안녕하세요. Gameeye에서 deeplol.gg 서비스를 개발 중인 김철기입니다.
클라우드 서버 인프라 구축, 백엔드 개발, 딥러닝 모델 연구를 담당하고 있습니다.
해당 포스팅은 AWS EKS 클러스터 기반에서 Kubeflow를 사용하기 위한 과정을 다룬 시리즈 중 세번째 포스팅입니다.
Kubeflow를 사용하는 간단한 예제를 다룰 예정이니 AWS EKS 클러스터 구축은 시리즈의 1번 포스트를, Kubeflow 설치과정은 시리즈의 2번 포스트를 참고해주세요.
시리즈
- AWS EKS 클러스터 구축하기
- Kubeflow 설치하기
- Kubeflow 예제 실행해보기
해당 포스팅은 아래 포스팅과 github을 참고하였음을 미리 밝힙니다.
- https://towardsdatascience.com/machine-learning-pipelines-with-kubeflow-4c59ad05522
- https://github.com/gnovack/kubeflow-pipelines
Kubeflow 예제 코드(예제 코드)
본 예제에서는 보스턴 집값 예측 모델 학습 및 평가 코드를 사용합니다.
(Dockerfile과 관련된 부분은 간단하여 설명을 생략합니다.)
본 예제는 아래 4가지 Task로 구성되어 있습니다.
- 데이터 로드 및 전처리
- 모델 학습
- 모델 평가
- 모델 deploy
- 데이터 로드 및 전처리
scikit-learn에서 제공하는 예제 데이터를 로드한 뒤 train_test_split 함수로 학습 데이터와 테스트 데이터를 나눠 저장하는 작업을 합니다.
코드
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
def _preprocess_data():
X, y = datasets.load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
np.save('x_train.npy', X_train)
np.save('x_test.npy', X_test)
np.save('y_train.npy', y_train)
np.save('y_test.npy', y_test)
if __name__ == '__main__':
print('Preprocessing data...')
_preprocess_data()- 모델 학습
전처리된 학습 데이터를 입력으로 받아 확률적 경사하강법 모델을 학습 후 모델을 저장하는 작업을 합니다.
코드
import argparse
import joblib
import numpy as np
from sklearn.linear_model import SGDRegressor
def train_model(x_train, y_train):
x_train_data = np.load(x_train)
y_train_data = np.load(y_train)
model = SGDRegressor(verbose=1)
model.fit(x_train_data, y_train_data)
joblib.dump(model, 'model.pkl')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_train')
parser.add_argument('--y_train')
args = parser.parse_args()
train_model(args.x_train, args.y_train)- 모델 평가
전처리된 테스트 데이터로 학습된 모델의 MSE(Mean Squared Error)를 계산해 파일로 저장합니다.
import argparse
import joblib
import numpy as np
from sklearn.metrics import mean_squared_error
def test_model(x_test, y_test, model_path):
x_test_data = np.load(x_test)
y_test_data = np.load(y_test)
model = joblib.load(model_path)
y_pred = model.predict(x_test_data)
err = mean_squared_error(y_test_data, y_pred)
with open('output.txt', 'a') as f:
f.write(str(err))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_test')
parser.add_argument('--y_test')
parser.add_argument('--model')
args = parser.parse_args()
test_model(args.x_test, args.y_test, args.model)- 모델 deploy
평가된 모델을 deploy하는 작업을 합니다.(보통 S3같은 스토리지에 저장하게되는데 본 예제에서는 다루지 않습니다.)
코드
import argparse
def deploy_model(model_path):
print(f'deploying model {model_path}...')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model')
args = parser.parse_args()
deploy_model(args.model)Docker Hub
작성한 예제 코드와 Dockerfile을 이용해 Docker Hub에 이미지를 push합니다.
아래 작업 전 Docker Hub 계정 생성 및 Repository 생성이 필요합니다.(DockerHub)
- docker build & tag
docker build ./boston_housing/preprocess_data --tag kimcheolgi/boston_pipeline_preprocessing
docker build ./boston_housing/train --tag kimcheolgi/boston_pipeline_train
docker build ./boston_housing/test --tag kimcheolgi/boston_pipeline_test
docker build ./boston_housing/deploy_model --tag kimcheolgi/boston_pipeline_deploy_model- docker push
docker push kimcheolgi/boston_pipeline_preprocessing
docker push kimcheolgi/boston_pipeline_train
docker push kimcheolgi/boston_pipeline_test
docker push kimcheolgi/boston_pipeline_deploy_modelPipeline
push한 컨테이너 이미지들을 이용하여 pipeline을 구축합니다.
- 컨테이너 정의
위에서 업로드한 docker image와 컨테이너로 전달하는 arguments, 컨테이너가 출력하는 file_outputs을 정의하여 각 Task 함수를 작성합니다.
코드
from kfp import dsl
def preprocess_op():
return dsl.ContainerOp(
name='Preprocess Data',
image='kimcheolgi/boston_pipeline_preprocessing:latest',
arguments=[],
file_outputs={
'x_train': '/app/x_train.npy',
'x_test': '/app/x_test.npy',
'y_train': '/app/y_train.npy',
'y_test': '/app/y_test.npy',
}
)
def train_op(x_train, y_train):
return dsl.ContainerOp(
name='Train Model',
image='kimcheolgi/boston_pipeline_train:latest',
arguments=[
'--x_train', x_train,
'--y_train', y_train
],
file_outputs={
'model': '/app/model.pkl'
}
)
def test_op(x_test, y_test, model):
return dsl.ContainerOp(
name='Test Model',
image='kimcheolgi/boston_pipeline_test:latest',
arguments=[
'--x_test', x_test,
'--y_test', y_test,
'--model', model
],
file_outputs={
'mean_squared_error': '/app/output.txt'
}
)
def deploy_model_op(model):
return dsl.ContainerOp(
name='Deploy Model',
image='kimcheolgi/boston_pipeline_deploy_model:latest',
arguments=[
'--model', model
]
)- 파이프라인 구축
작성된 함수를 이용해 파이프라인을 구축합니다.
코드
@dsl.pipeline(
name='Boston Housing Pipeline',
description='An example pipeline that trains and logs a regression model.'
)
def boston_pipeline():
_preprocess_op = preprocess_op()
_train_op = train_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_train']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_train'])
).after(_preprocess_op)
_test_op = test_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_test']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_test']),
dsl.InputArgumentPath(_train_op.outputs['model'])
).after(_train_op)
deploy_model_op(
dsl.InputArgumentPath(_train_op.outputs['model'])
).after(_test_op)- 파이프라인 컴파일
파이프라인을 업로드하기 위해 컴파일합니다.
코드
if __name__ == "__main__":
import kfp.compiler as compiler
compiler.Compiler().compile(boston_pipeline, __file__ + ".tar.gz")dsl-compile --py pipeline.py --output ironkey-boston-pipeline.tar.gzKubeflow 대시보드
컴파일된 파이프라인을 업로드하고 실행시켜봅니다.
- 파이프라인 업로드
updload pipeline 버튼을 클릭한 뒤 생성한 tar.gz 파일을 업로드합니다.
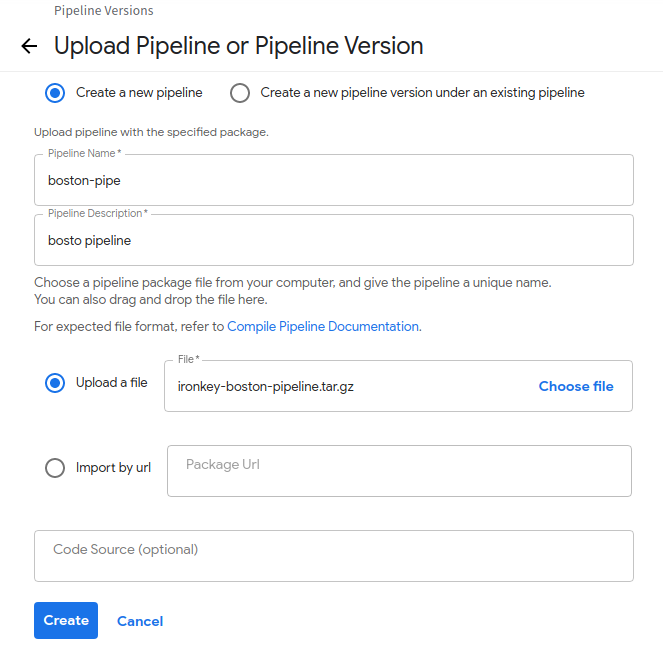
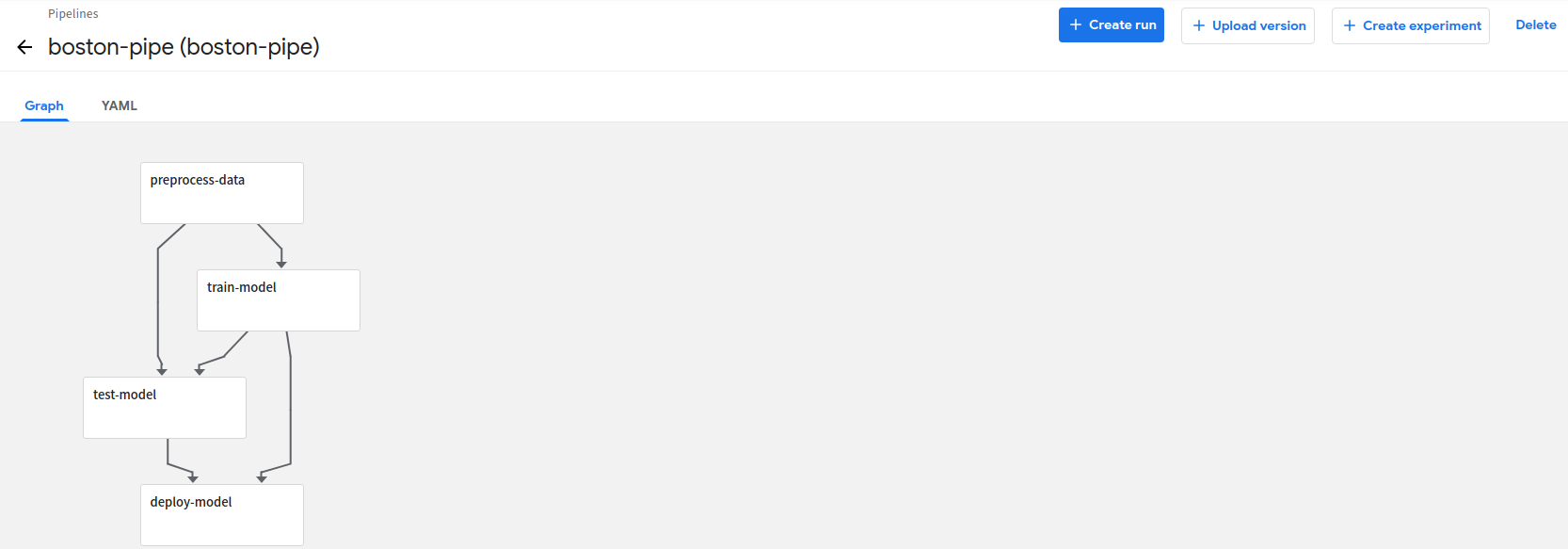
- 환경 생성
create experiment 버튼을 클릭합니다.
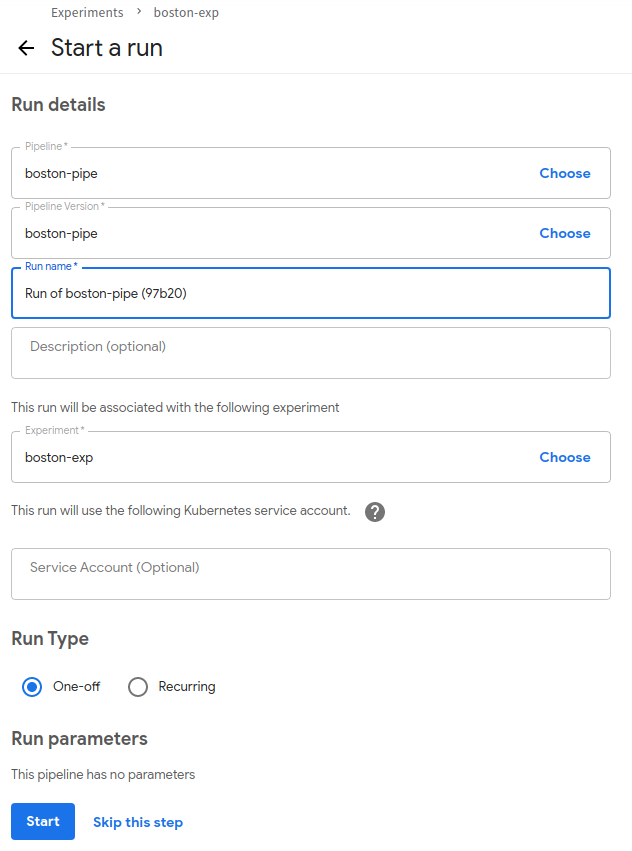
run name을 입력후 Start 버튼을 클릭합니다.
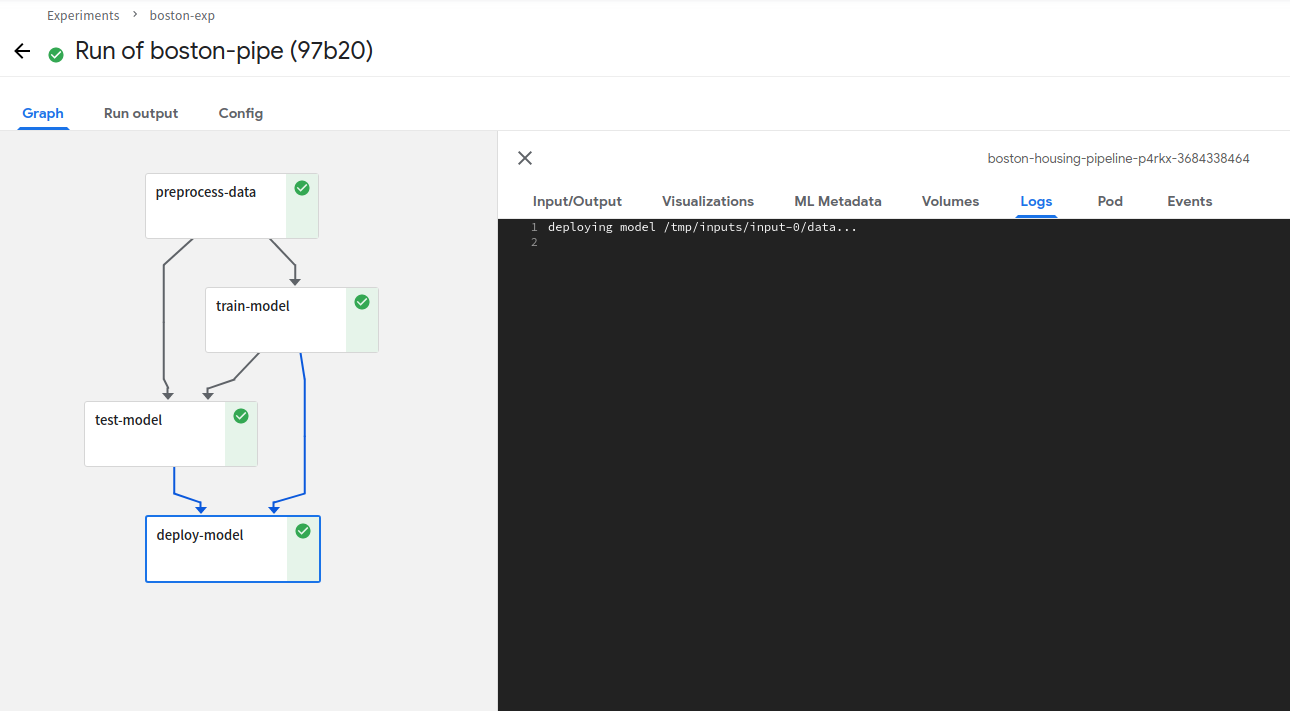
- 실행 확인
실행이 잘 되는 것을 확인할 수 있습니다.
정리
해당 포스팅에서는 예제 코드를 이용해 Docker Image를 생성 후 Pipeline을 구축하고 업로드하여 실행시켜보는 것까지 해보았습니다. 머신러닝과 도커의 경우 본 포스팅의 주요 주제라고 생각하지 않아 대부분의 설명을 생략하였습니다. 양해해주시면 감사하겠습니다.
kubeflow 시리즈는 여기서 마무리하려고 합니다. kubeflow와 관련해서는 향후 더욱 심화된 내용을 다루는 포스팅으로 찾아뵙겠습니다. 감사합니다.
