Modeling Protocols
보안 프로토콜들이 정의되어지는 방법은 여러가지가 있지만, Tamarin에서는 미리 정의된 프로토콜 컨셉이 없다. 사용자가 자유롭게 모델링하면 된다.
Public-key infrastructure
Tamarin 모델에서, PKI(public key infrastructure)의 미리 정의된 노테이션은 없다. 각 party를 위해서 비대칭키를 사용한 미리 분배된 PKI(A pre-distributed PKI with asymmetric keys)는 party를 위해 키를 생성하는 단일 규칙에 의해서 모델링 될 수 있다.
Party의 identity와 public/private key들은 fact들로써 저장될 수 있다.
public key를 위해서, 우리는 흔히 Pk fact를 사용하고, 해당 public key에 대응되는 long-term private key를 위해 Ltk fact를 사용한다.
이러한 fact들이 오직 key를 얻기 위한 다른 rule들에 의해서 사용될 것이기 때문에, 우리는 persistent fact로 모델링 한다. 우리는 private key x에 대응하는 public key를 나타내기 위해서 추상 함수(abstrat function) pk(x)를 사용한다.
rule Generate_key_pair:
[ Fr(~x) ]
-->
[ !Pk($A, pk(~x))
, Out(pk(~x))
, !Ltk($A, ~x)
]Naxos와 같은 몇몇 프로토콜들은 키 쌍의 대수 성질(the algebraic properties)을 사용한다. 많은 DH기반의 프로토콜들에서, private key 에 대한 public key는 로 표현한다. 이 것을 다음과 같은 rule로 표현할 수 있다.
rule Generate_DH_key_pair:
[ Fr(~x) ]
-->
[ !Pk($A, 'g'^~x)
, Out('g'^~x)
, !Ltk($A, ~x)
]Modeling a protocol step
프로토콜들은 시스템에서 에이전트들의 행동을 나타낸다. 에이전트들은 메시지를 받고 응답을 보내거나 세션을 시작하는 등의 프로토콜 단계(a protocol step)을 수행할 수 있다.
Modeling the Naxos responder role
우리가 responder role을 만들 때, 한 rule내에서 완료되기 때문에 initiator role보다 간편하다.
Diffie-Hellman 지수연산과 두 해시 함수 h1, h2를 사용하는 프로토콜을 설계하려면 반드시 다음과 같이 선언해야 한다.
builtins: diffie-hellman
functions: h1/1
functions: h2/2추가적인 equations없이는, 해당 방법으로 선언한 function들은 one-way function이다.
각각의 responder 스레드(Thread)는 에이전트$R이 메시지를 수신할 때마다, responder는 새로운 값 ~eskR을 생성하고, 응답 메시지를 전송하며, key kR을 계산할 것이다. 우리는 rule의 LHS에 In fact를 지정함으로써 메시지를 수신하는 모델을 설계할 수 있다. 새로운 값을 생성하는 과정은 내장된 fresh rule(Fr)을 사용하여 생성되도록 요구된다.
결국, 이 규칙은 행위자의 long-term private key에 따라 결정되며, 이는 이전에 제시된 Generate_DH_key_pair rule에 의해 생성된 persistent fact에서 얻을 수 있다.
응답 메시지는 기존 해시 함수의 거듭제곱을 사용하여 g를 지수화한 값이다. 해시 함수가 단항 함수(unary, arity one)이므로, 두 개의 메시지를 연결한 값을 인자로 사용하려면 <x, y> 형태의 쌍(pair)으로 모델링하여 단일 인자로 h1을 호출해야 한다.
이 규칙의 초기 공식화는 다음과 같다.
rule NaxosR_attempt1:
[
In(X),
Fr(~eskR),
!Ltk($R, lkR)
]
-->
[
Out('g'^h1(<~eskR, lkR>))
]하지만, responder는 또한 session key kR을 계산한다. session key가 메시지의 송수신에 영향을 주지 않기 때문에, 우리는 rule의 LHS와 RHS으로부터 제외할 수 있다.
그러나 이후 보안 속성(security property)에서 session key에 대한 주장을 제시해야 한다. 따라서, 계산된 key를 action에 추가한다.
rule NaxosR_attempt2:
[
In(X),
Fr(~eskR),
!Ltk($R, lkR)
]
--[ SessionKey($R, kR) ]->
[
Out('g'^h1(<~eskR, lkR>))
]kR의 계산은 위에서 아직 정의되어 있지 않다. 우리는 kR을 완전히 전개하여 명시할 수 있지만, 가독성이 떨어지므로 let ... binding을 사용하여 중복을 방지하고 불일치(mismatches) 가능성을 줄인다. 게다가, key 계산을 위해서 우리는 통신 파트너 $I의 public key가 필요하다. $I는 ~tid라는 thread identifier로 바인드 되어있다.
rule NaxosR_attempt3:
let
exR = h1(<~eskR, lkR>)
hkr = 'g'^exR
kR = h2(<pkI^exR, X^lkR, X^exR, $I, $R)
in
[
In(X),
Fr(~eskR),
Fr(~tid),
!Ltk($R, lkR),
!Pk($I, pkI)
]
--[ SessionKey(~tid, $R, $I, kR) ]->
[
Out(hkr)
]위의 모델은 responder의 역할을 정확하게 수행한다.
우리는 Tamarin의 역방향 탐색(backwards search)을 최적화할 수 있는 추가적인 방법을 고려할 수 있다. NaxosR_attempt3에서 규칙은 lkR이 임의의 항(term)으로 인스턴스화 될 수 있도록 지정하고 있으며, 이로 인해 새롭게 생성되지 않은(non-fresh)항도 허용될 가능성이 있다.
그러나, 키 생성 규칙은 Ltk fact를 생성하는 유일한 규칙이며, 이 규칙은 항상 새롭게 생성된(fresh)값을 사용하여 키를 생성한다. 따라서, 시스템의 어떠한 도달 가능한 상태에서도 lkR은 반드시 fresh 값으로만 인스턴스화됨이 보장된다.
이를 바탕으로 우리는 lkR을 sort fresh로 명시적으로 선언할 수 있으며, 이를 통해 lkR을 ~lkR로 대체할 수 있다. 이러한 변경을 통해 Tamarin의 역방향 탐색이 더욱 효율적으로 수행될 수 있다.
rule NaxosR_attempt3:
let
exR = h1(<~eskR, ~lkR>)
hkr = 'g'^exR
kR = h2(<pkI^exR, X^~lkR, X^exR, $I, $R)
in
[
In(X),
Fr(~eskR),
Fr(~tid),
!Ltk($R, ~lkR),
!Pk($I, pkI)
]
--[ SessionKey(~tid, $R, $I, kR) ]->
[
Out(hkr)
]Modeling the Naxos initiator role
Naxos 프로토콜에서 Initiator 역할은 메시지를 전송하고 응답을 기다리는 과정으로 구성된다. 그러나 initiator가 응답을 기다리는 동안, 다른 에이전트들도 동시에 동작할 수 있다. 따라서, initiator 역할을 두 개의 규칙으로 모델링한다.
첫 번째 규칙은 initiator 역할을 시작하고, 새로운 값을 생성하고, 적절한 메시지를 전송하는 것을 모델링한다. 앞선 예시와 마찬가지로 let ... in 바인딩을 사용하여 표현을 단순화하며, !Ltk fact는 항상 새로운 값을 두 번째 인자로 사용하여 생성되므로, lkI대신 ~lkI를 사용한다.
rule NaxosI_1_attempt1:
let exI = h1(<~eskI, ~lkI >)
hkI = 'g'^exI
in
[ Fr( ~eskI ),
!Ltk( $I, ~lkI ) ]
-->
[ Out( hkI ) ]Using state facts to model progress
이전 규칙이 트리거된 후, initiactor는 응답을 기다리게 된다. 우리는 아직 두 번째 부분을 모델링해야 하며, 이는 응답을 수신하고 키를 계산하는 과정이다.
Initiator 규칙의 두 번째 부분을 모델링하려면, 첫 번째 부분이 특정한 매개변수와 함께 수행되었음을 명확하게 지정할 수 있어야 한다. 직관적으로 보면, 전이 시스템의 상태에 특정 initiator thread가 특정 매개변수를 사용하여 첫 번째 메시지를 보냈다는 사실을 저장해야 한다.
이를 모델링하기 위해 새로운 fact를 도입하는데, 이를 state fact라고 부른다. 이는 특정 프로세스 또는 thread가 실행의 어느 지점에 있는지를 나타내며, 실질적으로 프로그램 카운터 역할을 하면서 해당 프로세스나 메모리 내용을 저장하는 컨테이너 역할도 수행한다.
또한, 동시에 여러 Initiator가 실행될 수 있으므로, 각 initiator의 state fact에 대해 고유한 handle을 제공해야 한다.
아래는 initiator의 첫 번째 규칙을 업데이트한 버전으로, 새로운 state fact인 Init_1을 생성하며, 각 규칙의 인스턴스마다 고유한 thread identifier ~tid를 도입한다.
rule NaxosI_1:
let exI = h1(<~eskI, ~lkI >)
hkI = 'g'^exI
in
[ Fr( ~eskI ),
Fr( ~tid ),
!Ltk( $I, ~lkI ) ]
-->
[ Init_1( ~tid, $I, $R, ~lkI, ~eskI ),
Out( hkI ) ]state fact는 여러 개의 매개변수를 가진다는 점에 주목해야 한다.
rule NaxosI_2:
let
exI = h1(< ~eskI, ~lkI >)
kI = h2(< Y^~lkI, pkR^exI, Y^exI, $I, $R >)
in
[ Init_1( ~tid, $I, $R, ~lkI , ~eskI),
!Pk( $R, pkR ),
In( Y ) ]
--[ SessionKey( ~tid, $I, $R, kI ) ]->
[]두 번째 규칙에서는 네트워크에서 메시지 Y를 수신해야 하며, 이전에 initiator fact가 생성되었음도 요구된다. 이 규칙은 해당 fact를 소모(consume)하며, 프로토콜에서 더 이상의 단계가 없으므로, 유사한 fact를 출력할 필요가 없다. 또한 Init_1 fact가 동일한 매개변수로 인스턴스화되었기 때문에, 두 번째 단계에서는 첫 번째 단계에서 계산된 동일한 에이전트 ID 및 지수 exI를 사용하게 된다.
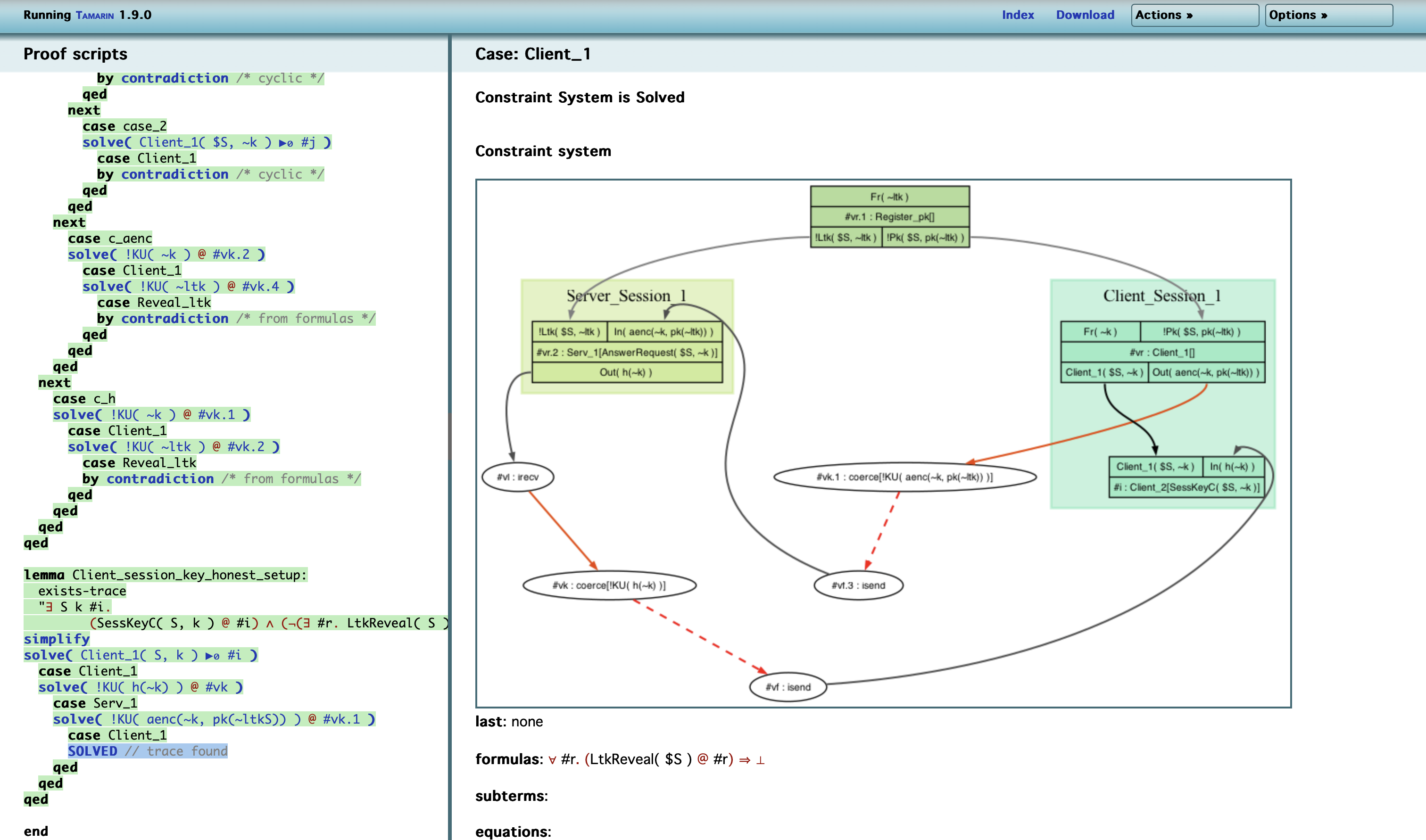
Clustering by Role
그래프의 명확성을 높이고 역할을 식별하기 위해, 노드들을 해당 역할에 따라 클러스터로 그룹화할 수 있다. 클러스터는 단순히 표시 방식에 관한 것이며, Tamarin의 추론에는 영향을 미치지 않는다. 이러한 클러스터링의 목적은 그래프를 더 쉽게 읽을 수 있도록 하는 것이며, 사용자가 이를 활성화하거나 비활성화할 수 있다. 클러스터는 관련된 노드를 포함하는 색상 박스로 표시된다.
클러스터링은 동일한 역할의 서로 다른 세션을 별도의 클러스터로 분할한다. 이를 위해 다음과 같은 휴리스틱을 사용한다. 같은 역할의 두 노드는 linear fact의 사용으로 인해 생성된 edge로 연결된 경우에만 같은 클러스터로 묶인다. 클러스터 내의 규칙들은 클러스터의 색상과 동일한 색을 가진다.
역할에 의해 그룹화하는 2가지 방법이 존재한다.
Manual Clustering
사용자는 특정 역할(role)의 동작을 나타내는 규칙을 수동으로 지정할 수 있다. 이를 위해, 해당 규칙에 역할의 이름을 다음과 같이 주석(annotation)으로 추가할 수 있다.
rule test[role="Alice"]:
[...]
-->
[...]
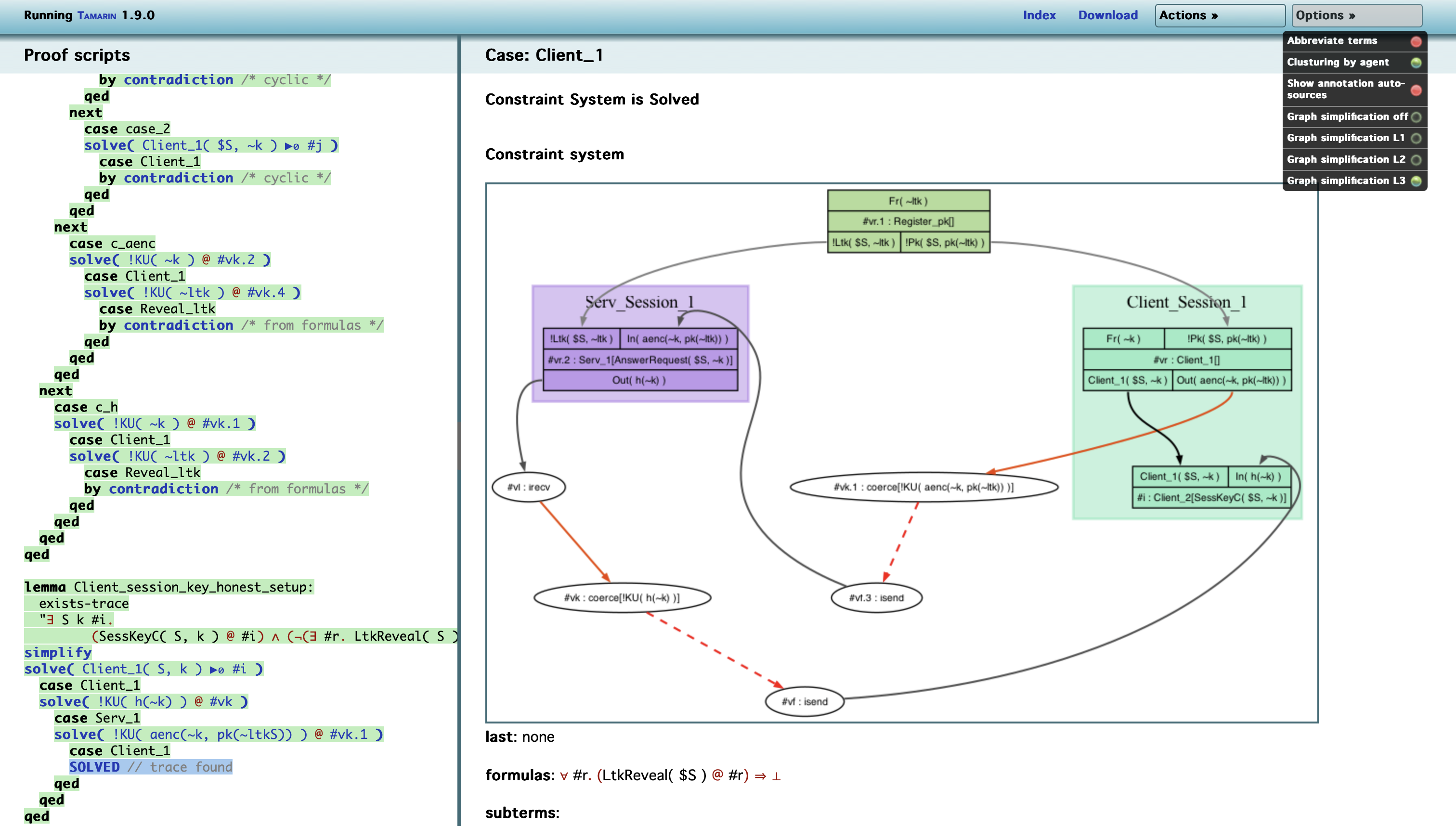
Automatic Clustering
설정 옵션 중 Clusterling By Role이라는 기능이 제공되며, 이를 활성화하면 자동으로 역할별 정렬이 수행된다. 이 옵션은 기본적으로 비활성화 되어 있다. 이 기능을 사용하면 이름이 유사한 모든 규칙이 자동으로 클러스터로 그룹화되며, 이는 수동 클러스터링보다 우선적으로 적용된다.
예를 들어, Alice_1, Alice_2, Alice_test_1, Bob_1이라는 규칙이 있을 경우, 이는 자동으로 세 개의 클러스터(Alice, Alice_test, Bob)으로 분리된다.

잘 보고갑니다~ ^^