카프카 커넥트는 데이터 파이프라인 생성 시 반복적인 작업을 줄이고, 효율적인 전송을 하기 위한 애플리케이션이다.
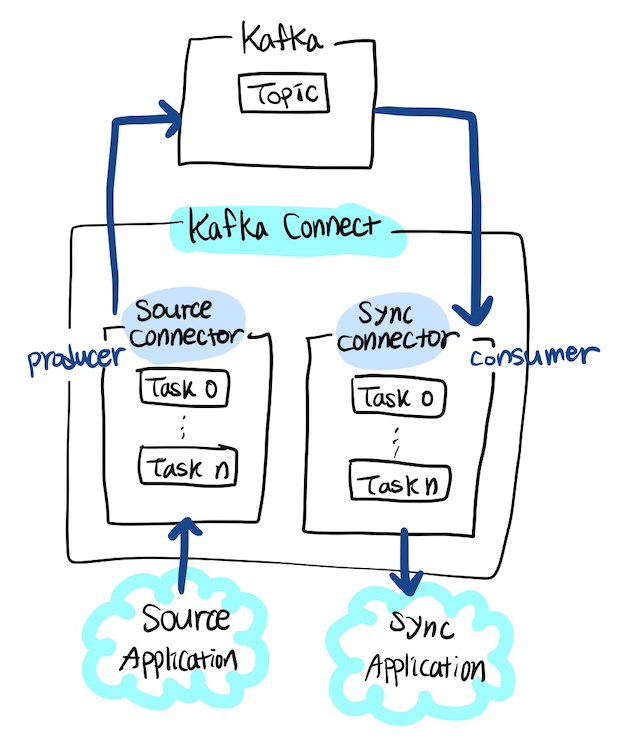
누추하게 나마 그림을 그려보았습니다.. (공대오길 잘했다..)
실질적인 데이터 처리는 커넥터 에서 담당하는데, 사용자가 커넥트에 커넥터 생성 명령을 내리면 커넥트가 내부에 커넥터와 태스크를 생성한다.
여기서 커넥트와 커넥터 용어가 헷갈릴 수 있는데, 커넥트는 config등 환경을 설정해주는 역할이고 데이터 처리는 커넥터 에서 처리된다.
1. 소스커넥터 & 싱크커넥터
MySQL, S3, MongoDB 등과 같은 저장소가 대표적인 소스 어플리케이션, 싱크 어플리케이션인데, 소스 애플리케이션에서 가져온 데이터를 커넥트를 통해 카프카 토픽으로 저장하고, 필요에 따라 가공 후 싱크 애플리케이션으로 저장할 수 있다.
- Source Connector
- 프로듀서 역할을 한다. 말그대로 카프카로 데이터를 가져오는 역할을 한다.
- Sync Connector
- 컨슈머 역할을 한다. 데이터를 저장함.
2. 컨버터, 트랜스폼
커넥터를 사용해서 파이프라인을 생성할 때 사용할 수 있는 기능들이 있는데 첫번째는 converter, 두번째는 transform 이다.
converter: 데이터 처리 전 스키마 변경시 사용
transform: 데이터 처리 시 각 메세지 단위로 데이터를 변환하기 위한 용도
3. 커넥트 실행 모드 (Standalone, Distributed)
커넥트는 두가지 모드로 실행될 수 있는데, 단일 모드(Standalone) 와 분산모드(Distributed) 이다.
단일모드 커넥트
- 환경 설정은 connect-standalone.properties
- 1개의 프로세스만 실행, 단일장애점(SPOF)
분산모드 커넥트
- 환경설정은 connect-distributed.properties
- 2개 이상의 서버에서 클러스터형태로 운영, 고가용성
- 2개 이상의 프로세스가 1개의 그룹으로 묶여서 사용된다. (group.id)
- 운영환경에서는 거의 분산모드를 사용함
예제 코드는,, 나중에 여유가 되면 추가예정..
