
해당 포스트는 이지스퍼블리싱, 『알고리즘 코딩테스트 자바 편』, Gene 김종관 을 참고하여 작성하였습니다.
퀵 정렬(quick sort)은 기준값(pivot)을 선정해 해당 값보다 작은 데이터와 큰 데이터로 분류하는 것을 반복해 정렬하는 알고리즘입니다. 기준값이 어떻게 선정되는지가 시간 복잡도에 많은 영향을 미치고, 평균적인 시간 복잡도는 O(nlogn)입니다.
퀵 정렬의 핵심 이론
pivot을 중심으로 계속 데이터를 2개의 집합으로 나누면서 정렬하는 것이 퀵 정렬의 핵심입니다.
-
퀵 정렬은 찰스 앤터니 리처드 호어가 개발한 정렬 알고리즘이다.
-
퀵 정렬은 분할 정복(divide and conquer) 방법을 통해 리스트를 정렬한다.
-
다른 원소와의 비교만으로 정렬을 수행하는 비교 정렬에 속한다.
-
퀵 정렬은 n개의 데이터를 정렬할 때, 최악의 경우에는 O(n^2)번의 비교를 수행하고, 평균적으로 O(n log n)번의 비교를 수행한다.
-
퀵 정렬의 내부 루프는 대부분의 컴퓨터 아키텍처에서 효율적으로 작동하도록 설계되어 있고(그 이유는 메모리 참조가 지역화되어 있기 때문에 CPU 캐시의 히트율이 높아지기 때문이다), 대부분의 실질적인 데이터를 정렬할 때 제곱 시간이 걸릴 확률이 거의 없도록 알고리즘을 설계하는 것이 가능하다. 또한 매 단계에서 적어도 1개의 원소가 자기 자리를 찾게 되므로 이후 정렬할 개수가 줄어든다. 그렇기에 일반적인 경우 퀵 정렬은 다른 O(n log n) 알고리즘에 비해 훨씬 빠르게 동작한다.
다음 그림을 봅시다.
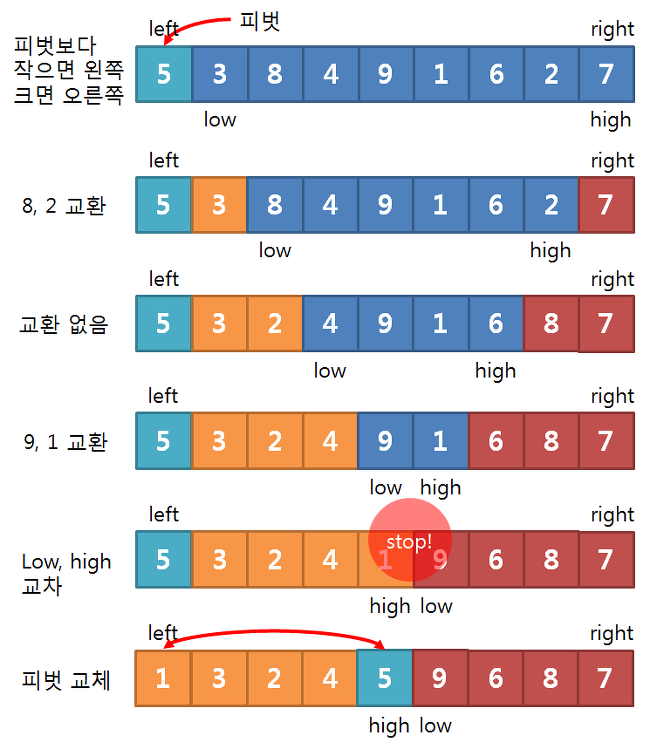
퀵 정렬 과정
-
배열의 첫 번째 값(5)를 피벗(pivot)으로 설정한다.
-
low 는 left + 1 자리부터 피벗(5)와 비교하면서 한칸씩 증가한다.
-
high 는 right 자리에서부터 피벗(5)와 비교하면서 한칸씩 감소한다.
-
위의 절차를 반복한다. low와 high가 엇갈리면 정지한다.
-
피벗값과 high 값을 SWAP한다.
-
피벗을 기준으로 왼쪽, 오른쪽 두개의 배열을 1~5번을 반복한다.
-
더 이상 나눠질 수 없을 때까지 재귀적으로 반복한다.
-
정렬이 완료된다.
퀵 정렬의 시간 복잡도는 비교적 준수하므로 코딩 테스트에서도 종종 응용합니다. 재귀 함수의 형태로 직접 구현해 볼 것을 추천합니다.
