요즘 공고를 보면 Kafka 사용 경험자가 필요 조건으로 많이 보인다.
이에따라 Kafaka 가 무엇인지 알아보자.
Kafka 란
Kafka는 아파치 재단에서 만든 오픈소스이며 분산 이벤트 스트리밍 플랫폼으로 사용처 다음과 같다.
- high-performance data pipelines
- streaming analytics
- data integration
- mission-critical applications (증권 거래소, 은행등)
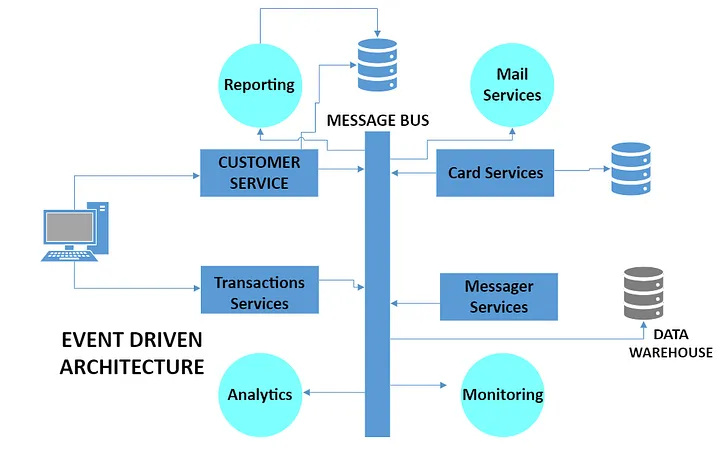
Event Driven에서의 Kafka
- Event Driven 아키텍처의 MSA 환경에서 이벤트 버스의 역할
- 중앙화된 이벤트 버스로 확장성이 매우 좋음
Kafka 특징
- 높은 처리량 및 낮은 지연 시간: 대용량 데이터를 빠르게 처리하고 실시간으로 전달할 수 있도록 설계되었습니다. 분산 아키텍처와 파티션 기반 처리를 통해 높은 처리량과 낮은 지연 시간을 보장합니다.
- 확장성 및 고가용성: 클러스터에 브로커(서버)를 추가하여 손쉽게 시스템을 확장할 수 있습니다. 또한, 데이터 복제 및 파티션 리더 선출 기능을 통해 일부 브로커(서버)에 장애가 발생하더라도 중단 없이 서비스를 제공할 수 있습니다.
- 데이터의 영속성: 메시지를 디스크에 저장하여 데이터 손실 위험을 최소화합니다. 설정에 따라 메시지 보관 기간을 조정할 수 있으며, 필요한 경우 데이터를 장기간 보관할 수 있습니다.
- 다양한 데이터 처리 패턴 지원: 메시지 큐, Pub-Sub 모델, 로그 수집, 이벤트 소싱 등 다양한 데이터 처리 패턴을 지원합니다. 컨슈머 그룹 기능을 통해 여러 애플리케이션이 동일한 데이터를 서로 다른 방식으로 처리할 수 있습니다.
Kafka Excosystem
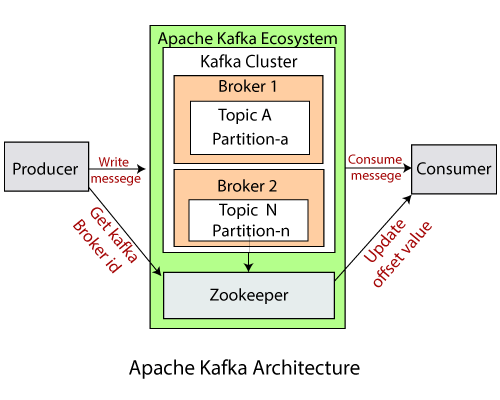
- Kafka Cluster : 여러대의 브로커(서버)가 함께 동작하는 클러스터
- Producers : 데이터를 카프카 클러스터의 특정 토픽으로 전송하는 역할을 합니다. 여러 프로듀서가 동시에 데이터를 전송할 수 있으며, 이를 통해 대규모 데이터 처리가 가능해집니다.
- Consumers : 카프카 클러스터에서 데이터를 읽어 처리하는 역할을 합니다. 여러 컨슈머가 각자 필요한 데이터를 독립적으로 가져갈 수 있으며, 각 컨슈머는 어디까지 데이터를 읽었는지 정보를 유지합니다.
- Brokers : 카프카 클러스터를 구성하는 서버입니다. 프로듀서와 컨슈머 사이의 다리 역할을 하며, 데이터를 안정적으로 저장하고 전달합니다. 여러 브로커가 함께 동작하여 시스템의 확장성과 안정성을 높입니다.
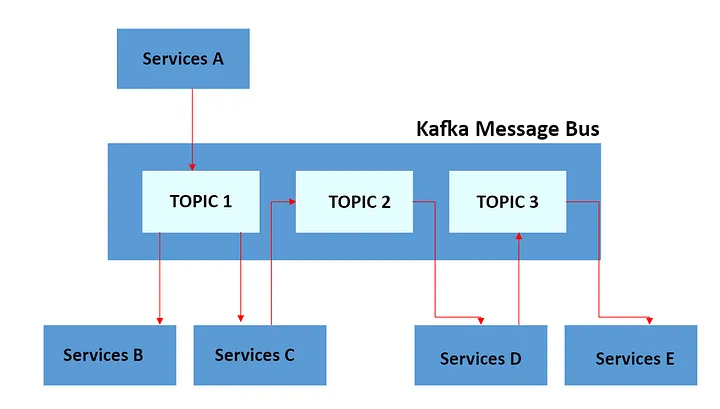
- Topics : 유사한 유형의 데이터를 묶어 관리하는 논리적인 단위입니다. 하나의 클러스터 내에 여러 토픽이 존재할 수 있으며, 각 토픽은 특정 종류의 메시지를 담당합니다.
- Partitions : 토픽 내의 데이터를 더 작은 단위로 나눈 것입니다. 각 파티션은 순차적으로 데이터를 저장하며, 여러 파티션을 통해 데이터 처리량을 높이고 병렬 처리를 가능하게 합니다. (파티션 설정시 전체의 순서를 보장하지 않습니다. 순서 보장은 단일 파티션 내에서만 보장됩니다.)
- ZooKeeper : 카프카 클러스터의 메타데이터와 컨슈머 정보를 관리하는 코디네이터 역할을 합니다. 브로커 목록 관리, 파티션 리더 선출, 클러스터 변경 감지 등 중요한 기능을 수행하며, 카프카 시스템 운영에 필수적인 요소입니다.
참고글
kafka 공식페이지
javatpoint.com
Monolithic Architecture and Message Bus with Apache Kafka

프론트도 조금 아는 짱구 같은 서버 프로그래머