venv 가상환경 만들어서 request 설치
request : fetch 역할 (서버에서 데이터 가져오는 것)
pip install bs4 : 크롤링하기 전 설치 library1. DB 만들기 / 저장
pip install pymongo dnspython 
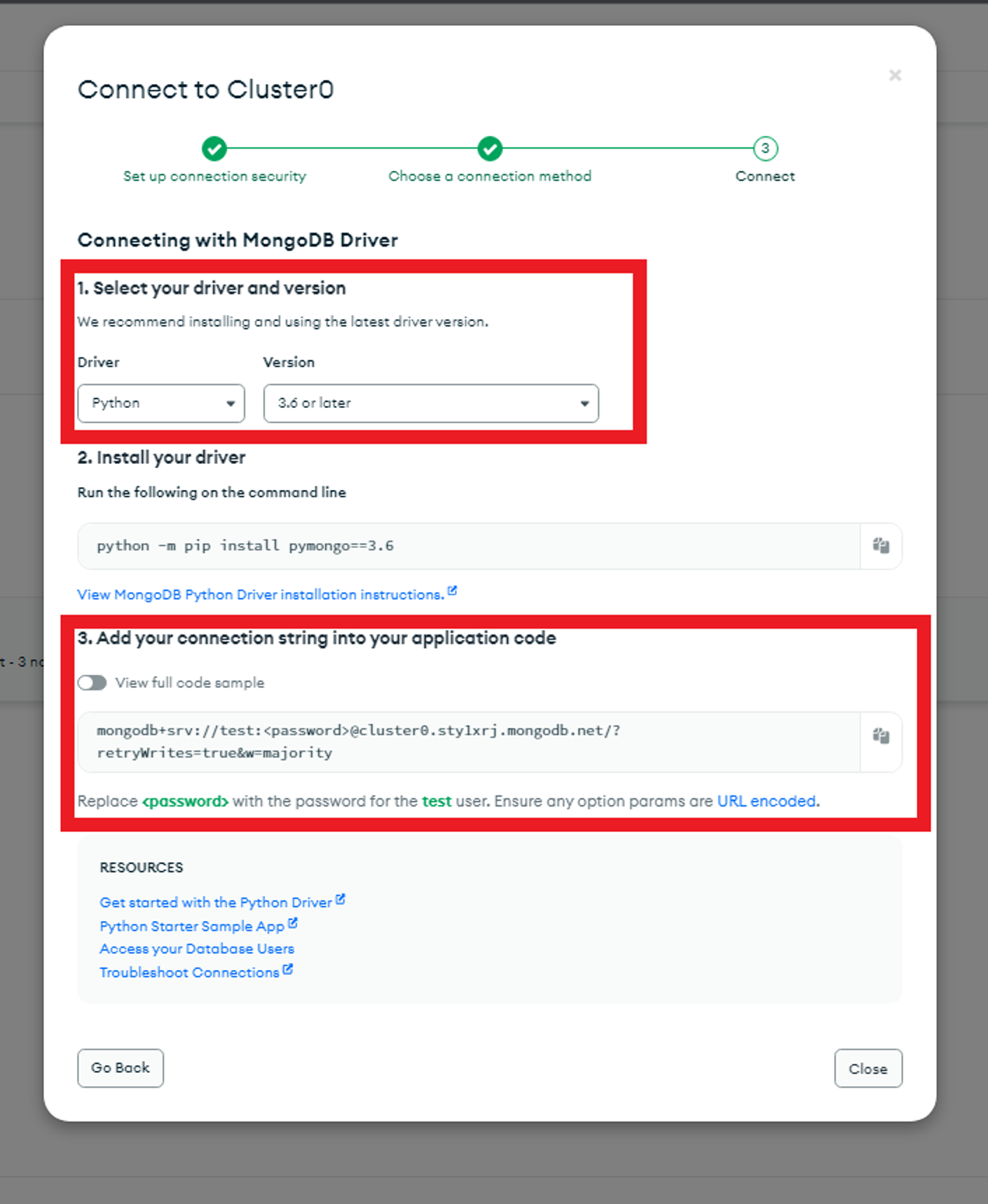
❗️주의❗️ ( 맥북 오류 )
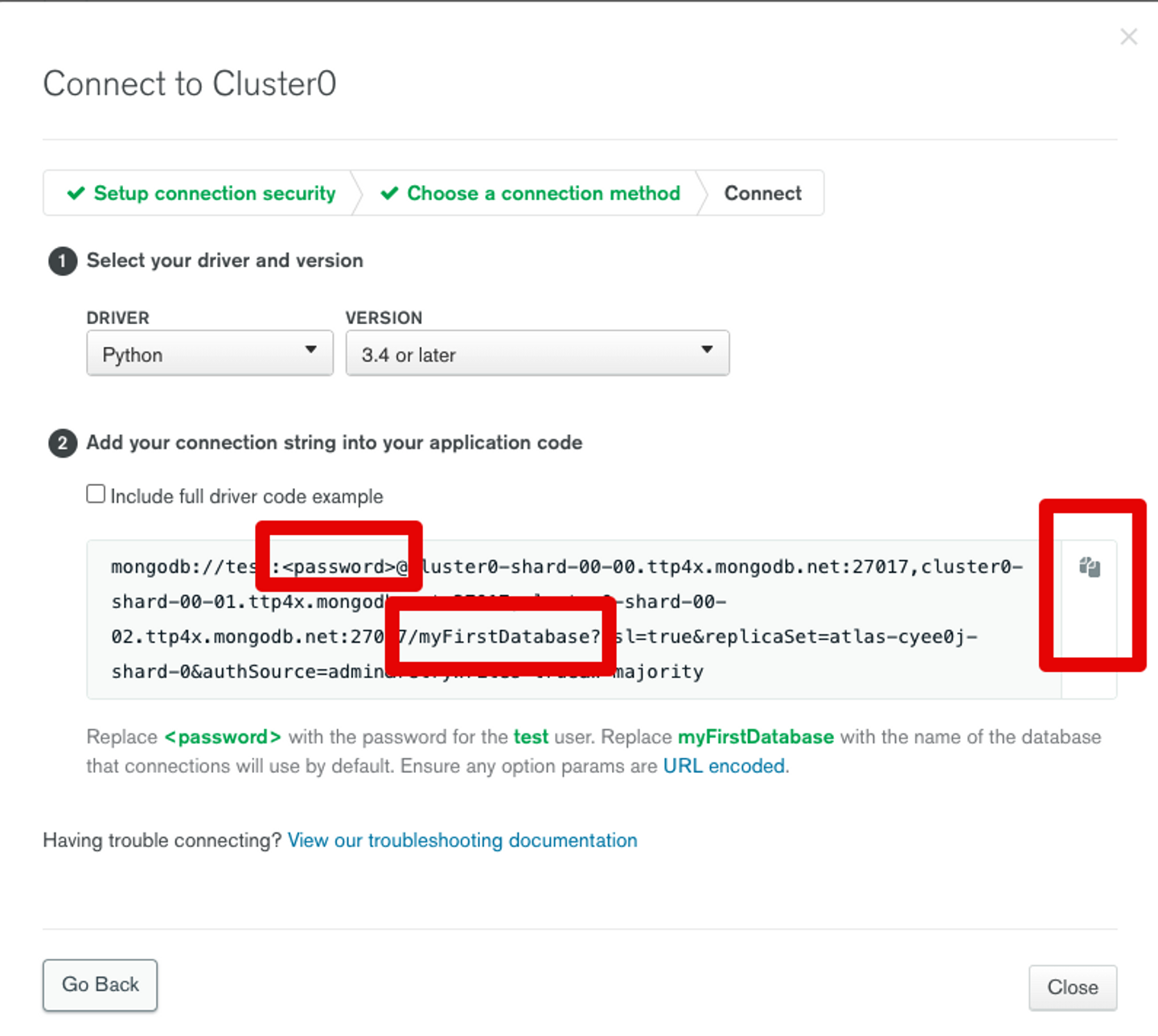
여기서 원래 3.6 or later로 설정해야 한다고 하는데 맥북은 dns 오류가 계속 떠서 3.4 or later 로 설정 후에 아래 코드로 install 후 그 다음 코드를 복붙해서 터미널에서 실행하니까 오류가 해결되었다 !
python -m pip install pymongo==3.4 💡 password 부분은 초기에 설정했던 password로 바꿔서 넣은 후에 코드 실행
2. 🔄 mongodb 연결해보기
다음 영화페이지를 스크래핑해서 순위, 제목, 평점을 db에 movies 파일에 업데이트 해보기 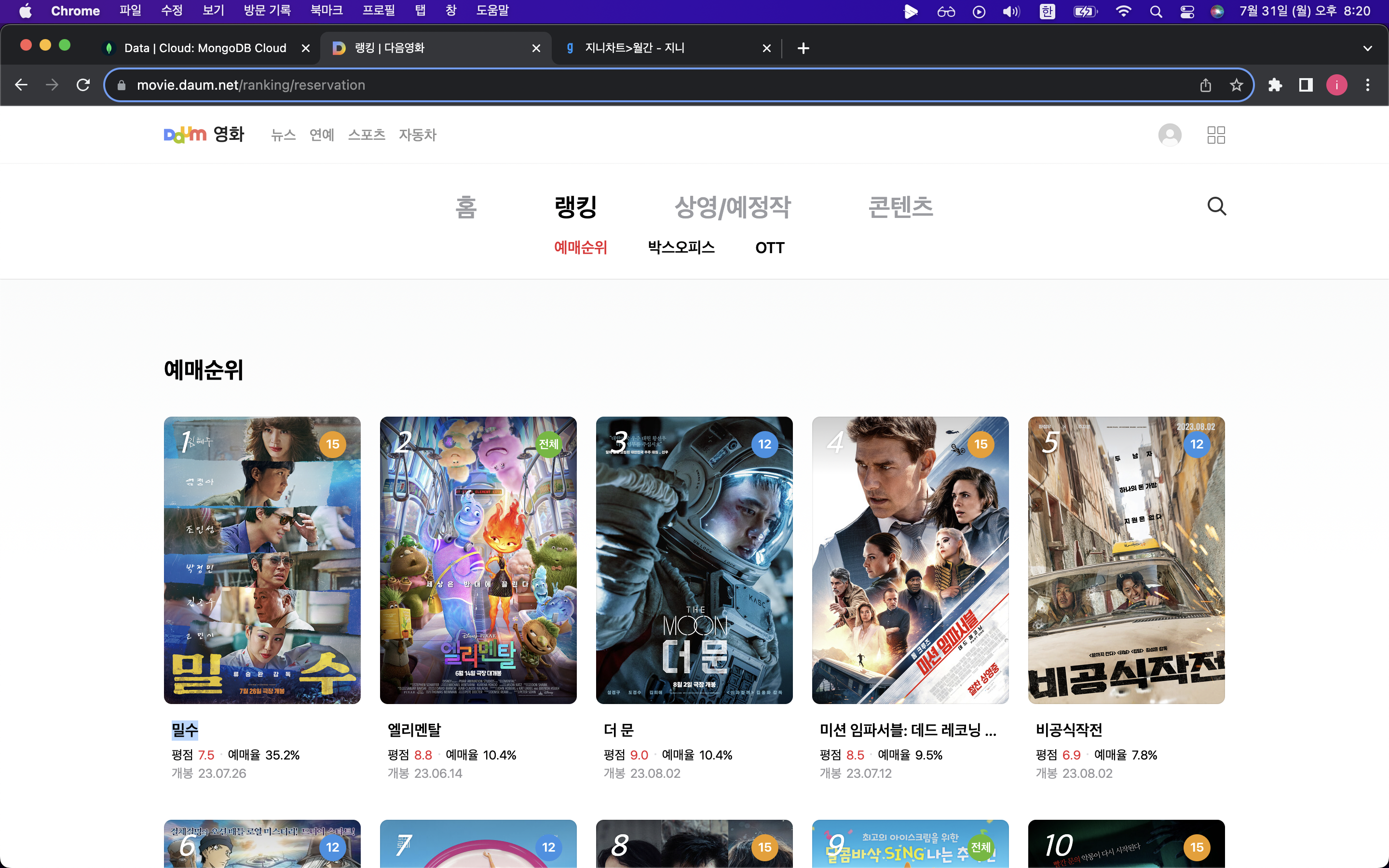
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
client = MongoClient('mongodb://sparta:test@ac-gbmvobs-shard-00-00.wzl4jv6.mongodb.net:27017,ac-gbmvobs-shard-00-01.wzl4jv6.mongodb.net:27017,ac-gbmvobs-shard-00-02.wzl4jv6.mongodb.net:27017/?ssl=true&replicaSet=atlas-lk9ter-shard-0&authSource=admin&retryWrites=true&w=majority')
db = client.dbsparta
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#mainContent > div > div.box_ranking > ol > li')
for li in lis:
rank = li.select_one('.rank_num').text
title = li.select_one('.link_txt').text
rate = li.select_one('.txt_grade').text
doc = {
'rank' : rank,
'title' : title,
'rate': rate
}
db.movies.insert_one(doc) #movies라는 collection에 저장출력결과💡
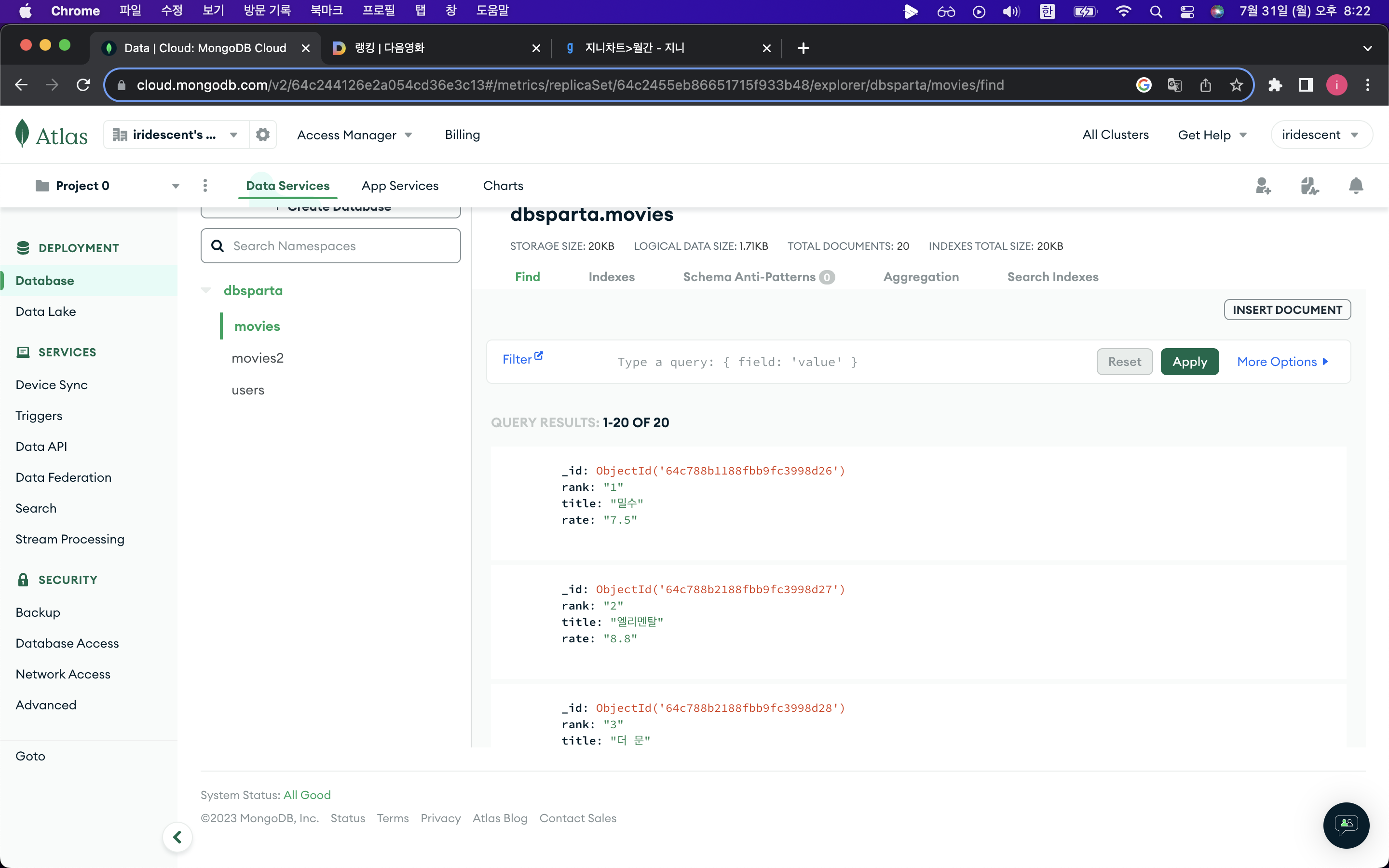
영화제목 하나만 가져오려면 ?! 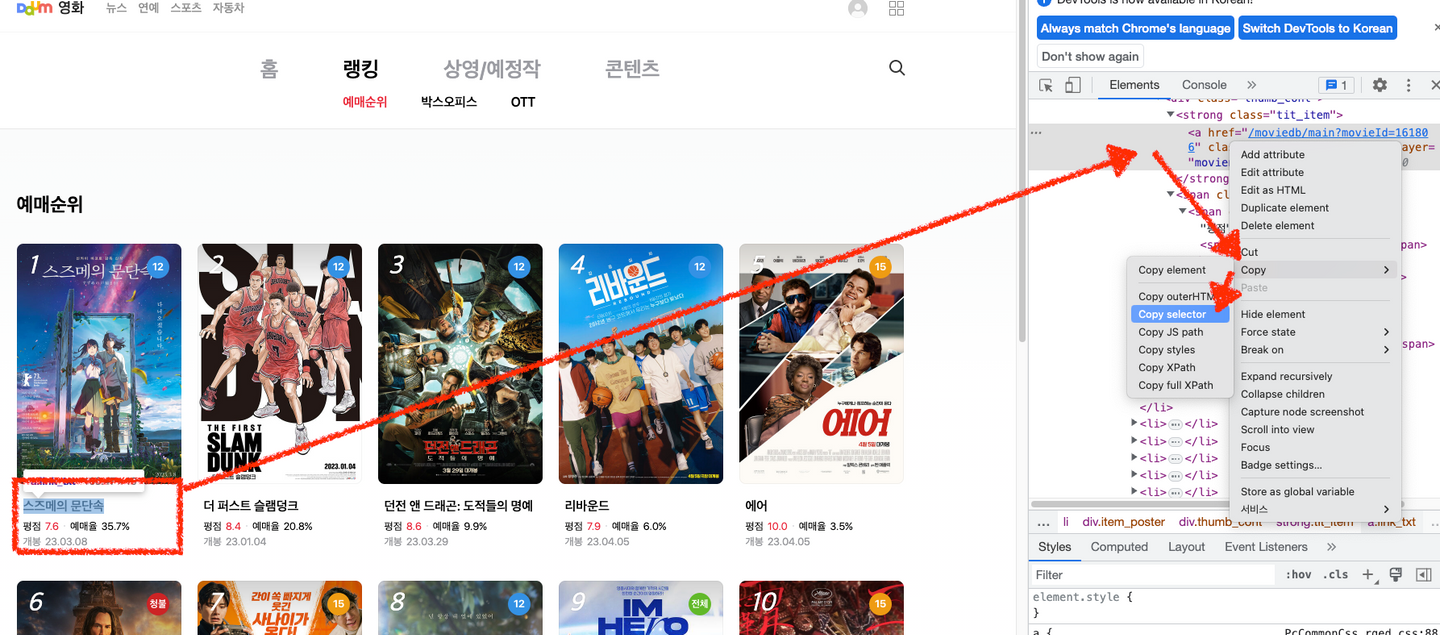
title = soup.select_one("#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a")
print(title.text)
li:nth-child(1) : 1위인 영화 제목만 가져온다는 뜻3. 지니뮤직 사이트 1~50위 곡 스크래핑 해보기 (순위/ 곡 제목/ 가수)
지니 뮤직 사이트 사용
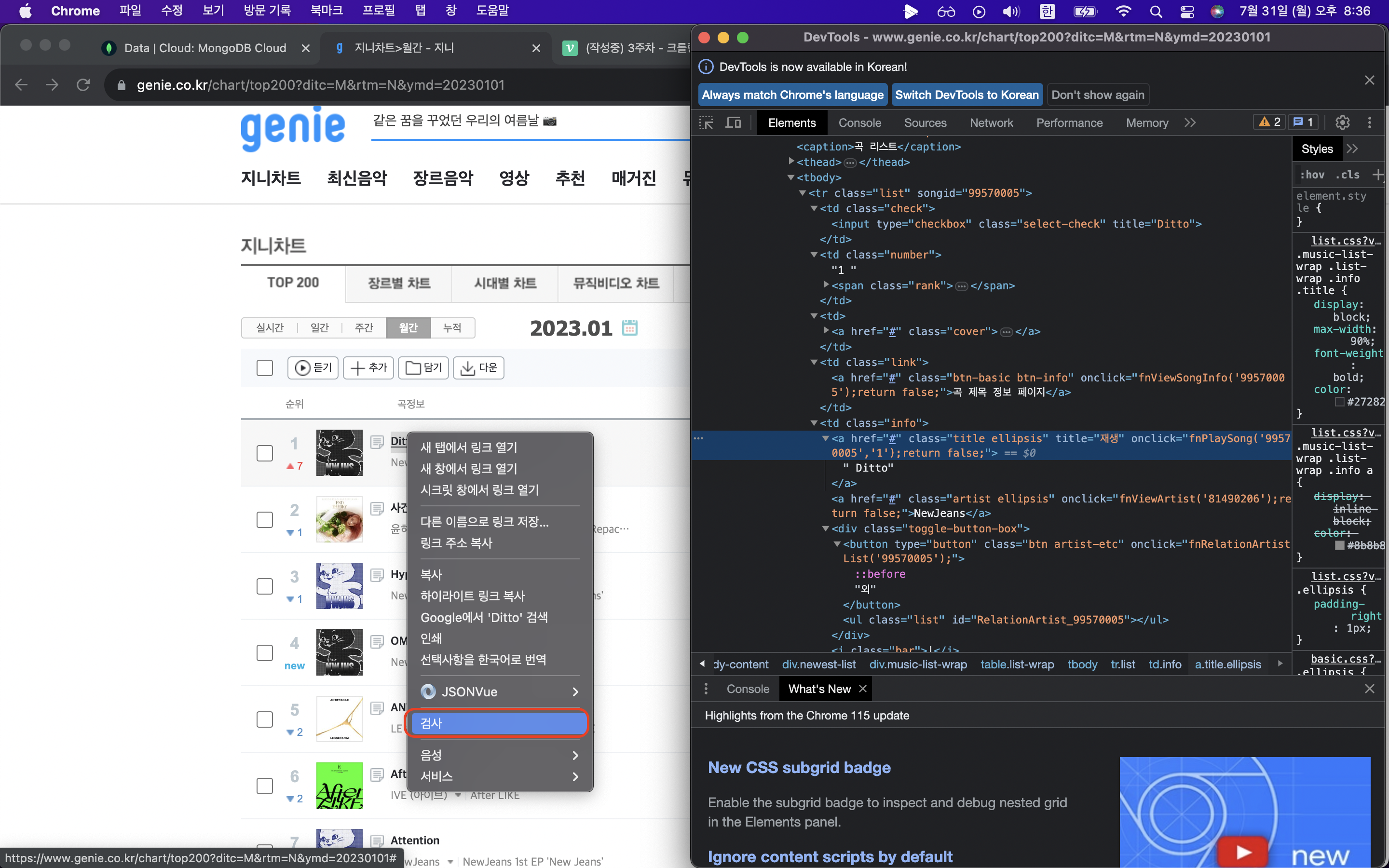
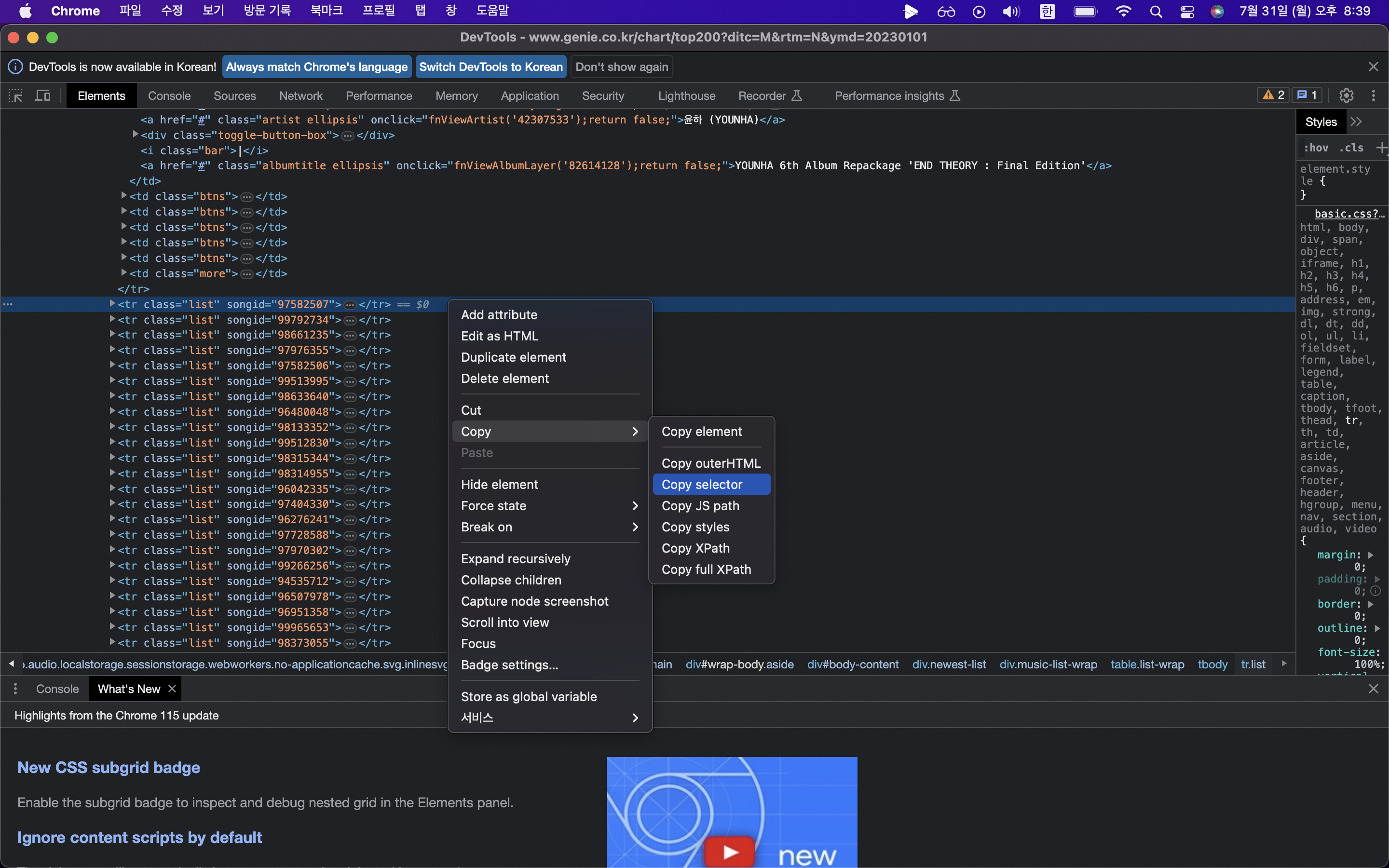
데이터 뼈대 가져오기 ( copy -> copy selector )
#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) 전체 코드는 이렇지만 데이터 하나만 가져오는 것이 아니기 때문에 코드를 **아래와 같이 수정해서 사용** #body-content > div.newest-list > div > table > tbody > tr:
현재까지 코드는 아래와 같음
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
제목, 가수, 순위에 해당되는 html 가져오기
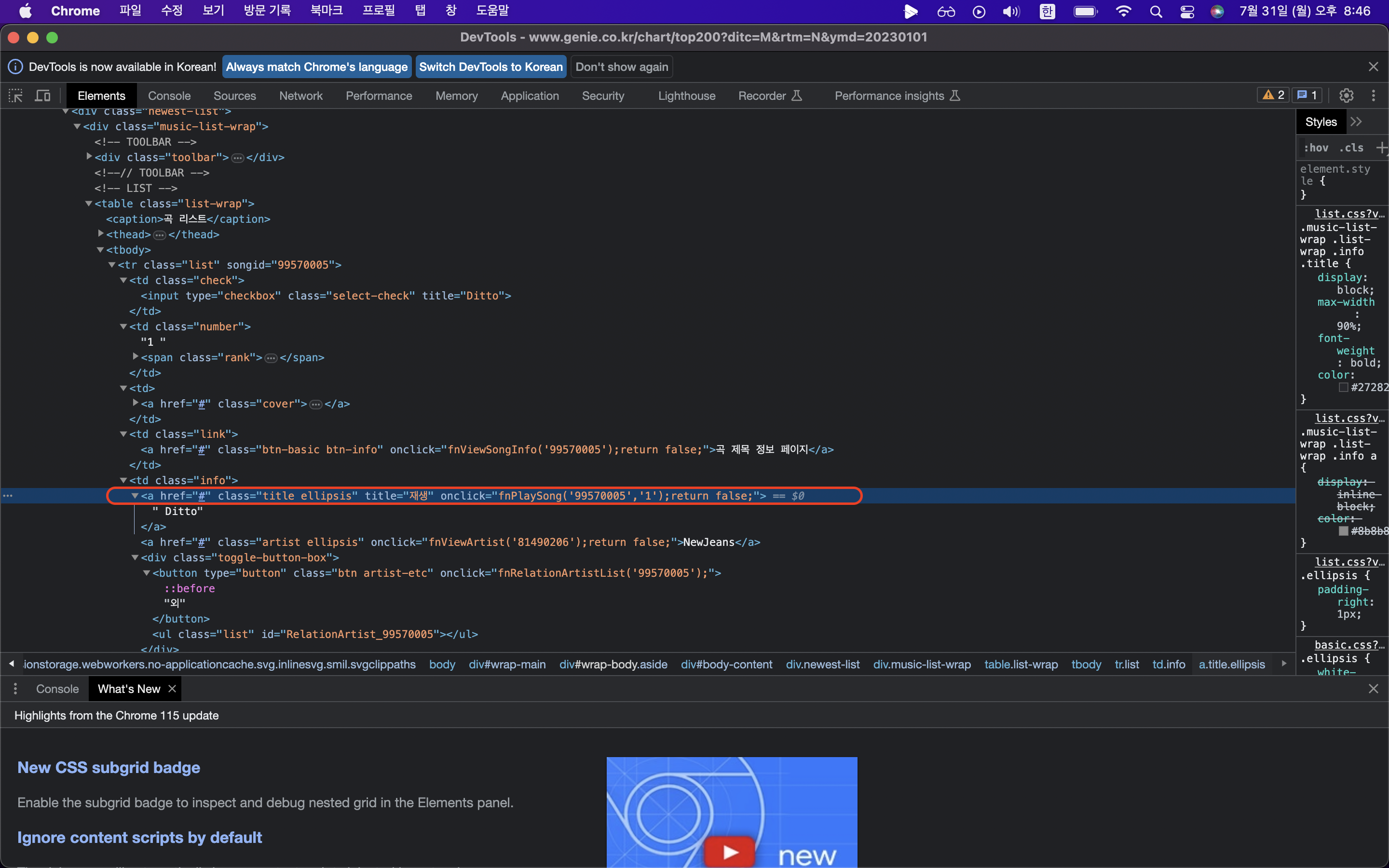
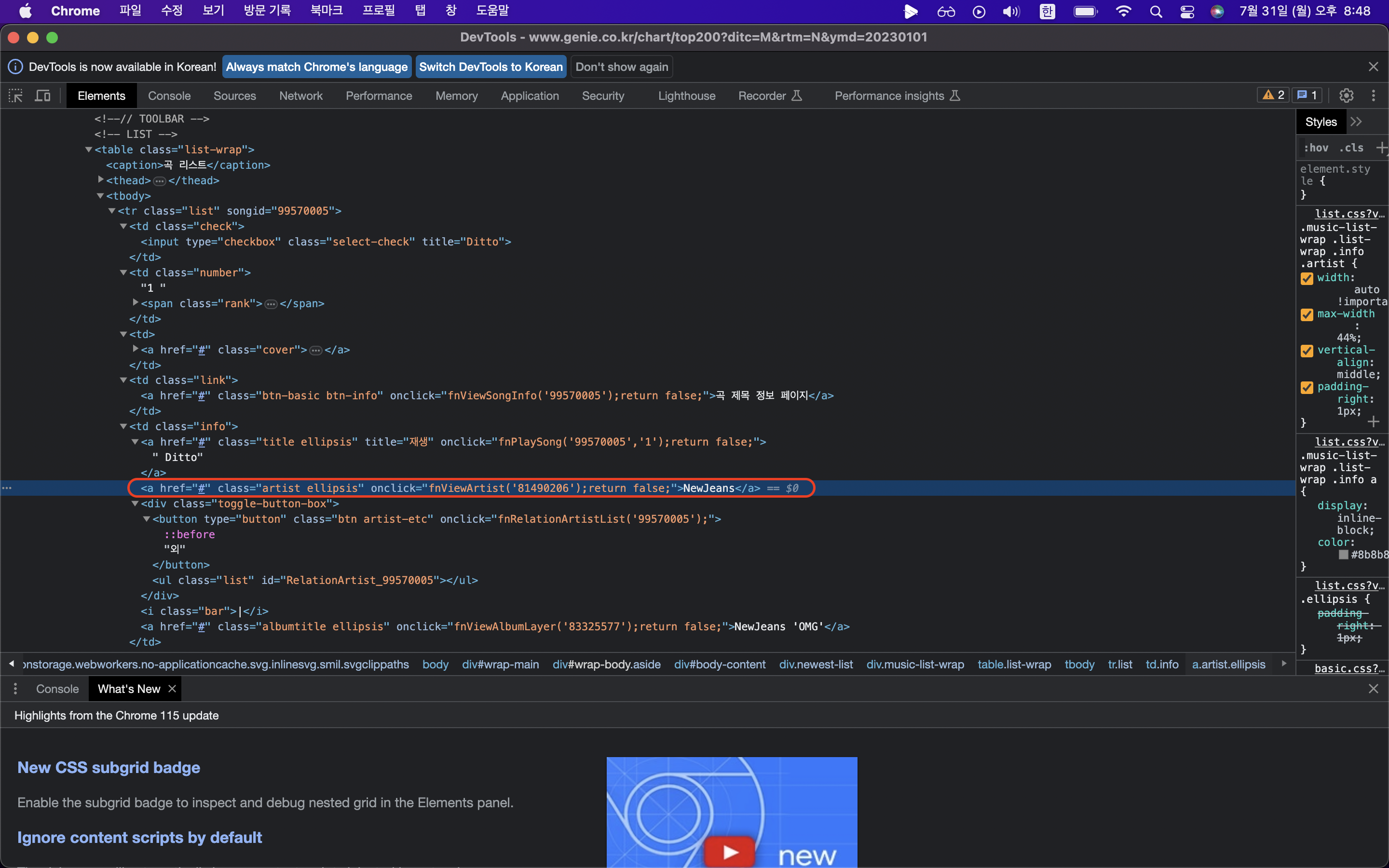
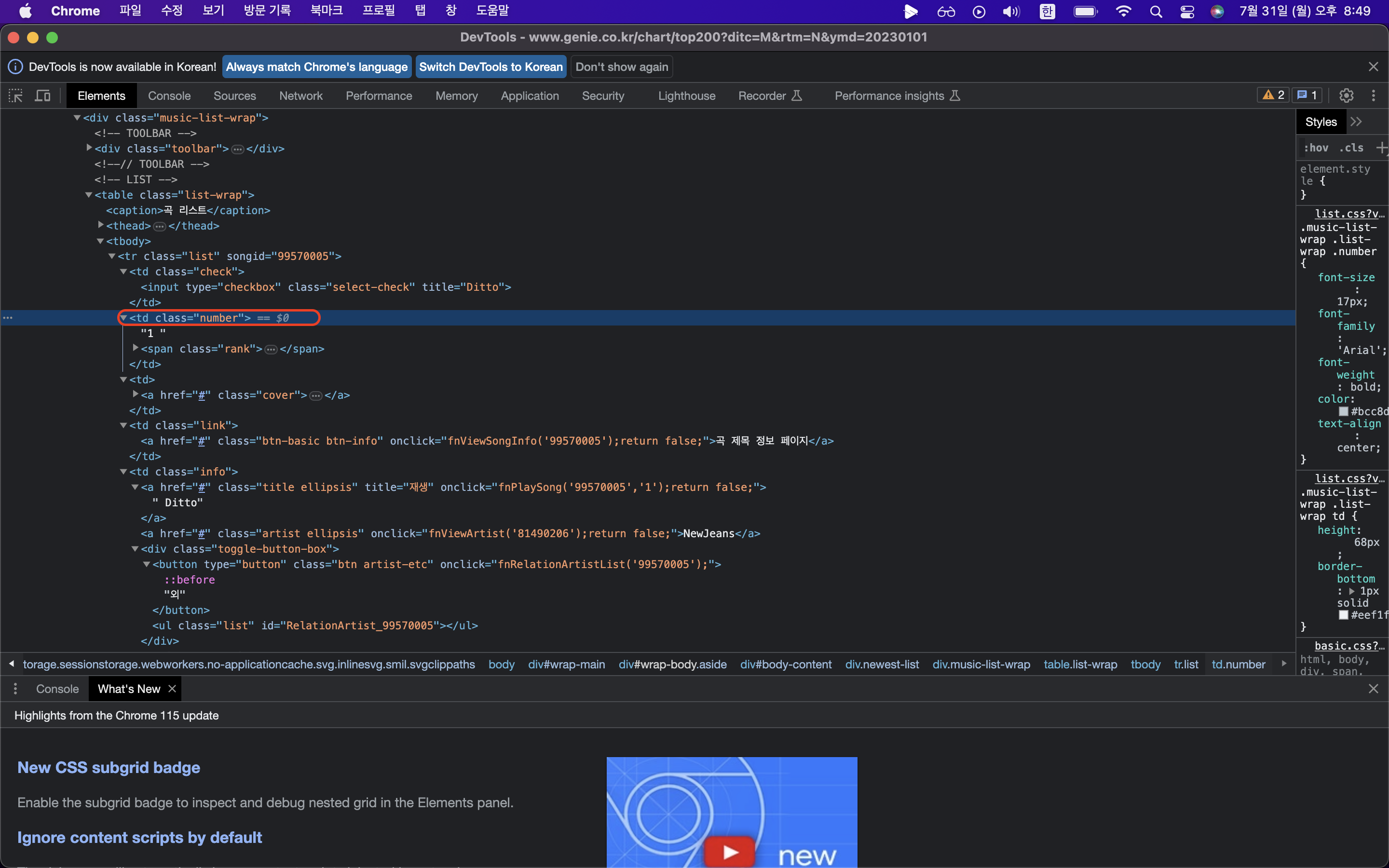
원래 copy selector까지 했을 때의 코드는 아래와 같지만
rank = #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number
title = #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis
artist = #body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis
lis에 이미 soup.select('#body-content > div.newest-list > div > table > tbody > tr')
까지 했기 때문에 최종 코드는 아래와 같다.☑️ 최종 코드 ☑️
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20230101', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
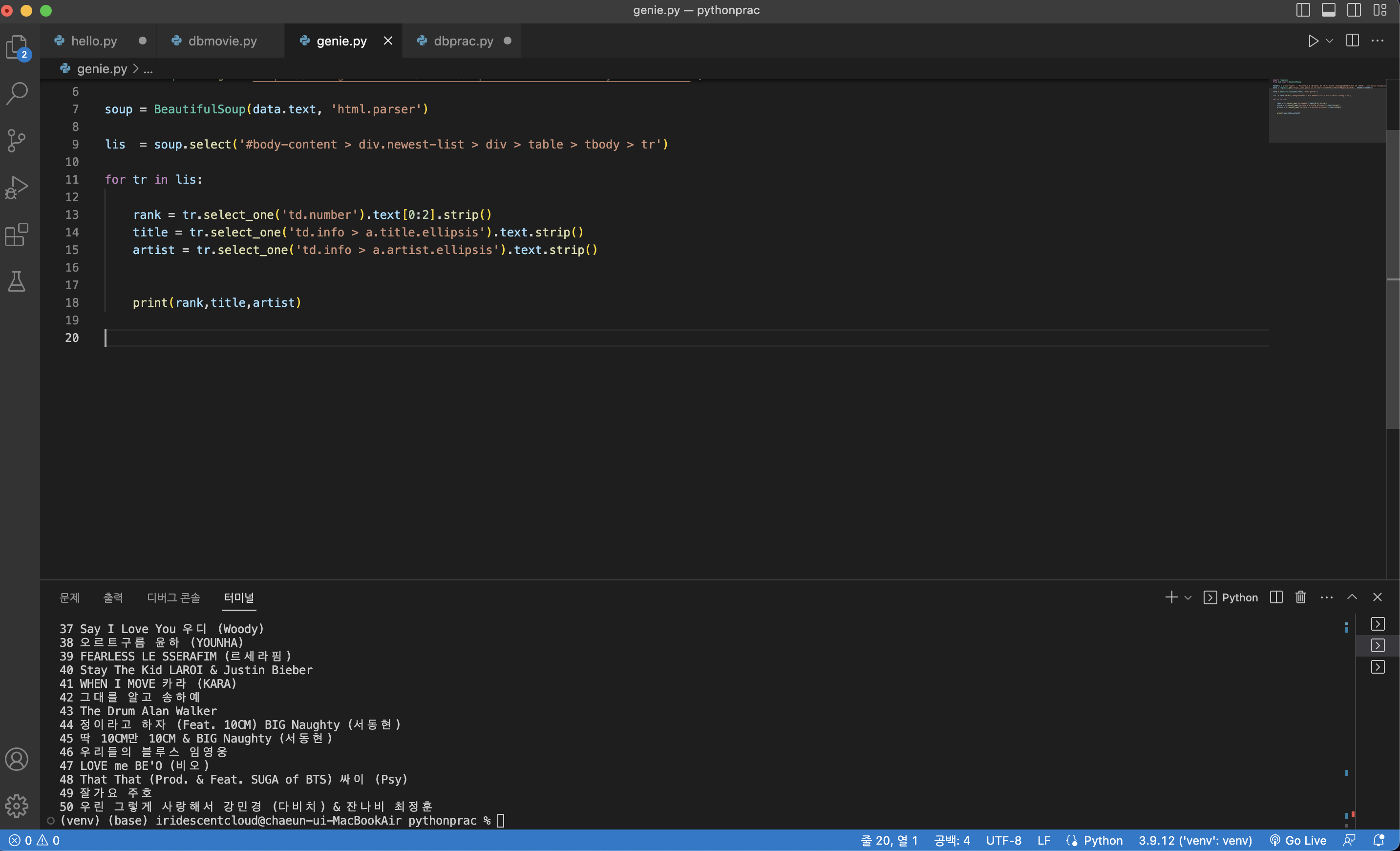
for tr in lis:
rank = tr.select_one('td.number').text[0:2].strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank,title,artist)
❗️주의❗️
strip(), 순위에서 text[0:2]를 해주지 않으면 아래와 같이 글씨가 잘리고 깔끔하게
나오지 않기 때문에 strip()을 통해서 공백을 제거해주고 text[0:2]를 통해 순위에 해당하는 숫자만 깔끔하게 나올 수 있도록 수정해준다.
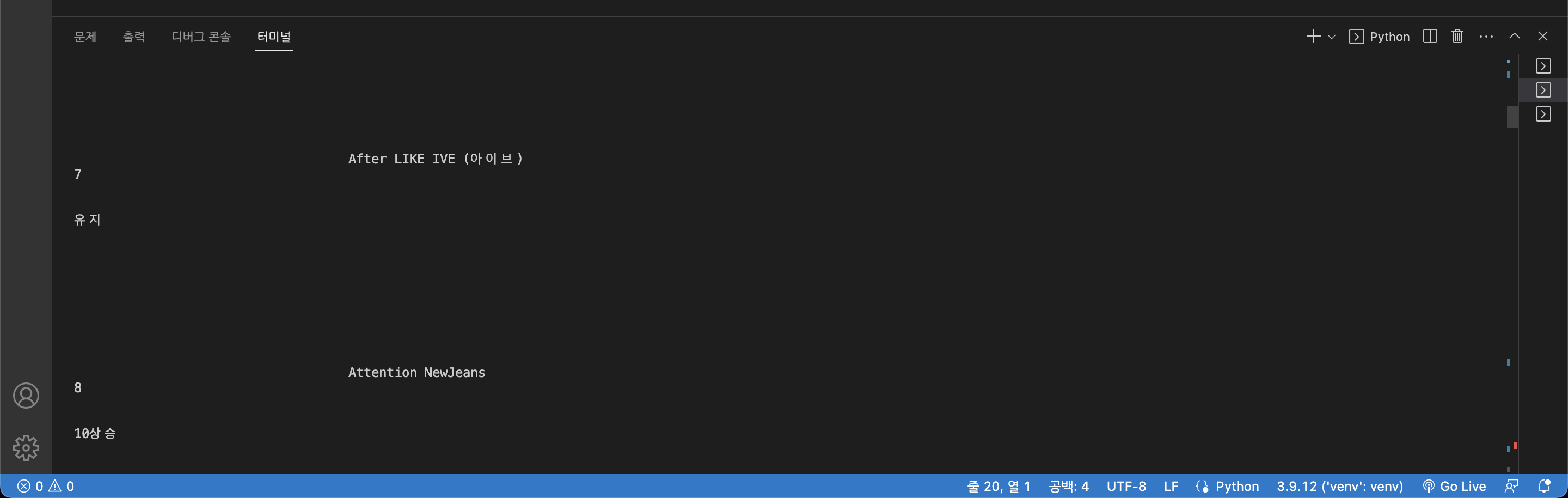
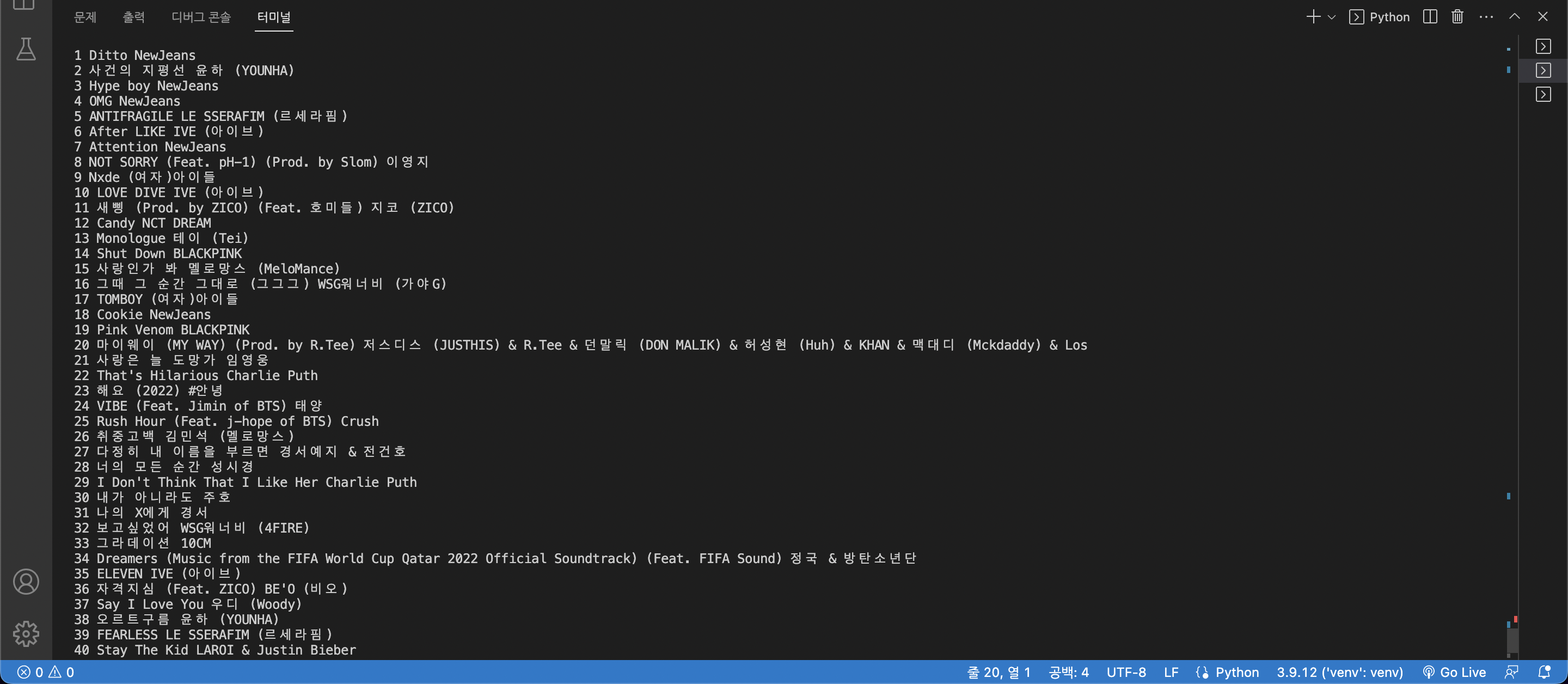
출력결과 💡