운영체제 상에서 커널쪽을 좀 더 자세하게 파보는 시스템 프로그래밍 수업을 기반으로 내용을 정리하고자 한다.
왜 리눅스인가?
리눅스는 오픈소스인 만큼 개인이 직접 들여다 볼수 있고, 개인의 용도에 맞게 튜닝도 가능하고, 또한 몇년간 많은 사람들이 참여해 계속 보완해온 만큼 리눅스 커널을 들여다보고 직접 튜닝해보는것은 중요하다고 할 수 있다. 개인이 어떠한 네트워크상의 프로토콜을 만든다고 할때 직접적으로 리눅스 커널 레벨로 들어가 만들어야 하며, 개인의 리눅스의 용도에 맞게 리눅스 커널을 통해서 최적화하는게 가능한 만큼 리눅스 커널을 직접적으로 만지고 공부해보는것은 세부적으로 네트워크, 최적화 분야에 있어서 필수라고 볼 수 있다.
리눅스의 역사에 대해서 간략하게 보면, 기존에는 벨 연구소에 의해서 개발된 유닉스라는 운영체제를 많이 썼었지만, 오픈되어 있지 않았고, 유료였다. 이 와중에 리누스 토르발스에 의해 오픈소스화 된 리눅스가 공개되면서 다양한 버전의 배포판이 생성되며, 많은 사람들이 참여해 지속적으로 개발된 운영체제라 할 수 있다. 지속적으로 버전마다 업데이트가 추가되어 발전해오고 있으며, 매버전마다 몇만줄의 코드가 추가되어 나온다고 한다.
리눅스 버전과 관련해서 2~3달 주기로 업데이트되는 버전인 mainline kernel이 존재하며, mainline kernel이 나오기 전까지 각종 버그들에 대한 픽스를 하는 developement/RC kernel 이 존재하며, mainline kernel이 나온 이후에 발생한 버그들에 대한 픽스들이 진행된 stable kernel이 존재한다. 추가적으로 많이 쓰이는 커널 버전에 대해서는 해당 버전에 관해서 버전을 업데이트 시키지 않고 특정 버전에 관해서 지속적으로 관리를 해주게 되는데 이러한 커널은 LTS kernel이라 한다.
듀얼 모드
하드웨어적으로 cpu 상에서는 두가지 모드가 돌아가게 된다. 유저 모드/커널 모드로 돌아가게 되며, 유저모드의 경우 유저의 프로그램이 돌아가게 되며, 커널 모드에서는 커널 코드를 바탕으로 운영체제 상의 로직이 돌아가게 된다. 두가지 모드를 왔다갔다 하면서 cpu 상에서 코드가 돌아가게 되며, 여기서 모드의 전환은 세가지의 경우에 대해서 전환된다.
첫번째는 하드웨어 인터럽트가 발생하는 경우로, 지금 돌아가고 있는 프로세스가 아닌 외부에서 인터럽트를 발생시켜 커널모드로 스위칭하는 경우이다. 두번째는 소프트웨어 인터럽트로 현재 돌아가고 있는 프로세스에서 인터럽트를 발생시켜 커널모드로 전환되는 경우이다. 세번째 경우는 시스템콜을 호출할 경우 커널모드로 스위칭을 한다음 해당 시스템콜을 수행하는 경우이다. 여기서 커널 모드에서 돌아가고 있는 커널 또한 코드중 일부분이며, 커널 코드는 유저의 코드가 cpu에서 돌아가는것처럼 돌아간다고 할 수 있으며, 커널 코드는 유저의 프로세스 뒤에 숨어서 돌아간다고 할 수 있다. 그러면 이제 관건은 커널 코드를 돌리기 위해서 커널 코드에 해당하는 코드를 메모리에 어떤식으로 올려야 되는지에 대한 것인데, 메모리에 미리 커널영역에 해당하는 공간을 할당하는 식으로 해결한다.
메모리 상에서 커널영역/유저 영역에 해당하는 공간을 미리 할당을 하고, 모드 스위칭이 일어날때마다 커널 영역에 있는 코드가 실행된다. 멀티 프로세서 기준으로 여러 프로세스들이 커널 영역에 해당하는 공간을 공유해서 사용하며, 커널 모드로 전환될때 모드 스위칭이 일어나 커널영역에서 cpu가 동작하게 된다고 볼 수 있다. 이러한 방식으로 미리 커널영역에 해당하는 공간을 메모리에 배정하게 되면 프로세스가 메모리를 덜 사용하게 되지만, 모드 스위칭이 일어날때마다 커널 프로세스에 해당하는 부분을 메모리에 올리는 context switching이 일어나지 않아도 되기 때문에 이점이 있다. cpu 상에서 타이머 인터럽트가 많이 발생한다는점에서 보면 모드 스위칭에서의 속도는 성능의 중요한 판단기준이 되며, 이러한 점에서 미리 커널 영역에 해당하는 공간을 선점하는 것은 속도면에서 이점이 있다. 추가적으로 보면 여러 프로세스들이 커널 영역을 공유하고 있기 때문에 여러 프로세서에서 동일한 커널 여역에 해당하는 코드를 사용하는 경우 critical section의 문제점이 생긴다고 할 수 있다.
프로세스
프로세스는 passive한 상태에 있는 프로그램이 컴퓨터상으로 돌아가고 있는것으로 볼 수 있다. 프로세스의 경우 이미지와 process context로 구성된다. 이미지의 경우 코드,데이터,스택,힙으로 구성되어 있다. 코드의 경우 실제 코드가 존재하는 영역이며, 데이터의 경우 전역변수와 정적 변수가 정의된 공간이며, 스택의 경우 함수호출과 지역변수와 관련해서 저장되는 공간, 마지막으로 힙은 동적 할당을 위한 공간이다. process context의 경우 program context와 kernel context로 이루어져 있으며, program context의 경우 실제 프로그램이 돌아갈때 할당된 레지스터의 정보등으로 이루어져 있으며, kernel context 상으로는 프로세스 아이디, 그룹 아이디와 같은 정보들로 이루어져 있다.
하지만 기술의 발전으로 인해 기존의 프로세스의 모델에 대해 한계점이 발생한다. cpu가 싸지면서 여러개의 cpu를 활용하는 기술들이 발전하는 와중에 기존의 프로세스 모델로는 여러개의 cpu를 활용하는데에 있어서 한계점이 발생한다. 예를 들어서 웹서버를 여러개의 cpu를 활용해 서비스하는경우, 프로그램 카운터가 하나밖에 없기 때문에 기존의 프로세스에서 포크를 하는 방식으로 또다른 프로세스들을 생성하는 방식으로 진행할 수 밖에 없는데, 이는 fork된 프로세스 상에서 중복되는 자원이 많다는 점에서 보면 낭비가 심하다 할 수 있다. 이와 관련해 단일한 프로세스를 다수의 프로세서에서 돌리는 방안이 떠올랐고, 스레딩에 대한 개념이 생성된다.
스레드
프로세스를 스레드 단위로 나누어 실행하게 되며, 공유할수 있는 범위/공유하지 않고 독립적으로 관리되어 하는 범위로 나눌 수 있는데, 기존의 프로세스의 구성을 보게 되면 kernel context, shared library, data, heap에 대한 부분은 모든 쓰레드에서 공유하며, 각 스레드 별로 로컬 스택과 cpu register의 경우 따로 관리를 해줘야 되는 필요성이 생긴다. 기존의 프로세스 모델에 비해 스레드로 분할된 프로세스의 모델을 살펴보면 각 스레드 별로 할당된 스택들이 별도로 관리되며, program counter와 각각 관리된다. 멀티 프로세싱과도 비교해보면 스레드의 경우 멀티 프로세싱의 경우 fork를 할 경우 수직적인 구조로 프로세스가 구성되다 보니 부모 프로세스가 죽게될 경우 자식 프로세스들이 다 죽게 되지만, 멀티 스레딩의 경우 해당 스레드가 죽게 되더라도 다른 스레드에 지장을 주지 않는다. 이러한 스레딩을 코드상으로 구현하는것은 순전히 개발자의 몫이며, 멀티 스레딩을 위해서 다양한 라이브러리들을 개발되어 왔지만, 현재에 이르러서는 pthreads라는 라이브러리가 표준으로 자리잡았다고 볼 수 있다.
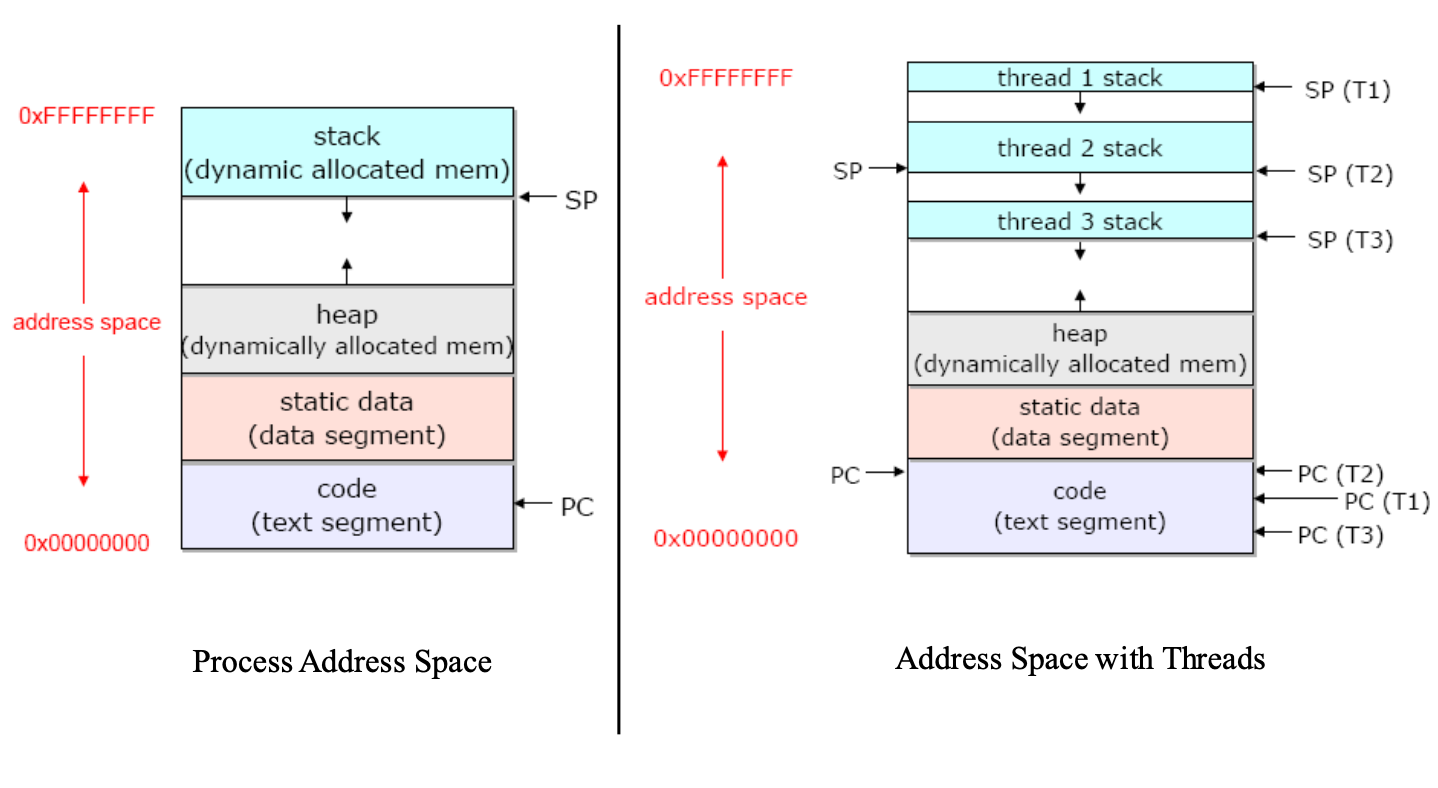
리눅스에서의 프로세스
리눅스 상에서의 프로세스를 좀 더 깊게 들여다보기 전에 유저스택/커널 스택, pcb에 대해서 알아보면 일단 프로세스는 유저 영역에서는 프로세스 실행을 위한 스택을 할당 받지만, 커널 모드에서 유저모드로 모드 스위칭을 할때 복원할 프로세스의 정보, 유저모드에서의 스택이 부족할 경우 사용하기 위해 프로세스는 커널영역에서도 스택 영역을 할당 받는다. pcb에 대해서 알아보면 pcb는 process controll block으로 커널에서 프로세스를 제어하기 위해 저장하는 별도의 구조체라고 볼 수 있다. 구체적으로 리눅스 상에서는 task_struct 라는 구조체를 통해서 pcb를 저장하고 있다. 기존의 리눅스 버전에서는 이러한 task_struct라는 구조체가 커널 스택상의 가장 아래에 저장되어서 프로세스에 대한 정보를 저장했었지만, 리눅스 커널이 발전하게 되면서 기존에 없던 thread_info라는 구조체가 이를 대신해 커널 스택 아래 영역에 저장되어 task_strcut를 향하는 포인터가 이곳에 저장되어 있다. 이 배경에는 기존의 task_struct 의 재사용을 위해서 (thread의 개념이 들어오면서 공유 리소스가 많이 생겨서 그런것 같다) slab allocator를 통해서 메모리 할당을 하게 되었고, 커널 스택 영역에서는 task_info라는 구조체를 통해서 해당 프로세스에 해당하는 task_struct를 가르키게 되었다. task_info는 architecture dependent한 정보가 담겨 있고, task_struct에는 generic한 정보가 담겨있다고 한다.
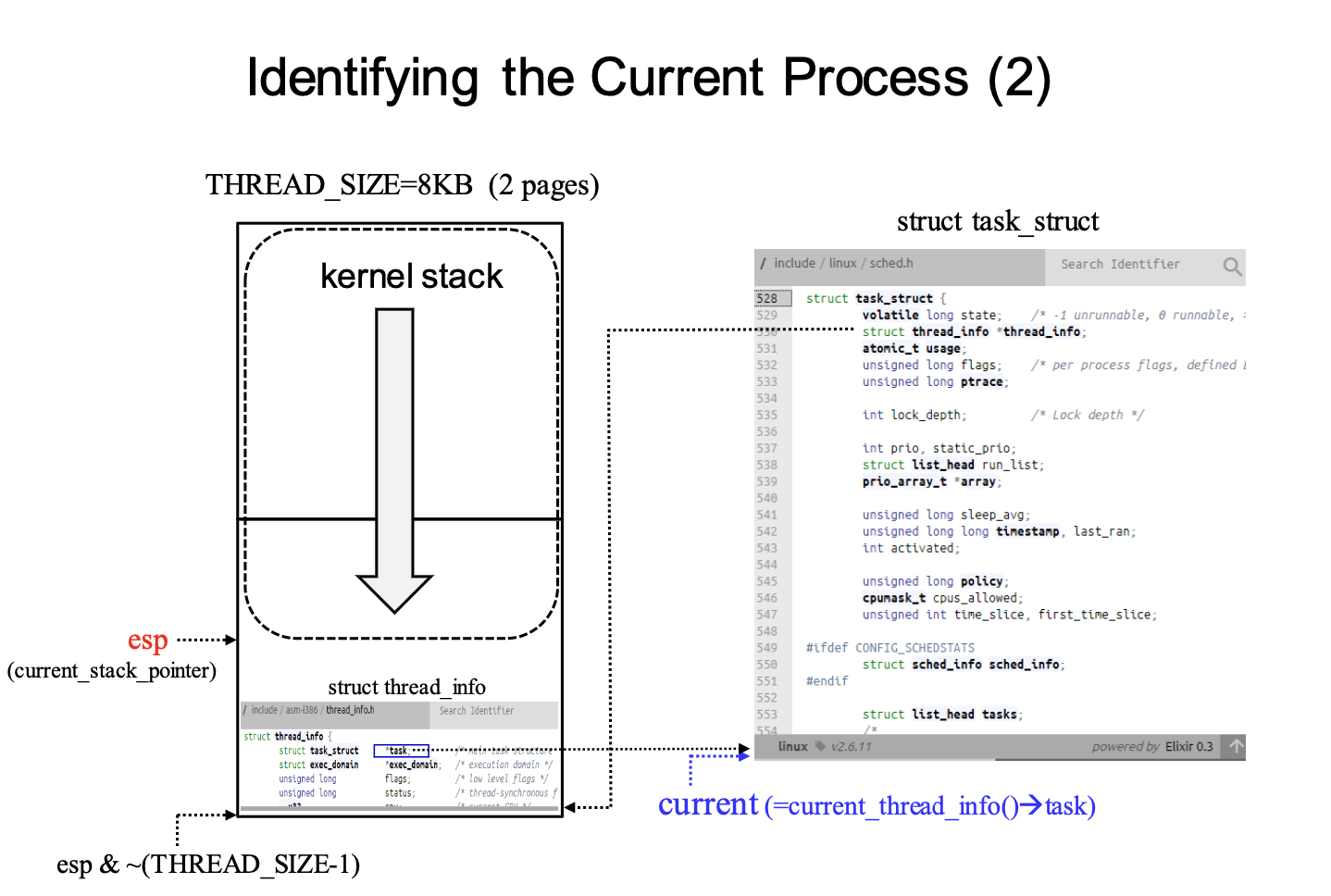
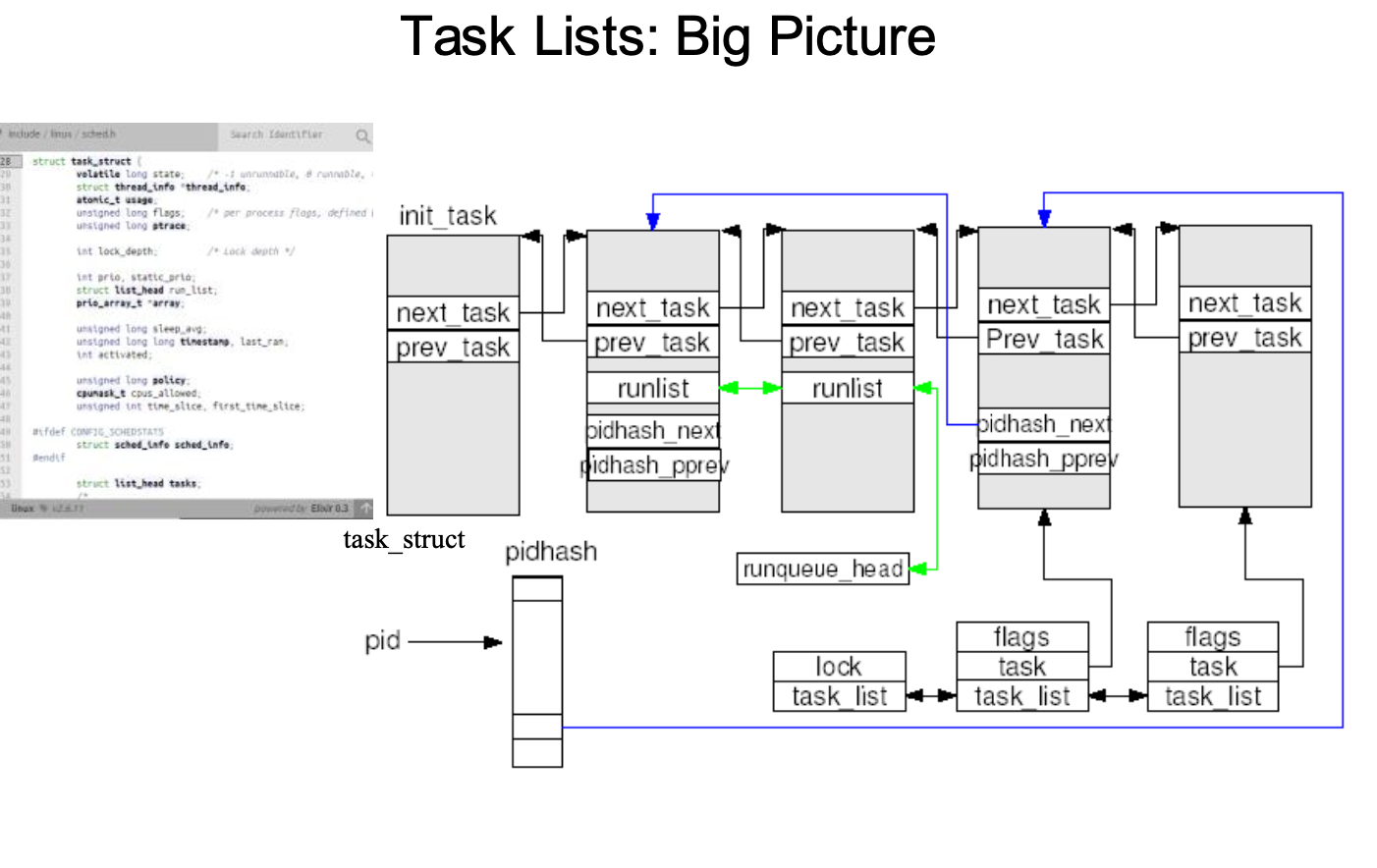
task_struct라는 구조체를 통해서 리눅스의 pcb가 정의되고 커널 스택의 밑 부분인 task_info가 해당 pcb에 대한 포인터를 가르키는데 이제 요점은 대체 pcb는 메모리 커널 영역에서 어떻게 저장되고 어떤식으로 관리되고 있는지를 보면 일단 pcb 저장에 대한 메모리 할당은 dynamic memory allocation을 하는 방식으로 kma(kernel memory allocator)라고 따로 커널 쪽에서 메모리 할당을 하는것이 존재한다고 한다. 커널에서는 기본적으로 몇개의 이중 리스트를 통해서 프로세스들을 관리하며, 탐색을 지원한다. 여기서 이중 포인터로 다음 task, 이전 task 들을 가르키게 되면 포인터 조작을 통해서 프로세스 저장을 관리하게 된다. 추후에 설명하실 거라 하셨지만 구체적으로 ready queue에 있는 프로세스들의 경우 2.6 커널기준으로 140개의 우선순위를 기준으로 각각의 연결리스트를 통해서 프로세스를 관리하고, 다음 실행할 프로세스를 정하게 된다. 또한 wait queue 같은 경우 특정 사건이 일어날때까지 대기하는 프로세스들이 대기하는 큐이며, 구체적으로 보면 io controller 관점에서 pending된 요청을 수행한다고 할 수 있다. io device 마다 wait queue가 존재하며, io device 에서 처리를 해줄 때까지 기다리는 프로세들이 존재한다.
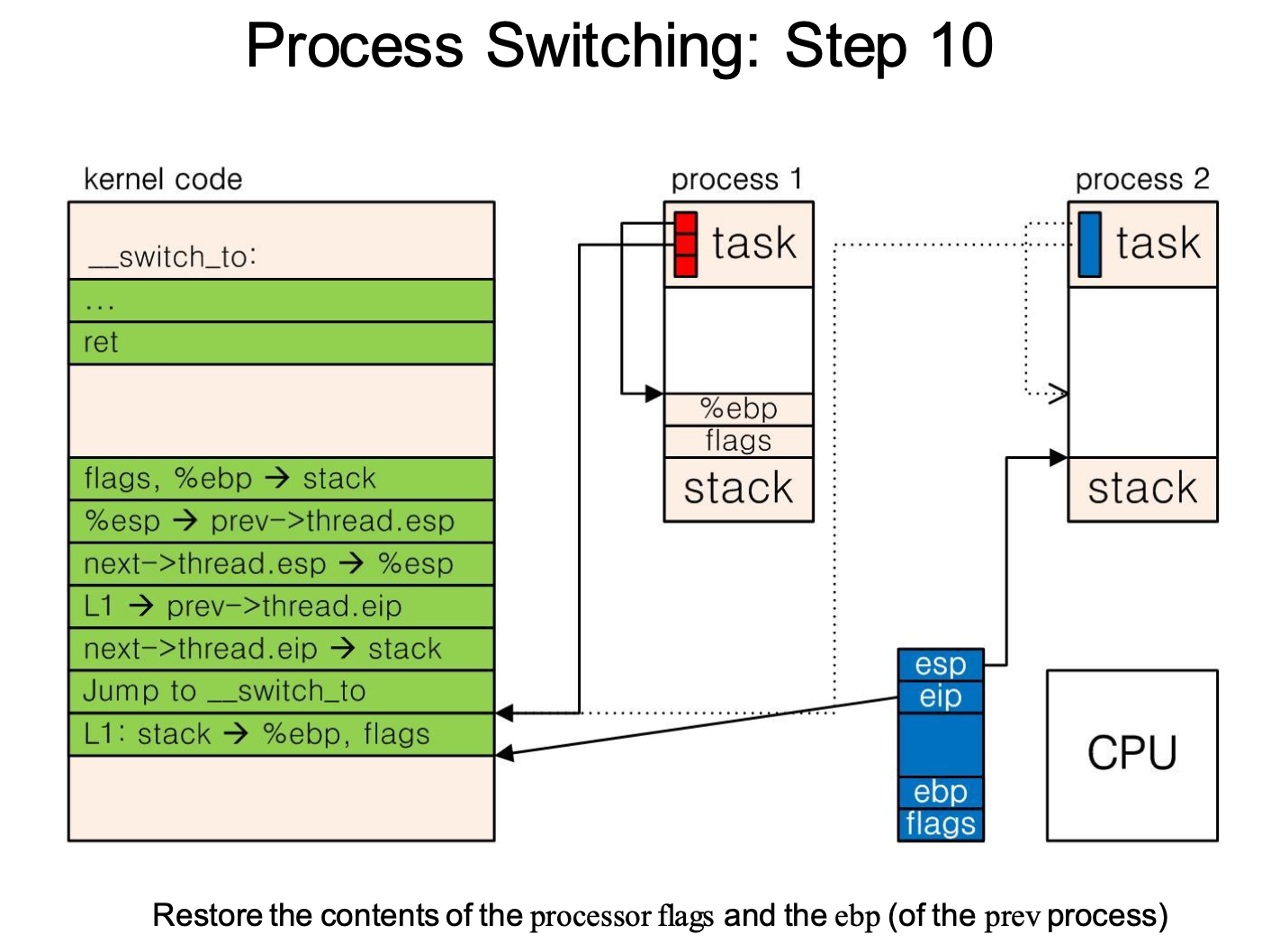
context switching이 일어날 경우 기존의 프로세스에 대해서 레지스터, pc와 같은 정보를 커널영역에 저장을 하고 다시 해당 프로세스가 실행 될때 커널 영역에서 유저 영역으로 저장한 정보를 복원해서 돌려야 할 필요성이 생긴다. 이러한 hardware conetext의 경우 pcb와 kernel stack에 나눠서 저장하게 된다. pcb의 경우 따로 architecture dependent한 thread_struct라는 구조체를 통해서 프로세스의 program context를 저장하게 된다. 추가적으로 context switching의 경우 페이지 테이블에 있는 정보도 갱신해줘야 되는데 이는 추후에 다룰 예정이라고 하셨다. 구체적으로 context switching이 어떻게 일어나는지에 대해서 커널 코드 레벨로 들어가게 되면 assembly 언어단위로 실행되는 switch_to macro를 통해서 이뤄지게 된다. switch_to macro를 이용해서 실제 프로세스에 대한 hardware context가 스위칭이 일어난는것 이외에 context swithching이 일어나기 위해 커널 모드로 돌입한 이후에 커널 스택 간의 스위칭이 일어나게 되는데, 실제 어셈블리 단계에서 어떤식으로 이뤄지는지에 대해서 살펴보자. 밑에 있는 어셈블리 명령어들을 보게 되면 kernel mode에서의 context switching에 관한 동작을 알 수 있는데, 상황을 전 프로세스 prev에서 다음 프로세스 next로 context switching을 한다고 생각해보자. 전체적으로 보면 context switching을 하기 위해서 유저모드에서 커널 모드로 전환을 하고, prev에서 next 로 context switching을 하게 되는 경우 처음에는 prev의 커널 스택에서 context switching을 위한 커널 코드가 돌아가게 된다. 해당 커널 코드를 분석해보면 다음과 같이 실제 process의 user space에서의 context switching 을 위한 switch_to 매크로 이외에도 esp,ebp,eip를 이용한 process의 kernel space에서의 switch도 일어난다. 이를 자세히 보면,
- flags, %ebp --> stack : prev process에 대한 flag와 ebp register에 대한 저장
- %esp --> prev->thread.esp : prev process의 유저영역에 대한 정보인 flags,ebp에 대한 정보를 kernel stack에 저장하게 되고, 이에 해당하는 kernel stack에 대한 esp의 정보를 pcb.thread_struct.esp에 저장하게 된다.
- next->thread.esp-->%esp :다음 프로세스인 next의 esp register에 대한 정보가 next의 pcb.thread.esp에 있을 것이고 이를 esp레지스터에 불러온다.(커널 스택의 스위칭이 일어난다고 볼 수 있다)
- label 1 address --> prev->thread.eip : label 1의 주소를 prev의 pcb.thread_struct에 저장한다(추후에 prev프로세스가 다시 실행될때 label 1 에 해당하는 명령어를 통해서 ebp, flags를 복원하기 위해서)
- next->thread.eip --> stack : next.pcb.thread_struct.eip에 있는 ebp,flags의 복원을 위한 명령어의 주소를 불러온다.
- jump to __switch_to()(exchange rest of the context) : 나머지 hardware context switching을 위한 명령어를 실행
- label 1 : stack --> %ebp,flags : ebp, flags에 대한 레지스터의 복원을 해준다.
context switching에 있어서 실제 유저 영역에서의 레지스터 switching, 커널 영역 레지스터의 switch가 일어나기 때문에 복잡한것처럼 보이지만, 정리하자면 switching이 일어나야 할 정보들은 커널영역에서 돌때의 esp,eip 그리고 process의 유저 영역에서의 ebp,flags,이를 제외한 hardware context라고 할 수 있다. 여기서 ebp와 flags는 process 커널 영역을 이용한 switching이 이루어지고, 나머지 hardware context와 kernel mode에서의 esp, eip는 pcb.thread_struct를 이용해서 switching이 이뤄진다. 여기서 eip는 프로세스의 ebp와 flags 의 복원을 위한 명령의 주소를 저장한다. 간단히 정리하자면
- %ebp,flags 를 전 프로세스의 커널 스택에 저장
- 커널 스택 크기가 변경됨에 따라 변경된 %esp를 전 프로세스의 pcb에 저장
- 다음 프로세스의 pcb에서 %esp를 복원
------ %esp 복원 완료 ------ - 전 프로세스에서 추후에 스택에 저장된 %ebp,flags복원을 위한 커널 코드의 주소를 pcb에 저장
- 4번과 연관되서 다음 프로세스의 %ebp,flags의 복원을 위한 커널 코드의 주소가 pcb에 저장되어 있을텐데, 이를 다음 프로세스의 커널 스택에 복원(추후에 해당 커널 코드를 실행하기 위해서)
- switch_to macro로 가서 %ebp,flags를 제외한 유저 영역에서의 hardware context의 복원
------ %ebp,flags를 제외한 유저영역에서의 hardware context 복원 완료 ------ - switch_to macro가 다 돈 다음 가르키는 주소는 5번에서 커널 스택에 저장한 복원을 위한 커널코드의 주소를 가르키게 되있으며 그곳으로 eip가 간다.
------ %eip 복원 완료 ------ - 복원을 위한 명령어로 가서 %ebp,flags에 대한 복원이 이루어진다.
------ %ebp,flags 복원 완료 ------
최종적으로 context switching이 완료된 이후의 프로세스의 구조를 보게 되면 전 프로세스의 경우 pcb에 ebp,flags가 들어가있는 커널 스택을 가르키고 있는 esp가 저장되어 있으며, 추후에 해당 프로세스의 ebp,flags의 복원을 위한 eip의 값도 저장되어 있으며, 나머지 hardware context가 저장되어 있는 상태이다. 현재 돌아가고 있는 프로세에 대해서 동일하게 저장되어 있겠지만 단지 ebp,flags에 대해서 복원이 되면서 커널 스택에서 빠져있는 상태일 것이다. 여기서 그림을 보게 되면 pcb esp가 과거에 ebp와 flags가 빠져나가기 전에의 위치를 가르키고 있는것을 볼 수 있으며, 추후에 해당 프로세스가 context switching이 될 경우 해당 값이 갱신될것으로 볼 수 있다.

기존의 프로세스 모델에서 스레드라는 개념이 생성되면서 기존의 프로세스 관리 방식에 있어서 변경점이 있었다. 리눅스를 제외한 다른 운영체제에서는 스레드를 관리하기 위한 기존의 프로세스를 관리하는 자료구조, 코드를 바꾸는 등의 변경이 있었다. 하지만 리눅스에서는 스레드용 pcb를 관리할 수 있는 코드를 따로 추가하는것보다 기존의 커널의 변화를 최소하하는 방향으로 전략을 바꿨다. 기존의 프로세스를 '자원을 공유할 수 있는 프로세스'의 light weight process의 개념으로 바꿨고, 스레드는 그저 다른 자원을 일부분 공유하는 프로세스의 개념으로 접근한 것이다. 결론적으로 리눅스에서는 스레드와 프로세스의 경계를 두지 않으며, 둘다 task라는 이름으로 부른다. 실제로 리눅스 상에서 각각의 프로세스를 추적해보면 TGID, ParentID, PID가 부여되며, 여기서 TGID가 동일하면 동일한 스레드 그룹을 의미한다. 리눅스에서 light weight process의 개념이 자리잡으면서 프로세스를 새로 생성하는 c wrapper function인 clone 함수에서 공유할 수 있는 자원을 정의할 수 있도록 변경되었다. clone 함수의 경우 커널 레벨로 들어가게 되면 커널 코드에서 do_fork()라는 함수를 통해 프로세스를 생성하게 되어 있다. 기존의 copy-on-write로 프로세스를 생성하는 fork, 부모 프로세스의 메모리 자원을 공유하도록 프로세스를 생성하는 vfork의 시스템 콜 경우 clone의 설정을 통해서 동일한 방식으로 프로세스를 생성할 수 있었기 때문에 커널 코드를 변화시킬 부분이 줄어 들었다.
일반적으로 프로세스가 생성될적에 커널영역에 스택 영역을 할당 받고, pcb가 생성되어 관리된다. 이러한 프로세스는 유저 영역과 커널 영역을 모드 스위칭을 통해서 왔다갔다 하면서 유저 영역의 로직과 context switching과 같은 커널 영역의 로직을 수행하게 된다. 이러한 프로세스 이외에도 커널 자체적으로 디스크 비우기, 페이지 프레임의 교체와 같은 특정한 일을 수행하기 위한 kernel thread가 존재한다. 이러한 kernel thread 또한 다른 프로세스와 마찬가지로 light weight process로 생성이 되며, 오직 커널 모드에서만 돌아가게 되며, 다른 kernel thread와 커널 영역을 공유하게 된다. 이러한 kernel thread에는 대표적으로 process 0으로 호출되는 swapper process가 존재한다. swapper process 같은 경우 모든 process의 조상 process가 되며, 인터럽트를 수행할 수 있게 설정해주며, 커널코드상에서 필요한 모든 자료구조를 초기화 시켜주며, 만약 cpu가 여러개인 경우 cpu마다 swapper process가 존재하게 되며, TASK_RUNNING으로 존재하는 프로세스가 없을때 스케줄러에 의해 할당된다. swapper process가 처음에 불려서 초기화같은 과정을 끝내게 되면 그다음 process로 init process를 콜하게 된다. process 1인 init process에서는 커널의 초기화가 진행 되며, 다른 kernel thread들이 메모리 캐시와 swapping 관련 역활을 할 수 있도록 초기화시켜준다. init process는 다른 kernel thread들을 생성하고 관리해주기 때문에 절대로 종료되지 않는다.
리눅스에서 프로세스가 종료될때를 한번 봐보자. 프로세스가 종료되면 일단 부모 프로세스에 대한 관계를 다시 설정하게 되며 자식 프로세스들 같은 경우 init process의 자식 프로세스가 된다. 리눅스에서는 프로세스가 종료된 직후에 바로 프로세스와 관련된 자료들을 지우지 않는데(task_zombie state로 존재), 이러한 프로세스의 경우 부모 프로세스에서 wait()와 같은 시스템 콜이 호출될 적에 커널 영역 스택과 pcb를 지우게 되면서 프로세스에 대한 정보가 사라진다. init process에서 주기적으로 자신의 자식 프로세스들에게 wait()콜을 날리면서 해당 프로세스들이 삭제 된다. 이러한 좀비 프로세스를 통해서 종료시키는 이유 중 하나로는 부모 프로세스에서 자식 프로세스가 어떠한 상태로 종료를 했는지 알 수 있도록 하기 위해서라고 한다.
