
💡 오라클 HR 계정의 EMPLOYEES 테이블을 사용했습니다.
employees / departments / jobs 테이블의 row 개수
select (select count(*) from employees) cnt_emp
,(select count(*) from departments) cnt_dep
,(select count(*) from jobs) cnt_jobs
from dual;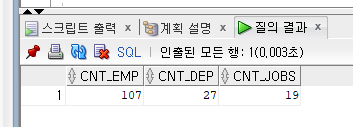
- 다른 쿼리문을 실행하기 전에 각 테이블 별로 몇 개의 데이터들이 있는지 파악하고자 하였다.
Join이 없을 경우
⇒ N * M 개의 데이터가 생성
SELECT count(*)
FROM jobs
,departments;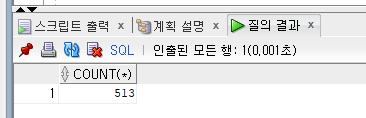
2개의 테이블 간 Join
SELECT e.employee_id
,e.first_name
,e.department_id
,d.department_name
FROM EMPLOYEES e
,departments d
WHERE 1 = 1
AND e.department_id = d.department_id;
3개의 테이블 간 Join
SELECT e.employee_id
,e.first_name
,e.department_id
,d.department_name
,e.job_id
,j.job_title
FROM EMPLOYEES e
,departments d
,jobs j
WHERE 1 = 1
AND e.department_id = d.department_id
AND e.job_id = j.job_id;- 위와 같이 3개 정도는 Join이 쉽지만…
- 만약, N개 이상의 Join문이 발생한다면 With문 등을 활용하여 2개씩 테이블을 찢고 쿼리를 구성하는 것도 좋은 방향이라고 생각한다.
스칼라 쿼리 / 인라인 뷰 / 서브쿼리 개념
- 🔊 스칼라 서브쿼리(Scala Subquery)
- 함수처럼 한 레코드 당 정확히 하나의 값만을 리턴하는 서브쿼리.
- 기본으로 Outer Join이 적용되어 있다.
- 🔊 인라인 뷰(Inline View)
- FROM절에 사용되는 서브쿼리를 지칭.
- 마치 뷰처럼 SQL문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 때문에 인라인 뷰(View)라는 이름이 붙었다.
- 그래서 일반적인 뷰를 정적 뷰(Static View), 인라인 뷰를 동적 뷰(Dynamic View)라고도 한다.
- 🔊 서브쿼리(Subquery)
- 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 지칭.
- 위 두가지 경우 이외에 쓰이는 서브쿼리를 보통 통틀어서 일컫는다.
스칼라 쿼리
SELECT e.employee_id
,e.first_name
,e.department_id
,d.department_name
,e.job_id
,(select sysdate from dual) today
FROM EMPLOYEES e
,departments d
WHERE 1 = 1
AND e.department_id = d.department_id;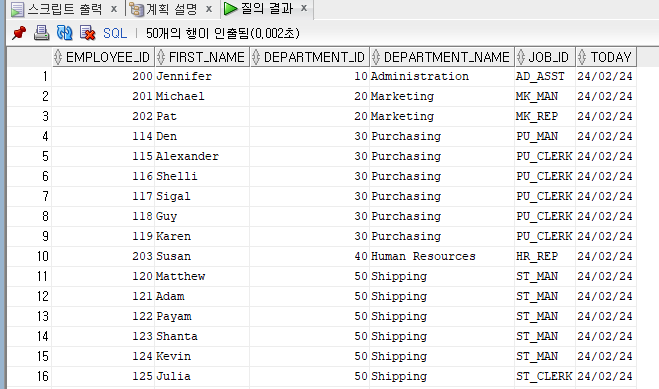
⇒ 결과와 같이 맨 우측 Today 컬럼이 모두 동일한 값으로 채워져 있다.
인라인 뷰
SELECT *
from (select first_name
from employees);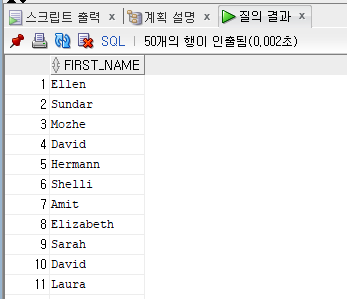
- From 절에서 쿼리를 사용하는 것이 인라인 뷰이다.
느낀점
Join은 전공 시절에도 3개 정도까지는 해본 적이 있어서 그렇게 색다르게 느껴지는 개념은 아니다.
하지만, 실무를 해보니 Join을 할 때 얻고자 하는 정보도 상당히 많기도 하고 정말 많은 테이블이 엮인 것을 많이 봤다.
그래서, Join을 하더라도 최대한 개발이나 유지보수를 쉽게 하기 위해서는 여러 With문을 활용해서 분리하는 것이 유리할 것이라는 느낌을 많이 받았다.
실제로, 현대글로비스 출신의 SQL 전문가가 강의한 것을 보았을 때도 자기는 With 문을 사용해서 최대한 찢는다고 언급했다.
스칼라 쿼리와 인라인 뷰는 내가 실무에서 많이 사용해본 적은 없다. 하지만, 일반적으로 많이 사용한다고 하니 많이 연습해야 할 것 같다는 느낌이 많이 들었다.

#Software Engineer #IRISH