtomicInteger(0); // 생산자가 데이터를 넣는 위치
@SuppressWarnings("unchecked")
public LockFreeRingBuffer(int capacity) {
this.capacity = capacity;
this.buffer = (E[]) new Object[capacity];
}
public boolean offer(E e) {
while (true) {
int currentTail = tail.get();
int currentHead = head.get();
// 큐가 가득찼는지 확인
if ((currentTail - currentHead) == capacity) {
return false; // 큐가 꽉 찼으므로 삽입 불가
}
// CAS로 tail을 증가 시도
if (tail.compareAndSet(currentTail, currentTail + 1)) {
// 인덱스 위치에 데이터 삽입
buffer[currentTail % capacity] = e;
return true;
}
// 실패 시 재시도 (Lock-Free 특성)
}
}
public E poll() {
while (true) {
int currentHead = head.get();
int currentTail = tail.get();
// 큐가 비었는지 확인
if (currentHead == currentTail) {
return null; // 빈 큐
}
// 원소를 읽어옴
E e = buffer[currentHead % capacity];
// CAS로 head 증가 시도
if (head.compareAndSet(currentHead, currentHead + 1)) {
return e; // 성공적으로 pop
}
// 실패 시 재시도
}
}
}여기서 offer()와 poll()은 어떤 스레드도 전역 락을 잡지 않습니다. 각각 CAS를 사용하여 인덱스를 업데이트하고, 만약 실패하면 재시도(retry)하는 식으로 구현되어 있습니다. 이로써 경쟁 상황에서 한 스레드의 지연이 다른 스레드의 진행을 완전히 막지 않는 Lock-Free 특징을 가집니다.
간단한 Wait-Free Ring Buffer 구현
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicReferenceArray;
public class WaitFreeRingBuffer<E> {
private final AtomicReferenceArray<E> buffer;
private final int capacity;
private final AtomicInteger head = new AtomicInteger(0); // 소비자가 데이터를 꺼내는 위치
private final AtomicInteger tail = new AtomicInteger(0); // 생산자가 데이터를 넣는 위치
public WaitFreeRingBuffer(int capacity) {
this.capacity = capacity;
this.buffer = new AtomicReferenceArray<>(capacity);
}
/**
* 데이터를 버퍼에 추가합니다.
* 최대 10번 시도한 후 실패하면 false를 반환합니다.
*/
public boolean offer(E e) {
for (int i = 0; i < 10; i++) { // 제한된 시도 횟수
int currentTail = tail.get();
int currentHead = head.get();
// 큐가 가득 찼는지 확인
if ((currentTail - currentHead) == capacity) {
return false; // 큐가 꽉 찼으므로 삽입 불가
}
// tail을 증가시키기 위한 CAS 시도
if (tail.compareAndSet(currentTail, currentTail + 1)) {
buffer.set(currentTail % capacity, e);
return true; // 성공적으로 삽입
}
// 실패 시 다음 시도로 넘어감
}
return false; // 시도 횟수 초과
}
/**
* 버퍼에서 데이터를 꺼냅니다.
* 최대 10번 시도한 후 실패하면 null을 반환합니다.
*/
public E poll() {
for (int i = 0; i < 10; i++) { // 제한된 시도 횟수
int currentHead = head.get();
int currentTail = tail.get();
// 큐가 비었는지 확인
if (currentHead == currentTail) {
return null; // 빈 큐
}
// 데이터를 읽어옴
E e = buffer.get(currentHead % capacity);
// head을 증가시키기 위한 CAS 시도
if (head.compareAndSet(currentHead, currentHead + 1)) {
buffer.set(currentHead % capacity, null); // GC를 위해 참조 해제
return e; // 성공적으로 꺼냄
}
// 실패 시 다음 시도로 넘어감
}
return null; // 시도 횟수 초과
}
public static void main(String[] args) {
WaitFreeRingBuffer<Integer> ringBuffer = new WaitFreeRingBuffer<>(5);
// 생산자 스레드
Runnable producer = () -> {
for (int i = 0; i < 10; i++) {
while (!ringBuffer.offer(i)) {
// 삽입 실패 시 재시도 (여기서는 간단히 루프를 사용)
}
System.out.println("Produced: " + i);
}
};
// 소비자 스레드
Runnable consumer = () -> {
for (int i = 0; i < 10; i++) {
Integer value;
while ((value = ringBuffer.poll()) == null) {
// 꺼내기 실패 시 재시도 (여기서는 간단히 루프를 사용)
}
System.out.println("Consumed: " + value);
}
};
Thread producerThread = new Thread(producer);
Thread consumerThread = new Thread(consumer);
producerThread.start();
consumerThread.start();
try {
producerThread.join();
consumerThread.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
- Bounded Attempts
offer와 poll 메서드에서 최대 10번의 시도를 제한함으로써, 각 연산이 유한한 단계 내에 완료되도록 합니다. 이는 wait-free 특성을 모방하려는 시도입니다. - 비영구적 실패
만약 10번의 시도 내에 성공하지 못하면, 메서드는 실패를 반환합니다. 이는 무한 루프에 빠지는 것을 방지하여, 스레드가 무한히 대기하지 않도록 합니다.
다만
- 완전한 Wait-Free 보장 부족
제한된 시도 횟수를 사용하여 wait-free 특성을 모방하지만, 진정한 wait-free를 보장하지는 않습니다. 완전한 wait-free 구현은 모든 스레드가 무한한 스레드 간 간섭 없이 연산을 완료할 수 있도록 해야 합니다. Java 표준 라이브러리에는 완전한 wait-free 데이터 구조가 포함되어 있지 않습니다.
🧶 사용하고 있는 언어의 자료구조는 Thread Safe한가요? 그렇지 않다면, Thread Safe한 Wrapped Data Structure를 제공하고 있나요?
-
자바의 기본 자료구조들
ArrayList,HashMap,HashSet등 기본java.util컬렉션은 Thread-Safe하지 않습니다. 동시에 여러 스레드가 접근하고 수정할 경우 일관성 문제가 발생할 수 있습니다. -
Thread Safe한 Wrapper
자바 표준 라이브러리는 기존 컬렉션을 Thread-Safe하게 감싸는 동기화 래퍼(synchronized wrapper)를 제공합니다.List<String> unsafeList = new ArrayList<>(); List<String> synchronizedList = Collections.synchronizedList(unsafeList);이와 같이
Collections.synchronizedList(),Collections.synchronizedMap()등을 사용하면 기존 컬렉션에 대해 간단히 동기화된 접근을 제공하지만, 내부적으로 전역적인synchronized를 사용하므로 성능적 병목이 발생할 수 있습니다. -
java.util.concurrent 패키지
ConcurrentHashMap,CopyOnWriteArrayList,ConcurrentLinkedQueue등 Lock-Free나 세분화된 락 기반의 자료구조를 제공하여, 고성능의 Thread-Safe 동시성 컬렉션을 제공합니다. 이는 별도의 wrapper 없이도 바로 Thread-Safe하게 사용할 수 있습니다.
참고 문헌
- https://web.mit.edu/6.005/www/fa15/classes/20-thread-safety/#reading_20_thread_safety
- https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/package-summary.html
- https://velog.io/@tsi0521/Thread-%ED%99%98%EA%B2%BD%EC%97%90%EC%84%9C-Safe%ED%95%9C-%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0%EB%9E%80
- https://hojunking.tistory.com/69
