BeautifulSoup4와 selenium을 활용하여 네이버 홈 화면에서 아파트를 검색한뒤 부동산 정보 얻기
[조회조건]
1. http://naver.com 접속
2. '(아파트 이름)' 검색
3. 네이버 부동산에 나오는 결과
[출력결과]
====== 매물 1 ======
거래 : 전세
소재지 : XX동
단지명 : XXXXX XX동
면적 : XX/XX (공급/전용)
매물가 : X,XXX 만원
층 : XX/XX (해당층/총층)
====== 매물 2 ======
...정상적으로 매물을 검색한 페이지인지 확인하기위해 html문서를 만들었다.
하지만 네이버 홈 화면의 html이 작성되었다.
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options.add_experimental_option("detach", True)
options.add_experimental_option("excludeSwitches", ["enable-logging"])
url = "http://naver.com"
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
browser.get(url)
search = browser.find_element(By.ID, "query")
# input = input("매매가가 궁금한 아파트를 입력해주세요 : ")
input = "송파 헬리오시티"
search.send_keys(input+" 매물")
search.send_keys(Keys.RETURN)
with open("quiz.html","w",encoding="utf8") as f:
f.write(soup.prettify())
browser.quit()코드를 다시 살펴보니 BeautifulSoup을 활용할때 http://naver.com의 url을 받아와서 그렇게 된 것이었다.
그래서 browser.current_url로 검색한 후의 url을 다시 받아와서 BeautifulSoup을 활용하는 흐름으로 수정하였다.
options = webdriver.ChromeOptions()
options.add_experimental_option("detach", True)
options.add_experimental_option("excludeSwitches", ["enable-logging"])
url = "http://naver.com"
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
browser.get(url)
search = browser.find_element(By.ID, "query")
# input = input("매매가가 궁금한 아파트를 입력해주세요 : ")
input = "송파 헬리오시티"
search.send_keys(input+" 매물")
search.send_keys(Keys.RETURN)
url = browser.current_url
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
with open("quiz.html","w",encoding="utf8") as f:
f.write(soup.prettify())
browser.quit()html 파일 작성이 잘 되는 것을 확인했고, 이제 매물 정보를 가져올 코드를 작성해준다.
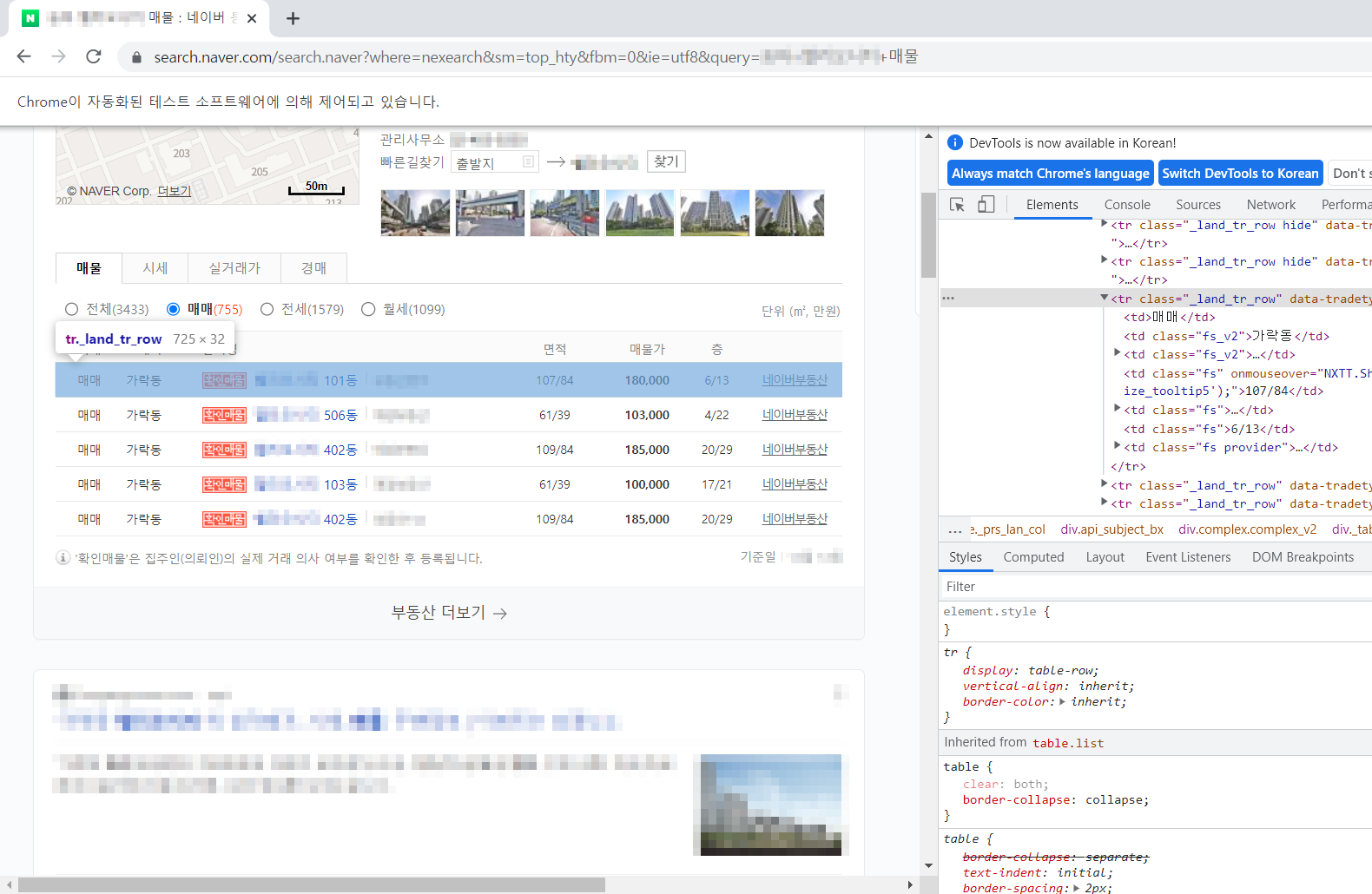
data_rows = soup.find("table", attrs={"class": "list"}).find("tbody").find_all("tr", attrs={"class": "_land_tr_row"})
for idx, row in enumerate(data_rows):
columns = row.find_all("td")
print(f"====== 매물 {idx+1} ======")
print("거래 :",columns[0].get_text())
print("소재지 :",columns[1].get_text())
print("단지명 :",columns[2].find("a").get_text())
print("면적 :",columns[3].get_text(),"(공급/전용)")
print("매물가 :",columns[4].get_text(),"(만원)")
print("층 :", columns[5].get_text(), "(해당층/총층)")인덱스와 같이 출력하기위해 enumerate를 이용했다.
단지명 부분은 부동산 이름이 같이 출력되는 부분이 있어서 a태그로 감싸진 단지명을 출력하도록 했다.
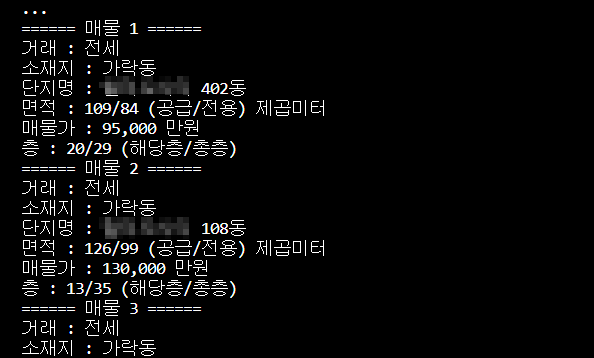
정상적으로 출력되는 것을 확인 할 수 있다.
[전체코드]
import requests
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options.add_experimental_option("detach", True)
options.add_experimental_option("excludeSwitches", ["enable-logging"])
url = "http://naver.com"
browser = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
browser.get(url)
search = browser.find_element(By.ID, "query")
# input = input("매매가가 궁금한 아파트를 입력해주세요 : ")
input = "송파 헬리오시티"
search.send_keys(input+" 매물")
search.send_keys(Keys.RETURN)
url = browser.current_url
res = requests.get(url)
res.raise_for_status()
soup = BeautifulSoup(res.text, "lxml")
# with open("quiz.html", "w", encoding="utf8") as f:
# f.write(soup.prettify())
data_rows = soup.find("table", attrs={"class": "list"}).find("tbody").find_all("tr", attrs={"class": "_land_tr_row"})
for idx, row in enumerate(data_rows):
columns = row.find_all("td")
print(f"====== 매물 {idx+1} ======")
print("거래 :",columns[0].get_text())
print("소재지 :",columns[1].get_text())
print("단지명 :",columns[2].find("a").get_text())
print("면적 :",columns[3].get_text(),"(공급/전용)")
print("매물가 :",columns[4].get_text(),"(만원)")
print("층 :", columns[5].get_text(), "(해당층/총층)")
browser.quit()참고) 나도 코딩 - 웹스크래핑 강의 (퀴즈)
