
1. StringTokenizer
1.1 StringTokenizer 클래스란?
StringTokenizder 클래스는 문자열을 지정된 구분자(delimiter)를 기준으로 토큰 이라는 여러 문자열로 잘라내는 것을 의미한다.
예를들어 보자.
100, 200, 300, 500, 400과 같은 문자열이 있다 가정하자. 이때, 쉼표 ,를 기준으로 문자열을 분류하려고 할때 StringTokenizer를 사용해 구분할 수 있다.
이때, 쉼표는 구분자, 분류된 100, 200, 300,500, 400은 토큰이 된다.
1.2 StringTokenizer의 사용
StringTokenizer는 아래와 같이 생성하면서 문자열을 입력하는 방식으로 사용한다.
public class Main {
public static void main(String[] args){
String str = "123,456,789,0";
StringTokenizer st = new StringTokenizer(str, ",");// 쉼표를 기준으로 구분
while(st.hasMoreTokens()){// 토큰이 남아있으면
System.out.println(st.nextToken());// 다음 토큰을 반환
}
}
}output
123
456
789
0mini quiz
StringTokenizer를 활용해 다음 문제를 풀면 다음과 같다.
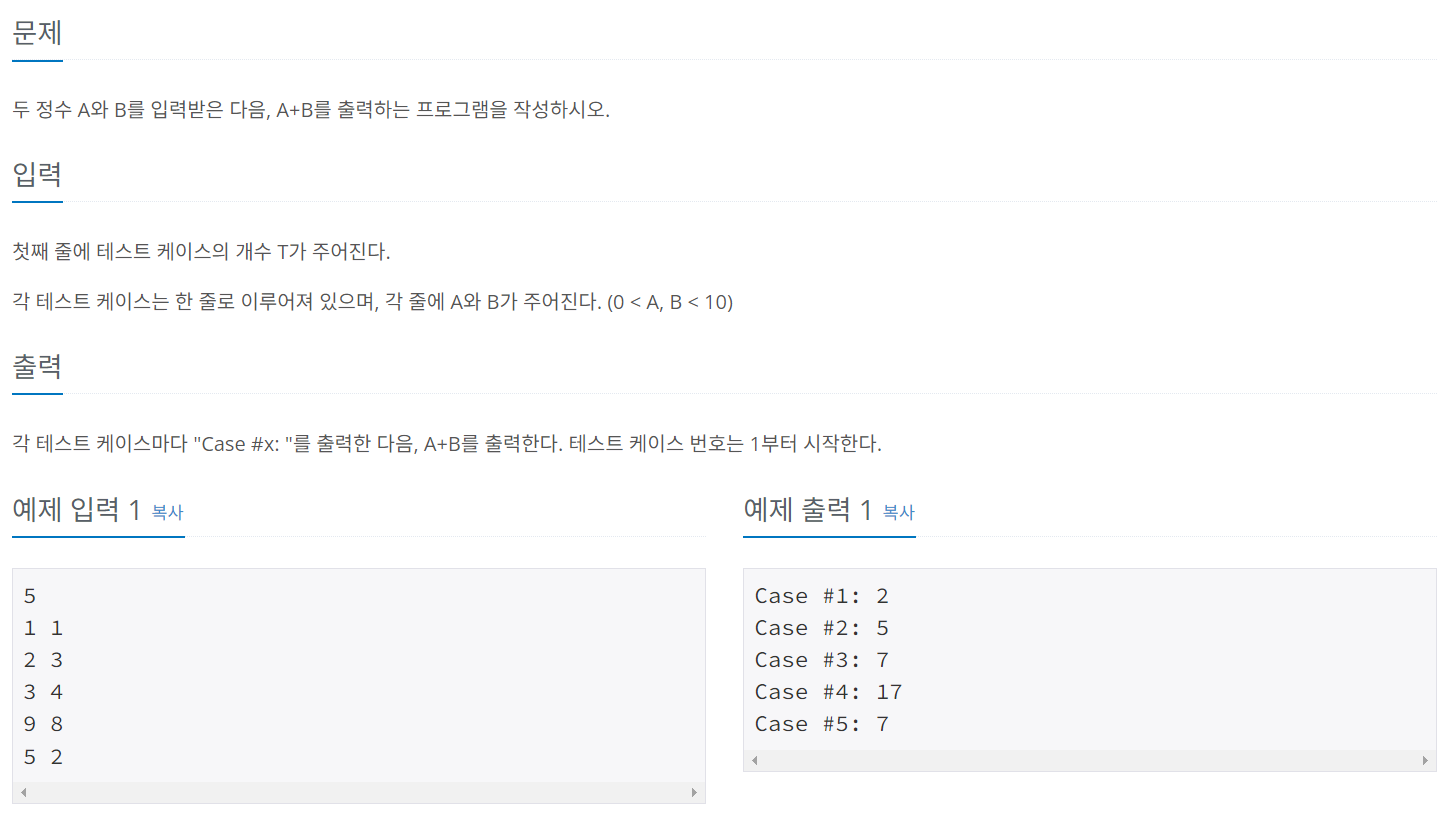
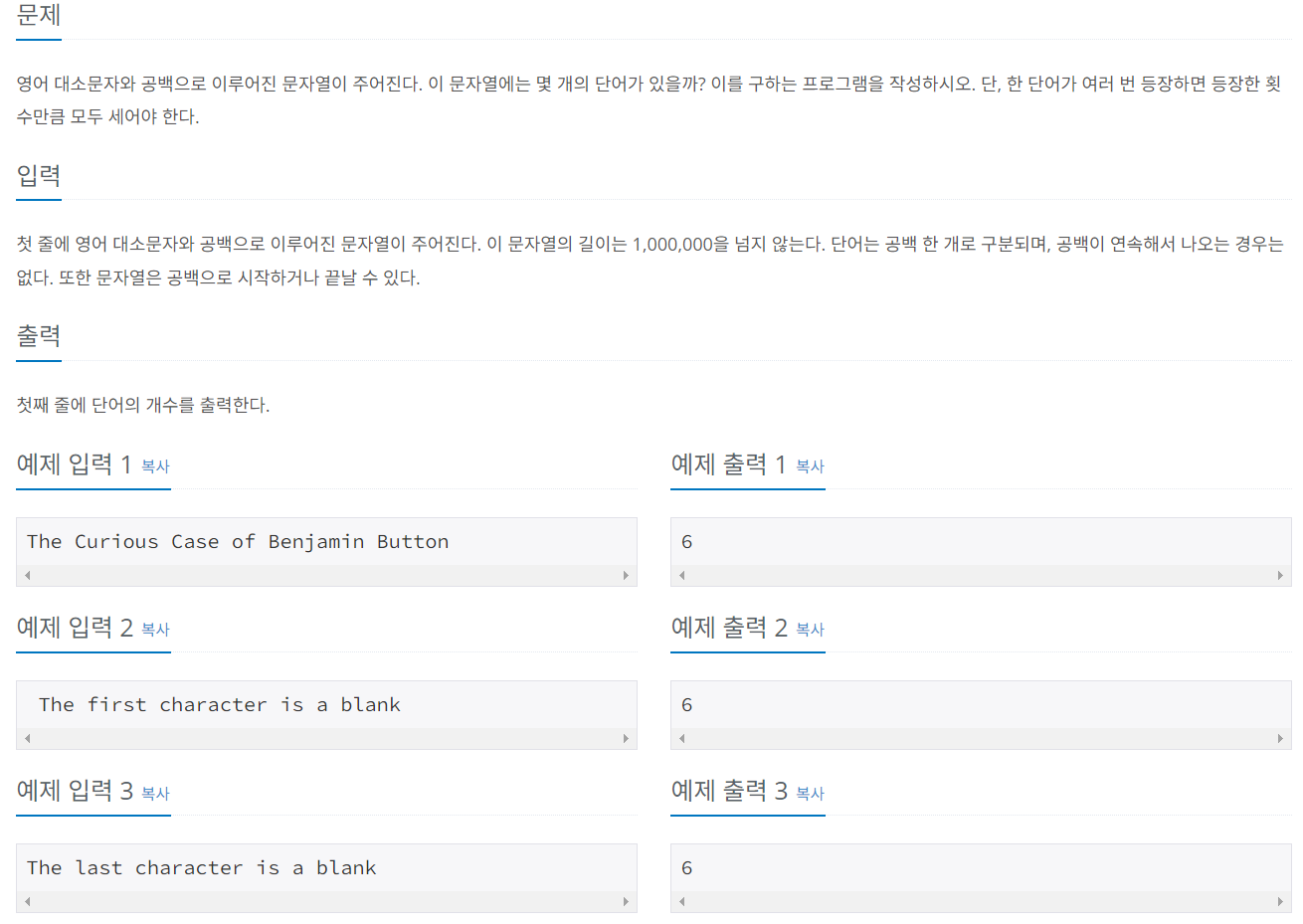
백준 11021
import java.util.*;
public class Main {
public static void main(String[] args){
int T;
String str;// 입력 문자열
int sum;
Scanner sc = new Scanner(System.in);
StringTokenizer st;
T=Integer.parseInt(sc.nextLine());// 테스트 케이스 갯수 입력
for(int i=0; i<T; i++){
str=sc.nextLine();// A, B 입력
st= new StringTokenizer(str, " ");// 공백을 기준으로 분류
sum=0;// A+B 값
while (st.hasMoreTokens()){// 문자열에서 A, B값 분리
sum+=Integer.parseInt(st.nextToken());// 분리된 A와 B 더하기
}
System.out.println("Case #"+(i+1)+": "+sum);// 출력 형식에 맞춰 출력
}
}
}
답:
import java.util.*;
public class Main {
public static void main(String[] args){
String str;
StringTokenizer st;
Scanner sc = new Scanner(System.in);
str = sc.nextLine();// 문자열 입력
st = new StringTokenizer(str, " ");// 문자열을 공백을 기준으로 분리
System.out.println(st.countTokens());// 분리된 문자열(토큰) 수 출력
}
}
ㅈ밥 문제였다. 이딴게 브론즈2?
이와같이 StringTokenizer를 사용할 수 있다.
2. StringTokenizer와 split()
2.1 StringTokenizer와 split() 차이
String클래스에서 사용할 수 있는 .split()메소드 역시 StringTokenizer와 마찬가지로 문자열을 특정한 구분자를 기준으로 분리할 수 있다.
그러나, StringTokenizer 클래스와 split() 메소드는 한가지 큰 차이점이 있다.
바로 split()메소드는 인자값을 정규식으로 준다는 점이다. 즉, split()메소드의 경우 복잡한 구분자를 사용할 경우에도 구분이 가능하다. 반면에 StringTokenizer는 구분자를 문자를 기준으로 한다. 쉽게말해 StringTokenizer에서 구분자를 abc라고 입력했다면 실제로 문자열을 분류할때 구분자는 a, b, c 중에서 하나 이상이 포함된 경우에 분리를 한다.
아래 코드를 보면 더 확실하게 알 수 있다.
import java.util.*;
public class Main {
public static void main(String[] args){
String str="111a222b333c444ab555bc666abc777";
String delimiter = "abc";// abc를 기준으로 구분하려고 함
StringTokenizer st= new StringTokenizer(str, delimiter);
System.out.println("-----------StringTokenizer----------");
while(st.hasMoreTokens()){
System.out.println(st.nextToken());
}
System.out.println("-----------split()----------");
String splitStr[] = str.split(delimiter);
for(String s : splitStr){
System.out.println(s);
}
}
}output
-----------StringTokenizer----------
111
222
333
444
555
666
777
-----------split()----------
111a222b333c444ab555bc666
777위 코드와 결과를 보면 알 수 있듯이 abc를 기준으로 구분하려는 목적으로 구분자를 설정했음에도 불구하고 StringTokenizer의 경우 abc라는 하나의 문자열이 아닌, a, b, c라는 각 문자를 구분자로 인식하고 전체 문자열을 분리한 것을 알 수 있다.
반면에 split()메소드의 경우 abc라는 하나의 문자열을 구분자로 인식하고 문자열을 분리했음을 볼 수 있다.
2.2 StringTokenizer vs split()
지금까지 배운 내용을 정리해보자.
StringTokenizer와 split()은 문자열을 특정 구분자를 기준으로 문자열을 분리한다는 공통점이 있다.
그러나, StringTokenizer의 경우 구분자를 문자열이 아닌 문자들을 이용해 구분을 한다. 즉, StringTokenizer에서 구분자를 abc라고 입력을 해도 실제로는 a, b, c 각각을 구분자로 삼는다는 것이다. 반면에 split()메소드는 정규식을 기반으로 문자열을 분리하기 때문에 구분자를 abc라고 입력하면 문자열 abc를 구분자로 삼게 된다.
또한, StringTokenizer의 경우 클래스이기에 문자열을 분리했을때 분리된 문자열 갯수등 편의기능이 있는 반면 split()메소드의 경우 이러한 기능이 없다.
따라서, 구분자가 하나의 문자들로 이루어진 경우 StringTokenizer를 사용하는 것이 좋으며, 구분자가 문자열이거나 복잡한 경우 split()을 사용하는 것이 좋다.
