1️⃣. 시계열 데이터 (주가데이터) 준비
1. 10년치 주가 정보 가져오기
🔍 사전지식
- DataReader([종목정보],[데이터소스],[시작일],[종료일])
- High(최고가), Low(최저가), Open(시가), Close(종가), Volume(거래량), Adj Close(수정종가;분할,배당,배분,신주 발생이 된 경우를 고려하여 주식가격을 조정해둔 가격)
# Libraries import pandas_datareader.data as web # 주가 데이터 import datetime # 날짜 import matplotlib.pyplot as plt # 시각화 라이브러리 # 시작일, 종료일 start = datetime.datetime(2012, 10, 31) end = datetime.datetime(2022, 10, 31) # DataReader([종목정보],[데이터소스],[시작일],[종료일]) alphabet = web.DataReader("GOOG","yahoo",start,end) print("<Alphabet Inc. (GOOG) 주가 Historical Data>\n") print(alphabet) print('\n') print(alphabet.info())
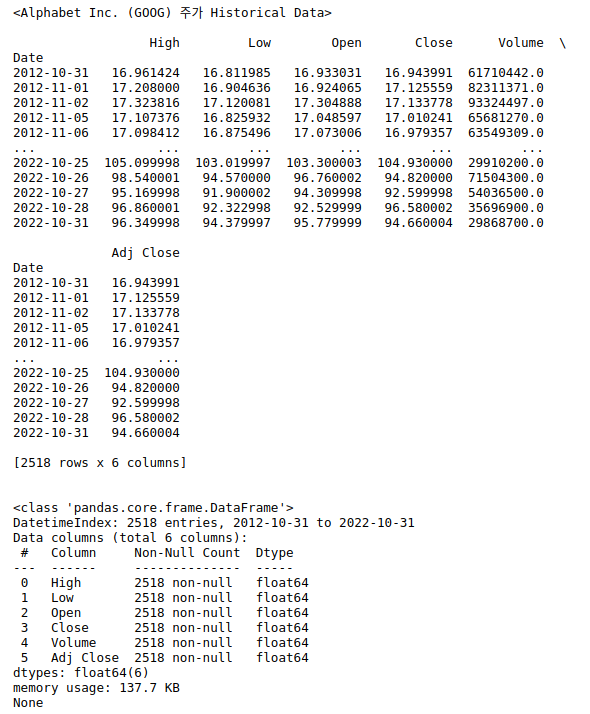
2. 데이터 전처리 & 원본시계열, 이동평균, 이동표준편차 시각화
- 전처리
# 거래량이 0인 일자 제거 & 수정종가 데이터만 사용 data = alphabet['Adj Close'][alphabet['Volume'] != 0]
- 원본시계열, 이동평균, 이동표준편차 시각화
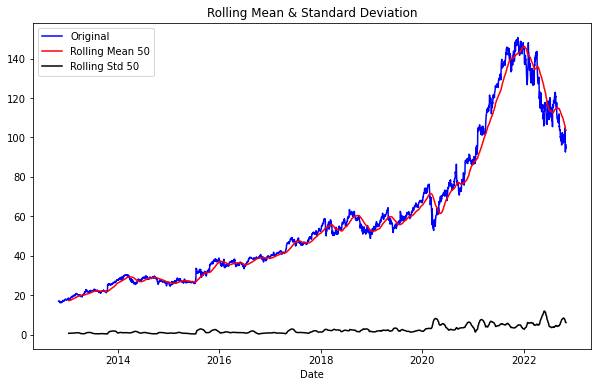
def plot_rolling(data, interval): rolmean = data.rolling(interval).mean() rolstd = data.rolling(interval).std() #Plot rolling statistics: plt.figure(figsize=(10, 6)) plt.xlabel('Date') orig = plt.plot(data, color='blue',label='Original') mean = plt.plot(rolmean, color='red', label='Rolling Mean {}'.format(interval)) std = plt.plot(rolstd, color='black', label = 'Rolling Std {}'.format(interval)) plt.legend(loc='best') plt.title('Rolling Mean & Standard Deviation') plt.show() # 50일치 평균내어 이동평균계산 plot_rolling(data, 50)
- 해석1. 데이터가 평균이 일정하지 않은 비정상성의 특징(아래 개념 설명)을 가지는 것 같아 보이므로, 변환과정을 거친다면 ARIMA의 d차수(아래 개념 설명)가 1 이상일 것이다.
해석2. 계절성이나 특정 주기성은 크게 확인되지 않기 때문에 추후 ARIMA 분석에서 모수 seasonal이나 m은 auto_arima에 적용할 필요가 없을 수도 있다.
2️⃣. 시계열 데이터 분석 - ARIMA
🔍 시계열 분석
: 시계열 분석이란, 일반적인 예측분석 중에서도 시간을 독립변수(X)로 사용하여 종속변수(Y)를 예측하는 분석이다. ARIMA는 시계열 분석(예측)에서 가장 널리 사용되는 모델 중 하나이고, 시계열 데이터는 정상성과 비정상성 데이터로 나눌 수 있다.
🔍 정상성(stationary)과 비정상성(Non-stationary)
- 정상성 : 관측된 시간에 대해 무관한 데이터. 평균과 분산이 일정함. ex)백색소음
- 비정상성 : 시간에 따라 평균 수준이 다르거나 추세(Trend)나 계절성(Seasonality)에 영향을 받는 데이터. ex) 겨울에 난방비 증가, 여름에 아이스크림 판매량 증가
- 비정상성 데이터는 예측범위가 무한대이고 고려할 파라미터들이 많다. 따라서, 비정상성 데이터를 정상성으로 변환하여 분석을 진행하면 예측범위가 일정 범위로 줄어들어 예측 성능이 개선되고, 고려할 파라미터의 수가 감소하여 보다 단순한 알고리즘으로 예측이 가능하며, over fitting도 방지할 수 있다.
- 변환 방법 중에는 평균의 정상화를 위한 차분과, 분산의 안정화를 위한 로그 변환, 제곱/제곱근 변환 등이 있다.
0. ARIMA ?
Autoregressive Integrated Moving Average
: ARIMA는 자기회귀모형(Autoregressive)과 이동평균모형(Moving Average) 둘 다 고려하고, 비정상성(Non-stationary) 데이터의 변환을 위해 관측치간의 차분(Diffrance)을 사용하는 모델이다. (차분이란 현시점 데이터에서 d시점 이전 데이터를 뺀 것이다. Ex. 1차 차분 : 1일 전 데이터와의 차이, 2차 차분 2일 전 데이터와의 차이 )
- AR : 자기회귀모형(Autoregressive). p시점 만큼 앞선 시점까지의 값에 영향을 받는 모형.
- I : integrated. 누적을 의미하며, 비정상성(Non-stationary) 데이터의 변환(평균의 정상화)을 위해 차분을 이용하는 시계열 모형에 붙이는 표현
- MA : 이동평균모형(Moving Average). q시점 만큼 앞선 시점까지의 연속적인 오차값들(shock)의 영향을 받는 모형.
=> AR(p), MA(q) 모형에 차분(d)을 이용해 비정상성을 제거하는 과정을 더하여 ARIMA(p,d,q)로 표현한다.
1. 시계열 정상성 확인 - ADF 테스트
: ADF Test(Augmented Dickey-Fuller Test)는 시계열 데이터의 정상성 여부를 통계적인 정량 방법으로 검증하는 방법이다.
- 귀무가설 Null hypothesis: 증명하고자 하는 가설의 반대되는 가설, 효과와 차이가 없는 가설. 기각에 실패하면 시계열이 비정상성(Non-stationary)임을 의미한다.
- 대립가설 Alternative hypothesis : 증명하고자 하는 가설. 귀무가설이 기각되고 시계열이 정상성(Stationary)임을 의미한다.
1) 원본데이터 ADF 테스트
from statsmodels.tsa.stattools import adfuller def adf_test(data): result = adfuller(data.values) print('ADF Statistics: %f' % result[0]) print('p-value: %f' % result[1]) print('num of lags: %f' % result[2]) print('num of observations: %f' % result[3]) print('Critical values:') for k, v in result[4].items(): print('\t%s: %.3f' % (k,v)) print('ADF TEST 결과') adf_test(data) """ ADF TEST 결과 ADF Statistics: -0.810527 p-value: 0.816010 num of lags: 24.000000 num of observations: 2493.000000 Critical values: 1%: -3.433 5%: -2.863 10%: -2.567 """해석>
pvalue > 0.05 이므로 귀무가설을 기각할 수 없다. 따라서 구글(알파벳) 주식 데이터 (data) 는 비정상성 데이터이다.
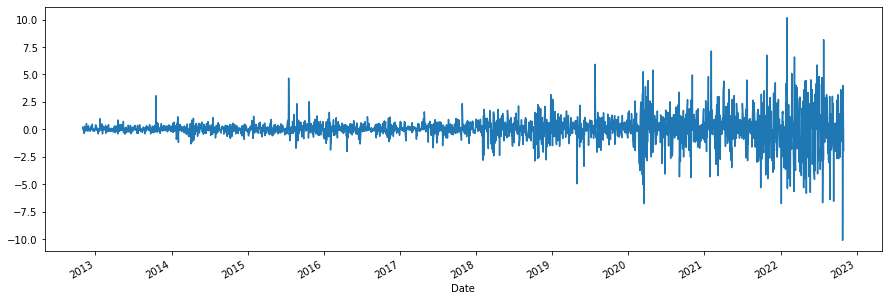
2) 차분 데이터 ADF 테스트# 1차 차분 데이터 diff1 dff1 = data.diff().dropna() dff1.plot(figsize=(15,5))
# 차분 테이터 adf테스트 print('ADF TEST 결과') adf_test(dff1) """ ADF TEST 결과 (-10.57269500384887, 7.236501803746375e-19, 23, 2493, {'1%': -3.4329757705711432, '5%': -2.862700050059295, '10%': -2.567387539813443}, 8124.823784502814) ADF Statistics: -10.572695 p-value: 0.000000 num of lags: 23.000000 num of observations: 2493.000000 Critical values: 1%: -3.433 5%: -2.863 10%: -2.567 """해석> pvalue가 0.05미만이므로 가설 기각(채택), 1차 차분 처리한 데이터가 정상성 데이터가 되었다!
=> 비정상성 데이터는 차분을 이용하여 안정적으로 만들어 분석한다. (ARIMA)
결론 : 원본데이터는 비정상성 시계열 데이터이므로 차분을 이용하는 시계열 모형을 사용하자! = ARIMA를 사용하자~!
2. ARIMA(p,d,q) 모수 추정
AR(p), 차분(d), MA(q)에서 보통 p+q <2, p*q=0 인 값을 많이 사용한다. (p,q둘 중 한 값이 0)
실제로는 AR 이나 MA 둘중 하나의 경향을 강하게 띄기 때문에 주로 이렇게 사용한다.
추정 방법은 (방법1)ACF plot과 PACF plot을 통해 모수 추정 하는 것과 (방법2)pmdarima 라이브러리의 ndiffs, auto_arima 함수를 사용하여 모수 추정하는 방법이 있다.
📍 방법1. ACF, PACF 검정 !
: ACF plot 과 PACF plot 은 현재 값이 과거 값과 어떤 relationship이 있는지 보여준다.
| ACF plot (자기상관함수, Autocorrelation Function plot) | PACF plot (편자기상관함수, Partial Autocorrelation Function plot) |
|---|---|
| 현재값 S(t)에 S(t-p)값 부터 S(t)에 도달하기까지의 값들의 영향까지 고려 ( S(t-p), S(t-p+1), S(t-p+2) .. S(t)값 ) | 현재값 S(t)에 S(t-p)값이 주는 영향만 의미 |
정상 시계열 데이터의 경우, ACF는 상대적으로 빠르게 0(상관관계 0)에 접근하고,
비정상 시계열 데이터의 경우, ACF는 천천히 감소하며 종종 큰 양의 값을 가진다.
> 모델 적합
| AR(p) 모델 적합 | MA(q) 모델 적합 | |
|---|---|---|
| ACF plot | 천천히 감소 | 첫 값으로부터 q개 뒤에 끊긴다 |
| PACF plot | 첫 값으로부터 p개 뒤에 끊긴다 | 천천히 감소 |
* 원본 데이터 (비정상) > ACF 그래프 천천히 감소
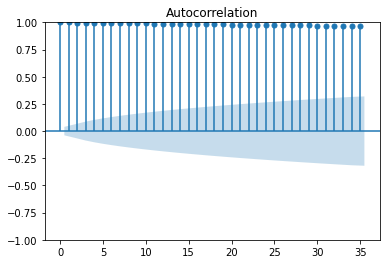
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf plot_acf(data) plot_pacf(data) plt.show()
해석> ACF plot가 천천히 감소되는 것으로 보아 주식 데이터는 주기에 따라 일정하지 않은 비정상성 데이터이고,
PACF plot에서 첫값으로부터 1개 이후 파란 박스에 들어가면서 그래프가 끊기는 것으로 보아 AR(1) 모델을 활용하는 것이 가장 적절할 것으로 예상된다.
*1차 차분 데이터 (정상성) > ACF 그래프 1개 뒤에 끊김
plot_acf(dff1) plot_pacf(dff1) plt.show()
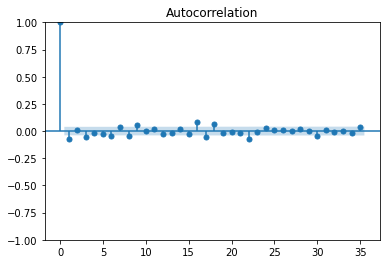
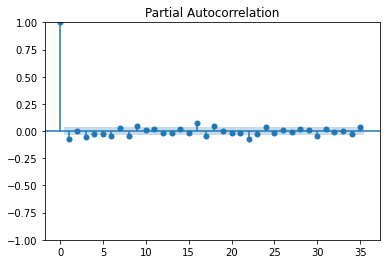
결론: ACF, PACF 그래프 그려본 결과, AR(1), d(1), MA(0)이 적절해 보인다.
📍 방법2. ndiffs, auto_arima 함수 사용
1. 차분 결정 : ndiffs
import pmdarima as pm from pmdarima.arima import ndiffs data = new_alpha['Adj Close'] n_diffs = ndiffs(data, alpha=0.05, test='adf', max_d=6) print(f"추정된 차수 d = {n_diffs}") # 결과 추정된 차수 d = 1
2. 모형 차수 결정 : auto_arima, pmdarima 라이브러리에 있는 함수로, ARIMA 모형의 차수 p,d,q와 계수를 자동으로 추정해주는 함수
y: 시계열 데이터(array 형태)d(기본값 = none): 차분의 차수, 이를 지정하지 않으면 실행 기간이 매우 길어질 수 있음start_p(기본값 = 2),max_p(기본값 = 5): AR(p)를 찾을 범위 (start_p에서 max_p까지 찾는다!)start_q(기본값 = 2),max_q(기본값 = 5): MA(q)를 찾을 범위 (start_q에서 max_q까지 찾는다!)m(기본값 = 1): 계절적 차분이 필요할 때 쓸 수 있는 모수로 m=4이면 분기별, m=12면 월별, m=1이면 자동적으로 seasonal 에 대한 옵션은 False로 지정되며 계절적 특징을 띠지 않는 데이터를 의미함seasonal(기본값 = True): 계절성 ARIMA 모형을 적합할지의 여부stepwise(기본값 = True): 최적의 모수를 찾기 위해 쓰는 힌드만 - 칸다카르 알고리즘을 사용할지의 여부, False면 모든 모수 조합으로 모형을 적합한다.trace(기본값 = False): stepwise로 모델을 적합할 때마다 결과를 프린트하고 싶을 때 사용한다.
model = pm.auto_arima( y=data, d=1, start_p=0, max_p=3, start_q=0, max_q=3, m=1, seasonal=False, # 계절성이 없음! stepwise=True, trace=True )
- 해석> auto_arima를 사용한 결과 최적의 모델은 ARIMA (1,1,0) 모형으로 나왔다.
이때, AIC(Akaike Information Criterion) 또는 BIC(Bayesian Information Criterion)을 최소화하는 차수를 결정한다.
(모델의 fitting력이 좋을수록 AIC값이 작아지고 모델의 복잡도가 높아질수록 AIC값이 커진다.)
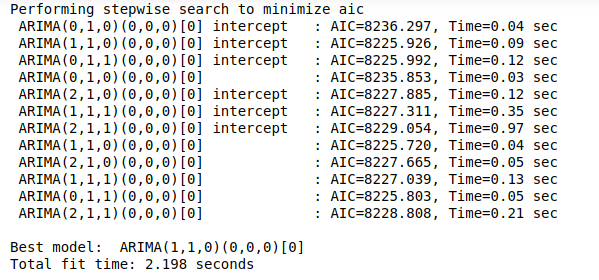
결론: auto_arima결과, ARIMA (1,1,0)이 적절해 보인다.
3. 잔차 검정
: 잔차가 정상성(백색잡음인지), 정규성, 등분산성 등을 만족하는지 파악. model.summary(), model.plot_diagnostics()
print(model.summary())
- 해석> Ljung-Box (Q), Heteroskedasticity (H), Jarque-Bera (JB)에 대한 부분은 모두 잔차에 대한 검정 통계량이다.
통계량 Ljung-Box (Q) Heteroskedasticity (H) Jarque-Bera (JB) 통계량의 귀무가설 "잔차가 백색잡음이다." "잔차가 이분산을 띄지 않는다" “잔차가 정규성을 만족한다” p-value Prob(JB) > 0.05
귀무가설 채택 OProb(JB) <0.05
귀무가설 채택 XProb(JB) <0.05
귀무가설 채택 X해석 잔차가 자기 상관을 가지지 않는 백색잡음이며,
시게열 모형이 잘 적합되었다.잔차가 이분산성을 띈다 잔차가 정규성을 따르지 않음 model.plot_diagnostics(figsize=(16,8)) plt.show()
- 해석1. 잔차의 정상성
- Standardized residual(좌상단) : 잔차의 시계열 데이터. 잔차의 시계열이 평균 0을 중심으로 변동하는 것으로 보임.
- Correlogram (우하단) : 잔차에 대한 ACF 플롯. 어느정도 허용 범위(파란박스) 안에 위치하여 자기상관이 없음을 알 수 있음.
- 해석2. 잔차의 정규성
- Histogram plus estimated density (우상단) : 잔차의 히스토그램을 그려 정규분포(N(0,1))와 밀도를 추정한 그래프.
- Normal Q-Q (좌하단) : 양끝쪽 빨간 선을 벗어나는 구간이 존재한다. 정규성을 만족하려면 빨간 일직선 위에 점들이 분포해야 함.
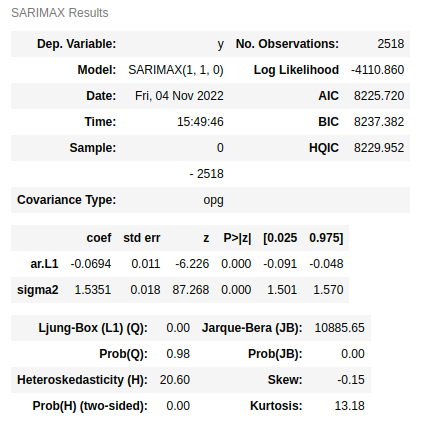
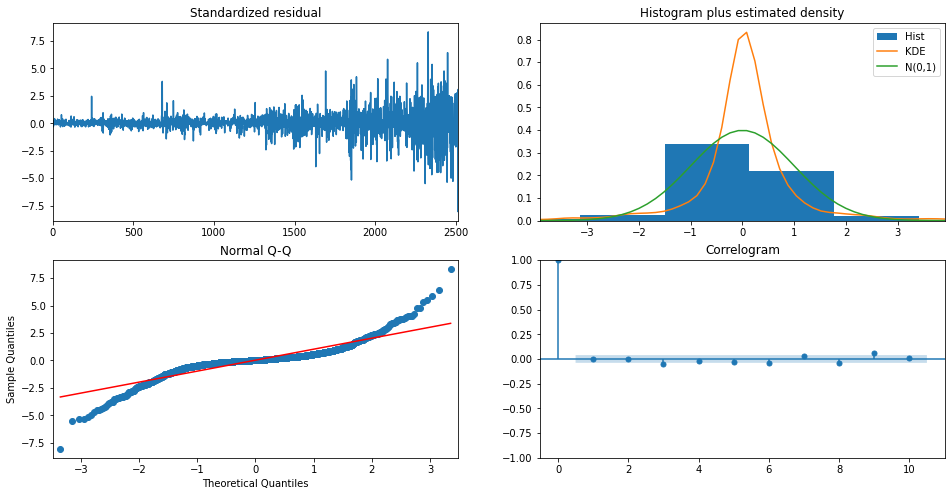
결론: 잔차는 백색잡음(정상성)이지만, 정규성은 따르지 않는다. 따라서 추후 모형 설정에서 여러 파라미터(모수)들을 변경하거나 데이터를 변환해가며 모형을 테스트해본다.
4. ARIMA모델 훈련과 테스트
1) train, test set분리
# train : test = 9 : 1 train_data, test_data = data[:int(len(data)*0.9)], data[int(len(data)*0.9):]2) train_data 모델 학습
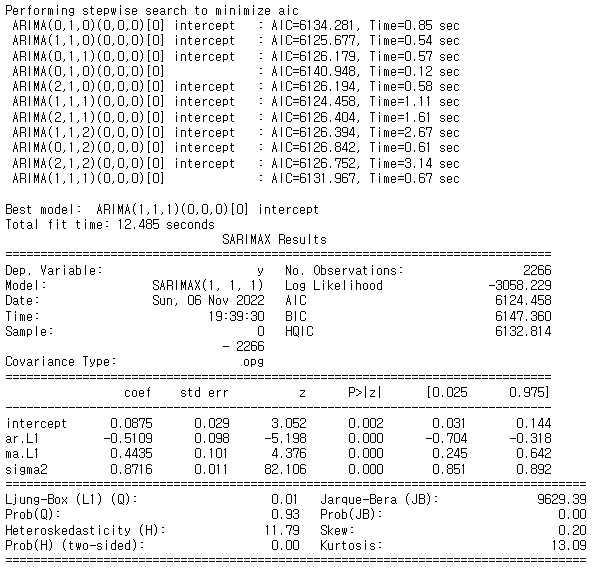
from statsmodels.tsa.arima_model import ARIMA model_fit = pm.auto_arima( y=train_data, d=n_diffs , start_p=0, max_p=2, start_q=0, max_q=2, m=1, seasonal=False, # 계절성이 없음! stepwise=True, trace=True ) print(model_fit.summary())
3) test_data 와 예측값 비교
- forecast 함수 생성
# forecast 함수 def forecast_n_step(model, n = 1): fc, conf_int = model.predict(n_periods=n, return_conf_int=True) # print("fc", fc,"conf_int", conf_int) return ( fc.tolist()[0:n], np.asarray(conf_int).tolist()[0:n] ) def forecast(len, model, index, data=None): y_pred = [] pred_upper = [] pred_lower = [] if data is not None: for new_ob in data: fc, conf = forecast_n_step(model) y_pred.append(fc[0]) pred_upper.append(conf[0][1]) pred_lower.append(conf[0][0]) model.update(new_ob) else: for i in range(len): fc, conf = forecast_n_step(model) y_pred.append(fc[0]) pred_upper.append(conf[0][1]) pred_lower.append(conf[0][0]) model.update(fc[0]) return pd.Series(y_pred, index=index), pred_upper, pred_lower
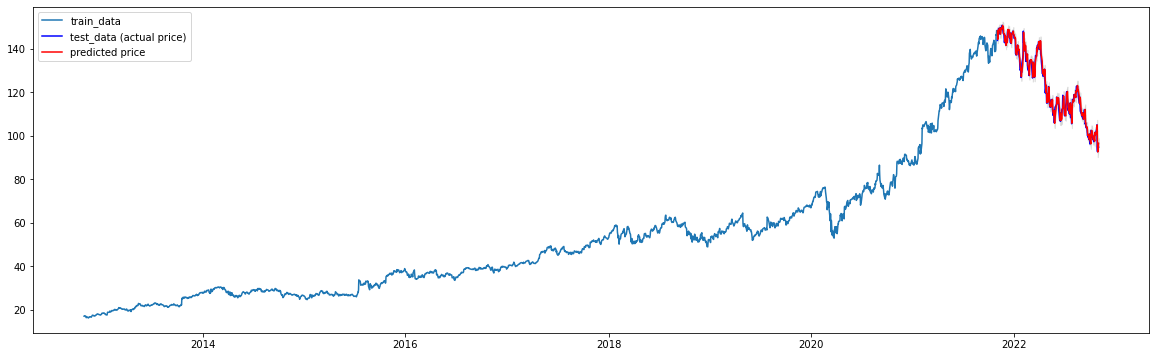
- test_data와 예측값 그래프
# Forecast fc, upper, lower = forecast(len(test_data), model_fit, test_data.index, data = test_data) # pandas series 생성 # fc # 예측결과 lower_series = pd.Series(lower, index=test_data.index) # 예측결과의 하한 바운드 upper_series = pd.Series(upper, index=test_data.index) # 예측결과의 상한 바운드 # Plot plt.figure(figsize=(20,6)) plt.plot(train_data, label='train_data') plt.plot(test_data, c='b', label='test_data (actual price)') plt.plot(fc, c='r',label='predicted price') plt.fill_between(lower_series.index, lower_series, upper_series, color='k', alpha=.10) plt.legend(loc='upper left') plt.show()
4) 모델의 오차율 계산
from sklearn.metrics import mean_squared_error, mean_absolute_error import math mse = mean_squared_error(np.exp(test_data), np.exp(fc)) print('MSE: ', mse) mae = mean_absolute_error(np.exp(test_data), np.exp(fc)) print('MAE: ', mae) rmse = math.sqrt(mean_squared_error(np.exp(test_data), np.exp(fc))) print('RMSE: ', rmse) mape = np.mean(np.abs(np.exp(fc) - np.exp(test_data))/np.abs(np.exp(test_data))) print('MAPE: ' ,'{:.2f}%'.format(mape*100)) """ 결과 모델의 오차율 계산(성능평가) MSE: 4.423699884665538e+128 MAE: 4.1226648119126564e+63 RMSE: 2.103259347932522e+64 MAPE: 11709.69% """
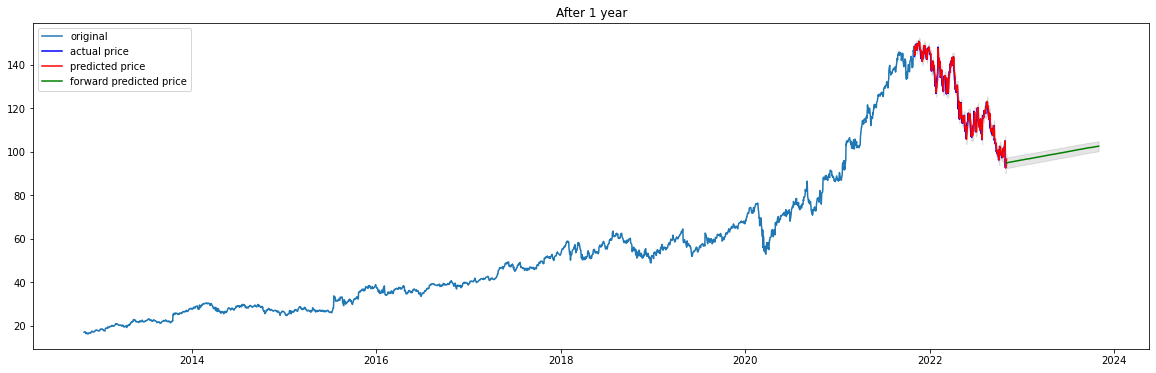
5. 향후 1년 주가 예측
- 주식개장일 불러오는 함수 생성
import exchange_calendars as ecals def get_open_dates(start,end): k = ecals.get_calendar("XKRX") df = pd.DataFrame(k.schedule.loc[start:end]) #["2022-11-01":"2023-10-31"]) # print(df['open']) date_list = [] for i in df['open']: date_list.append(i.strftime("%Y-%m-%d")) # print(i.strftime("%Y-%m-%d")) date_index = pd.DatetimeIndex(date_list) return date_index # DatetimeIndex
- 향후 1년 주가 예측
date_index = get_open_dates("2022-11-01","2023-10-31") fc2, upper2, lower2 = forecast(len(date_index), model_fit, date_index) print('1년 후 주가') print(fc2.tail()) # fc2, conf = forecast_n_step(model_fit, len(date_list)) lower_series2 = pd.Series(lower2, index=date_index) # 예측결과의 하한 바운드 upper_series2 = pd.Series(upper2, index=date_index) # 예측결과의 상한 바운드 # plot plt.figure(figsize=(20,6)) plt.plot(train_data, label='original') plt.plot(test_data, c='b', label='actual price') plt.plot(fc, c='r',label='predicted price') plt.plot(fc2, c='g',label='forward predicted price') plt.fill_between(lower_series.index, lower_series, upper_series, color='k', alpha=.10) plt.fill_between(lower_series2.index, lower_series2, upper_series2, color='k', alpha=.10) plt.title('After 1 year') plt.legend(loc='upper left') plt.show() """ 1년 후 주가 2023-10-25 102.362737 2023-10-26 102.393655 2023-10-27 102.424573 2023-10-30 102.455491 2023-10-31 102.486410 """
Ref
3개의 댓글

좋은 내용 감사합니다 멋지네요! 저도 금융 개발 공부하는 중인데, https://quantpro.co.kr/ 해당 사이트 퀀트 내용 어떤지 의견주시면 감사하겠습니다!

안녕하세요 머신러닝 이제 공부시작한 컴퓨터공학과 학생입니당~
글 너무 잘 보고 있습니다.
이 글을 참고해서 공부를 하며 주가 예측 모델을 만들어 보려하는데,
공부하던중 ACF, PACF 검정에서 AR(1), d(1), MA(0)가 나온 이유를 명확하게 이해하지 못했습니당
d가 1인 것과 원본 데이터에서는 AR을 사용하는 것은 이해가 가지만, 1차분 데이터에서는 왜 AR을 사용하는지 잘 모르겠습니당...
혹시 시간 되시면 답변해주시면 감사하겠습니당