그리디 알고리즘(탐욕법) The Greedy Approach
당장 눈 앞에 보이는 최적의 상황만을 쫓는 알고리즘 (ex. 단순하게 큰 경우만 쫓음)
항상 최적의 결과를 도출하는 것은 아니지만 어느 정도 최적의 해에 근사한 값을 빠르게 구할 수 있다.
- 프림 알고리즘
- 크루스칼 알고리즘
- 다익스트라 알고리즘
- 허프만 알고리즘
최소비용 신장트리(MST) 문제 - 프림/크루스칼 알고리즘
: 모든 신장트리 T중 가중치의 합이 최소가 되는 신장트리. Minimum cost Spanning Tree
주어진 그래프 G는 모든 정점이 연결된 가중치가 있는 무방향 그래프 (G = (V, E) : connected, weighted, and undirected)
그래프 G의 모든 정점을 연결하는 트리 : 간선의 개수는 n - 1
-
Brute-Force로 단순무식하게 풀이할 수도 있다.
-> 모든 신장트리를 찾고 가중치의 합이 가장 작은 것 선택; 간선이 n-1개인 트리가 되게끔 선을 하나씩 제거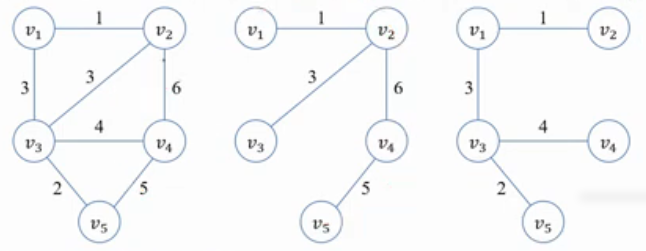 => O(n!)에 가까운 시간복잡도가 나온다
=> O(n!)에 가까운 시간복잡도가 나온다 -
그리디 알고리즘
- 답의 집합(F)을 공집합으로 초기화
- 최적의 원소 하나를 선택하여 답 집합에 포함
-> 최적을 선택하는 방법은 프림 vs 크루스칼 - 딥 집합을 검사하여 집합의 원소가 n-1개가 되면 종료, 아니라면 2단계 반복
-
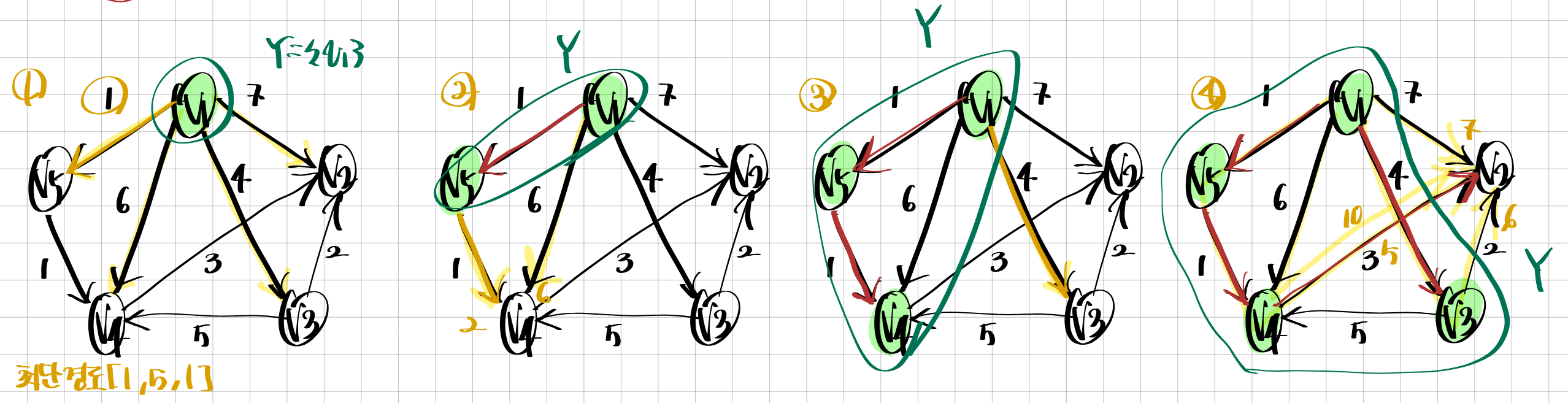
프림 알고리즘 Prim's Algorithm
1. 답 집합을 공집합으로 초기화. 점 하나를 선택해 Y = {v1}:Y는 정점 집합 V의 부분집합으로 설정.
2. V - Y 집합에서 Y집합에서(v1노드 하나가 아님) 가장 가까운 점 vnear를 선택하여 Y에 추가. 답집합에 (nearest(vnear), vnear) 추가
3. Y = V : Y집합이 V집합의 모든 원소를 포함하면 종료, 아니라면 2단계 반복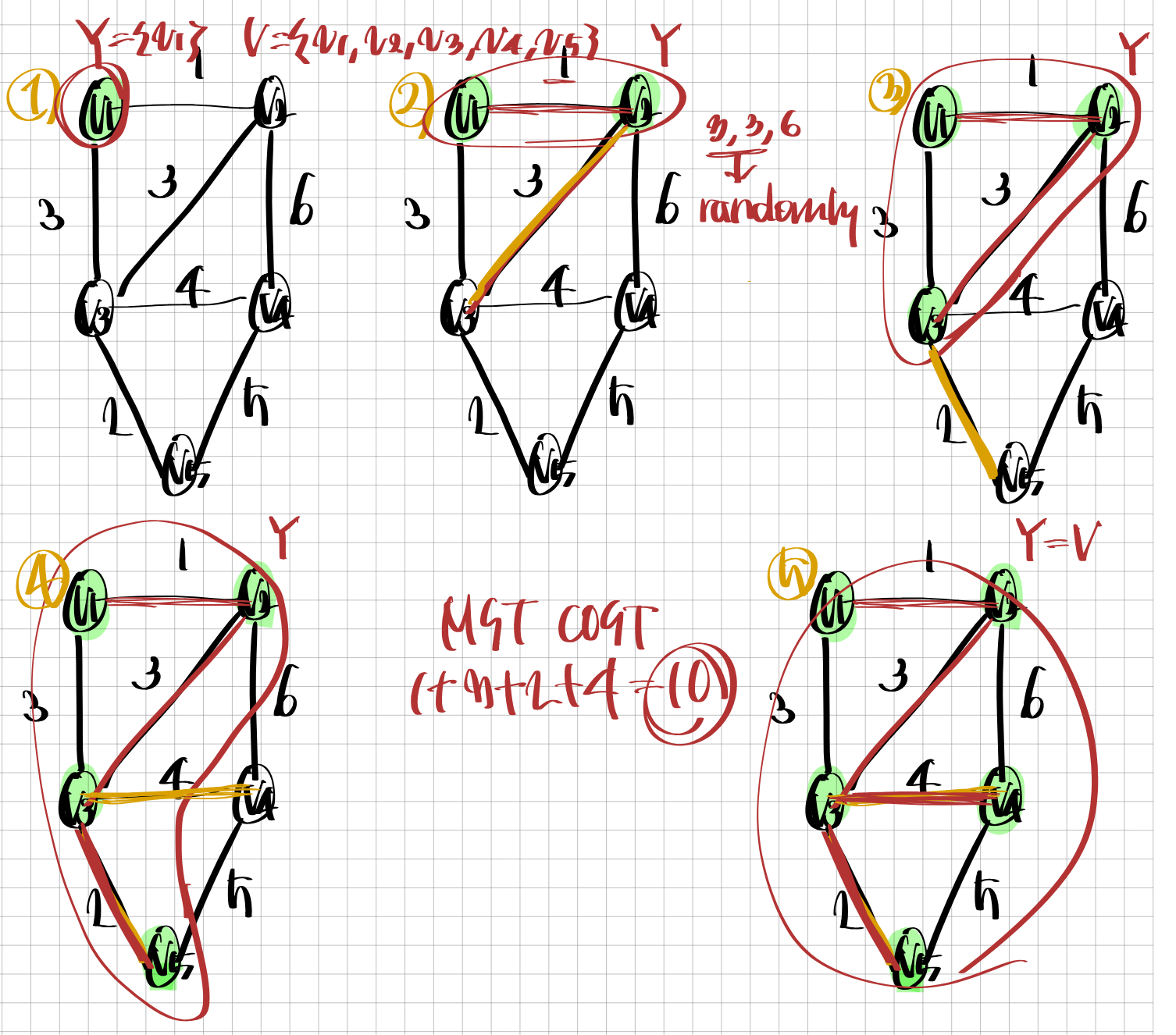
프림 알고리즘 구현
def prim(W): n = len(W) - 1 F = [] nearest = [-1] * (n + 1) distance = [-1] * (n + 1) for i in range(2, n + 1): nearest[i] = 1 distance[i] = W[1][i] print_nd(F, nearest, distance) for _ in range(n - 1): minVal = INF for i in range(2, n + 1): if 0 <= distance[i] and distance[i] < minVal: minVal = distance[i] vnear = i edge = (nearest[vnear], vnear, W[nearest[vnear]][vnear]) F.append(edge) distance[vnear] = -1 for i in range(2, n + 1): if distance[i] > W[i][vnear]: distance[i] = W[i][vnear] nearest[i] = vnear print_nd(F, nearest, distance) return F def cost(F, W): total = 0 for e in F: total += e[2] #weight값 return total def print_nd(F, nearest, distance): print('F =', end = ' ') print(F) print('nearest =', end = ' ') print(nearest) print('distance =', end = ' ') print(distance) INF = 999 W = [ [-1. -1, -1, -1, -1], [-1, 0, 1, 3, INF, INF], [-1, 1, 0, 3, 6, INF], [-1, 3, 3, 0, 4, 2], [-1, INF, 6, 4, 0, 5], [-1, INF, INF, 2, 5, 0] ] F = prim(W) for i in range(len(F)): print(F[i]) print('cost = ', cost(F, W))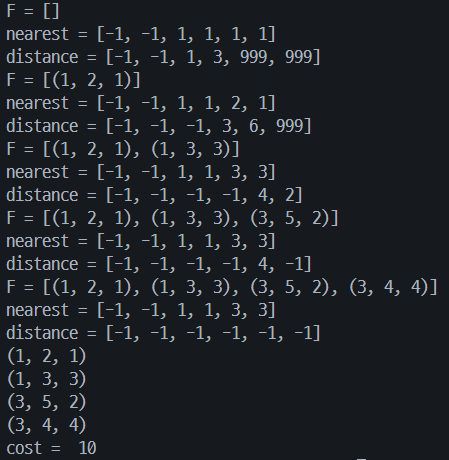
-
크루스칼 알고리즘 Kruskal's Algorithm
1. 답집합(F)을 공집합으로 초기화, V의 서로소 집합을 생성, E를 가중치의 비내림차순으로 정렬
2. 정렬된 E집합에서 간선 e=(i,j)선택. i,j가 속한 집합 p,q를 찾아 p,q가 같은 집합이라면 e버림, 다른 집합이라면 F에 e포함 후 p,q를 합침
3. |F| = n-1이면 종료, 아니면 2단계 반복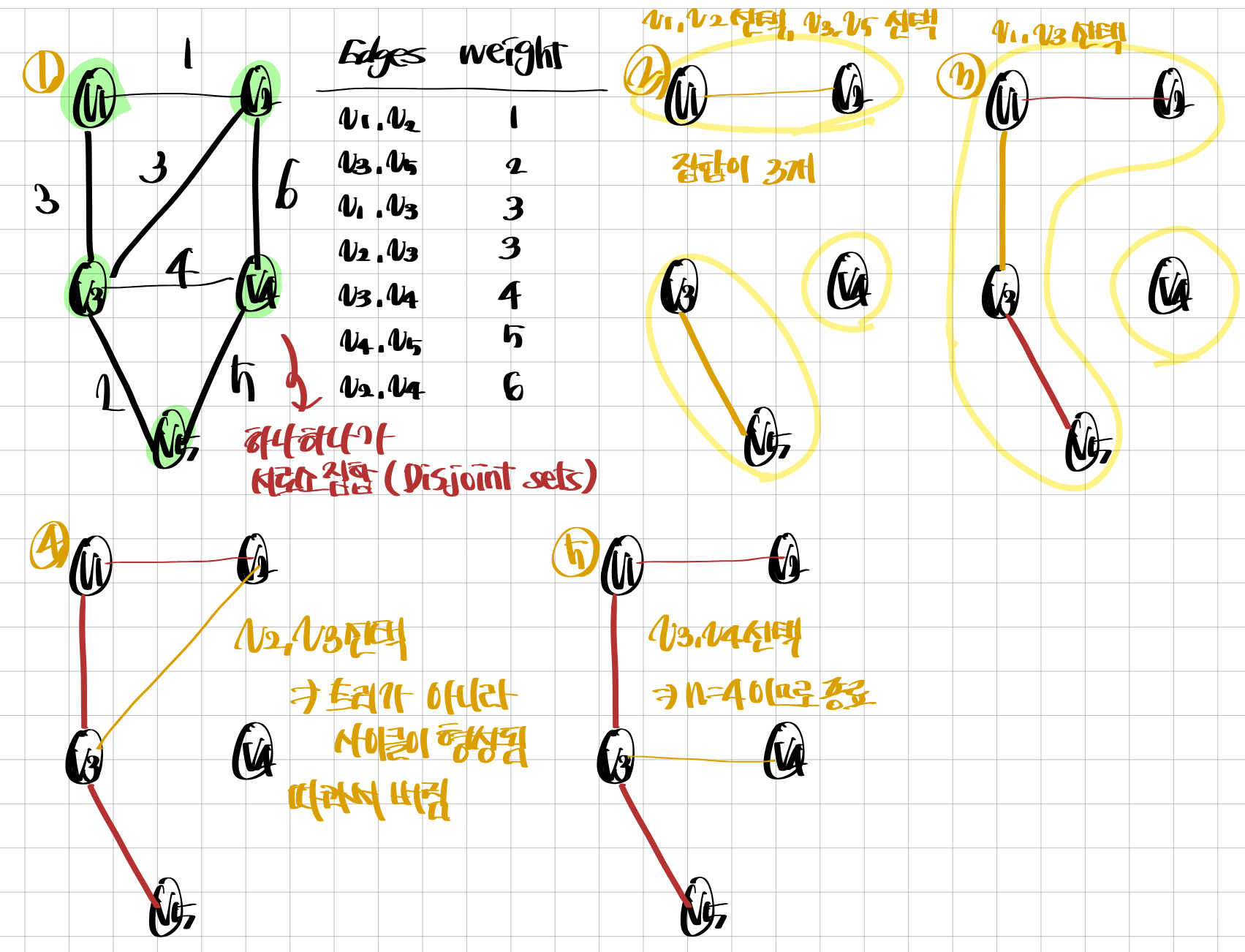
비내림차순, 비오름차순, 내림차순, 오름차순
오름차순ascending : 1 2 3 4 5
내림차순descending : 5 4 3 2 1
비오름차순non-increasing : 5 5 4 3 3 2 1 (중복이 있을 수 있음)
비내림차순non-descending : 1 2 3 3 4 5 5 (중복이 있을 수 있음)사이클 탐지를 위한 Union-Find 알고리즘 사용
-> 서로소 집합 자료구조를 이용해 두 개의 원소가 같은 집합에 속하는지 판단크루스칼 알고리즘 구현
class DisjointSet: #Union-Find 알고리즘 def __init__(self, n): self.U = [] for i in range(n): self.U.append(i) def find(self, i): j = i while self.U[j] != j: j = self.U[j] return j def union(self, p, q): if p < q: self.U[q] = p else: self.U[p] = q def equal(self, p, q): if p == q: return True else: return False def cost(F): total = 0 for e in F: total += e[2] return total def kruskal(n, E): #E가 sort되어있다고 가정 F = [] dset = DisjointSet(n) while len(F) < n - 1: edge = E.pop(0) #제일 앞 원소 꺼냄 i, j = edge[0], edge[1] p = dset.find(i) q = dset.find(j) if not dset.equal(p, q): F.append(edge) dset.union(p, q) print("accepted edge: ", edge) print(dset.U) else: print("discarded edge: ", edge) return F INF = 999 n = 5 E = [ [0, 1, 1], #i, j, w [2, 4, 2], [0, 2, 3], [1, 2, 3], [2, 3, 4], [3, 4, 5], [1, 3, 6] ] F = kruskal(n, E) for i in range(len(F)): print(F[i]) print("cost :", cost(F))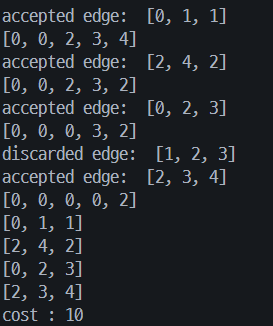
최단 경로 문제 - 다익스트라(Dijkstra's) 알고리즘
모든 정점의 쌍에 대한 최단 경로 구하기 - 플로이드 알고리즘 : 동적 계획법
단일 정점에서 모든 다른 정점으로의 최단 경로 구하기 - 다익스트라 알고리즘 : 탐욕법
- Y = {v1}, 답집합은 공집합으로 초기화
- Y에 속한 정점만 중간에 거쳐가는 정점으로 하여 v1에서 최단경로를 가진 정점 v를 V - Y에서 선택. 새로운 정점 v를 Y에 추가, 최단경로에서 v로 가는 간선을 F에 추가.
- Y == V이면 종료, 아니라면 2과정 반복
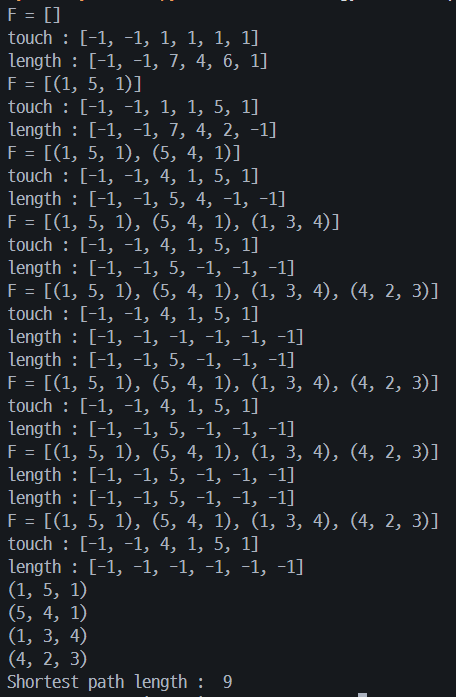
다익스트라 알고리즘 구현
def dijkstra(W): n = len(W) - 1 F = [] touch = [-1] * (n + 1) length = [-1] * (n + 1) for i in range(2, n + 1): touch[i] = 1 #v1에서 출발 length[i] = W[1][i] print_t1(F, touch, length) for _ in range(n - 1): minVal = INF for i in range(2, n + 1): if 0 <= length[i] and length[i] < minVal: minVal = length[i] vnear = i edge = (touch[vnear], vnear, W[touch[vnear]][vnear]) F.append(edge) for i in range(2, n + 1): if length[i] > length[vnear] + W[vnear][i]: length[i] = length[vnear] + W[vnear][i] touch[i] = vnear length[vnear] = -1 print_t1(F, touch, length) return F def length(F): total = 0 for e in F: total += e[2] return total def print_t1(F, touch, length): print("F = ", end = '') print(F) print("touch : ", end = '') print(touch) print("length : ", end = '') print(length) INF = 999 W = [ [-1, -1, -1, -1, -1, -1], [-1, 0, 7, 4, 6, 1], [-1, INF, 0, INF, INF, INF], [-1, INF, 2, 0, 5, INF], [-1, INF, 3, INF, 0, INF], [-1, INF, INF, INF, 1, 0] ] F = dijkstra(W) for i in range(len(F)): print(F[i]) print("Shortest path length : ", length(F))
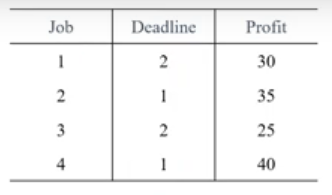
마감시간이 있는 스케줄 짜기 문제
마감시간과 함께 여러 작업이 주어지고 각 작업을 마감시간 전에 마치면 받을 수 있는 보상이 정해져있음. 주어진 마감시간 내에 얻을 수 있는 보상을 최대화 하는 스케줄
- 각 작업을 끝내는데 1의 단위 시간이 걸림
- 보상은 마감시간 이전이나 마감시간에 끝내는 경우에만 주어짐
- 마감시간 이후의 스케줄에 대해서는 고려할 필요 없음
solution
1. 보상에 따라 비오름차순으로 작업 정렬
2. 각 작업을 순서대로 하나씩 가능한 스케줄에 포함
3. 더 이상 남은 작업이 없다면 종료
적절함feasibility 정의
- 어떤 순서sequence는 그 순서 내의 모든 작업이 데드라인 이전에 시작될 때
-> [4, 1] o, [1, 4] x- 어떤 집합set은 그 집합의 원소들로 하나 이상의 적절한 순서를 만들 수 있을 때
-> {1, 4} o, {2, 4} x
def schedule(deadline):
n = len(deadline) - 1
J = [1]
for i in range(2, n + 1):
K = insert(J, i, deadline) #J에 i 삽입
print("K : ", K, end=" ")
if feasible(K, deadline):
print("feasible")
J = K[:] #deep copy. J = K를 하면 J와 K가 같은 주소 참조 ?
else:
print("not feasible")
print("\tJ : ", J)
return J
def feasible(K, deadline):
for i in range(1, len(K) + 1):
if i > deadline[K[i - 1]]:
return False
return True
def insert(J, i, deadline):
K = J[:]
for j in range(len(J), 0, -1):
if deadline[i] > deadline[K[j - 1]]: # >= 수정함
j += 1 #이부분 확인 필요
break
K.insert(j - 1, i)
return K
deadline = [0, 3, 1, 1, 3, 1, 3, 2] #0은 없다고 생각(무시)
profit = [0, 40, 35, 30, 25, 20, 15, 10]
# K = [2, 1] # 함수 테스트용
# print(K, feasible(K, deadline))
# J = [2, 1, 4]
# K = insert(J,74, deadline)
# print(K)
J = schedule(deadline)
print("Schedule : ", J)
maxprofit = 0
for job in J:
maxprofit += profit[job]
print("Max Profit : ", maxprofit)
💡 교재에서 그리디 알고리즘의 영어 표기가 Greedy Algorithm이 아닌 Approach라고 표기되어 있어 생각해보았다.
- Algorithm은 특정한 문제를 풀기 위해 정해진 구체적 절차, Approach는 접근법이다.
-> 탐욕법은 문제마다 "무엇이 탐욕적인가"에 대한 기준이 매번 바뀌므로 상황에 따라 기준을 새로 정의해 접근해야한다. 문제에 대한 아이디어인 Approach를 사용하는 것이 아닐까 한다.
