[6] Fuzzing: Art, Science, and Engineering 논문 보고서
6 INPUT EVALUATION
input evaluation은 입력값이 생성되면, fuzzer는 그 입력값을 이용해서 PUT를 실행하고 실행 결과를 이용해서 무엇을 할지 결정하는 과정을 말한다.
fuzzing의 매력 중 하나는 PUT을 간편하게 실행하며 테스트할 수 있다는 점이지만 fuzzing의 성능과 효과에 영향을 미치는 input evluation과 관련된 많은 최적화 및 design decision을 고려하지 않을 수 없다. 이번 6장에서는 이러한 고려사항에 대해 자세히 살펴본다.
6.1 Bug Oracles
fuzz testing에서 사용되는 표준 보안 정책은 치명적인 signal(세그먼트화 오류 등)에 의해 종료된 모든 프로그램 실행을 위반(violation)으로 간주한다.
이 정책은 메모리 취약점을 탐지한다. 왜냐하면 메모리 취약점은 데이터 또는 코드 포인터를 잘못된 값으로 덮어서 segmentation fault를 유발하거나 역참조될 때 중단(abort)되기 때문이다.
-
유효하지 않은 값으로 데이터나 코드 포인터를 덮어쓰는 메모리 취약점은 segmentation fault를 유발하거나 참조가 취소될 때 중지되는것을 유발하기에 탐지 가능
instrumentation 없이도 OS가 이러한 예외적인 상황들이 fuzzer에 갇히는 걸(to be trapped) 허락해주기 때문에 이 정책은 효율적이고 구현하기 쉽다.
→ fuzzer가 instrumentation 없이 측정할 수 있다는 것 같음
하지만 crash를 탐지하는 기존의 정책이 트리거된 모든 메모리 취약점을 탐지할 수 있는건 아니다. 예를 들어서, 만약에 stack buffer overflow가 발생해서 스택에 있는 포인터를 valid(유효한) 메모리 주소로 덮어씌웠을 때(그 주소를 가리키거나 접근해도 crash는 안날때), 프로그램은 crash가 발생하는게 아니라 invalid한 결과로 실행될 수 있다. 그러면 이런 경우에는 fuzzeer가 감지할 수가 없다.
- 원래는 잘못된 주소로 덮어씌워지면 문제가 발생하지만 그 메모리 주소로도 실행은 가능한 경우 crash는 일어나지 않아 탐지는 불가능함 (버퍼 오버플로우를 통해 공격 코드를 삽입하고 그 공격 코드 주소로 메모리 주소를 덮어씌워 실행하는 경우 공격이 실행 되는 상황을 생각해보면 이해가 쉬움)
이러한 경우에도 fuzzer가 감지할 수 있도록 하기 위해서, 연구자들은 unsafe 하거나 원하지 않는 동작을 탐지하고 프로그램을 중지할 수 있는 방법들을 제안했고 이를 sanitizers라고 한다.
- Sanitizers : 메모리 취약점이 발생했는데 crash는 나지 않아서 탐지하지 못하는 경우 이를 방지하고 탐지하기 위한 방법
6.1.1 Memory and Type Safety
Memory safety error는 크게 공간적 에러와 시간적 에러 두가지 경우로 나누어진다.
- 공간적 에러
- 포인터가 원래 가리키려고(point to) 했던 객체의 외부를 역참조할때 발생한다. 예를 들어서 buffer overflow랑 underflow는 고전적인 공간적 메모리 에러의 예시이다.
- 역참조 : 주소를 통해 그 값에 접근하는 것을 의미한다. 즉 포인터 변수 ptr이 변수 a의 주소를 가리키고 있다면 포인터 변수 ptr을 이용해 변수 a의 값에 접근하는 것을 의미한다.
- 포인터가 원래 가리키려고(point to) 했던 객체의 외부를 역참조할때 발생한다. 예를 들어서 buffer overflow랑 underflow는 고전적인 공간적 메모리 에러의 예시이다.
- 시간적 에러
- 더이상 유효하지 않은 공간에 포인터를 통해 접근할 때 발생. 예를 들어 포인터를 사용 후에 할당을 해제한 메모리에 다시 접근하는 use-after-free 취약점은 전형적인 시간적 메모리 에러이다.
ASan은 컴파일 때 프로그램을 instrument하는 빠른 메모리 에러 탐지기다. ASan은 시간적/공간적 에러를 둘다 탐지할 수 있으며 속도 저하도 적게 일어나기 때문에 basic crash harness의 매력적인 대안이 될 수 있다.
ASan의 목적 ⇒ instrument를 이용해서 메모리 취약점이 발생했을때 감지하지 못하는 현상을 줄이기 위해
- harness : fuzzing 하려는 함수를 트리거하는 작은 프로그램 https://hackyboiz.github.io/2021/07/04/fabu1ous/50cve/ ⇒ basic crash harness도 memory error를 탐지하지만 Asan이 더 빠름.
ASan은 shadow memory를 사용하고 있다. shadow memory를 사용하면 각 메모리 주소가 역참조 되기전에 유효성(validity)를 빠르게 확인할 수 있다. 이 방법은 원본 프로그램에서 crash가 발생하지지 않아도 안전하지 않은 메모리 접근들을 많이(다는 아니고) 탐지할 수 있게 해준다.
- Shadow Memory : 프로그램이 실행되는 동안 사용되는 컴퓨터 메모리에 대한 정보를 추적하고 저장하는데 사용되는 기술. 개별 비트 또는 주 메모리의 하나 이상의 바이트에 매핑되는 섀도우 바이트로 구성
MEDICES[101]는 64비트 플랫폼에서 사용할 수 있는 큰 메모리 공간을 활용하여 할당된 객체 사이에 액세스 불가능한 redzone에 큰 chunk를 생성함으로써 ASan을 향상시킨다. 이러한 redzone 은 손상된 포인터가 잘못된 메모리를 가리키고 crash를 일으킬 가능성을 높인다.
- 할당된 객체들 사이에 엑세스 불가능한 redzone을 만들어두면, 그 객체 범위를 넘는 접근에 대해서 문제가 발생했다는 것 알 수 있음
- 스택 카나리와 비슷한 개념인듯함
SoftBound/CETS [159], [160]은 컴파일 중에 프로그램을 instrument하는 또 다른 메모리 에러 탐지기다. 그러나 ASan처럼 유효한 메모리 주소를 추적하는게 아니라, 경계와 시간적 정보를 각 포인터와 연결하여 이론적으로 모든 공간 및 시간 메모리 에러를 감지한다. 하지만 이렇게 완벽하게 탐지를 하다보니 평균적으로 오버헤드가 116% 정도 높은 단점도 가지고 있다[160].
- 경계 bounds(공간, out of bounds를 생각하면 될거같음)
- 시간적 temporal(시간, 시간적 에러)
CaVer [133], TypeSan [96], HexType [113]은 instrument 프로그램을 컴파일하여 C++ Type Casting의 bad-casting 을 검출한다.
- Bad casting : 객체가 호환되지 않는 type으로 캐스팅될때, 예를 들어 base class의 객체가 파생된 타입(derived type)으로 캐스팅되는 경우
CaVer는 역사적으로 이러한 유형의 취약점을 포함하고 있는 웹 브라우저로 확장되는 것으로 나타났으며 7.6에서 64.6%의 오버헤드를 발생시킨다.
memory safety protection의 또 다른 클래스는 Control Flow Integrity [10], 11로, 원래 프로그램에서는 불가능한 제어 흐름 전환을 런타임에 감지한다. CFI는 프로그램의 제어 흐름을 비정상적으로 수정한 test case를 탐지하는 데 사용될 수 있다. a subset of CFI violations으로부터 보호하는 데 초점을 맞춘 최근 프로젝트는 주요 gcc 및 clang 컴파일러에서 사용되고 있다[208].
- CFI 보장은 프로그램 내의 모든 제어 흐름이 의도한대로 흘러가는 것을 확인함으로써 현재 수행 중인 프로그램의 무결성을 보장하는 기법,즉 미리 분석해놓은 Control-Flow Graph와 실제 프로그램 수행이 부합되는지 확인하는 방식
6.1.2 Undefined Behaviors
C와 같은 언어는 언어 specification에 의해 정의되지 않은 많은 행동들이 있다. 컴파일러는 이러한 구조(constructs)를 다양한 방식으로 자유롭게 처리할 수 있다. 많은 경우에, 프로그래머들은 의도했든 아니든 그들의 코드를 몇 개의 컴파일러에서만 맞도록 구현하는 경우가 많다.
비록 이게 많이 위험해 보이지는 않지만, 많은 요소들이 최적화 설정, 아키텍처, 컴파일러, 심지어 컴파일러 버전까지, 정의되지 않은 동작들을 컴파일러가 어떻게 구현하느냐에 영향을 미칠 수 있다. 취약점과 버그는 컴파일러의 정의되지않은 행위에 대한 구현이 프로그래머의 의도와 일치하지 않을때 발생한다.
⇒ 컴파일러, 최적화설정, 아키텍처, 컴파일러 버전에 따라 정의되지 않은 동작을 다루는 방법이 달라지는데, 프로그래머들은 몇 개의 컴파일러에만 집중해서 코드를 짜는 경우가 많다. 그래서 프로그래머의 의도와 다른 결과가 나오는 경우 취약점과 버그가 발생
Memory Sanitizer(MSan)
MSAN(Memory Sanitizer)은 컴파일 중에 프로그램을 instrument 하여 C 및 C++의 초기화되지 않은 메모리 사용으로 인해 발생하는 정의되지 않은 동작을 탐지하는 도구이다 [199]. ASAN과 유사하게 MSan은 주소 지정 가능한 각 비트의 초기화 여부를 나타내는 shadow memory를 사용한다. Memory Sanitizer의 오버헤드는 약 150%이다.
- 초기화 되었는지 아닌지를 위한 각 addressable 비트를 표현하기 위해 shadow memory 사용
Undefined Behavior Sanitizer (UBSan)
Undefined Behavior Sanitizer (UBSan) [71] modifies programs at compile-time to detect undefined behaviors. Unlike other sanitizers which focus on one particular source of undefined behavior, UBSan can detect a wide variety of undefined behaviors, such as using misaligned pointers,
division by zero, dereferencing null pointers, and integer overflow.
Undefined Behavior Sanitizer (UBSan)는 프로그램을 compile-time에 수정하여 정의 되지 않은 동작들을 탐지한다. 다른 sanitizers들이 정의되지 않은 동작의 한가지 특정 요소에만 집중한다면 UBSan은 다양하고 넓은 종류의 정의되지 않은 동작들을 탐지할 수 있다. 예를 들어 잘못 할당된 포인터 ,0으로 나누는 경우, 널 포인터 역참조(널포인터에 어떠한 값을 대입할 때), 정수 오버플로우와 등이 있다.
Thread Sanitizer(TSan)
TSAN(Thread Sanitizer) [193]은 컴파일 중 수정을 통해 정밀도와 성능 사이의 trade off를 유지하면서 data race(race condition)을 감지한다. 이러한 버그는 데이터 손상을 유발할 수 있으며 비결정적인 특성으로 인해 다시 재현하기가 매우 어려울 수 있다.
⇒ 다시 재현하는게 어려움. 시간 차에 의해 중복해서 쓰려고해서 발생하는 문제니까
→ data race : 멀티쓰레드에서 하나의 데이터를 동시에 접근하여 본인의 레지스터로 가져와 계산 수행 후 다른 쓰레드가 새로운 값을 써넣을 때 발생

6.1.3 Input Validation
웹 브라우저와 데이터베이스 엔진을 구동하는 매우 복잡한 파서의 동작을 이해해야 하기 때문에 XSS(사이트 간 스크립팅) 및 SQL injection과 같은 입력 유효성 검사 취약점을 테스트하는 것은 어렵다.
입력값 유효성 검증 fuzzer 예시
KameleonFuzz[74]는 실제 웹 브라우저로 test case를 파싱하고, Document Object Model 트리를 추출하고, XSS 공격을 의미하는 특정 패턴(manually specified patterns)과 비교하여 XSS 공격을 탐지한다.
µ4SQLi 는 유사한 방식을 이용해서 SQL injections을 탐지한다. 웹 응용 프로그램 응답에서 SQL injection 을 탐지하는 것은 실질적으로 힘들기 때문에 대상 웹 응용 프로그램과 데이터베이스 간의 통신을 가로채는 데이터베이스 프록시를 사용하여 입력이 위험한 행동을 유발하는지 여부를 탐지한다.
6.1.4 Semantic Difference
Semantic 버그는 유사한 프로그램의 동작과 비교하는 (근데 완벽하게 동일하지는 않은) differential testing이라고 불리는 기술을 이용해서 발견된다.
- Semantic 버그 : 문법적으로는 옳으나 실행시 결과가 의도하는 대로 안나옴
- Differential testing ; 유사한 응용 프로그램에 동일한 입력을 넣고 실행의 차이점을 통해서 버그를 감지하는 방식의 테스트
여러 fuzzer들은[41], [171], [59] 유사한 프로그램 간의 버그로 동작할 수 있는 불일치를 식별하기 위해 differentail testing을 사용했다.
“Privacy oracle : A system for finding application leaks with black box differential testing”은 단일 프로그램에서 여러 입력의 differential testing를 사용하여 PUT의 입력값으로부터 출력값으로 mutation을 매핑하는 black-box differential fuzz testing를 도입했다. 이러한 매핑은 정보 leak을 식별하는 데 사용된다.
정보 leak : 시스템 권한이 없는 자에게 정보가 노출되는 버그
6.2 Execution Optimizations
우리의 모델에서는 개별 fuzz iteration이 순차적으로 실행된다. 그러한 접근 방식을 간단하게 구현하면 fuzz iteration의 초반부에서 새로운 프로세스가 시작될 때마다 PUT를 단순히 로드하는 것이지만, 반복적으로 PUT을 계속 로딩하면 상당히 성능이 줄어들 수 있다.
- 프로세스 시작될때마다 PUT을 로드하면 로딩으로 인한 오버헤드로 인해 성능이 저하됨
이러한 성능이 줄어드는 문제를 해결하기 위해서 현대의 fuzzer는 이러한 반복적인 로딩 프로세스를 건너뛰는 기능을 제공한다. 예를 들어, AFL [231]은 각 새로운 fuzz iteration 이 이미 초기화된 프로세스에서 fork를 할 수 있도록 하는 fork 서버를 제공한다. 마찬가지로, in-memory fuzzing은 또한 실행 속도를 최적화하는 또 다른 방법이다. 정확한 메커니즘에 관계없이, PUT를 로드하고 초기화하는 오버헤드는 많은 반복에 걸쳐 줄어든다.
“Designing new operating primitives to improve fuzzing performance”에서는 fork()를 대체하는 새로운 system call을 설계하여 반복에 드는 오버헤드를 더욱 낮췄다.
6.3 Triage
Triage is the process of analyzing and reporting test cases that cause policy violations. Triage can be separated into three steps: deduplication, prioritization, and test case minimization.
Triage는 정책 위반을 유발하는 test case를 분석하고 보고하는 과정이다. Triage는 세가지의 스텝들로 나누어질 수 있다. deduplication(중복제거), prioritization(우선순위부여), test case minimization(테스트 케이스 간소화) 세가지 스텝으로 나눌수 있다.
6.3.1 Deduplication
중복제거는 다른 test case와 동일한 버그를 트리거하는 출력 세트에서 test case를 제거하는 과정이다. 중복제거는 각각 고유한 버그를 트리거하는 test case 집합을 반환하는 것이 이상적이다.
중복제거는 여러 가지 이유로 대부분의 fuzzer에서 중요한 구성 요소이다. 실용적으로 구현하는 방법으로는 하드 드라이브에 중복된 결과를 저장하여 디스크 공간 및 기타 리소스의 낭비를 방지하는 방법이 있다.
사용적합성(usability) 고려사항로서, 중복제거는 사용자가 얼마나 많은 다른 버그가 존재하는지 쉽게 이해하고 각 버그의 예를 분석할 수 있게 한다.
이는 다양한 퍼저 사용자에게 유용하다. 예를 들어 공격자는 reliable exploitation이 발생할 가능성이 있는 "home run"(효과가 좋은) 취약점만 찾고 싶어 할 수 있다.
현재 실제로 사용되는 중복제거를 구현하는 방법으로는 세가지 정도 있는데, stack backtrace hashing, coverage-based deduplication, semantics-aware deduplication 정도가 있다.
6.3.1.1 Stack Backtrace Hashing: Stack backtrace
Stack back trace hashing은 crash 발생 시에 자동화된 툴이 stack backtrace을 기록하고 해당 backtrace의 내용을 기반으로 stack hash를 할당하는 가장 오래되고 널리 사용되는 crash 중복 제거 방법 중 하나이다.
예를들어서, 만약에 프로그램이 함수 foo() 안에서 실행되다가 crash가 발생했고 (함수 foo에 crash가 발생하면) main → d → c → b → a → foo 과 같은 call stack 을 가지고 있다면, ,n=5 의 stack backtrace hashing 구현은 d → c → b → a → foo 로 backtrace가 끝난 다른 크래쉬 실행을 유발한 test case와 그룹화 한다.
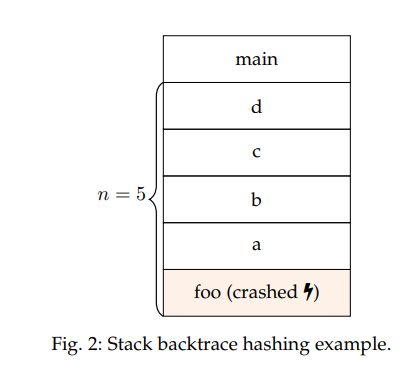
stack hashing 구현
stack hashing 구현은 해시에 포함된 스택 프레임의 수를 시작으로 매우 다양하다. 일부 구현에서는 1개 19, 3개 (SmartFuzz,Woo)[154], [225], 5개 (gdb-exploitable,BFF)[82], [49]를 사용하거나 제한 [123]이 없다. 구현들은 또한 각 스택 프레임에 포함된 정보의 양에 따라 다르다. 몇몇 구현들은 함수의 이름이나 주소만 해시하지만, 몇몇 구현들은 이름과 오프셋 또는 line을 해시한다.
두 옵션이 모두 항상 잘 작동하는 것은 아니기 때문에, 일부 구현[150], [82]은 major hash와 minor hash 두 개의 해시를 생성한다. major hash는 함수 이름만 해시하기 때문에 유사하지 않은 crash들을 함께 그룹화할 가능성이 높은 반면, minor hash는 함수 이름과 line number를 사용하고 스택프레임의 제한이 없기 때문에 더 정확하다.
stack backtrace hashing의 단점
stack backtrace hashing 이 널리 사용되고 있지만, 단점이 없는 것은 아니다. stack backtrace hashing 의 기본 전제는 유사한 crash는 유사한 버그에 의해 발생하며, 그 반대(유사한 버그는 유사한 크래쉬를 발생시킨다.)도 마찬가지라는 것이지만, 아직 검증된 바가 없다. 이 전제가 맞는지에 대해 의심하는 이유중 하나는 몇몇 crash는 crash를 유발한 코드 근처에서 나타나지 않는다는 것이다.
예를들어 heap corruption의 경우 heap overflow가 발생할때가 아니라 코드에서 관련없는 부분이 메모리를 할당하려고할때 크래쉬가 발생할 수 있다.
⇒ heap overflow가 heap corruption을 유발하는게 아니라 코드의 관련없는 부분이 메모리를 할당하려고할때만 heap corruption을 유발하는 취약점이 발생한다. 따라서 crash를 근본적으로 유발한 코드와 위치가 다름
6.3.1.2 Coverage-based Deduplication:
AFL [231]은 인기있는 grey-box fuzzer로, 효율적인 소스 코드 instrumentation을 사용하여 PUT의 각 실행의 edge 커버리지를 기록하고 각 edge에 대한 대략적인 히트 카운트도 측정한다. grey-box fuzzer로써 AFL은 주로 이 coverage 정보를 이용해서 새로운 seed 파일을 선택하는데 이것은 상당히 고유한 중복제거 방식으로 도출된다.
문서에 따르면 AFL은 (i) crash가 이전에 못 찾았던 edge를 커버하거나 (ii) 이전의 모든 crash에 존재했던 edge를 커버하지 않았을 경우 (새로운 부분을 덮었을 경우) crash을 고유하다고 간주한다.
6.3.1.3 Semantics-aware Deduplication:
RETracer [65]는 각 crash의 reverse data-flow에서 복구된 semantics를 기반으로 crash를 선별한다. 특히 RETracer는 crash 덤프(코어 덤프)를 분석하여 crash의 원인이 된 포인터를 확인하고, 잘못된 값을 할당한 명령을 재귀적으로 식별한다. 그것은 결국 최대 프레임 레벨(maximum frame level)을 가진 함수를 찾아내고, 그 함수를 "blames"한다.
blame된 함수는 crash을 클러스터링(집단화)하는 데 사용될 수 있다. 저자들은 sementics-aware 중복제거가 수백만 개의 인터넷 익스플로러 버그를 성공적으로 하나로 중복제거(deduped)하였으나 대조적으로 stack hashing은 동일한 crash를 다수의 다른 그룹으로 분류하며 Semantics-aware 중복 제거 방식의 효율성을 보여주었다.
6.3.2 Prioritization and Exploitability
fuzzer taming 문제라고 불리는 우선순위 결정은 violating(crash로 의심되는.. policy violating) test cases들을 심각성과 고유성에 따라 순위를 매기거나 분류하는 과정이다.
- 즉 crash를 유발하는 test case를 분류하고 순위를 매김
Fuzzing has traditionally been used to discover memory vulnerabilities, and in this context prioritization is better known as determining the exploitability of a crash.
퍼징은 전통적으로 메모리 취약점을 발견하는데 사용되어왔으며, 이러한 맥락에서 우선순위를 결정하는 것은 crash의 exploitability(exploit 가능성)를 결정하는 것으로 더 잘 알려져있다.
- 즉 우선순위가 높을 수록 exploit 가능성이 높다는 의미로 알려져있다는 뜻
방어자와 공격자 모두 공격 가능한 버그에 관심이 있다. 방어자들은 일반적으로 공격 가능한 버그를 공격 불가능한 버그보다 먼저 고치고, 공격자는 명백한 이유로 공격 가능한 버그에 관심을 갖는다.
exploitability ranking system(!exploitable)
최초의 취약점 순위 시스템 중 하나는 마이크로소프트의 !exploitable [150]으로, !exploitable WinDbg 명령 이름에서 이름을 따왔다.
!exploitable은 단순화된 오염 분석(taint analysis)와 쌍을 이룬 여러 가지 휴리스틱(추측)을 사용한다.
- taint analyze : taint(오염) 값을 프로그램에 삽입한 후 이 데이터를 추적하여 프로그램에 어떤 위치에 영향을 미치는지 관찰하는 분석
각 crash를 다음과 같은 심각도 척도(severity scale)로 분류한다. 공격 가능 > 잠재적으로 공격 가능 > 알수 없음 > 공격 가능할 것 같지 않음 이런 분류가 공식적으로 정의된건 아니지만, !exploitable은 비공식적으로 보수적인 경향이 있고 실제보다 좀 더 익스플로잇 가능성이 높다고 보고하는 경향이 높다.
예를 들어, !exploitable은 공격자가 제어 흐름을 강제할 수 있었다는 가정에 따라 잘못된 명령이 실행될 경우 crash를 공격 가능이라고 결론짓는다. 반면, a division by zero crash는 공격 가능할 것 같지 않음로 간주된다.
!exploitable이 도입된 이후, GDB용 exploitable 플러그인 [82]과 애플의 CrashWrangler [19]를 포함한 유사한 규칙 기반 휴리스틱 시스템이 제안되었다. 그러나, 그들의 정확성은 아직 체계적으로 연구되고 평가되지 않았다.
6.3.3 Test case minimization
Triage 의 또 다른 중요한 부분은 test case를 최소화는 것이다. test csae 최소화란 정책을 위반하는 test case에서 이 정책 위반이 어떤 부분에 의해서 트리거 되는지 파악하고, 선택적으로 원본보다 작고 단순하지만 여전히 정책 위반을 유발하는 test case를 생성하는 과정이다. (violation vs crash)
→ 즉 문제가 발생하는 test case에서 문제를 일으키는 부분을 식별하고 test case의 크기를 줄이는 과정
test case 최소화와 seed trimming(3.3, 페이지 8 참조)은 입력 크기를 줄이는 것을 목표로 한다는 점에서 개념적으로 유사하지만, minimizer는 버그 오라클을 활용할 수 있기 때문에 구별된다.
fuzzer에서의 test case minimization 예시
일부 fuzzer는 이를 위해 자체 구현 및 알고리즘을 사용한다.
-
BFF[49]는 원본 seed 파일과 서로 다른 비트 수를 최소화하려는 최소화 알고리즘을 사용한다.
-
AFL [231]에는 test case minimizer가 포함되어 있는데, 이는 바이트를 기회주의적으로 0으로 설정하고 test case의 길이를 단축함으로써 test case를 단순화한다.
-
Lithium [179]은 기하급수적으로 내려가는 크기의 인접한 줄이나 바이트의 "chunks"를 제거함으로써 파일을 최소화하는 범용 test case 최소화 도구이다.
→ 지수적으로 인접한 line이나 바이트의 chunk를 제거해서 파일의 크기를 줄인다?
Lithium은 jsfunfuzz[187]와 같은 JavaScript fuzzer에 의해 생성된 복잡한 test case에 적용하기 위해 만들어졌다
fuzzing 목적 외의 test case minimization 도구
또한 퍼징을 목적으로 특별히 설계되지는 않았지만 fuzzing으로 식별된 test case에 사용할 수 있는 다양한 test case 최소화 도구가 있다.
여기에는 delta debugging [236]과 같은 format agnostic 기법과 C/C++ 파일용 CReduce [178]과 같은 특정 포맷을 위한 특수 기법이 포함된다.
*불가지론(agnostic) 불가지론은 몇몇 명제의 진위 여부를 알 수 없다고 보는 철학적 관점, 또는 사물의 본질은 인간에게 있어서 인식 불가능하다는 철학적 관점이다. 이 관점은 철학적 의심이 바탕이 되어 성립되었다. 절대적 진실은 부정확하다는 관점을 취한다
→ format agnostic 기술 : 포맷이 정해져있는 것이 아닌 일반적으로 사용할 수 있는 기술을 의미하는 듯
→ 델타 디버깅 : 입력값을 줄여나가면서 어느 부분이 문제를 일으키는지 찾아나가는 디버깅
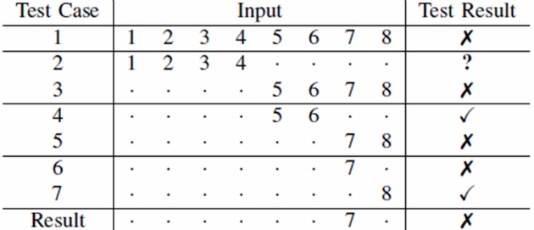
→ 델타디버깅의 예시
비록 특정 포맷들을 대상으로 하는 기법들은 범용적으로 사용할 수는 없지만, 그들은 특정 파일들의 문법에 맞춰 제작되어있기 때문에 일반 기술들보다 훨씬 더 효율적일 수 있다는 장점이 있다.
