
1. 메소드?
1.1 메소드란?
메소드(Method)란 아래 그림과 같이 특정 작업을 수행하는 일련의 동작을 묶은 것이다.
메소드는 어떤 특정한 작업/기능 등을 수행하기 위해 묶은 문장으로, 우리는 지금까지 알게 모르게 많은 메소드를 사용해왔다.
콘솔에 출력하기 위해 System.out.println(), 배열 등을 문자열로 바꾸기 위해 .toString(), 정수값 입력을 받기 위해 .nextInt()등 특정한 기능을 동작시키기 위해 적었던 것들이 바로 메소드 이다.
이러한 메소드를 사용하는 이유는 높은 재사용성, 코드의 중복 제거, 프로그램의 구조화 라는 장점이 있기 때문이다.
-
재사용성
재사용성이란 작성했던 코드를 다른 프로젝트에서도 사용하는 것이다.
만약 A라는 프로그램을 개발하면서 데이터의 평균과 표준편차를 계산하는 코드를 작성했다고 가정하자. 시간이 지나 추후에 B라는 프로그램을 개발하면서 데이터의 평균과 표준편차를 계산하는 기능이 필요하다고 가정한다면 재사용성이란 예전에 작성했던 A라는 프로그램에서 사용됬던 평균, 표준편차를 구하는 코드를 그대로 B프로그램에 사용할 수 있음을 말한다. 이렇게 재사용성이 높은 코드를 작성하면 새로 코드를 작성하면서 소요되는 시간을 줄이면서 개발 기간을 단축시킬 수 있다. -
중복제거
프로그램을 개발하다 보면 비슷한 동작을 하는 부분이 상당히 많다. 이를 메소드를 사용하지 않고 작성하다보면 코드가 불필요하게 길어지면서 가독성이 낮아지고, 개발 복잡도가 상당히 올라가게 된다. -
프로그램 구조화
프로그램을 개발하면서 이 프로그램은 어떤식으로 구성되 있고, 어떻게 동작하는등의 프로그램의 구조가 있다. 프로그램의 구조화란 이러한 프로그램의 구조를 고려해 개발을 하는 것을 의미한다.
예를들어, 간단한 쇼핑몰을 예를 들어보자.
쇼핑몰에는 먼저, 회원가입과 로그인등의 회원관리 기능과, 결제기능이 있을 것이다. 이를 코딩할때는 메소드와 클래스, 파일들을 적절하게 분리해서 코드의 구조를 한 눈에 알아볼 수 있도록 작성하는 것이 바로 프로그램의 구조화다.
1.2 메소드와 메모리구조
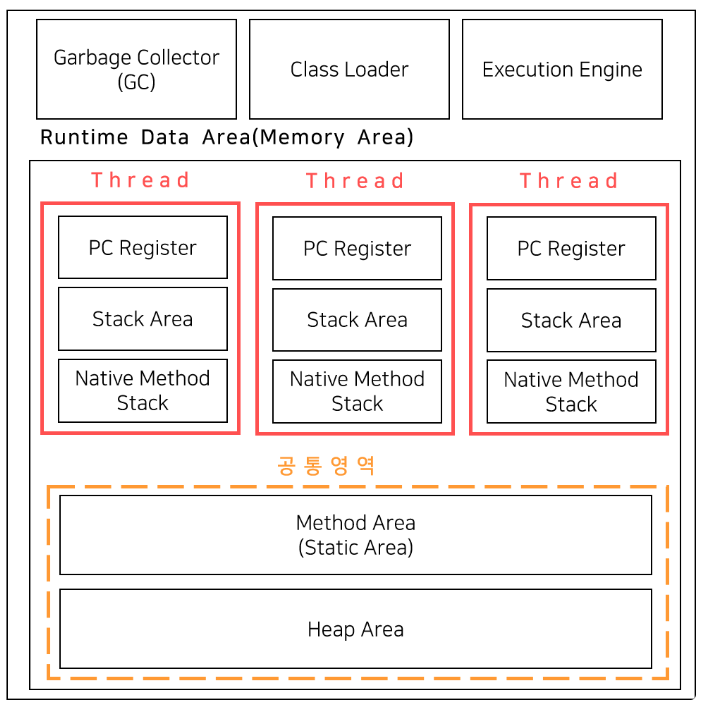
JVM에서 Method area(Static Area)는 인스턴스 생성을 위한 객체 구조, 생성자, 필드 등이 저장된다. 쉽게 말해서 메소드와 클래스의 내용이 들어있다고 생각하면 된다. 이때, JVM당 하나만 생성이 되며, Class Loader가 해당 클래스와 메소드를 load하면 Method Area에 해당 클래스와 메소드의 내용이 저장이 되며, JVM당 하나만 생성이 되기 때문에 모든 스레드들이 이 Method Area를 공유하는 구조이다.
Reference:
https://tecoble.techcourse.co.kr/post/2021-08-09-jvm-memory/
https://kotlinworld.com/3
2. 메소드의 정의 및 선언
2.1 메소드의 정의
메소드의 정의:
반환타입 메소드이름(parameter){
...// 코드
}
우리가 메소드를 사용하기 전에는 반드시 메소드를 정의해야 한다.
예를들어 1부터 10까지 더하는 메소드를 사용하고 싶다면 1부터 10까지 더하는 메소드 이름과 인자값, 반환값을 정의하고, 그 메소드의 기능을 직접 구현해야 한다.
물론, java를 설치하면서 기본적으로 주어지는 메소드들(System.out.println();, object.toString()등 이전까지 자주 사용했던 메소드들)은 java를 설치하면 기본적으로 정의가 되 있기 때문에 추가적으로 정의할 필요가 없으나, 기본적으로 정의되 있지 않은 메소드를 사용하고 싶을 경우에는 직접 메소드를 정의해야 한다.
또한, 메소드를 정의할때는 클래스 내부에 속해있어야 한다.
예를들어
public class Method {
public static void main(String[] args) {
int sum;
System.out.println("methodTest:");
sum=addTo10();
System.out.println(sum);
}
}// 클래스 끝
public int addTo10(){// 클래스 밖에 메소드가 있다.
int i, sum=0;
for(i=0; i<=10; i++)
{
sum+=i;
}
return sum;
}위와 같은 코드는 메소드가 클래스 내부에 없으므로, 메소드가 실행되지 않을 뿐 아니라 컴파일 역시 안된다.
이는 자바는 클래스 단위로 동작이 실행되기 때문이다.
자바 컴파일러가 프로그램을 컴파일 한 후에 코드가 실행될때는 class loader에서 해당 코드를 읽어오는데, 이때, 클래스 단위로 읽어와 메모리 할당을 하기 때문에 어느 클래스에도 속하지 않은 경우 실행이 되지 않으며, 이러한 실수를 방지하기 위해 자바 컴파일러에서는 클래스에 속하지 않은 메소드, 변수 등의 사용을 허락하지 않고 있다.
메소드를 올바르게 정의하기 위해서는 다음과 같이 클래스 내부에 선언을 해야 한다.
public class Method {
public static void main(String[] args) {
int sum;
System.out.println("methodTest:");
sum=addTo10();
System.out.println(sum);
}
public int addTo10(){// 메소드가 클래스 내부에 있다.
int i, sum=0;
for(i=0; i<=10; i++)
{
sum+=i;
}
return sum;
}
}// 클래스 끝output
methodTest:
55위 코드를 보면 메소드가 클래스 내부에 았는것을 알 수 있다. 즉, 위 코드와 같이 메소드는 클래스 내부에 있을때 정상적으로 동작함을 알 수 있다.
2.2 메소드의 선언
메소드의 선언:
반환타입 메소드이름(parameter); 형식으로 선언을 한다.
정의된 메소드를 사용하기 위해서는 메소드를 선언해야 하며, 선언은 우리가 익숙하게 사용했던것과 같이 클래스_이름.메소드_이름();형태로 사용한다.
그러나, 앞에서 봤던 코드를 보면 조금 어색한 부분이 있을 것이다.
public class Method {
public static void main(String[] args) {
int sum;
System.out.println("methodTest:");
sum=addTo10();
System.out.println(sum);
}
public int addTo10(){// 메소드가 클래스 내부에 있다.
int i, sum=0;
for(i=0; i<=10; i++)
{
sum+=i;
}
return sum;
}
}// 클래스 끝output
methodTest:
55앞 코드를 다시 보면 메소드를 선언할때 클래스_이름.메소드_이름();형태가 아닌 메소드_이름();형태로 선언이 되 있음을 볼 수 있다.
원래대로라면 클래스_이름.메소드_이름(); 형태가 맞으며, 위의 코드에서는 Method.addTo10();형태로 선언을 하는 것이 정석적인 방법이다.
그러나, 같은 클래스 내에서 메소드를 선언할 경우에는 클래스 이름을 생략하고 메소드_이름();형태로 선언하는 것 역시 가능하다.
3. 반환값 및 인자값
3.1 인자값
인자값이란 메소드에 입력하는 인자(값, 데이터들)를 의미한다.
반환타입 메소드이름(인자값){
...// 코드
}
인자값이란 메소드에 입력하는 데이터 등을 의미한다.
처음 메소드를 표현한 그림을 한번 보도록 하자.
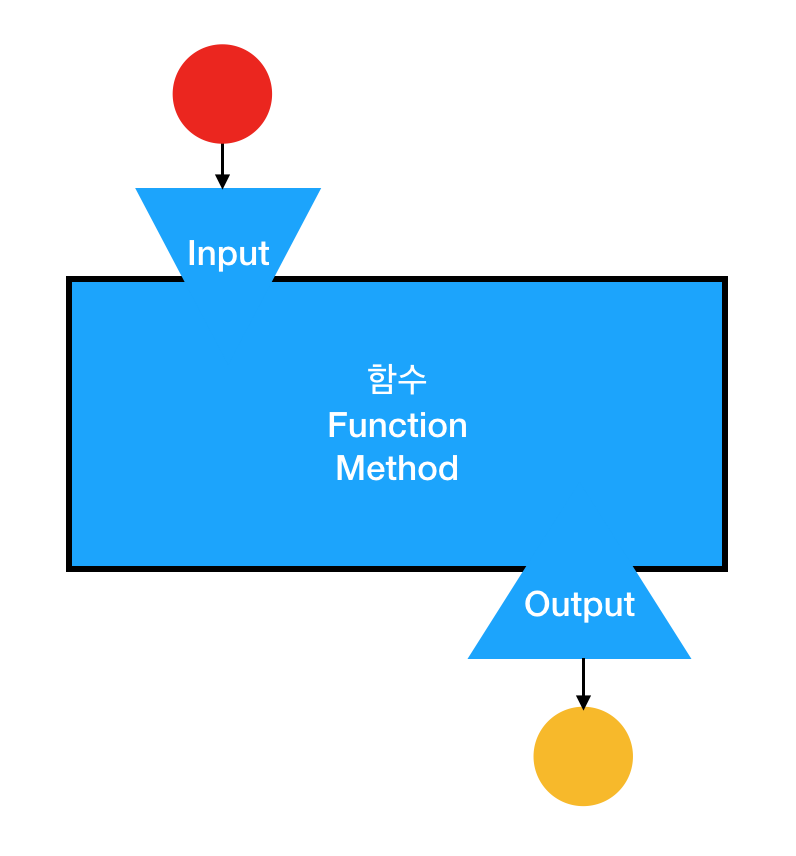
위 그림에서 input이 바로 인자값이다.
물론, 앞에서 코드를 작성한 바와 같이 addTo10();처럼 메소드에는 인자가 없을 수도 있다.
또한, 인자값은 반드시 자료형과 인자값의 이름이 필요하며, 인자값은 여러개를 입력할 수 있다.(method(arg1, arg2, arg3, arg4);와 같이 가능)
인자값 사용을 알아보기 위해 입력받은 인자의 제곱을 출력하는 코드를 작성하면 다음과 같다.
public class Method {
public static void main(String[] args) {
System.out.println("methodTest:");
power(5);// 인자값 5 입력
}
public void power(int x){// 인자값: int x
System.out.println(x +"^2 is "+ x*x);
}
}output
methodTest:
5^2 is 253.2 반환값
반환값이란 메소드가 실행이 끝나고 반환하는 데이터를 의미한다.
반환값은 반환하는 데이터의 자료형을 메소드 선언시 작성해야 하며, 반환시return키워드를 사용해 반환한다.반환타입 메소드이름(인자값){
...// 코드
return 반환값;
}
메소드를 표현한 그림을 다시 한번 보도록 하자.
위 그림에서 output이 바로 반환값이다.
반환값은 메소드가 종료하면서 반환하는 데이터이며, return키워드를 사용해 반환을 한다.
또한, 반환값은 반환하는 값의 자료형이 반드시 필요하며, 이는 메소드를 정의할때 반드시 작성을 해야 한다.
반환값 사용을 알아보기 위해 입력받은 인자의 n제곱(a^n)을 반환하는 코드를 작성하면 다음과 같다.
public class Method {
public static void main(String[] args) {
int a, x;
int result;
a=2;
x=5;
System.out.println("methodTest:");
result=powerbyExp(a, x);
System.out.println(a + "^" + x + " is " + result);
}
public int powerbyExp(int a, int n){// 반환값: int 자료형
int i, pow=1;
for(i=0; i<n; i++) {
pow*=a;
}
return pow;// 반환 및 함수 종료
}
}
output
methodTest:
2^5 is 32앞서 설명한 바와 같이 return을 사용하는 시점에서 메소드가 종료되기 때문에 반환값 이후의 코드는 실행되지 않으며, 반환값 이후에 추가적으로 코드를 작성하면 컴파일 오류를 발생시킨다.
public class Method {
public static void main(String[] args) {
int a, x;
int result;
a=2;
x=5;
System.out.println("methodTest:");
result=powerbyExp(a, x);
System.out.println(a + "^" + x + " is " + result);
}
public int powerbyExp(int a, int n){
int i, pow=1;
for(i=0; i<n; i++) {
result*=a;
}
return pow;// 메소드 종료
System.out.println("return이후 코드...");// 메소드 종료후 코드(컴파일 오류 발생!)
return result;// 메소드 종료후 코드(컴파일 오류 발생!)
}
}또한, 반환값은 인자값과 다르게 오직 하나의 데이터만 반환할 수 있다.
즉, return a, b;와 같이 다중반환은 허용하지 않는다.
4. 오버로딩(Overloading)
4.1 오버로딩(Overloading)이란
오버로딩이란 같은 이름의 메소드를 인자값 혹은 반환값을 다르게 해서 여러번 정의하는 것을 의미한다.
오버로딩이란 같은 이름의 메소드의 인자값을 다르게 해서 정의하는 것을 의미한다.
예를 들어 우리가 계산기 프로그램을 개발한다 가정하자.
계산기 프로그램을 만들때 두 수의 합을 구하는 기능을 만들때, int형 값의 두 수를 더하는 경우와 int형 , double형 값의 두 수를 더하는 경우, 마지막으로 double형 값의 두 수를 더하는 경우가 있을 것이다.
이때, 이를 각각 addTwoInt(), addIntDouble(), addTwoDouble()와 같이 메소드를 각각 만들 수 있으나, 결국에는 두 수를 더한다는 동일한 기능을 하는 메소드를 여러개 정의하는 것이기 때문에 코드의 가독성이 안좋아진다. 이때, 만약 add()라는 메소드 하나로 통일할 수 있다면 상당히 코드의 가독성과 사용성이 좋아지며, 이를 가능하게 하는 것이 바로 오버로딩(Overloading)이다.
4.2 오버로딩 사용법
메소드의 오버로딩은 별도의 키워드 없이 같은 클래스 내에서 메소드를 다시 정의하면 된다.
앞서 언급했던 계산기의 덧셈부분을 오버로딩을 통해 구현하면 다음과 같다..
public class Method {
public static void main(String[] args) {
int result1;
double result2, result3;
result1=add(2, 3);
result2=add(2, 3.7);
result3=add(2.5, 4.1);
System.out.println("add two int: "+result1);
System.out.println("int int and double: "+result2);
System.out.println("int two double: "+result3);
}
public int add(int a, int b){// 두 int형 더하기
return a+b;
}
public double add(int a, double b){// int형, double형 더하기(overloading)
return a+b;
}
public double add(double a, double b){// 두 double형 더하기(overloading)
return a+b;
}
}output
add two int: 5
int int and double: 5.7
int two double: 6.6또한, 오버로딩의 경우 인자값이 다르면 사용이 가능하기 때문에 다음과 같은 경우 역시 사용이 가능하다.
public class Method {
public static void main(String[] args) {
int result1, result2;
result1=add(2, 3);
result2=add(2, 3, 5);
System.out.println("add two int: "+result1);
System.out.println("add three int: "+result2);
}
public int add(int a, int b){// 두 int형 더하기
return a+b;
}
public int add(int a, int b, int c){// 3개의 int형 더하기(overloading)
return a+b+c;
}
}output
add two int: 5
add three int: 10이와같이 오버로딩은 이름은 같으나, 반환형이 다르거나 입력하는 인자값의 갯수 혹은 인자값의 자료형이 다를때 사용이 가능하다.
즉, 아래와 같은 경우 오버로딩은 불가능하다.
public int add(int a, int b){
return a+b;
}
public int add(int c, int d){// 오버라이딩 불가(인자값의 타입과 갯수가 같음.)
return c+d;
}5. 변수의 범위
5.1 지역변수(Local variable)
지역변수란 메소드나 생성자, 초기화 블록 내에 위치한 변수이다.
지역변수는 메소드나 생성자, 초기화 블록 내에 위치한 변수로, 쉽게 말해서 중괄호 내부에 있는 변수를 의미한다. 즉, java에서 우리가 생성한 변수는 모두 지역변수이다.
5.2 지역변수의 범위
지역변수의 범위는 지역변수가 속한 블록(중괄호 안)이다.
코드를 작성하면서 직접 알아보도록 하자.
public class Method {
public static void main(String[] args) {
int data1=10;
System.out.println("data2: "+data2);// data2 출력
printData1();// data1 출력 함수
}
public void printData1() {
int data2=100;
System.out.println("data1: "+data1);
}
}이 코드는 동작하는가?
아마 동작하지 않을 것이다.
그렇다면 이 코드의 동작결과는 어떻게 되는가?
public class Method {
public static void main(String[] args) {
int data=10;
System.out.println("data: "+data);// data 출력
updateData();// data 수정 함수
System.out.println("updated data: "+data);// data 출력
}
public void updateData() {
int data=200;
}
}output
data: 10
updated data: 10놀랍게도 업데이트된 데이터가 200이 아니라 10이 됬다.
이러한 이유는 지역변수는 지역변수가 선언되 있는 블록까지 유효하기 때문이다. 또한, 지역변수의 블록은 중괄호로 구분한다.
위의 코드를 블록별로 나누면 다음과 같다.
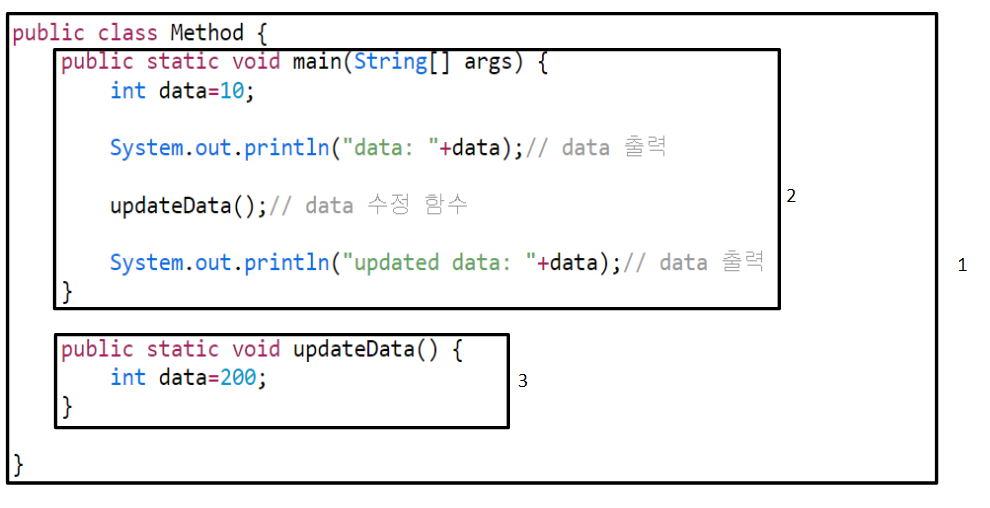
또한, 위 그림을 보면 알 수 있듯이 2번 블록과 3번 블록에 변수data가 선언되 있음을 볼 수 있다.
또한, 1번블록은 2번블록과 3번블록을 포함하고 있으나, 변수가 있는 2번블록과 3번블록은 다른 블록들을 포함하고 있지 않음 역시 알 수 있다. 즉, data변수는 각각 다른 블록에 속하고, 포함관계 역시 아니기 때문에 updateData();가 있는 3번블록에서 변경한 data가 2번블록의 data에 영향을 미치지 않는 것이다.
정확히 말하면 2번블록에 있는 data와 3번 블록에 있는 data는 이름만 같을 뿐, 동명이인과 같이 전혀 다른 변수이기에 서로 영향을 주지 않은 것이다.
또 다른 예를 보도록 하자.
public class Method {
public static void main(String[] args) {
int i=10;
{
i=20;
{
i=30;
int j=100;
{
System.out.println("j1: "+j);
i=40;
}
}
}
System.out.println("i: "+i);
System.out.println("j2: "+j);
}
}위의 코드를 블록별로 나누면 다음과 같다.
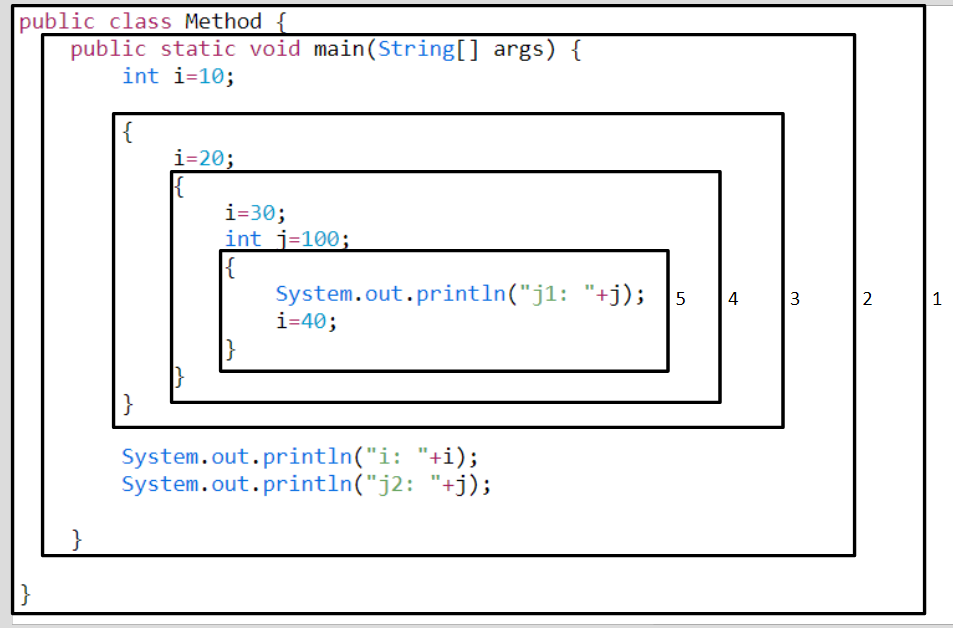
위 코드의 블록의 상관관계는 다음과 같다.
-
1번블록
2, 3, 4, 5번 블록 포함 -
2번블록
3, 4, 5번 블록 포함 -
3번블록
4, 5번 블록 포함 -
4번블록
5번 블록 포함 -
5번블록
다른 블록 포함x
이를 기반으로 코드를 분석하면 다음과 같다.
2번 블록에 있는 변수 i는 3번, 4번 5번 블록에 있는 i변수를 변경하는 부분에 영향을 미치게 되면서 i값이 10(초기값)->20(3번블록)->30(4번블록)->40(5번블록)이 되면서 최종적으로 i=40이 되면서 출력값은 40이 된다.
또한 j의 경우 4번 블록에서 선언 및 초기화가 됬으나, 2번블록에서 출력을 하려고 하면서 컴파일 오류를 일으킨다. 이는 변수j는 4번 블록(4번블록, 5번블록)에서만 유효하기 때문에 2번블록에서는 변수 j가 선언이 되지 않은것이나 마찬가지이기 때문이다.
6. 실습
Q1.
다음 코드가 동작하지 않는 이유를 설명하고, 동작할 수 있도록 코드를 수정하시오.
public class Q1 {
public static void main(String[] args) {
for(int i=0; i<5; i++) {
System.out.println("i: "+i);
}
System.out.println("i: "+i);
}
}
A1.
문제의 코드를 블럭으로 나누면 다음과 같다.

-
1번블록
2번, 3번블록 포함 -
2번블록
3번블록 포함 -
3번블록
다른 블록 포함x
이를 기반으로 컴파일 오류를 찾으면 다음과 같다.
변수 i가 선언된 위치는 3번 블록이므로, 2번 블록에서 출력하는 i와는 관련이 없는 변수다. 이대, 2번 블록에 변수 i가 선언이 되 있지 않기 때문에 컴파일 오류가 발생했다.
이를 해결하기 위해서는 아래와 같이 2번블록 혹은 1번블록에 변수 i를 선언하면 문제가 해결된다.
public class Q1 {
public static void main(String[] args) {
int i;
for(i=0; i<5; i++) {
System.out.println("i: "+i);
}
System.out.println("i: "+i);
}
}