22.03.12 SQLD 시험 후기
공부 방법: 노랭이책과 네이버카페(데이터 전문가 포럼의 SQLD 예상문제 풀이) 자료로 퇴근 후 하루 1~2시간 정도 활용해 문제 풀이 및 오답 정리를 통해 개념 및 문제유형을 익히고, 틈날 때마다 sqld 관련 유튜브를 보며 몰랐던 개념을 숙지하고 관련 문제를 다시 풀어보는 시간을 가졌다.
시험 후기: 객관식 40, 단답형 10문제 중 객관식은 5~6문제 정도, 단답형은 특정 함수명이 정확히 기억나지 않아 정답이 확실하지 않았다.
현업을 주로 소프트웨어 설계를 배우고 쓰는 중이라 ORACLE이나 SQL을 직접 쓰지 않기 때문에 개념만으로는 유추해 내기는 어렵고 경험적으로 직접 코딩을 해봐야 알 수 있는 문제들이 더러 있었다. 추후에 현업에서 SW 설계단을 넘어가서 SQL을 다룰 수 있는 환경이 만들어진다면 좀 더 쉽게 풀 수 있었을 것 같다.
여러 IT 자격증(정보처리기사, 리눅스마스터1급, 빅데이터분석기사) 등을 시험 한번에 취득하면서 그나마 SQLD는 나름 현업을 고려해서 잘 짜여진 문제들로 구성되있는 것이 아닌가 하는 시험이 었다.
SQLD 스피드 퀴즈
모델링의 특징 3가지
- 추상화
- 단순화
- 명확화
DCL에 속하는 명령어
- GRANT
- REVOKE
DDL
- CREATE
- DROP
- RENAME
- ALTER
- TRUNCATE
트랜잭션의 특징
- 원자성
- 일관성
- 고립성
- 지속성
독립성, 편리성, 보안성 하면 떠오르는 것은?
- 뷰(VIEW)
순위가 1 2 3 3 4 5 ... 일 때 생각나는 함수는?
- DENSE_RANK
SELECT NULLIF('A','A') FROM DUAL; 의 결과는?
- NULL
SELECT문의 논리적인 수행 순서
- FROM - WHERE - GROUP BY - HAVING - SELECT - ORDER BY
UNION 과 UNION ALL 의 차이
- UNION은 중복 데이터 삭제
데이터를 빠르게 조회하기 위해 미리 계산된 값이 저장되는 속성
- 파생속성
계층 쿼리에서 형제 노드 간의 정렬을 지정하는 구문?
- ORDER SIBLINGS BY
제1장 데이터 모델링의 이해 (22.02.17)
2. 데이터 모델링이 필요한 이유
- 업무정보를 구성하는 기초가 되는 정보들에 대해 일정한 표기법에 의해 표현함 정보시스템 구축의 대상이 되는 업무 내용을 정확하게 분석하는 것
- 분석된 모델을 가지고 실제 데이터베이스를 생성하여 개발 및 데이터관리에 사용하기 위한 것
- 즉, 데이터모델링이란 것은 단지 데이터베이스만을 구축하기 위한 용도로 쓰이는 것이 아닌 업무를 설명하고 분석하는 부분에서도 중요한 의미
3. 데이터모델링 유의점
- 중복 : 여러 장소의 데이터베이스에 데이터를 중복으로 저장하지 않도록
- 비유연성 : 데이터의 정의를 데이터의 사용 프로세스와 분리함으로써 데이터 모델링은 데이터 혹은 프로세스의 작은 변화가 어플리케이션과 데이터베이스에 중대한 변화를 일으킬 수 있는 가능성을 줄임
- 비일관성 : 예를 들어 신용 상태에 대한 갱신 없이 고객의 납부 이력 정보를 갱신하는 경우. 서로 연관된 다른 데이터와 모순된다는 고려 없이 일련의 데이터를 수정할 수 있기 때문에 이와 같은 문제가 발생할 수 있음
6. ANSI-SPARC에서 정의한 데이터베이스 3단계 구조
- 외부스키마
- 개념스키마
- 모든 사용자 관점을 통합한 조직 전체 관점의 통합적 표현
- 모든 응용시스템들이나 사용자들이 필요로 하는 데이터를 통합한 조직 전체의 DB를 기술한 것
- 내부스키마
10. 엔터티의 특징
- 반드시 해당 업무에서 필요하고 관리하고자 하는 정보이어야 함
- 유일한 식별자에 의해 식별이 가능해야 함
- 영속적으로 존재하는 인스턴스의 집합(두 개 이상)
- 엔터티는 업무 프로세스에 의해 이용되어야 함
- 엔터티는 반드시 속성(attribute)가 있어야 함
- 엔터티는 다른 엔터티와 최소 한 개 이상의 관계가 있어야 함.
14. 업무에서 필요로 하는 인스턴스에서 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위?
답: attribute(속성)
15. 속성에 대한 설명
- 면적을 가져야 한다
- 하나의 엔티티는 두 개 이상의 속성을 갖는다.
- 한 개의 엔티티는 두 개 이상의 인스턴스의 집합이어야 함
18. 도메인이란?
주문이라는 엔터티가 있을 때 단가라는 속 값의 범위는 100에서 10,000 사이의 실수 값이며 제품명이라는 속성은 길이가 20자리 이내의 문자열로 정의할 수 있다
답 : 도메인(Domain)
19. 속성의 명칭 부여
속성의 명칭은 애매모호하지 않게, 복합 명사를 사용하여 구체적으로 명명(Ex. 학생 엔티티의 이름, 교수 엔티티의 이름과 같이 각 엔티티별로 동일한 속성명을 사용하는 것을 지양)함으로써 전체 데이터모델에서 유일성을 확보하는 것이 반정규화, 통합 등의 작업을 할 때 혼란을 방지
20. 데이터모델링 관계표현
- 데이터모델링에서는 존재에 의한 관계와 행위에 의한 관계를 구분하는 표기법은 없음.
- UML에서 클래스다이어그램 관계 중 연관관계(Association)와 의존관계(Dependency)는 실선과 점선으로 다르게 표현
21. 관계 표기법은 3가지 개념으로 표현
- 관계명
- 관계차수 (1:1, 1:M(crow'sfoot), Relationship Degree/Cardinality)
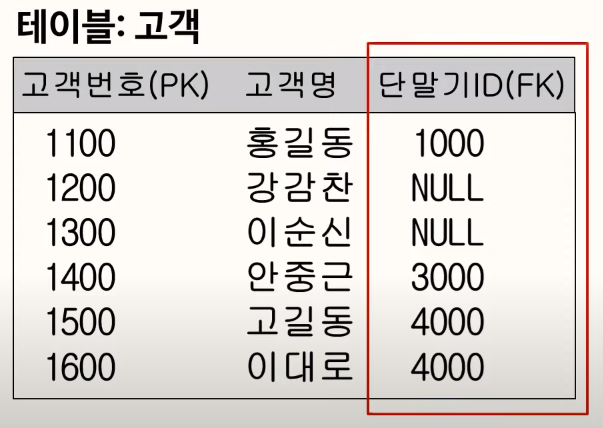
- 선택성(선택사양, Relationship Optionality) : 필수관계(실선), 선택관계(점선) as Barker notation
26. 식별자의 종류
- 주식별자 vs 보조식별자
- 엔터티 내에서 스스로 생성되었는지 여부에 따라
내부식별자 vs 외부식별자 - 단일 속성으로 식별이 되는가에 따라
단일식별자 vs 복합식별자 - 원래 업무적으로 의미가 있던 식별자 속성을 대체하여 일련번호와 같이 새롭게 만든 식별자를 구분하기 위한
본질식별자(누가, 무엇을, 언제, 어디에서 등) vs 인조식별자(주민번호, 사원번호 등)
28. 주식별자 지정 시 유의사항
명칭, 내역 등과 같이 이름으로 기술되는 것들은 주식별자로 지정하기에 부적절함
29. 식별자와 비식별자관계 비교
| 항목 | 식별자관계 | 비식별자관계 |
|---|---|---|
| 목적 | 강한 연결관계 표현 | 약한 연결관계 표현 |
| 자식 주식별자 영향 | 자식 주식별자의 구성에 포함 | 자식 일반 속성에 포함 |
| 표기법 | 실선 | 점선 |
| 연결 고려사항 | - 반드시 부모엔티티 종속 | - 약한 종속관계 |
제2장 데이터 모델과 성능 (22.02.18 ~ )
32. 데이터 모델링 단계에서 성능을 충분히 고려하기 위한 성능 데이터 모델링 수행 절차
1) 데이터모델링을 할 때 정규화를 정확하게 수행한다.
2) 데이터베이스 용량산정을 수행한다.
3) 데이터베이스에 발생되는 트랜잭션의 유형을 파악한다.
4) 용량과 트랜잭션의 유형에 따라 반정규화를 수행한다.
5) 이력모델의 조정, PK/FK조정, 슈퍼타입/서브타입 조정 등을 수행한다.
6) 성능관점에서 데이터모델을 검증한다.
35. N차 정규화
아래와 같은 보관금원장 엔터티에서 관서에 대한 정보가 반정규화 되어 있기 때문에 관서정보를 조회할 때 성능저하가 발생하고 있다. 이 엔터티에 대해 몇차 정규화가 필요한 지와 분리된 스키마 구조를 가장 바르게 짝지은 것은?
보관금원장 테이블{관서번호, 납부자번호 | 관리점번호, 관서명, 상태, 관서등록일자, 직급명, 통신번호}
함수 종속성(FD):
{관서번호, 납부자번호} {직급명, 통신번호}
{관서번호} {관리점번호, 관서명, 상태, 관서등록일자}
ANS: 함수종속성의 규칙에 따라 {관서번호} {관리점번호, 관서명, 상태, 관서등록일자}가 PK인 엔터티가 2차 정규화로 분리되어야 함.
36. 2차 정규화 과정
매각기일과 일자별매각물건을 1:M 관계로 2차 정규화하는 과정으로 지금의 나로써는 알아먹기 힘들다(22.2.18)
37. 1차 정규화 대상
컬럼에 의한 반복적인 속성값을 갖는 형태는 속성의 원자성을 위배한 제1차 정규화의 대상
38. 1차 정규화 대상의 분리 방법
컬럼 단위에서 중복된 경우도 1차 정규화의 대상이 된다. 이에 대한 분리는 1:M의 관계로 두 개의 엔터티로 분리된다.
39. 1차 정규화 대상-컬럼+로우
중복속성에 대한 분리가 1차 정규화의 대상이 되며, 로우단위의 중복도 1차 정규화의 대상이 되지만 컬럼 단위로 중복이 되는 경우도 1차 정규화의 대상이다.
40. 반정규화 고려
- 다량 데이터 탐색의 경우 인덱스가 아닌 파티션 및 데이터 클러스터링 등의 다양한 물리 저장 기법을 활용하여 성능 개선을 유도할 수 있음. 다만, 하나의 결과셋을 추출하기 위해 다량의 데이터를 탐색하는 처리가 반복적으로 빈번하게 발생한다면 이때는 반정규화를 고려하는 것이 좋음
- 이전 또는 이후 위치의 레코드에 대한 탐색은 window function으로 접근 가능
- 집계 테이블 이외에도 다양한 유형(다수 테이블의 키 연결 테이블 등)에 대하여 반정규화 테이블 적용이 필요할 수 있음.
42. 컬럼에 대한 반정규화 기법
- 중복칼럼 추가 - 조인감소를 위해 여러 테이블에 동일한 칼럼을 갖도록 한다.
- 파생칼럼 추가 - 조회 성능을 우수하게 하기 위해 미리 계산된 칼럼을 갖게 한다.
- FK에 대한 속성을 추가 - FK관계에 해당하는 속성을 추가하여 조인성능을 높인다.
- 반정규화 기법이라기보다는 데이터모델링에서 관계를 연결할 때 나타나는 자연스러운 현상
- 이력테이블에 기능 칼럼을 추가 - 최신값을 처리하는 이력의 특성을 고려하여 기능성 칼럼을 추가
(22.02.18-2일차)
44. 조회 성능 향상
공급자 테이블 vs 전화번호 테이블, 메일주소 테이블, 위치 테이블(1:M) 관계
- 공급자의 데이터는 1000만건 이상의 대량 데이터를 가진 테이블임
- 전화번호, 메일주소, 위치는 자주 변경이 될 수 있으며 데이터를 조회를 할 때 항상 최근에 변경된 값을 조회
- 공급자별로 최근에 변경된 전화번호, 메일주소, 위치와 공급자 이름을 같이 조회할 때 이 값들을 공급자 테이블에 반정규화로 갖고 있는 경우에 비해 조회 성능이 저하되지 않는다. 과도한 조인으로 인해 성능이 저하되어 나타남
- 공급자 테이블에 가장 빈번하게 조회되는 값인 최근 변경값에 해당하는 전화번호, 메일주소, 위치를 반정규화하여 조회 성능 향상 가능
- 전화번호, 메일주소, 위치에 대한 가장 최근에 변경된 값을 알 수 있도록 최신여부라는 속성을 추가함으로써 최근 값을 찾기 위한 조회 성능 저하를 예방
- 조회 성능을 위해 하나의 테이블로 통합하여 전화번호, 메일주소, 위치 등이 변경될 경우 전체 속성이 계속 발생되는 이력의 형태로 설계 될 수 있음. 이럴 경우 조회에 대한 성능은 향상되지만 과도한 데이터가 한 테이블에 들어가 용량이 너무 커지는 단점
45. 한 테이블에 많은 컬럼이 존재할 경우 발생하는 문제
- 데이터가 물리적으로 저장되는 디스크 상에 넓게 분포할 가능성이 커지게 되어 디스크 I/O가 대량으로 발생할 수 있음 성능저하
- 따라서 트랜잭션이 접근하는 칼럼유형을 분석해서 자주 접근하는 칼럼들과 상대적으로 접근 빈도가 낮은 칼럼들을 구분하여 1:1로 테이블을 분리하면 디스크 I/O가 줄어들어 성능을 향상시킬 수 있음.
46. 파티셔닝 기법
하나의 테이블에 많은 양의 데이터가 저장되면 인덱스를 추가하고 테이블을 몇 개로 쪼개도 성능이 저하되는 경우가 있다. 이때 논리적으로는 하나의 테이블이지만 물리적으로는 여러 개의 테이블로 분리하여 데이터 액세스 성능도 향상시키고, 데이터 관리방법도 개선할 수 있도록 테이블에 적용하는 기법
48. 논리데이터모델의 슈퍼타입과 서브타입 데이터모델을 물리적인 테이블 형식으로 변환 시
- 트랜잭션은 항상 전체를 대상으로 일괄 처리하는데 테이블은 서브타입별로 개별 유지하는 것으로 변환하면 Union 연산에 의해 성능저하 될 수 있음. (OK)
- 트랜잭션은 항상 서브타입 개별로 처리하는데 테이블은 하나로 통합하여 변환하면 불필요하게 많은 양의 데이터가 집적되어 있어 성능이 저하될 수 있다. (OK)
- 트랜잭션은 항상 슈퍼+서브 타입을 함께 처리하는데 개별로 유지 하면 조인에 의해 성능이 저하될 수 있음(OK)
49. SQL 조회시 PK 인덱스 설계 순서
현금출급기실적 테이블
설계된 순서는 아래와 같음
- PK 인덱스 = 거래일자 > 사무소코드 > 출급기번호 > 명세표번호
- 건수, 금액 컬럼
SQL문
SELECT 건수, 금액 FROM 현금출급기실적 WHERE 거래일자 BETWEEN '20140701' AND '20140702' AND 사무소코드 = '000369'
ANS) 인덱스는 값의 범위에 따라 일정하게 정렬이 되어 있으므로 상수값으로 EQUAL 조건으로 조회되는 칼럼이 가장 앞으로 나오고 범위조회 하는 유형의 칼럼이 그 다음에 오도록 하는 것이 인덱스 엑세스 범위를 좁힐 수 있는 가장 좋은 방법!
PK의 순서를 사무소코드 > 거래일자 > 출급기번호 > 명세표번호로 바꾸는 것이 성능에 유리함
51. FK 조인 정보 조회 시 인덱스 생성 여부
학사기준 테이블
- PK: 학사기준번호
- 컬럼: 년도 + 학기 + 특이사항
수강신청 테이블- PK: 강의번호 + 학번
- 컬럼: 학사기준번호(FK) + 성명 + 연락처1 + 연락처2 + 등록년도 + 감면코드
단, 학사기준과 수강신청은 조인하여 정보를 조회할 업무가 많음
ANS) 엔터티 간에 논리적 관계가 있을 경우, 이 데이터들이 업무적으로 밀접하게 연결되어 상호간에 조인이 자주 발생한다는 것을 의미하는 것이기 때문에, 데이터베이스 상에서 DBMS가 제공하는 FK Constraint를 생성했는지 여부와 상관없이 조인 성능을 향상시키기 위한 인덱스를 생성시켜주는 것이 좋음 수강신청 테이블의 학사기준번호에 인덱스가 필요함.
- 데이터베이스에 생성하는 FK Constraints는 데이터 모델 상에 표현된 논리적 관계에 따라 관련 인스턴스 간에 일관성을 보장하기 위해 설계된 제약조건을 구현할 수 있도록 DBMS가 제공해주는 하나의 '지원기능'으로 이해할 수 있음
SQL 기본 및 활용
1. 다음중 DCL에 해당하는 명령어는?
DDL: 객체 생성(CREATE), 변경(ALTER, RENAME), 제거(TRUNCATE: 테이블 안 내부 데이터만 삭제하고 테이블은 남김, DROP)의 5가지 - DDL은 ROLLBACK을 할 수 없음
DML: 입력(INSERT), 수정(UPDATE), 삭제(DELETE), 조회(SELECT), MERGE(존재하면 UPDATE, 존재하지 않으면 INSERT)
TCL: 작업 완료(COMMIT, SAVEPOINT) 및 취소(ROLLBACK)
DCL: 권한 부여 및 회수(GRANT, REVOKE)
4. 다음 중 데이터 언어와 SQL 명령에 대한 설명으로 가장 부적절한 것은?
(1) 비절차적 데이터 조작어(DML)는 사용자가 무슨 데이터를 원하며, 어떻게 그것을 접근해야 되는지를 명시하는 언어이다.
=> PL/SQL처럼 절차적 데이터 조작어를 통한 프로그래밍이 가능한 경우만 어떻게 데이터를 접근해야 하는지 가능함.
(2) DML은 데이터베이스 사용자가 응용 프로그램이나 질의어를 통하여 저장된 데이터베이스를 실질적으로 접근하는 데 사용되며 SELECT, INSERT, DELETE, UPDATE 등이 있다.
(3) DDL은 스키마, 도메인, 테이블, 뷰, 인덱스를 정의하거나 변경 또는 제거할 때 사용되며 CREATE, DROP, ALTER, RENAME 등이 있다.
(4) 호스트 프로그램 속에 삽입되어 사용되는 DML명령어들을 데이터 부속어(Data sub language)라고 한다.
6. CREATE TABLE, CONSTRAINT 사용

NOT NULL constraint 를 먼저보고 보기를 체크하자
(PROD_ID VARCHAR2(10) NOT NULL
,PROD_NM VARCHAR2(100) NOT NULL,
,REG_DT DATE NOT NULL,
,REGR_NO NUMBER(10)
,CONSTRAINT PRODUCT_PK PRIMARY KEY(PROD_ID));Contraint를 사용한 기본키 지정 방법
CONSTRAINT constraint_name PRIMARY KEY(col_1, col_2, ...)7. ALTER TABLE 활용
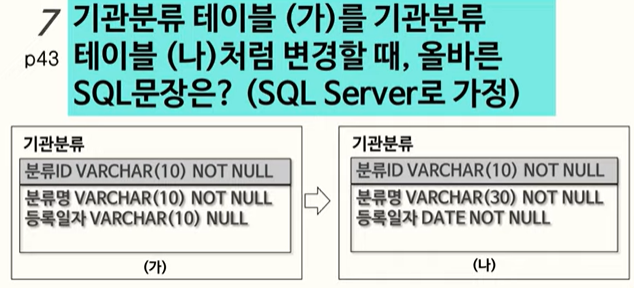
ALTER TABLE 기관분류 ALTER COLUMN 분류명 VARCHAR(30) NOT NULL;
ALTER TABLE 기관분류 ALTER COLUMN 등록일자 DATE NOT NULL;
NULL 값이란?
- NULL은 알 수 없는 값
- 0(zero)도 공백('') 문자도 아님
- NULL을 포함한 사칙연산의 결과는 NULL!
- 숫자를 0으로 나누면 에러가 발생되나, NULL로 나누면 NULL
- IS NULL, IS NOT NULL 만으로 비교 가능
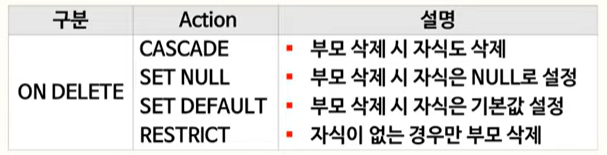
9. ON DELETE 속성

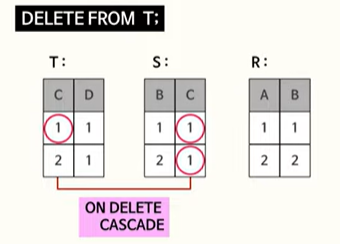
S 테이블의 두개의 row 값은 삭제됨
ON DELETE CASCADE속성
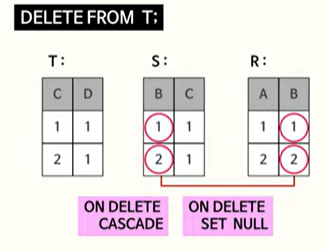
R 테이블의 두개의 row 값 중 B 컬럼의 값은 NULL로 바뀜
ON DELETE SET NULL속성으로 인해
결과적으로 테이블 R의 데이터는
(1, NULL) 과 (2, NULL)
10. 제약조건

UNIQUE 는 NULL 입력이 가능함
| 제약조건 | 설명 |
|---|---|
| NOT NULL | 컬럼이 NULL 값을 포함하지 못하도록 지정 |
| UNIQUE | 컬럼 값이 해당 테이블 전체에서 유일한 값으로 NULL 가능 |
| PRIMARY KEY | NOT NULL & UNIQUE |
| FOREIGN KEY | 입력되어야 할 값이 다른 테이블의 컬럼 값을 참조 |
| CHECK | 해당 조건을 만족하는 값으로만 입력을 제한 |
11. 물리적 테이블 명
65-Base
- A - Z, a-z
- 0 - 9, $, #, _
12. 인덱스 생성 방법


제약 조건의 생략 여부를 확인, 특히 NOT NULL
CREATE TABLE EMP
(EMP_NO VARCHAR2(10) PRIMARY KEY
,EMP_NM VARCHAR2(300) NOT NULL
,DEPT_CODE VARCHAR2(4) NOT NULL
,JOIN_DATE DATE NOT NULL
,REGIST_DATE DATE NULL);
CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE);또는 (기본키를 테이블 만들고 나서 지정하는 경우)
CREATE TABLE EMP
(EMP_NO VARCHAR2(10) NOT NULL
,EMP_NM VARCHAR2(300) NOT NULL
,DEPT_CODE VARCHAR2(4) DEFAULT '0000' NOT NULL
,JOIN_DATE DATE NOT NULL
,REGIST_DATE DATE);
ALTER TABLE EMP ADD CONSTRAINT EMP_PK PRIMARY KEY (EMP_NO);
CREATE INDEX IDX_EMP_01 ON EMP (JOIN_DATE);4번이 틀린 이유: 테이블 생성문과 인덱스 생성문은 정상적으로 수행되지만, 테이블 생성문장에서 이미 PRIMARY KEY를 지정하였으므로 ALTER TABLE 문장에서 오류가 발생함.
13. PK와 집계함수 COUNT

ANS) 학번은 PK 이므로 COUNT 집계 함수의 결과는 둘 다 같음
14. 외래키 설명
1) 테이블 생성시 설정할 수 있다.
2) 외래 키 값은 NULL 값을 가질 수 없다. (특정 테이블의 PK라면)
3) 한 테이블에 하나만 존재해야 한다. (-> PRIMARY KEY에 대한 설명)
4) 외래키 값은 참조 무결성 제약을 만들 수 있다.
15. 데이터베이스의 제약조건에 대한 설명
1) 체크(checK) 제약조건은 DB의 데이터의 무결성을 유지하기 위하여 테이블의 특정 칼럼에 설정
3) 고유키로 지정된 모든 컬럼들은 NULL 값을 가질 수 없다.(NULL 입력 가능)
4) 외래키는 테이블 간의 관계를 정의하기 위해 기본 키를 다른 테이블의 외래키가 참조하도록 설정(참조 무결성)
16. 컬럼 삭제
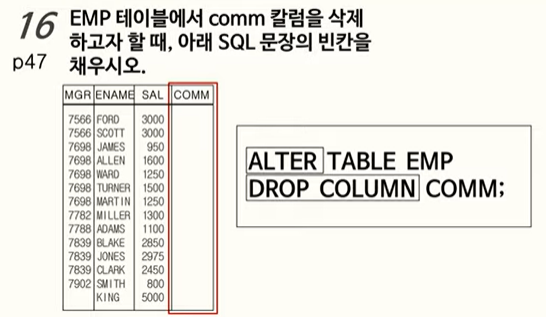
참고: 테이블의 데이터가 아주 많을 때 오라클에서는 이와 같은 삭제(
ALTER TABLE DROP COLUMN작업은 많은 시간을 필요로 함!
17. 참조 관계에서 데이터 삭제


18. RENAME 사용법

RENAME STADIUM TO STADIUM_JSC19. FOREIGN KEY에 의한 Ations

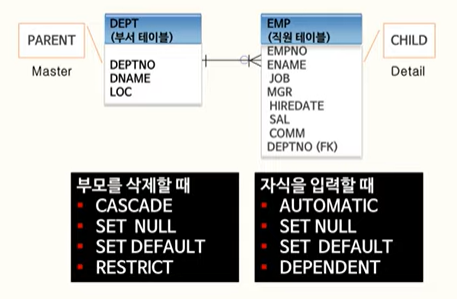
부모 테이블의 행이 삭제될 때 자식 테이블의 행에 어떤 일이 발생하는지 정의할 수 있음.
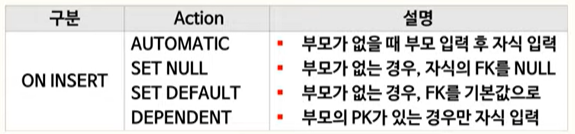
자식 테이블의 행이 입력될 때 부모 테이블의 행과 관련해서 어떻게 할 것인지를 정의.
20. 삽입 성공 SQL 문


1) INTO TBL (ID, AMT)로 명시해야 삽입 가능
2) DEGREE 자릿수 초과
3) AMT 컬럼의 NOT NULL 제약조건으로 인해 불가능
22. FOREIGN KEY와 관련된 DML

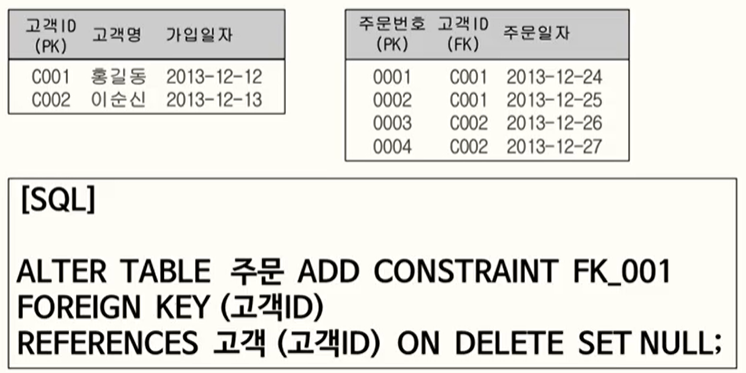
FOREIGN KEY로 인해 고객테이블은 삭제 작업이 제약
주문테이블은 입력 작업이 제약


23. 로그를 남기는 데이터 삭제

2) SYNTAX 에러 발생
3) TRUNCATE 는 테이블 초기화로 ROLLBACK이 불가능
4) DROP과 같은 DDL 명령은 ROLLBACK이 불가능
정리하자면, TRUNCATE TABLE, DROP TABLE은 로그를 남기지 않으므로(Auto COMMIT되어 ROLLBACK 불가) 개발 기준과 상충됨.
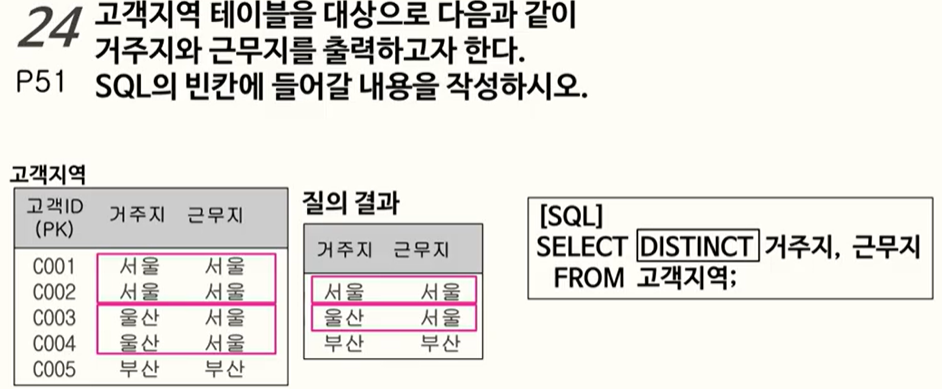
24. DISTINCT 사용법
25-26. DELETE, TRUNCATE, DROP 명령
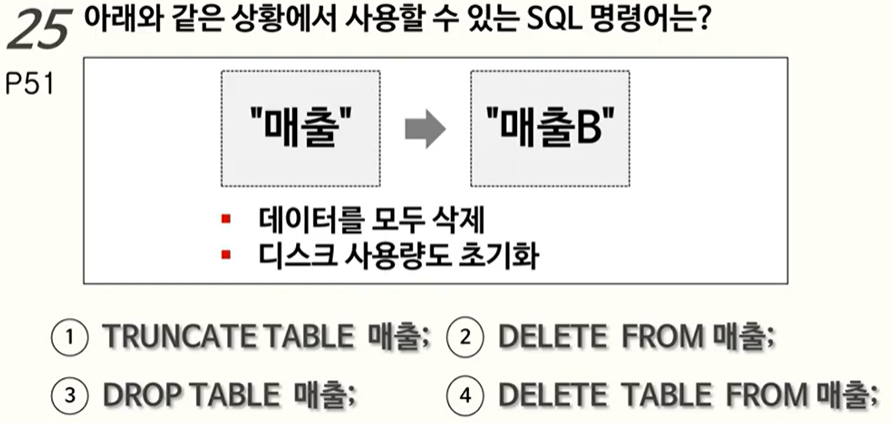
정답은 1번
TRUNCATE명령어는UNDO를 위한 데이터를 생성하지 않기 때문에(e.g.ROLBACK이 불가능) 동일 데이터량 삭제 시DELETE보다 빠르다!
TRUNCATE도 별도로 사용자COMMIT이 필요없이 Auto commit 됨!

27-28. TRANSACTION의 특징
ACID!

2) 일관성(Consistency)
성공적으로 수행이 완료된 트랜잭션의 결과는 영구적으로 반영되어야 한다. 는 일관성이 아닌 지속성에 대한 설명
3) 고립성(Isolation)
둘 이상의 트랜잭션이 동시에 실행되는 경우에 서로의 작업에 영향을 끼칠 수 없다. (격리성)
4) 지속성(Durability)
트랜잭션의 수행 전과 트랜잭션의 수행 완료 후의 데이터베이스의 상태는 언제나 같아야 한다. 는 지속성이 아닌 일관성에 관한 설명

설명 오류!
- Dirty read: 다른 트랜잭션에 의해 수정되었고, commit 전의 데이터를 읽는 것임

- Non-repeatable read: 맞는 설명 ~ 격리성이 낮아서 나타날 수 있는 현상

- Phantom read: 맞는 설명
29. ORACLE 과 SQL Server의 DDL 수행 차이
UPDATE A SET VAL = 200 WHERE ID = '001'; CREATE TABLE B ( ID CHAR(3) PRIMARY KEY); ROLLBACK;에서 ORACLE에서는 200, SQL Server에서는 100이 되었다.
1) ORACLE에서는 DDL 문장(CREATE, ALTER, DROP, TRUNCATE, RENAME) 수행 후 자동으로 COMMIT을 수행
2) SQL Server에서는 ROLLBACK 문장에 의해 UPDATE가 취소되어 VAL 값이 100
3) ORACLE에서는 DDL 문장의 수행은 내부적으로 트랜잭션을 종료 시키므로 B 테이블은 생성됨
4) SQL Server에서는 CREATE TABLE 문장도 TRANSACTION의 범주에 포함된다. 그러므로 ROLLBACK 문장에 의해서 최종적으로 B 테이블은 생성되지 않음!
30. 트랜잭션의 정의
트랜잭션은 데이터베이스의 논리적 연산단위로서 밀접히 관련되어 분리될 수 없는 한 개 이상의 데이터베이스 조작을 가리킴.
31. 트랜잭션의 종료
BEGIN TRANSACTION
으로 구문을 트랜잭션을 시작하고
COMMIT 또는 ROLLBACK으로 트랜잭션을 종료한다.
ROLLBACK 구문을 만나면
최초의 BEGIN TRANSACTION 시점까지 모두 ROLLBACK이 수행된다.32. 트랜잭션의 저장점
저장점을 정의하면 롤백할 때 트랜잭션에 포함된 전체 작업을 롤백하는 것이 아니라 현 시점에서
SAVEPOINT까지 트랜잭션의 일부만 롤백
BEGIN TRANSACTION;
SAVE TRANSACTION SP1;
UPDATE 상품 SET 상품명 = 'LCD-TV' WHERE 상품ID = '001';
SAVE TRANSACTION SP2;
UPDATE 상품 SET 상품명 = '평면-TV' WHERE 상품ID = '001';
ROLLBACK TRANSACTION SP2;
COMMIT
하면 LCD-TV 까지는 저장됨!34. 논리연산자의 우선순위
NOT > AND > OR
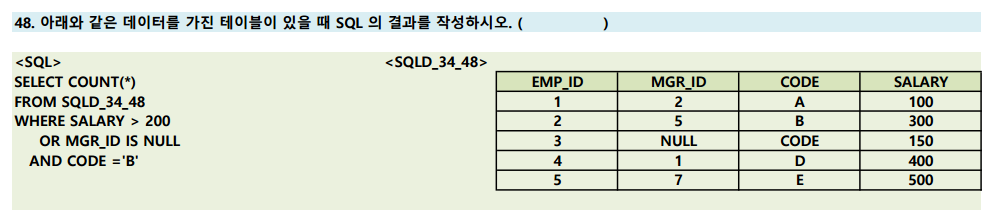
다음과 같을 때 AND를 먼저 수행 한 후 OR 연산을 수행하므로 답은 3이 된다.
37. ORACLE 과 SQL 차이: NULL 과 VARCHAR
1) 서비스번호 컬럼의 모든 레코드가 '001'과 같은 숫자형식으로 입력되어 있어야 오류가 발생하지 않음.
2-4) ''으로 데이터 입력시, 서비스명 컬럼의 데이터에 대해서 ORACLE에서는 NULL로 입력되며, IS NULL로 조건으로 조회하여야 함
반면에 SQL Server에서는 데이터를 조회하려면 서비스명 = ''로 조회하여야 한다.
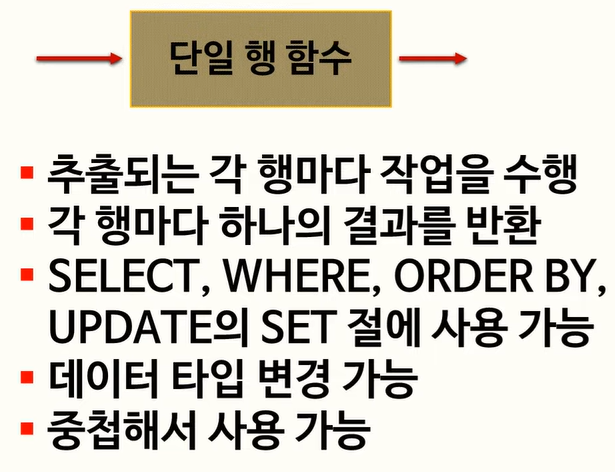
40. 내장 함수 中 단일행, 다중행 함수
가) 함수의 입력 행수에 따라 단일행 함수와 다중행 함수로 구분
나) 단일행 함수는 SELECT, WHERE, ORDER BY, UPDATE의 SET절에 사용이 가능하다.
다) 1:M 관계의 두 테이블을 조인할 경우 M쪽에 다중행이 출력되므로 단일행 함수는 사용할 수 없다(X) 1:M 조인이라 하더라도 M 쪽에서 출력된 행이 하나씩 단일행 함수의 입력값으로 사용되므로 사용할 수 있다.
라) 다중행 함수도 단일행 함수와 동일하게 단일 값만을 반환한다.
다중행 함수(Multi-Row Function)는 집계 함수(Aggregate Function), 그룹 함수(Group Function), 윈도우 함수(Window Function)으로 구분된다.
Ex.COUNT(), AVG(), SUM(), MIN(), MAX(), STDDEV()등

단일행 함수 : 문자형, 숫자형, 날짜형, 변환형 함수로 구성되며
문자형 함수 :UPPER(), LOWER(), CONCAT(), SUBSTR(), LENGTH()등
숫자형 함수 :ROUND(), TRUNC(), MOD(), POWER(a,b), SQRT()등
날짜형 함수 :SYSDATE(), LAST_DAY(SYSDATE), ADD_MONTHS()등,
변환형 함수 :TO_CHAR(), TO_NUMBER(), TO_DATE()등
41. 라인수를 구하기 위해서 함수를 이용해 작성한 SQL
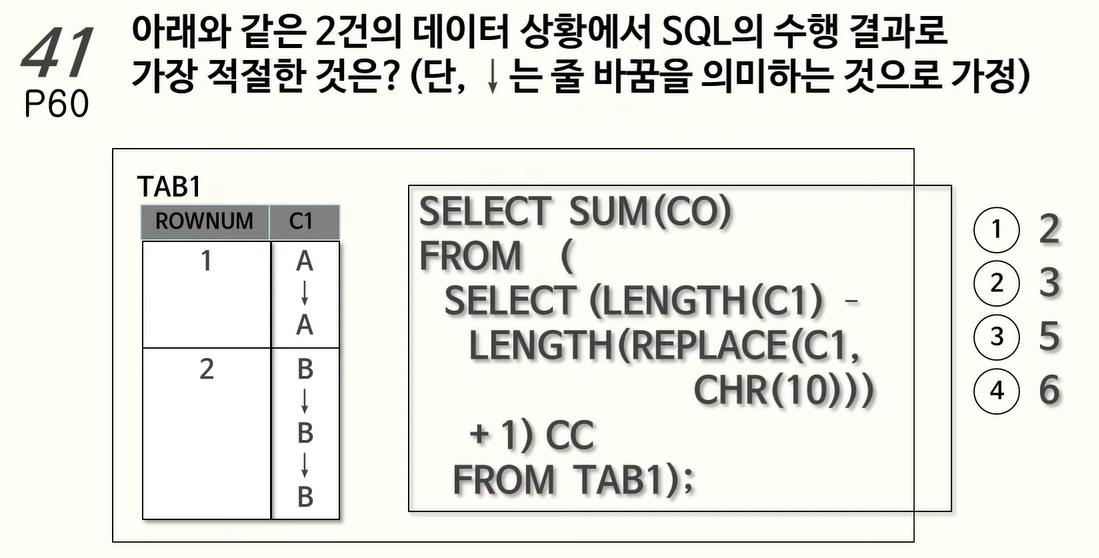
- 줄바꿈 하나의 문자열이므로 C1 컬럼의 문자열의 길이는 3+5=8,
- 여기서 줄바꿈을 의미하는 CHR(10)을 공백 문자열로 바꿨기 때문에
- C1 컬럼은 각각 AA, BBB로 변환되고
- 각각의 문자열의 길이를 빼고 +1을 하면
- SUM((3-2+1) + (5-3+1)) = 5
LENGTH : 문자열의 길이를 반환하는 함수
CHR : 주어진 ASCII 코드에 대한 문자를 반환하는 함수 (CHR(10) -> 줄바꿈)
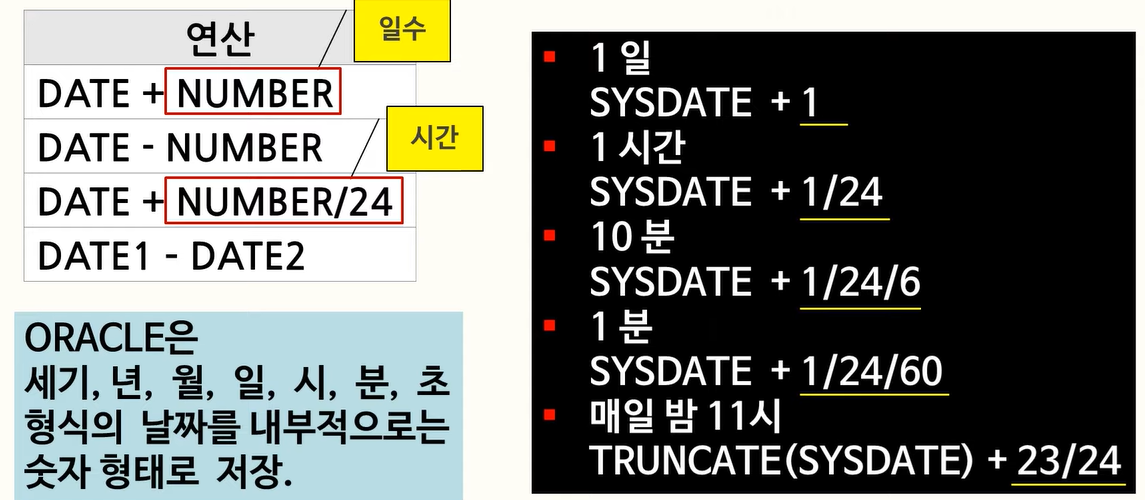
REPLACE : 문자열을 치환하는 함수 (REPLACE(C1, CHR(10)) -> 줄바꿈 제거)42. ORACLE 날짜형 데이터 이해

날짜 정보에다가 +1, 즉 하루를 더하고
그것을 24로 나누면 1시간
또 그것을 6으로 나누면 10분을 더한셈이므로
정답은 3번
43. SEARCHED_CASE_EXPRESSION SQL 과 SIMPLE_CASE_EXPRESSION 문장



44. SUM(CASE ~ END 문)

CASE 컬럼 WHEN 조건1 THEN 값1 WHEN 조건2 THEN 값2 ELSE 값3 END#컬럼이 조건1일 때는 값1을 조건2일 때는 값2를 반환하고 조건에 맞지 않는 경우에는 값3을 반환함


45. ISNULL (SQL) 과 NVL (ORACLE)


IN ('b','c')인 경우 b나 c 둘다
46. 단일행 NULL과 관련 함수의 종류
| 일반형 함수 | 함수 설명 |
|---|---|
| NVL(표현식1, 표현식2) ~ 오라클 / ISNULL(표현식1, 표현식2) ~ SQL | 표현식1의 결과값이 NULL이면 표현식2의 값을 출력한다. (단, 표현식1과 표현식2의 결과 데이터 타입이 같아야 한다. |
| NULLIF(표현식1, 표현식2) | 표현식1의 결과값과 표현식2의 결과값이 같으면, NULL을, 같지 않으면 표현식1을 리턴한다. |
| COALESCE(표현식1, 표현식2, ....) | 임의의 개수 표현식에서 NULL이 아닌 최초의 표현식을 나타낸다. 모든 표현식이 NULL이면 NUULL을 리턴한다. |
| NVL2(col, 표현식1, 표현식2) | col이 NULL이 아니면 표현식1, NULL이면 표현식2를 리턴 |
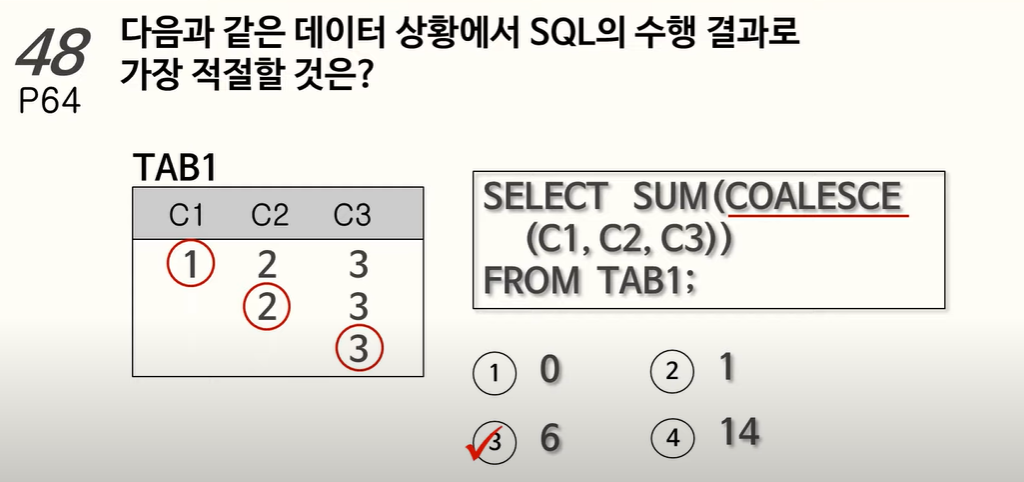
48. COALESCE
51. COUNT

집계함수 COUNT는
NULL인 행 제외하므로 COUNT(GRADE)의 결과는 645
52. 인라인뷰 집계함수 MIN() 활용
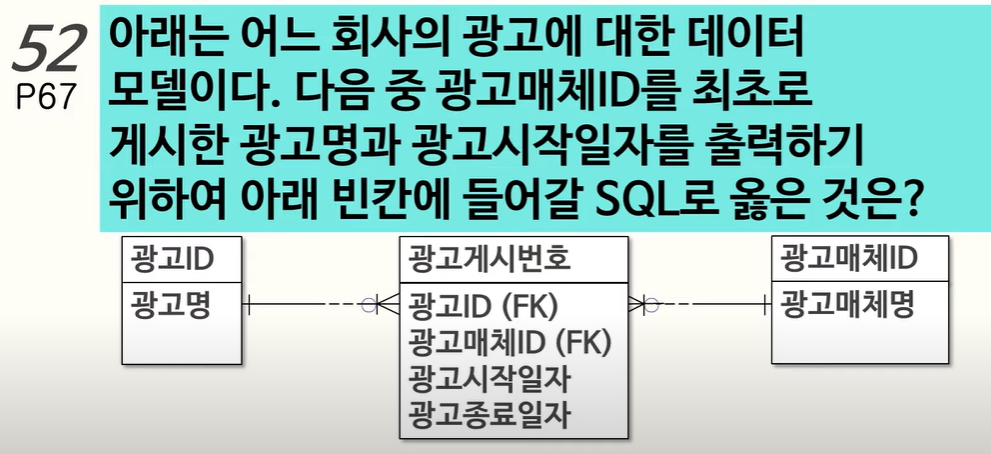

빈칸에 들어갈 쿼리 = 인라인뷰(Inline view)
1번에서 인라인 뷰 안에서 뷰 바깥의 테이블 D와 조인하는 것은 불가능

53. GROUP BY 절 vs HAVING 절
GROUP BY 절
- 소그룹별 기준을 정한 후, SELECT 절에 집계함수를 사용한다.
- 집계함수의 통계 정보는 NULL 값을 가진 행을 제외하고 수행한다.
- GROUP BY 절에서는 SELECT 절과는 달리 ALIAS 명을 사용할 수 없다.
- 집계 함수는 WHERE절에는 올 수 없다. (집계 함수를 사용할 수 있는 GROUP BY절보다 WHERE 절이 먼저 수행된다.)
- WHERE 절은 전체 데이터를 GROUP으로 나누기 전에 행들을 미리 제거시킨다.
HAVING 절
- GROUP BY 절의 기준 항목이나 소그룹의 집계 함수를 이용한 조건을 표시할 수 있다.
- GROUP BY 절에 의한 소그룹별로 만들어진 집계 데이터 중, HAVING 절에서 제한 조건을 두어 조건을 만족하는 내용만 출력한다.
- HAVING 절은 일반적으로 GROUP BY 절 뒤에 위치한다.

GROUP BY 절에서 나타난 회원ID는 반드시 SELECT 절에서 나타나야함.
HAVING절과 같이 나타난 그룹함수의 사용은 문제가 없음.

3번 역시 GROUP BY 절에 나타난 메뉴ID, 사용유형코드가 SELECT에 나타남. HAVING 절을 통한 조건문 필터는 문제가 없음.

56. ORDER BY 절



GROUP BY로 묶었는데 애먼
년칼럼으로 ORDER BY할 수 없음
58. ORDER BY 절

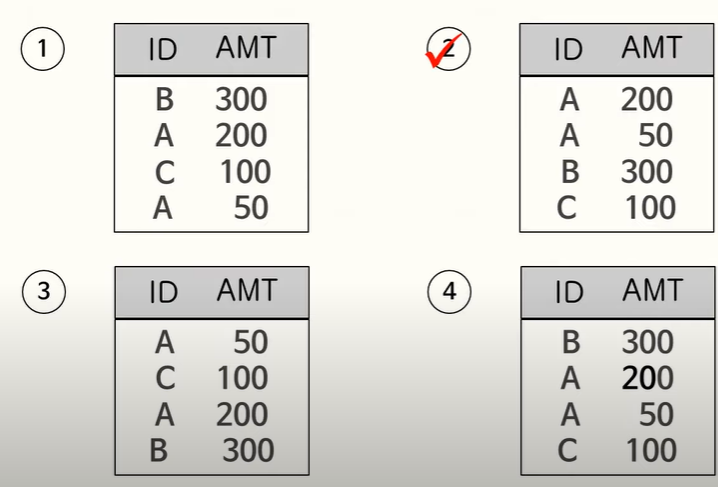
ID 칼럼을 1과 2로 변환하여 오름차순, AMT의 경우 내림차순으로 정렬
59. SELECT 문의 실행 순서
FWGHSO
FROM WHERE GROUP BY HAVING SELECT ORDER BY
60. TOP-N 쿼리


(22.02.21(D-19) 까지)
61. JOIN 최소 조건 테이블
5개의 테이블로부터 필요한 칼럼을 조회하려고 할 때, 최소 몇 개의 JOIN 조건이 필요한가?
=> 4개
63. DBMS 옵티마이저
DBMS 옵티마이저는 From 절에 나열된 테이블이 아무리 많아도 항상 2개의 테이블씩 짝을 지어 Join을 수행한다.
64. LIKE를 이용한 조인
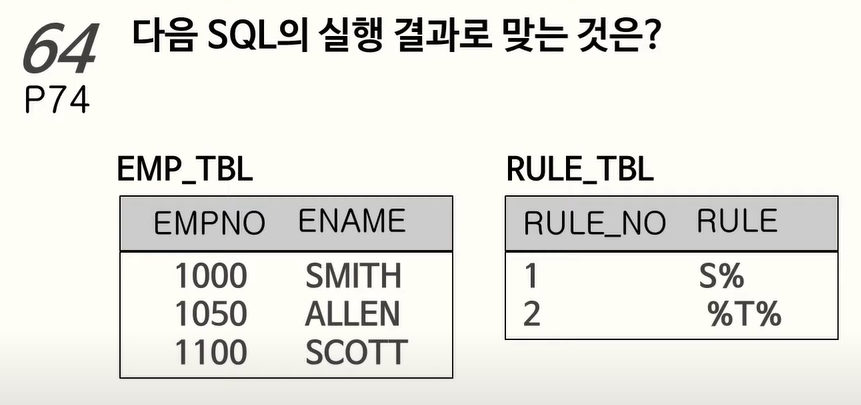

4개: SMITH -> S%, %T% 에 해당 + SCOTT -> S%, %T%에 해당함.
제2장 SQL 활용
(22.02.22)
65. 순수관계연산자
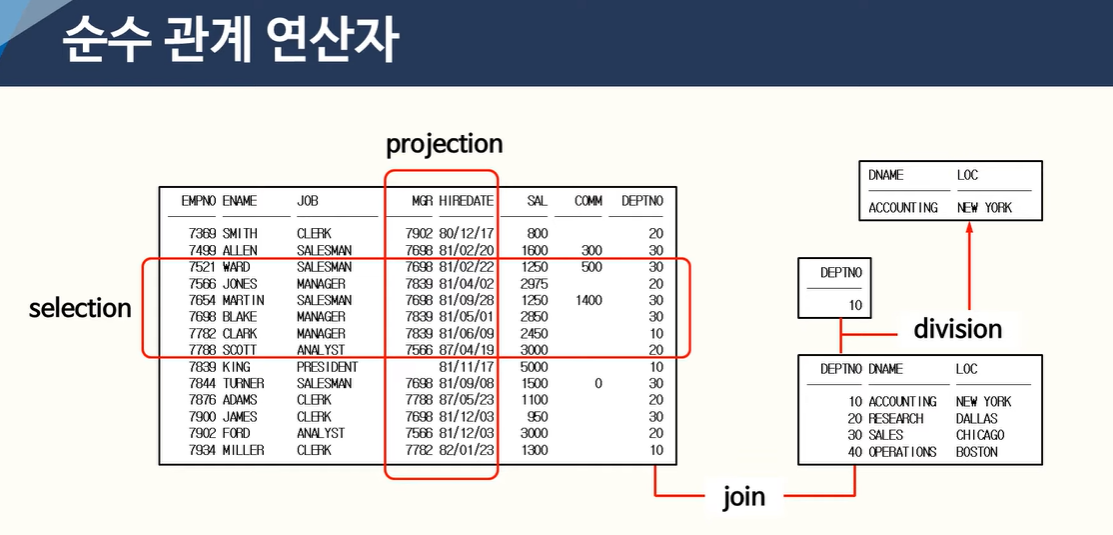
그림과 같이 순수관계연산자는 SELECTION, PROJECTION, JOIN, DIVISION이 있다.
66. 데이터 모델과 JOIN
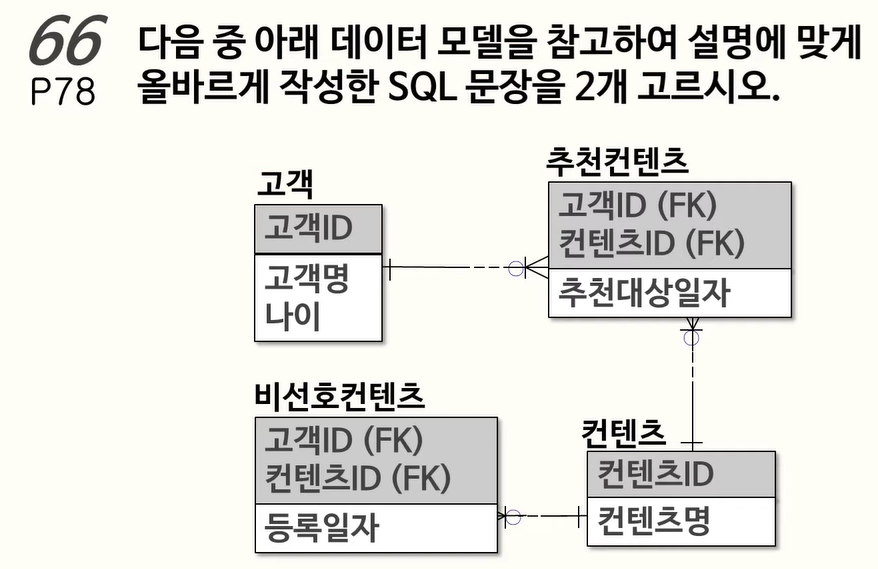
비선호컨텐츠를 제외하는 쿼리를 작성하였으나 고객ID 말고도 컨텐츠ID가 같아야함.


2번의 경우 비선호컨텐츠가 기준으로 선정되었기 때문에 답이 될 수 없음.


67. 데이터 모델과 JOIN
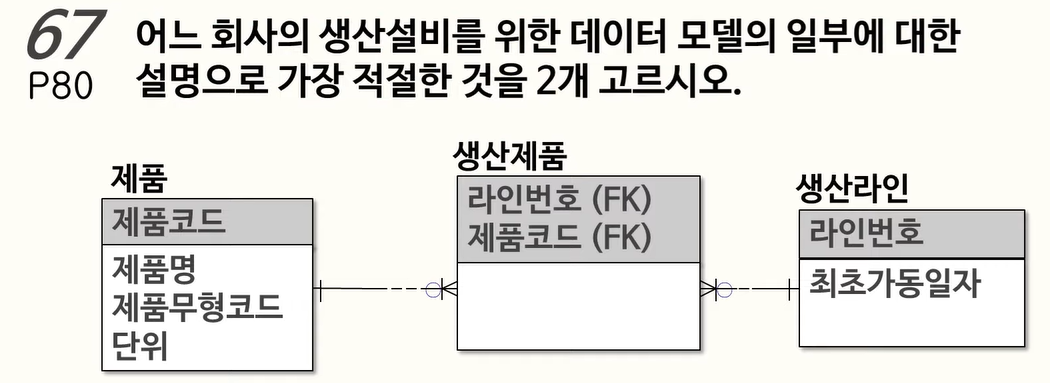


2개의 INNER JOIN이면 됨
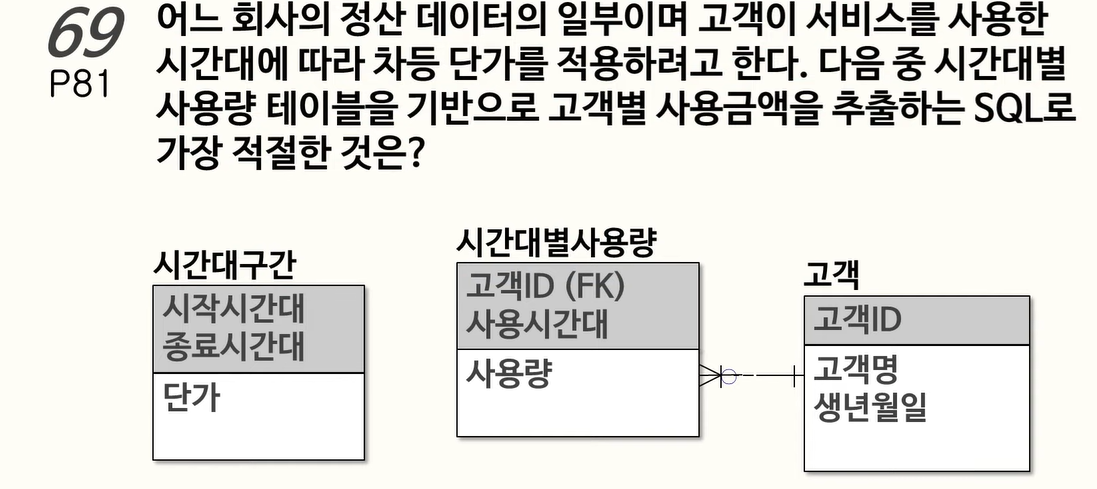
69. 데이터 모델과 JOIN

70. USING & ON & WHERE


Join 시 Using 과 On 비교
department 테이블
| dept_id | description |
|---|---|
| 1 | Accounting |
| 2 | Finance |
| 3 | Research and Development |
| 4 | Marketing |
| 5 | Sales |
employees 테이블
| employee_id | dept_id | first_name | last_name |
|---|---|---|---|
| 1 | 1 | John | Smith |
| 2 | 4 | Peter | Maybank |
| 3 | 5 | Samantha | Savoy |
| 4 | 2 | Evan | Baxter |
| 5 | 3 | Kamila | Erdos |
select *
from employees as e
inner join departments as d
on e.dept_id = d.dept_id;
On을 이용한 조인 질의 결과는 두 테이블의 모든 컬럼이 결과로 산출
| employee_id | dept_id | first_name | last_name | dept_id | description |
|---|---|---|---|---|---|
| 1 | 1 | John | Smith | 1 | Accounting |
| 2 | 4 | Peter | Maybank | 4 | Marketing |
| 3 | 5 | Samantha | Savoy | 5 | Sales |
| 4 | 2 | Evan | Baxter | 2 | Finance |
| 5 | 3 | Kamila | Erdos | 3 | Research and Development |
5 rows & 6 columns
select *
from employees as e
inner join departments as d using (dept_id);
Using을 이용한 조인 질의 결과는 중복된 컬럼인 dept_id는 한번만 산출
| dept_id | employee_id | first_name | last_name | description |
|---|---|---|---|---|
| 1 | 1 | John | Smith | Accounting |
| 4 | 2 | Peter | Maybank | Marketing |
| 5 | 3 | Samantha | Savoy | Sales |
| 2 | 4 | Evan | Baxter | Finance |
| 3 | 5 | Kamila | Erdos | Research and Development |
5 rows & 5 columns
USING의 경우 동등 조인을 수행하고 오직 컬럼명이 같을 경우에 사용할 수 있기 때문에, 같은 컬럼을 중복하여 포함시킬 필요가 없는 것.
The dept_id column, the column we're joining the two tables on, only appears once in the output. Why? Because USING performs an equality join and can only be used when the column names are identical, it's unnecessary to include the column twice. A nice side-effect of this is convenience - when you're using USING, if you want to refer to the column in your SELECT clause or elsewhere, you don't need to prefix the column name with the table name!

ON과WHERE의 차이
SQL문 순서는FROMONJOINWHERE, 즉 ON이 WHERE보다 순서상으로 더 빠름
Inner Join의 경우 존재하는 값에 대해서만 출력하기 때문에 조건의 위치나 테이블의 순서와 상관없이 같은 실행계획으로 같은 값이 출력
Outer Join의 경우
71. CROSS JOIN & Cartesian Product

72. 표준 조인
LEFT OUTER JOIN
조인 수행시 먼저 표기된 좌측 테이블에 해당하는 데이터를 먼저 읽은 후, 나중에 표기된 우측 테이블에서 JOIN 대상 데이터를 읽어 온다. 즉, A와 B를 비교해서 B의 JOIN 칼럼에서 같은 값이 있을 때 그 해당 데이터를 가져오고, B의 칼럼에서 같은 값이 없는 경우 B 테이블에서 가져오는 칼럼들은 NULL로 채운다.


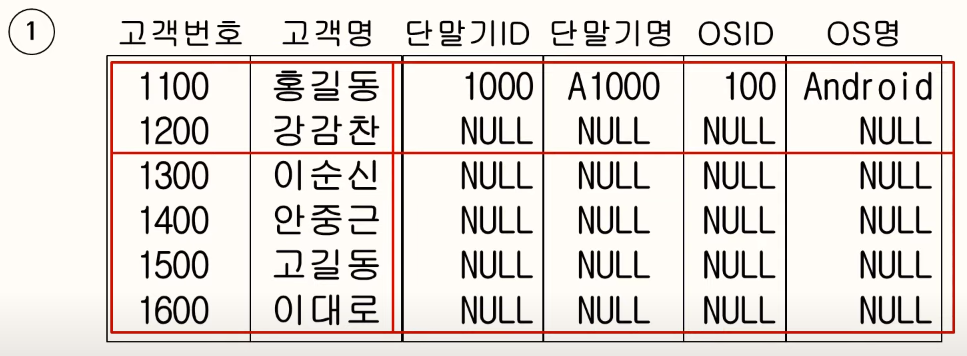

73. FULL OUTER JOIN

77.표준조인 ORACLE vs SQL Server
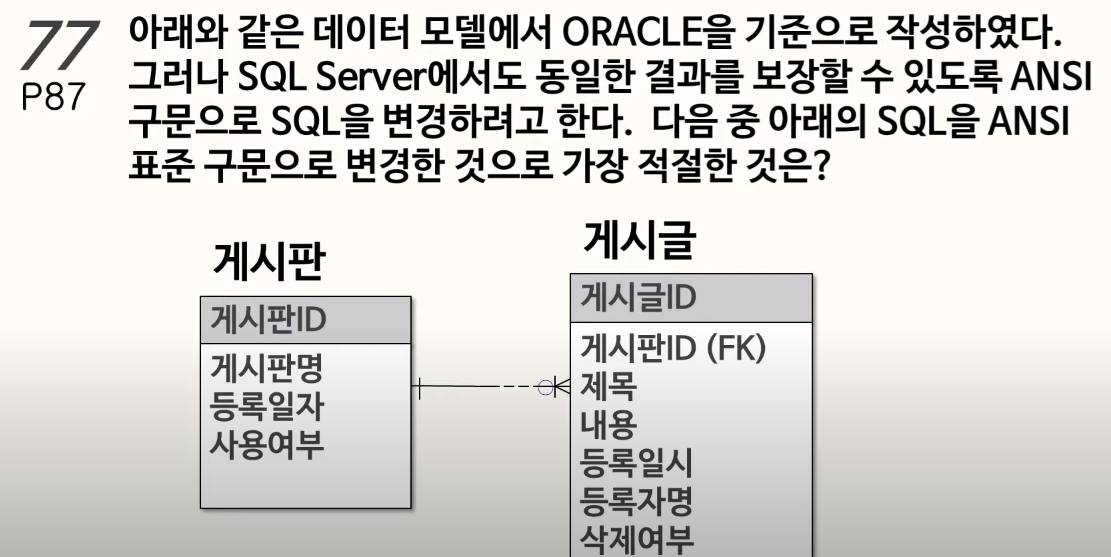



79. EXCEPT
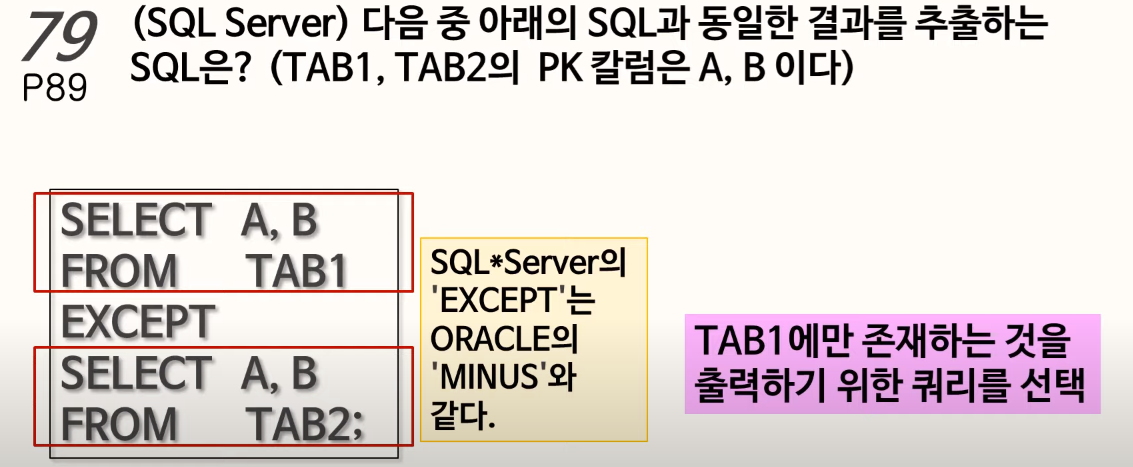
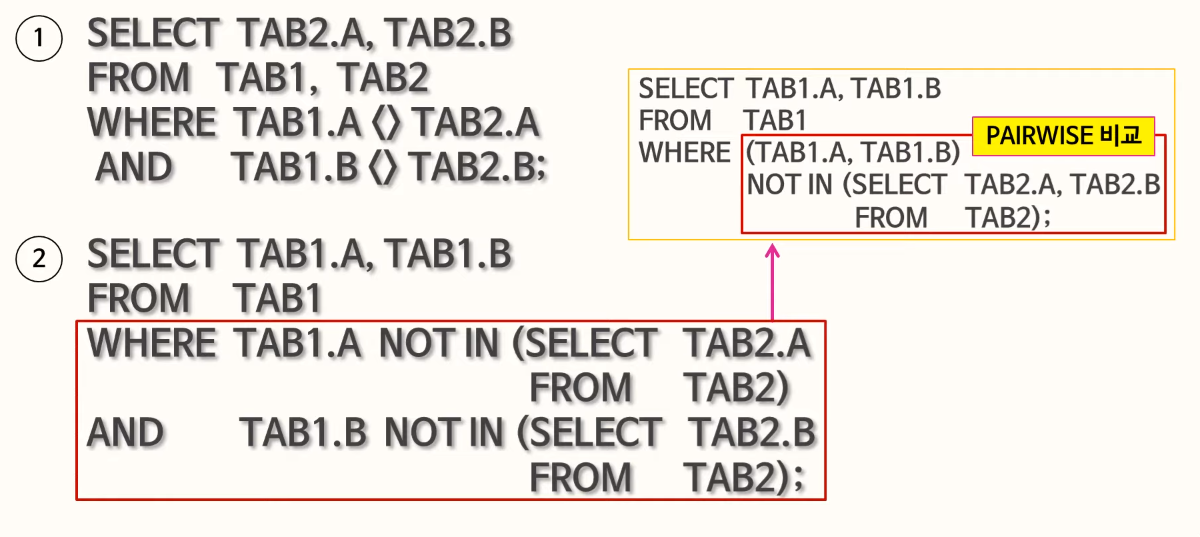
pairwise 형태로 비교해야됨!
80. SUBQUERY & 집합연산자 INTERSECT
INTERSECT는 결과의 교집합으로 중복된 행을 하나의 행으로 표시!
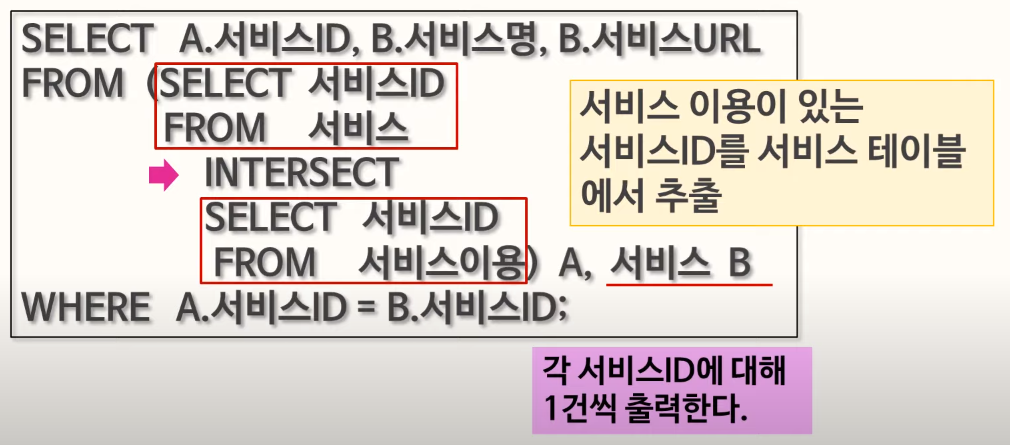
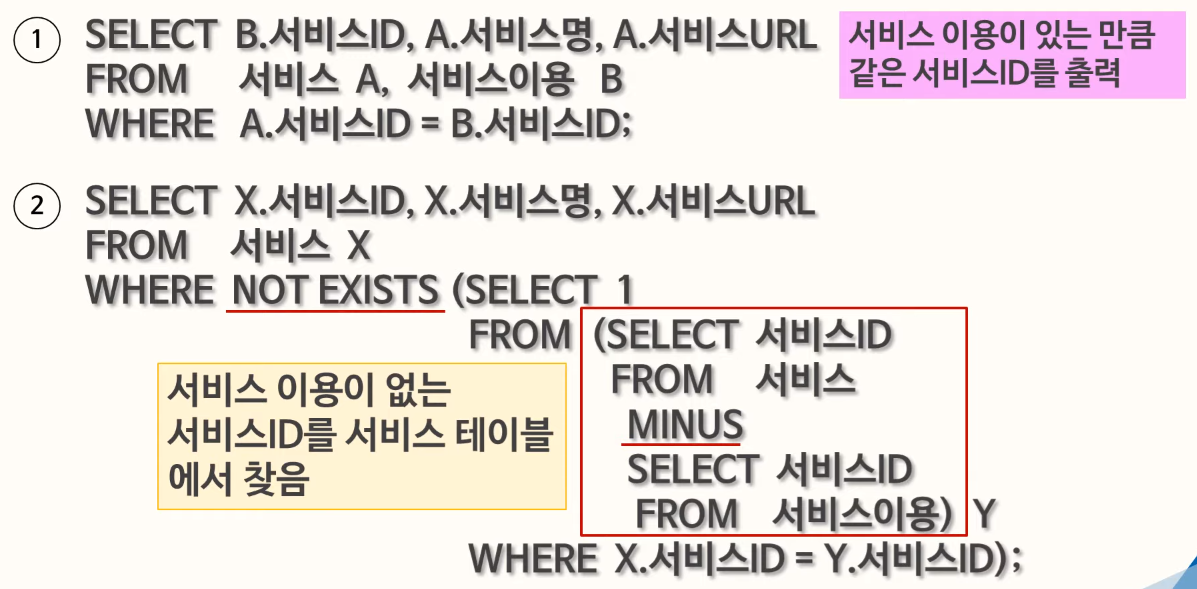
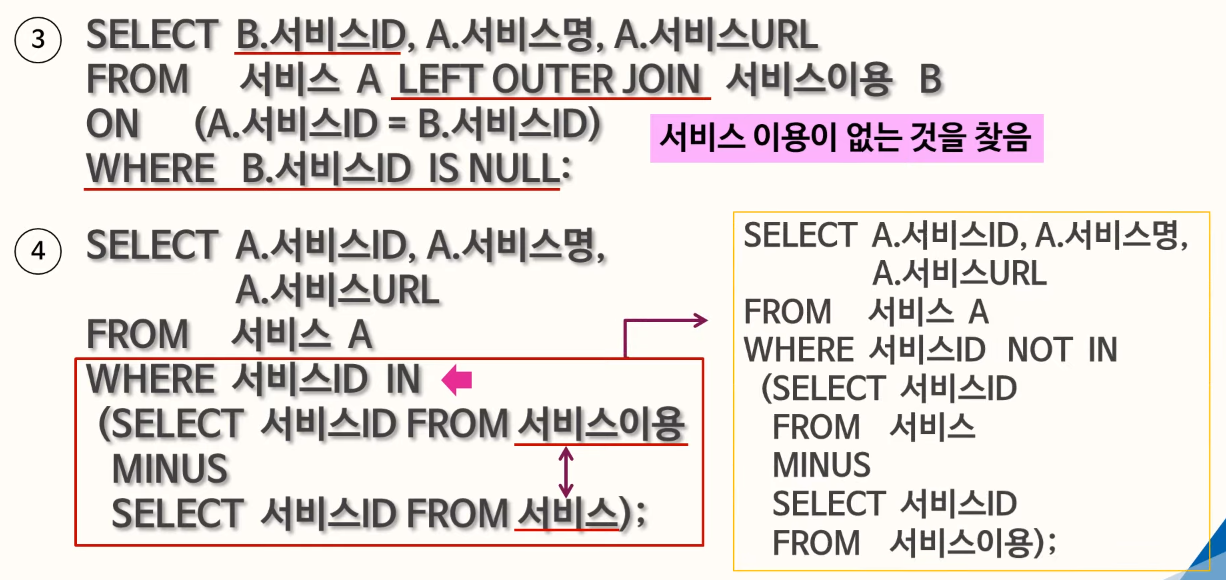
82. 집합연산자

Query1의 별칭으로 출력되야하고, ENAME, JOB의 오름차순으로 정렬되야
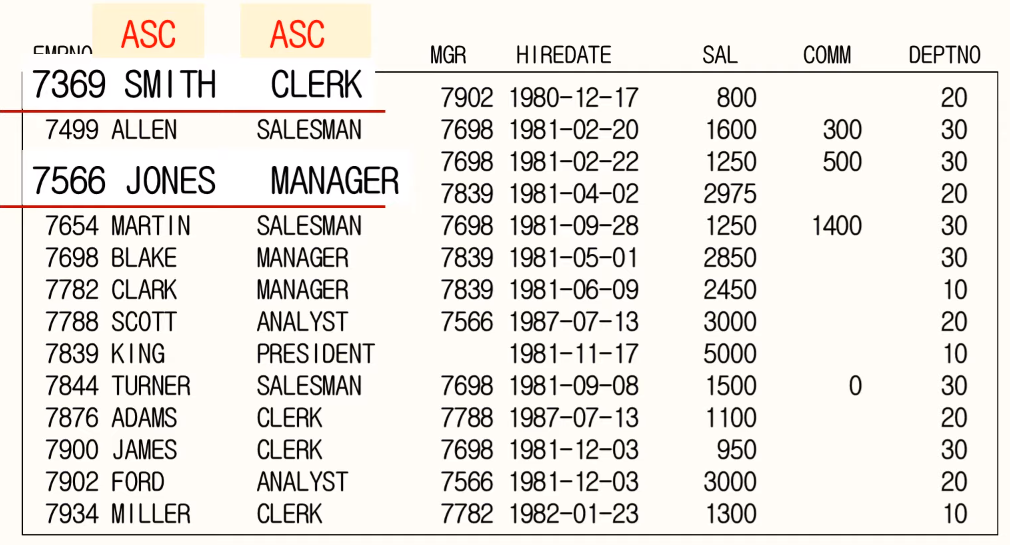
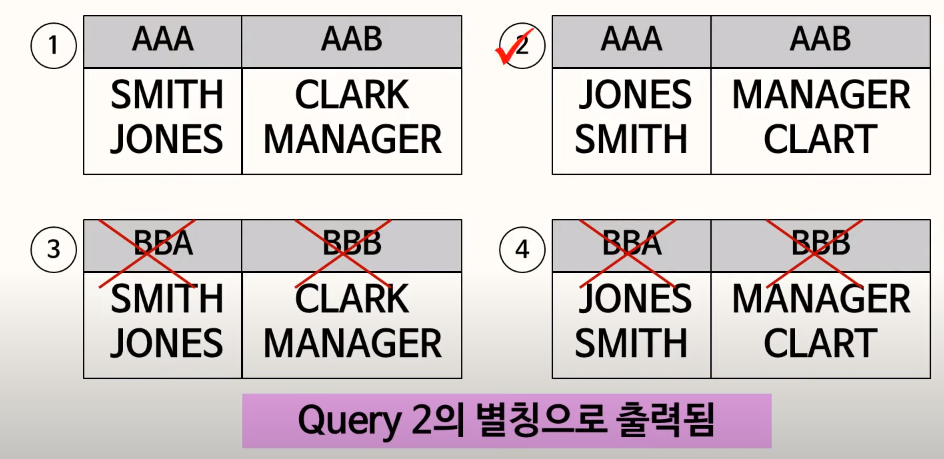
83. 집합연산자의 연산 순서
집합연산자는 SQL에서 위에 정의된 연산자가 먼저 수행된다. 그러므로 UNION이 나중에 수행되므로 결과적으로 중복 데이터가 모두 제거되어 수행

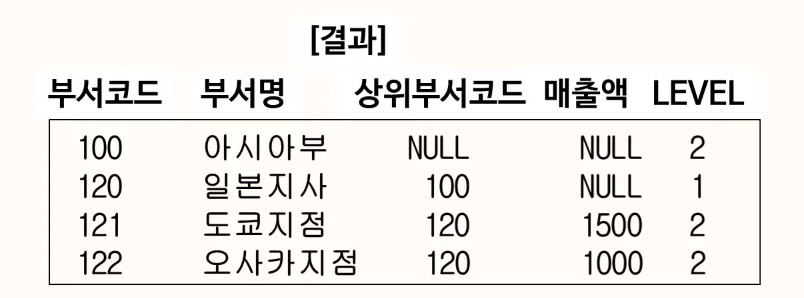
87. 계층형 질의
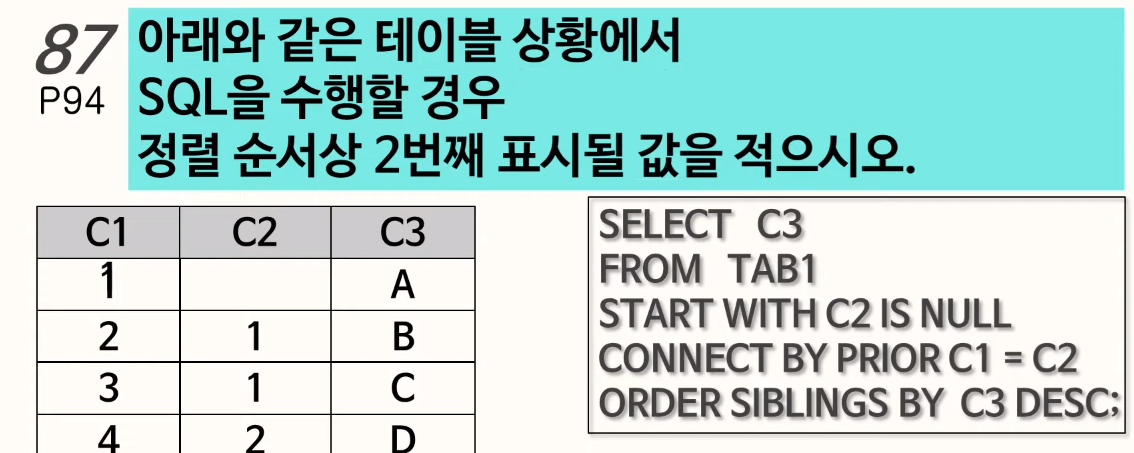
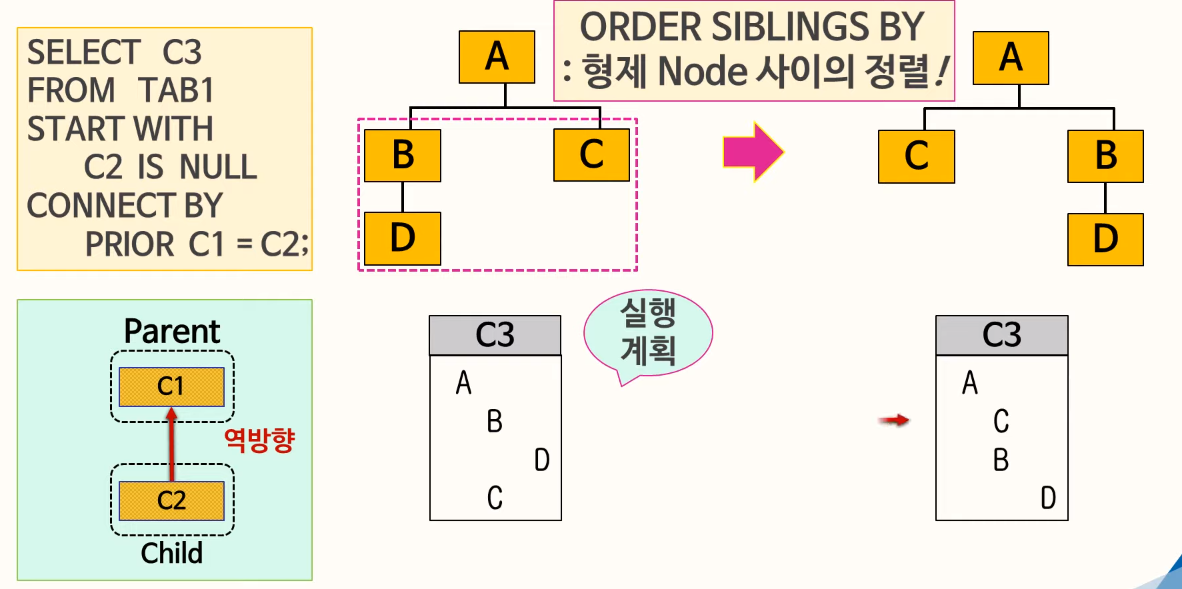
START WITH 절은 계층 구조 전개의 시작 위치를 지정하는 구문이다. 즉, 루트 데이터를 지정한다(액세스)
PRIOR : CONNECT BY 절에 사용되며, 현재 읽은 칼럼을 지정한다.
PRIOR 자식 = 부모 형태를 사용하면 계층구조에서 부모데이터에서 자식데이터(부모 -> 자식) 방향으로 전개하는 순방향 전개를 한다. 그리고 PRIOR 부모 = 자식 형태를 사용하면 반대로 자식 데이터에서 부모 데이터(자식 -> 부모) 방향으로 전개하는 역방향 전개를 한다.
ORDER SIBLINGS BY: 형제 노드(동일 LEVEL) 사이에서 정렬을 수행한다.
(22.02.26)
88. ORACLE 계층형 질의
루트노드의 LEVEL 값은 1
89. SQL 계층형 질의
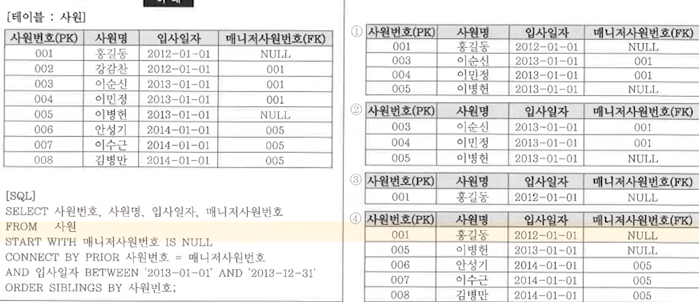
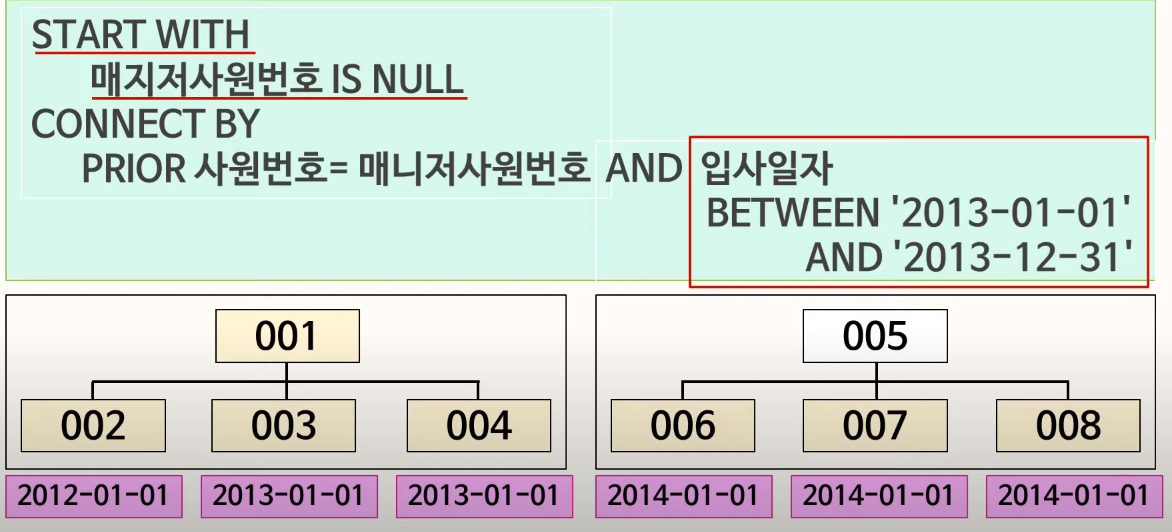
CONNECT BY PRIOR 사원번호 = 매니저사원번호
부모의 사원번호가 자식의 매니저 사원번호와 같은 애들을 방향으로 계층화
90. 계층형 질의
- SQL Server에서의 계층형 질의문은 CTE(Common Table Expression)를 재귀 호출함으로써 계층 구조를 전개한다.
- SQL Server에서의 계층형 질의문은 앵커 맴버를 실행하여 기본 결과 집합을 만들고 이후 재귀 맴버를 지속적으로 실행한다.

- 오라클의 계층형 질의문에서 WHERE 절은 모든 전개를 진행한 이후 필터 조건으로서 조건을 만족하는 데이터만을 추출하는데 활용된다.
- 오라클의 계층형 질의문에서 PRIOR 키워드는
CONNECT BY 절에만 사용할 수 있으며'PRIOR 자식 = 부모' 형태로 사용하면 순방향 전개로 수행 된다.- PRIOR 키워드는 SELECT, WHERE 절에서도 사용할 수 있음.
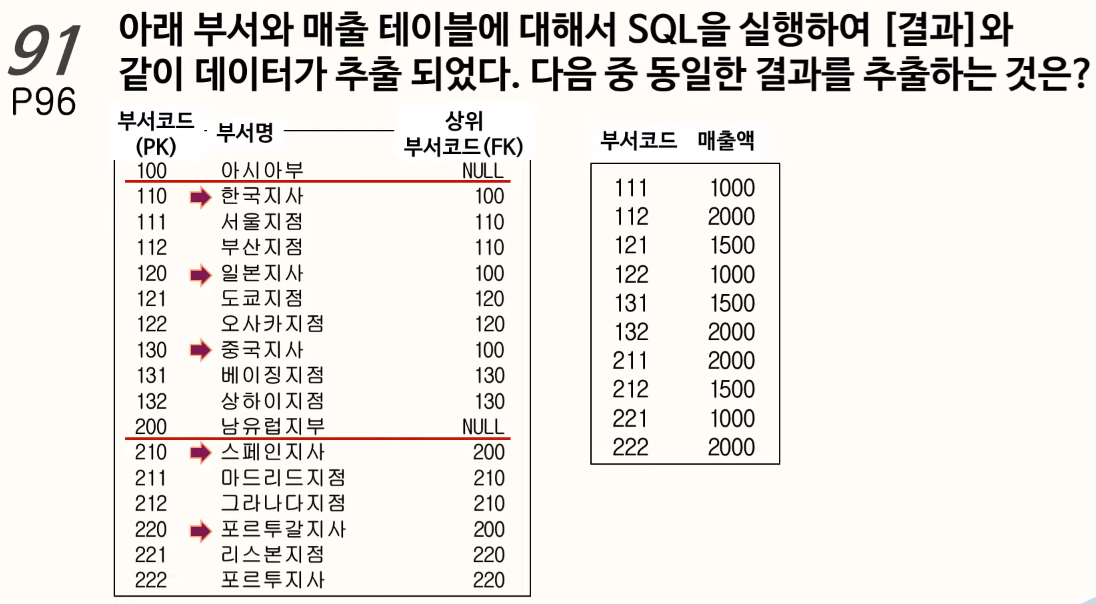
91. 계층형 질의
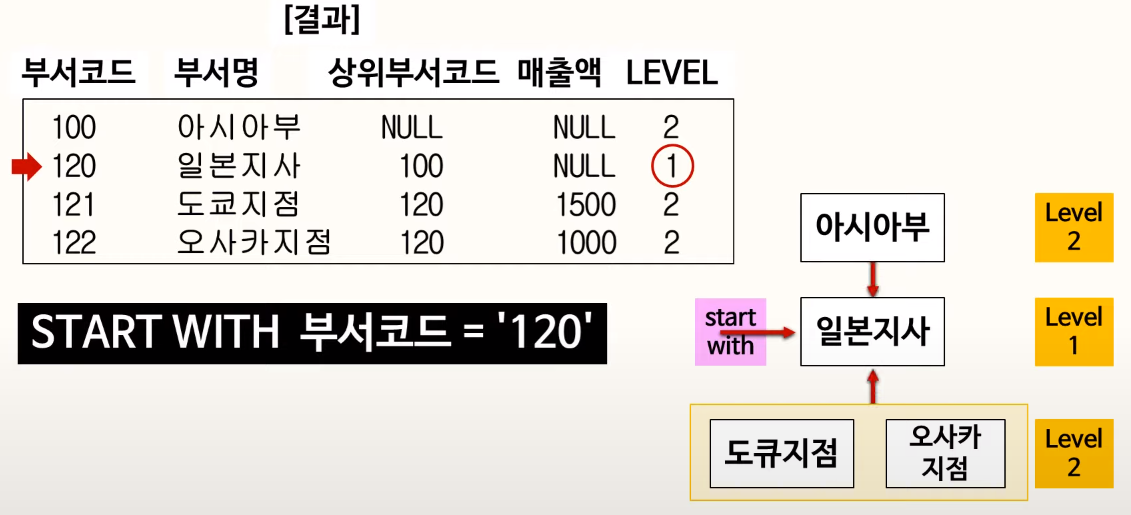

92. 셀프조인
한 테이블에서 두 칼럼이 연관 관계가 있을 때 사용한다.
FROM 절에 동일 테이블이 두 번 이상 나타난다. 동일 테이블 사이의 조인을 수행하면 테이블과 칼럼 이름이 모두 동일하기 때문에 식별을 위해서는 반드시 테이블 별칭 Alias를 사용해야 한다.
(22.02.27)
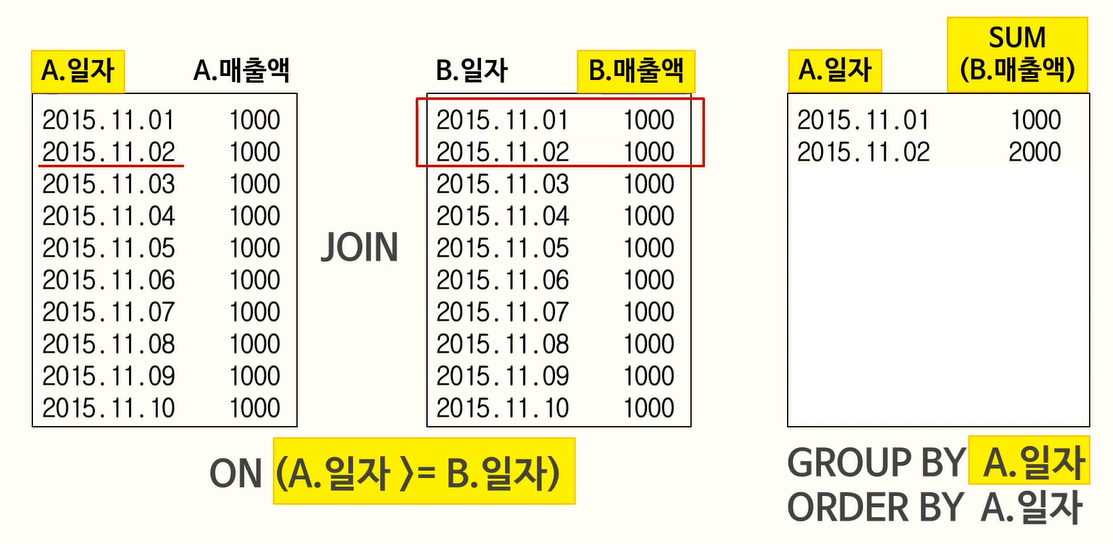
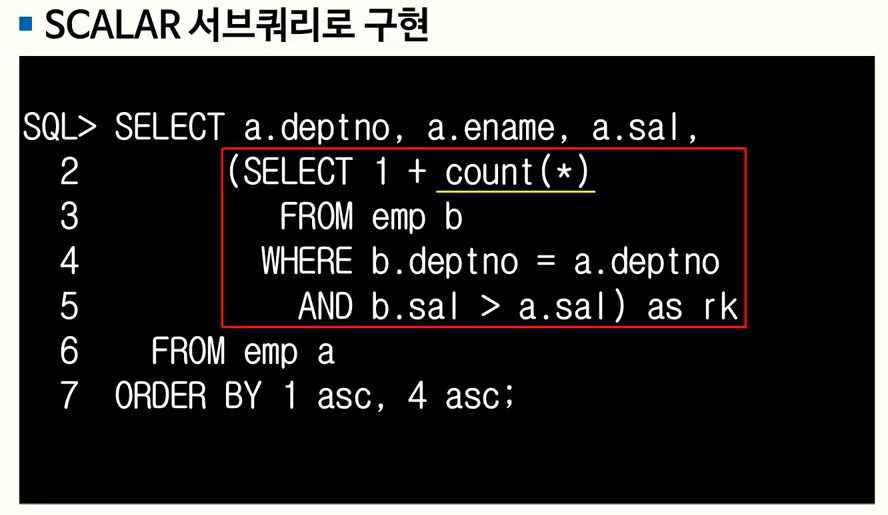
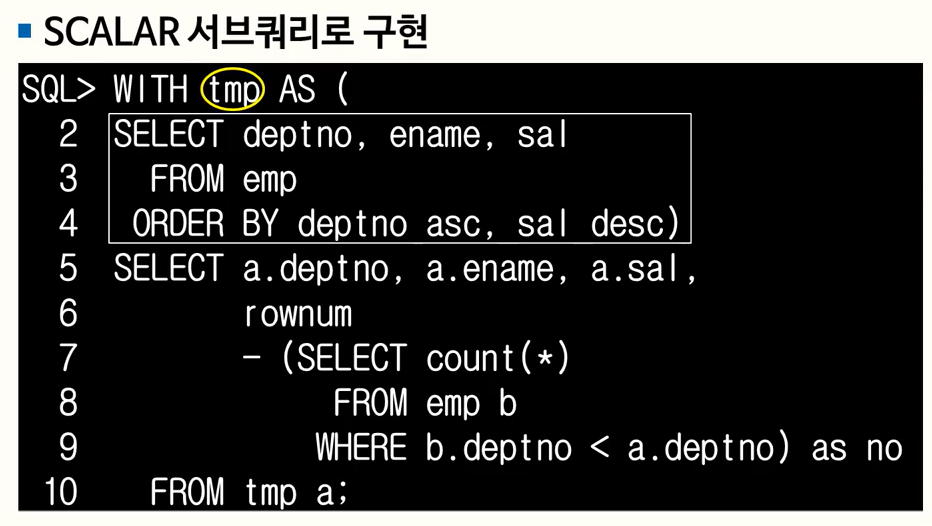
93. 누적값 처리
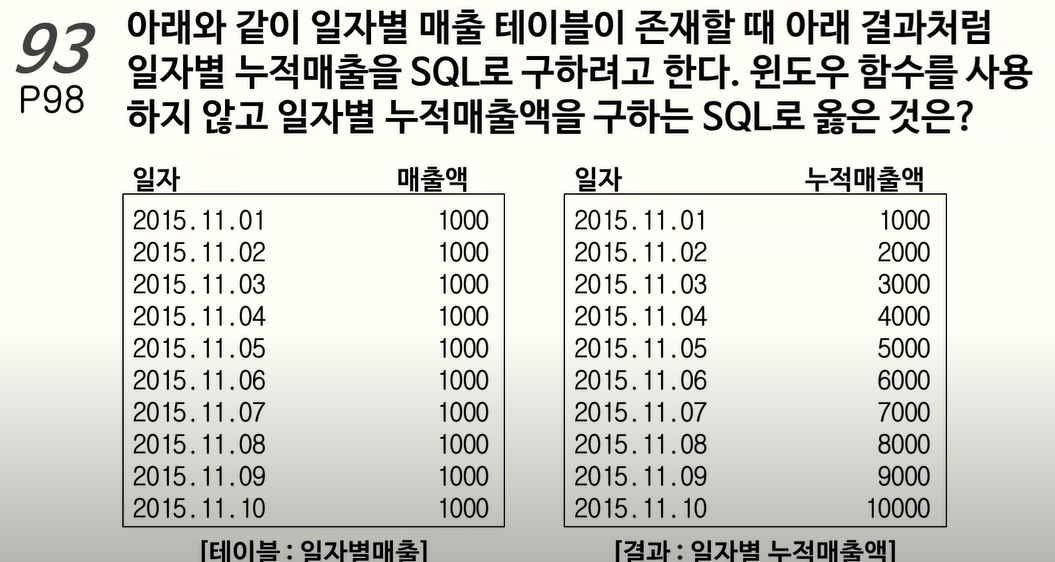
크게 두가지 방법 : 하나는 셀프 조인, 하나는 스칼라 서브 쿼리 활용

- 셀프 조인 방식이나 방법 오류

- 정답

- 스칼라 서브쿼리를 활용하였으나 부등호 방향 오류
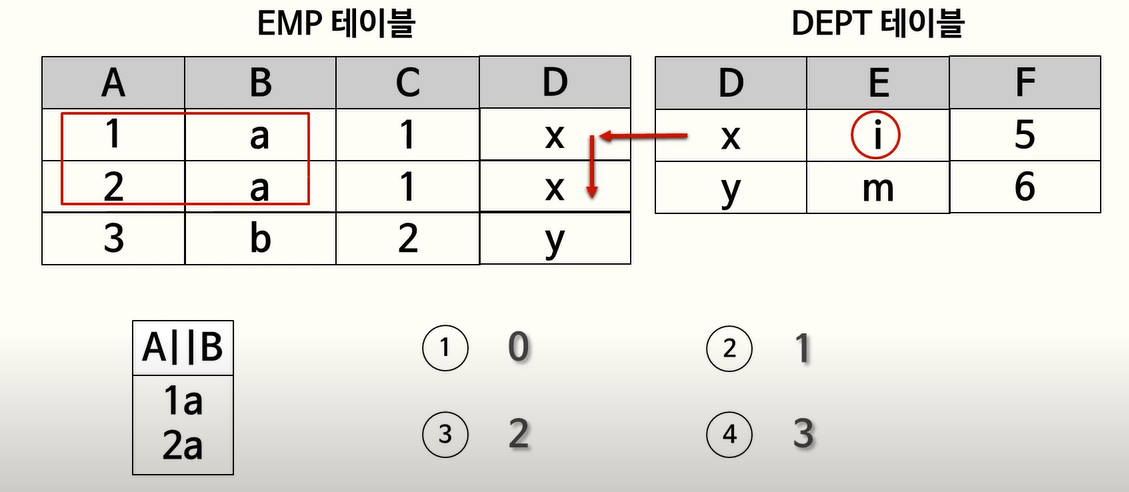
94. 서브쿼리, A || B
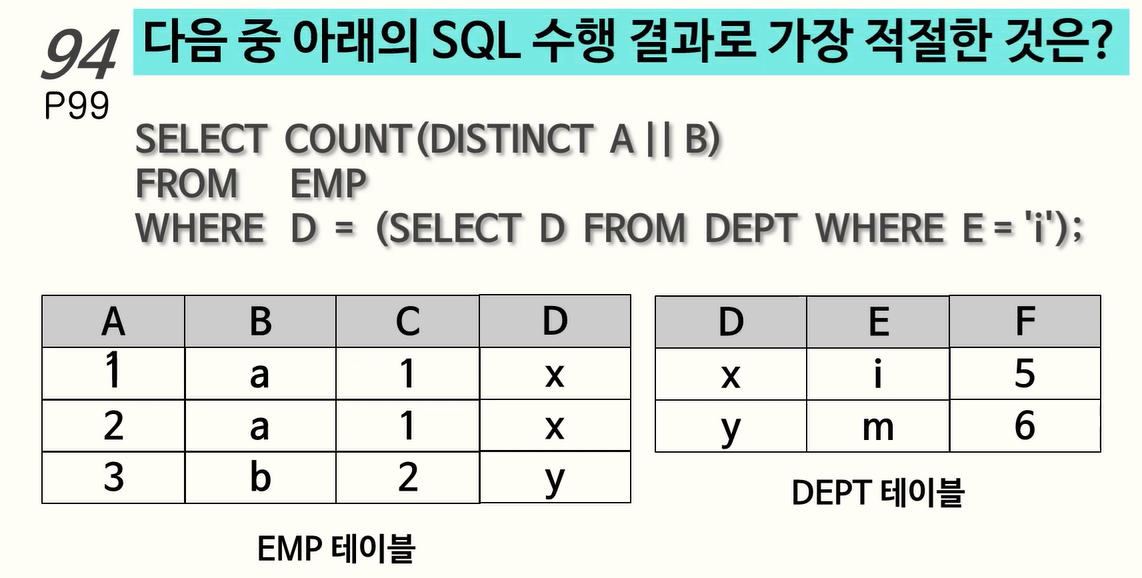
A || B 는 연결연산자로 A: 1, B: a 이면 A||B는 1a
95. 서브쿼리에 대한 설명
- 서브쿼리는 단일 행 또는 복수 행 비교 연산자와 함께 사용할 수 있다.
- 서브쿼리는 SELECT 절, FROM 절, HAVING 절, ORDER BY 절 등에서 사용이 가능하다. (GROUP BY 절에는 서브쿼리 사용불가)
- 서브쿼리의 결과가
복수 행(Multi Row)결과를 반환하는 경우에는 '=', '<=', '=>' 등의 연산자와 함께 사용이 가능하다. (해당 연산자는 단일 행 연산자만 사용 가능, IN, ALL, ANY 연산자와 사용 가능) - 연관(Correlated) 서브쿼리는 서브쿼리가 메인쿼리의 컬럼을 포함하고 있는 형태의 서브쿼리
- 다중 컬럼 서브쿼리는 서브쿼리의 결과로 여러 개의 컬럼이 반환되어 메인 쿼리의 조건과 동시에 비교하는 것을 의미하며 ORACLE과
SQL Server등의 DBMS에서 사용할 수 있다. (SQL Server에서는 다중 컬럼 서브쿼리를 사용할 수 없음)다중 컬럼 서브쿼리란 서브 쿼리의 결과가 여러 컬럼의 데이터를 출력해주는 서브쿼리
97. 서브쿼리 사용시 주의사항
- 서브쿼리를 괄호로 감싸서 사용
- 서브쿼리는 단일 행 또는 복수 행 비교 연산자와 함께 사용 가능 (단일 행 비교 연산자는 서브쿼리의 결과가 반드시 1건)
- 서브쿼리에서는 ORDER BY를 사용하지 못한다. ORDER BY절은 SELECT절에서 오직 한 개만 올 수 있기 때문에 ORDER BY절은 메인 쿼리의 마지막 문장에 위치
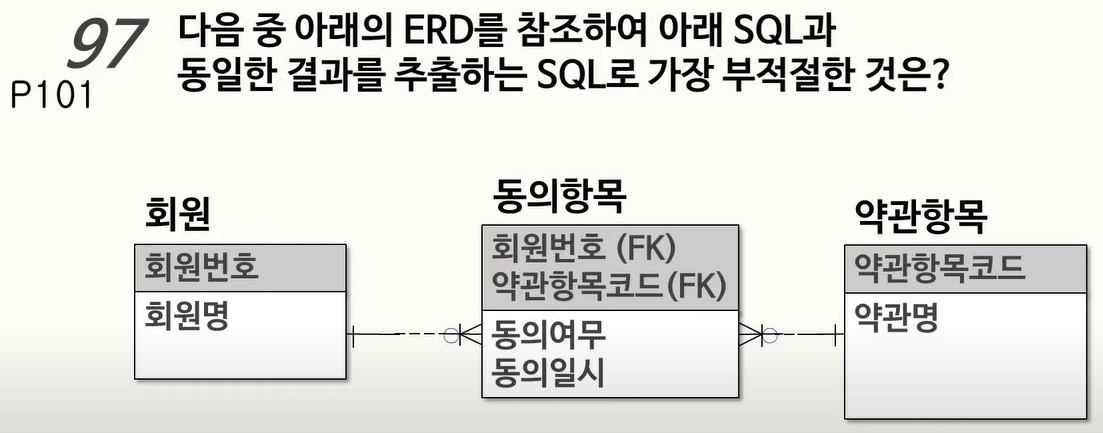


98. 연관 서브쿼리와 Nested 서브쿼리
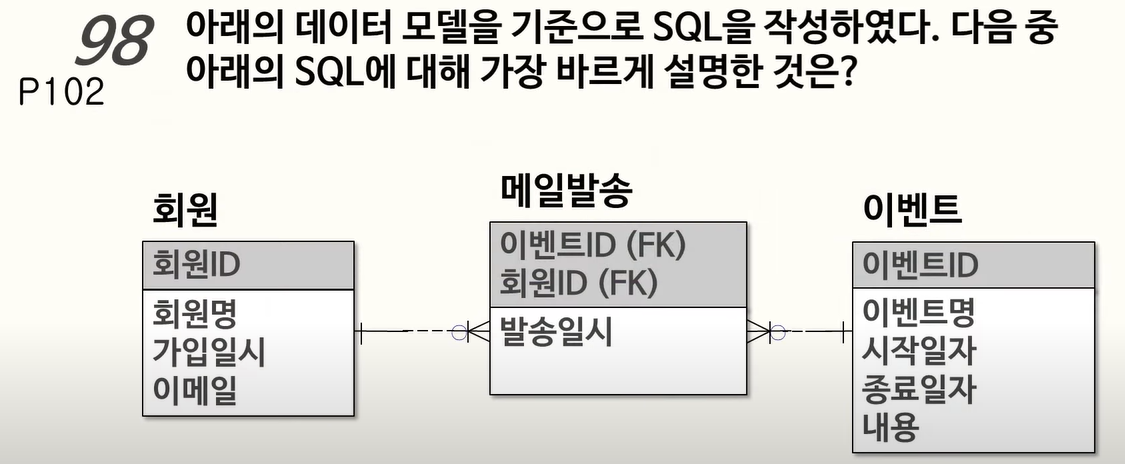

메인 쿼리에서 참조한 회원 A 컬럼을 서브쿼리에서 활용하므로 연관 서브쿼리


99. 연관 서브쿼리와 메인 쿼리의 관계

101. 서브쿼리, 인라인뷰
FROM 절에서 사용되는 서브쿼리를 인라인뷰(Inline view)라고 한다. 서브쿼리의 결과가 마치 실행 시에 동적으로 생성된 테이블인 것처럼 사용할 수 있다. 인라인뷰는 SQL문이 실행될 때만 임시적으로 생성되는 동적인 뷰이기 떄문에 데이터베이스에 해당 정보가 저장되지 않는다. 서브쿼리의 결과가 마치 실행 시에 동적으로 생성된 테이블인 것처럼 사용할 수 있다.
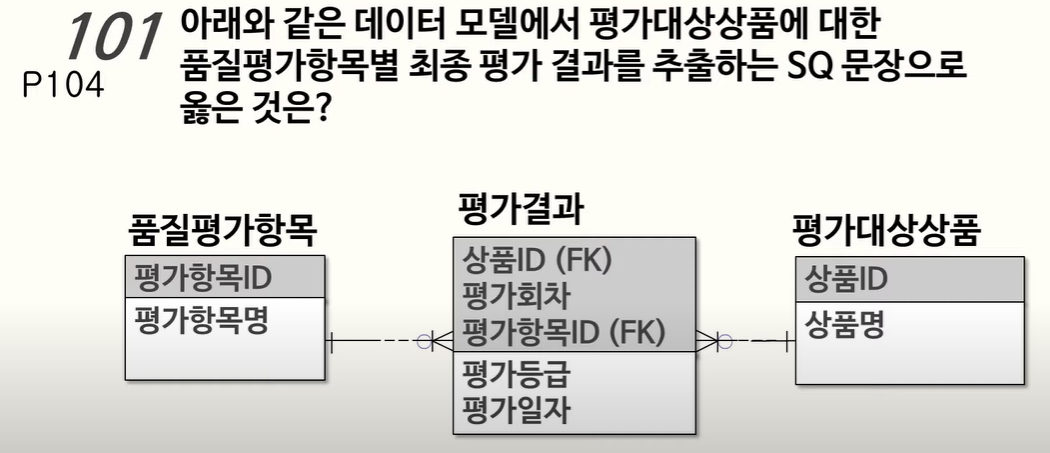

하나의 평가 항목에 평가등급이 기대수준 이하일 경우 재평가를 수행하여 평가회차가 증가하고 평가등급이 갱신되는 데이터를 찾는 쿼리가 필요함!

102. 서브쿼리를 활용한 UPDATE

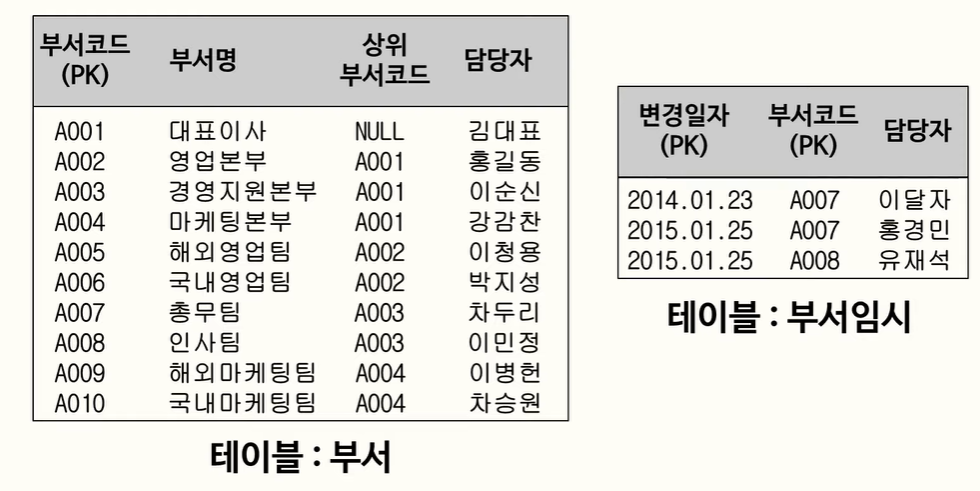
담당자를 바꾸기 위해 부서코드를 SELECT하는건 말이 안됨

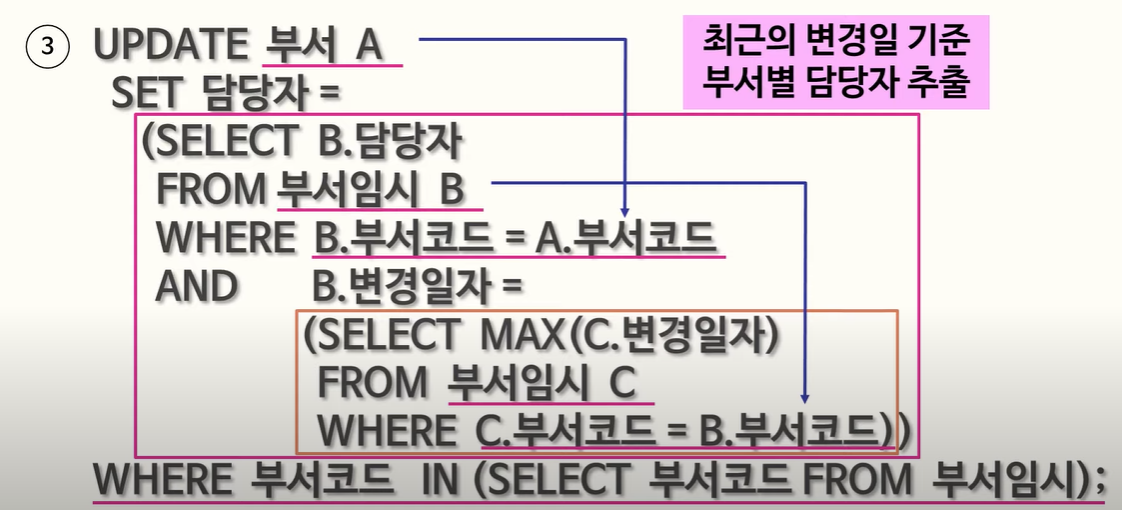
103. 뷰에 대한 설명
- 뷰는 복잡한 SQL 문장을 단순화 시켜주는 장점이 있는 반면, 테이블 구조가 변경되면
응용 프로그램을 변경해 주어야 한다.- 독립성은 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램을 변경하지 않아도 된다.
- 실제 데이터를 저장하고 있는 뷰를 생성하는 기능을 지원하는 DBMS도 있다.
105. GROUPING, NVL, ROLLUP
- NVL :
NVL(e1, e2)e1이 NULL 이면 e2 반환, e1이 NON NULL 이면 e1 반환- ROLLUP :
GROUP BY ROLLUP(A,B)
- (A, B) : A와 B를 기준으로 GROUP BY 해서 카운트한 결과가 나타남
- (A, NULL): A만을 GROUP BY 기준으로 해서 카운트한 결과가 나타남, B는 NULL
- (NULL, NULL): 아무런 기준없이 전체를 GROUP BY 해서 카운트한 결과가 나타남
- GROUPING : GROUP BY 기준이 되는 컬럼의 값이 NULL 일때 1을 리턴, NULL 이 아닐 때 0을 리턴
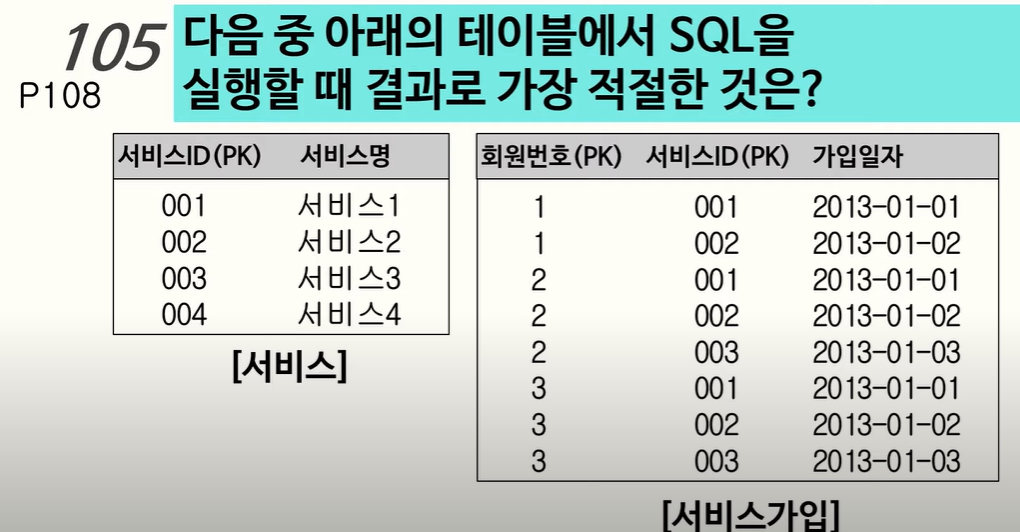

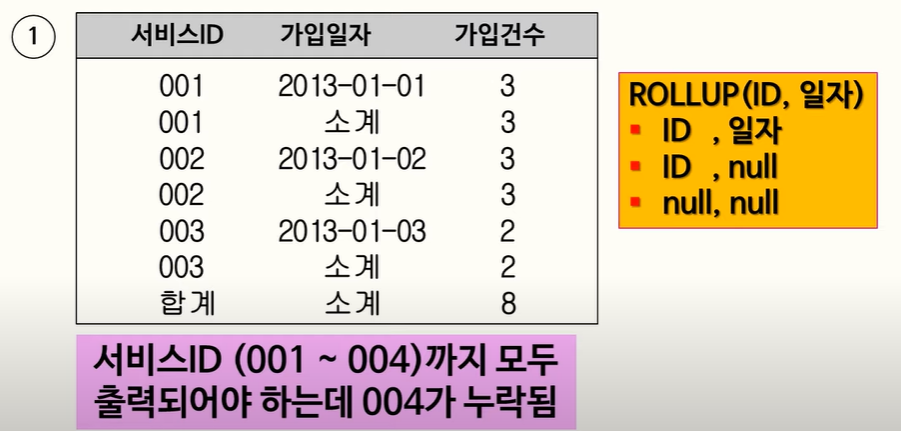
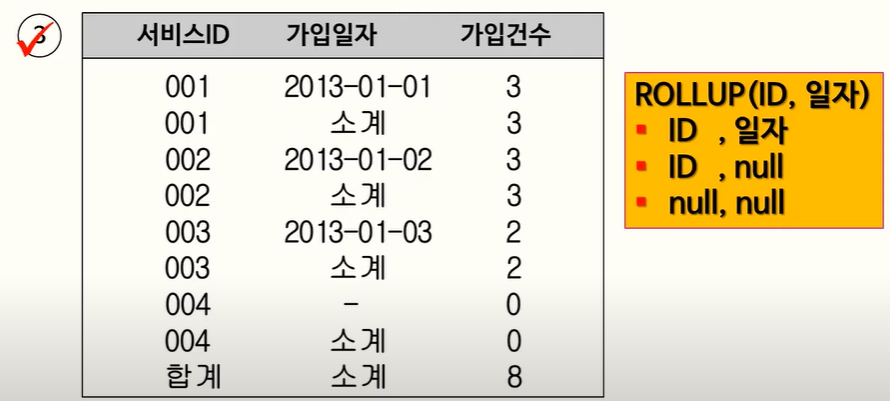
(22.03.01)
106. ROLLUP 과 GROUPING 활용
GROUPING : GROUP BY 기준이 되는 컬럼의 값이 NULL 일때 1을 리턴, NULL 이 아닐 때 0을 리턴, 즉 소계나, 총합등 집계된 데이터의 경우 1을 리턴하고 만약 집계된 데이터가 아니라면 0을 리턴
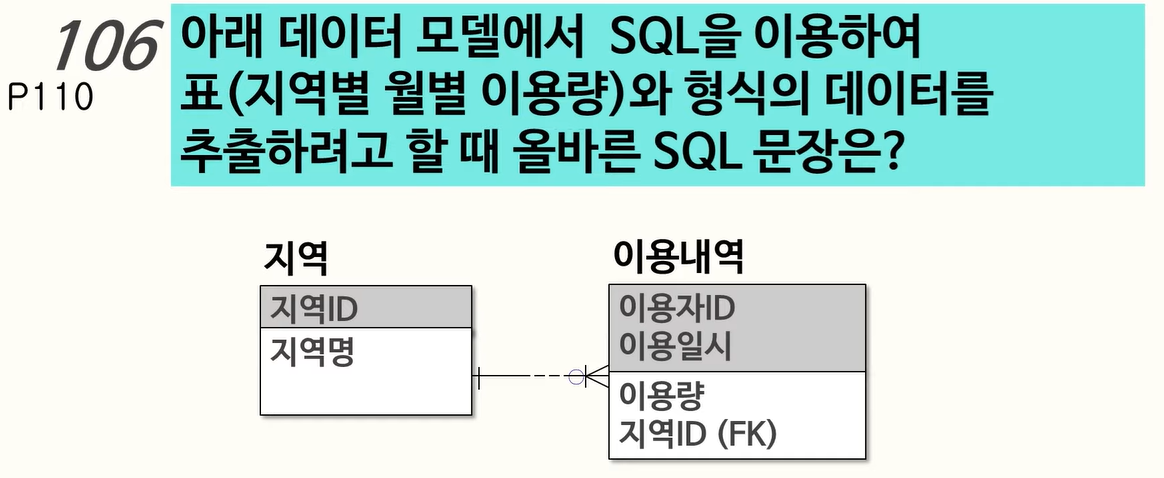
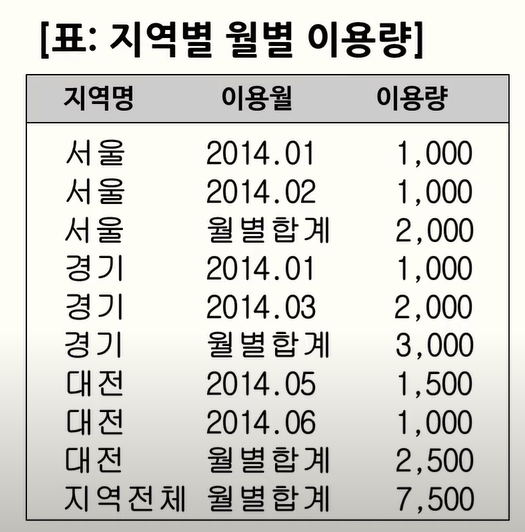

108. ROLLUP, CUBE, GROUPING SETS
- 일반 그룹함수를 사용하여 CUBE, GROUPING SETS와 같은 그룹함수와 동일한 결과를 추출할 수 있으나, ROLLUP 그룹함수와 동일한 결과를
추출할 수는 없다.-> 있음 - GROUPING SETS 함수 경우에는 함수의 인자로
주어진 칼럼의 순서에 따라 결과가 달라지므로칼럼의 순서가 중요하다. -> 달라지지 않음 - CUBE 그룹함수는 인자로 주어진 칼럼의 결합 가능한 모든 조합에 대해서 집계 함수를 수행하므로 다른 그룹함수에 비해 시스템 부하가 크다.
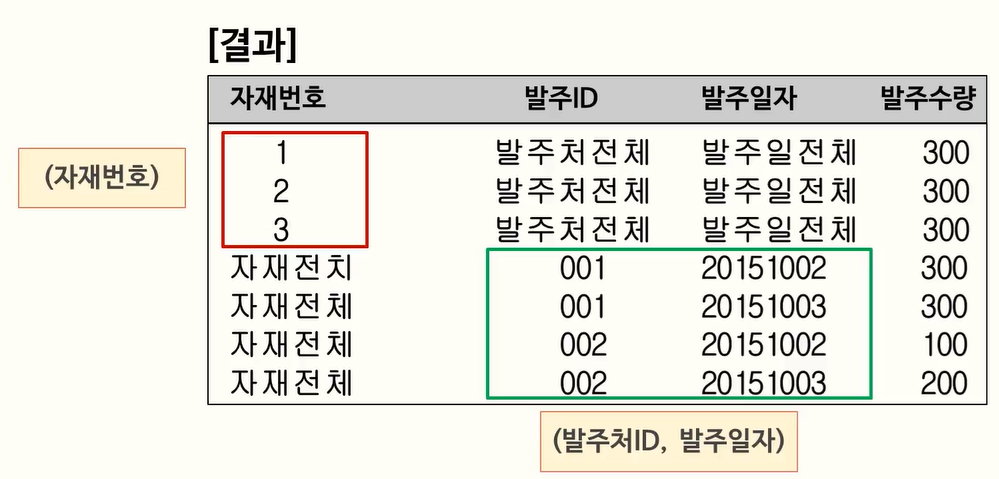
109. CUBE 와 GROUPING SETS 사용법
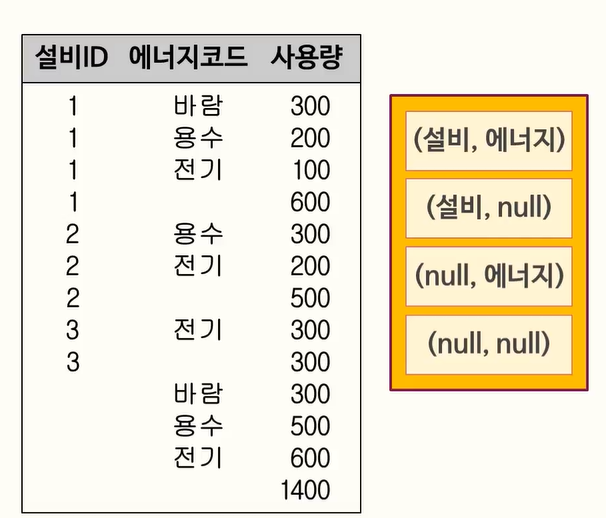


110. GROUP BY GROUPING SETS
(22.03.02, ~111번)
112. 윈도우 함수(Window Function, Analytic Function)
-
Partition 과 Group By 구문은 의미적으로 유사하다.
Partition By: SQL에서 추출한 데이터를 일련의 기준에 의해서 함수의 적용 대상을 구분짓고자 할 때 사용할 수 있는 것
-
Partition 구문이 없으면 전체 집합을 하나의 Partition으로 정의한 것과 동일하다.
-
윈도우 함수 처리로 인해 결과 건수가
줄어든다.윈도우 함수 적용 시 결과 건수는 줄어들지 않음, GROUP 함수 적용시 결과 건수가 줄어듦
-
윈도우 함수 적용 범위는 Partition을 넘을 수 없다.
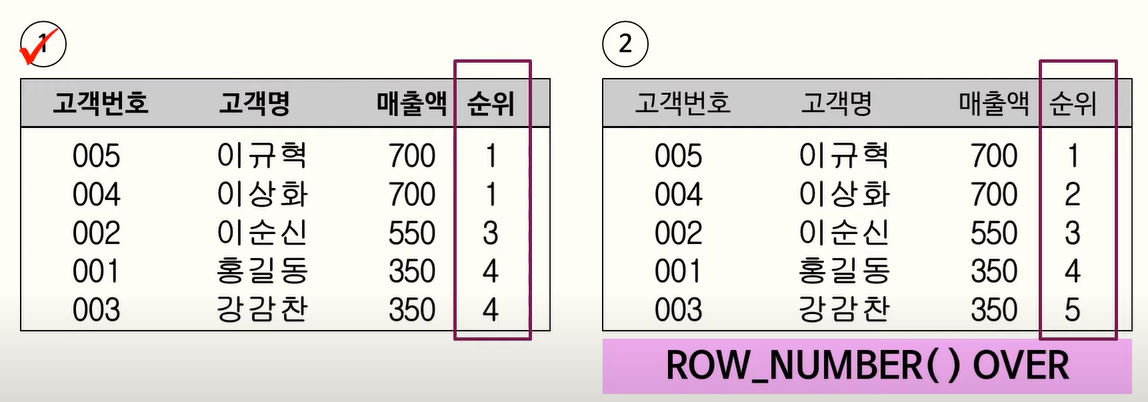
113. RANK 함수
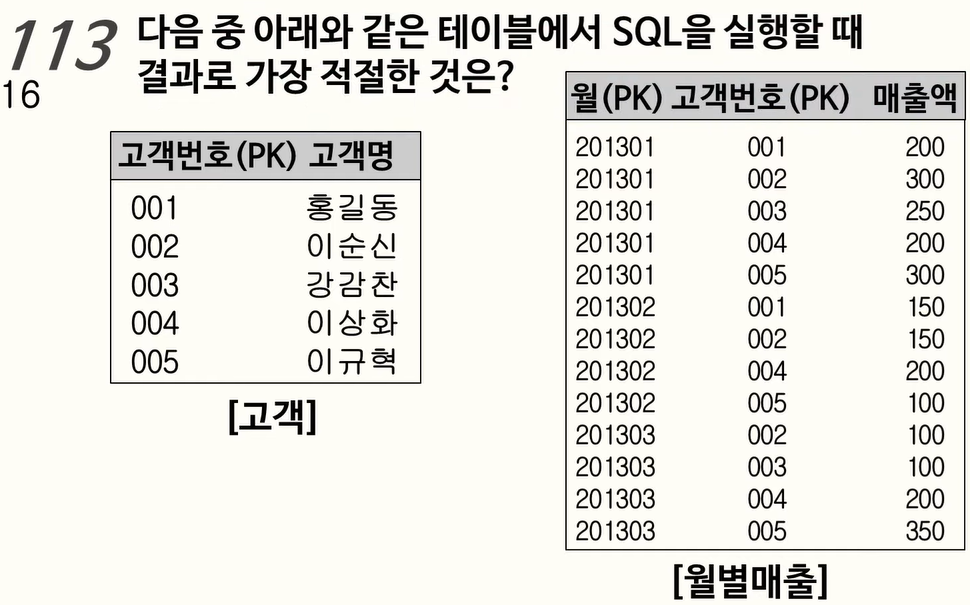
RANK 함수는 ORDER BY를 포함한 QUERY 문에서 특정 항목(칼럼)에 대한 순위를 구하는 함수이며 동일한 값에 대해서는 동일한 순위를 매긴다.

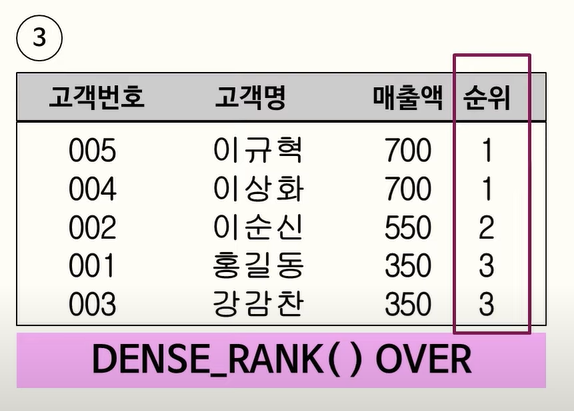
114. Partition BY
| GROUP BY | PARTITION BY | |
|---|---|---|
| 사용 | 그룹 외부에서 묶어 순위 및 그룹별 집계를 구할 떄 사용 | 그룹 내 순위 및 그룹별 집계를 구할 때 사용 |
| 결과값 | 특정 원하는 컬럼에 대해서 추출해 결과값을 보여줌 | 전체 데이터에서 원하는 값을 보여줌 |
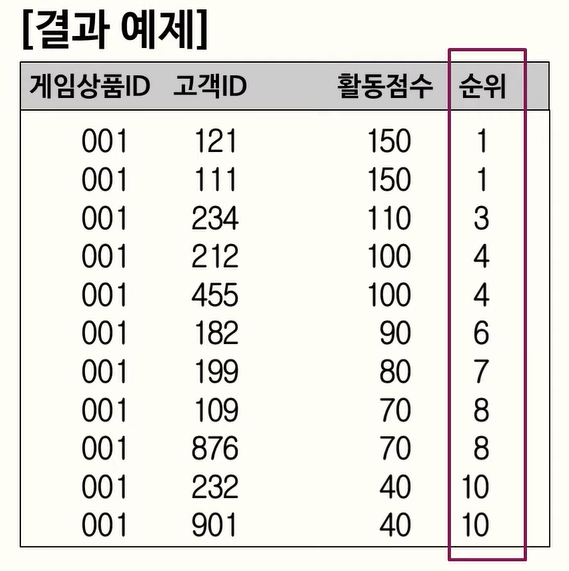
RANK를 잘 사용하고 있으나, 요구사항에서 게임상품ID별로 각각 순위를 매겨야 하므로 오답


115. ROW_NUMBER()
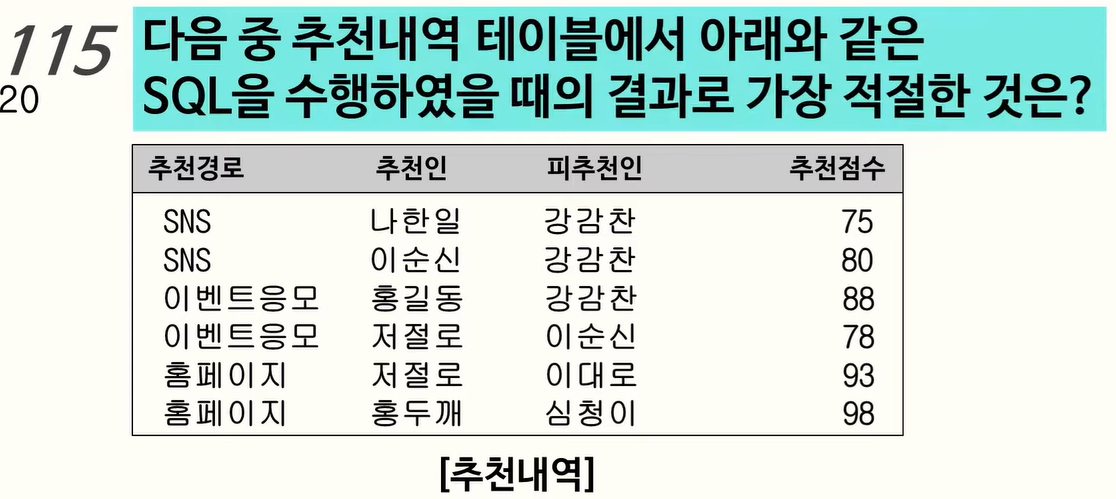

각각의 추천경로별로 1건씩 추출

116. COUNT(*) OVER, RANGE, PRECEDING, FOLLOWING

GROUP BY 절에 의한 GROUP 함수의 값을 구한 뒤 윈도우 함수가 실행되므로 문제가 없음.
그룹함수로 인한 모든 값은 다 처리된 후 윈도우 함수가 실행됨.



WINDOWNING 절
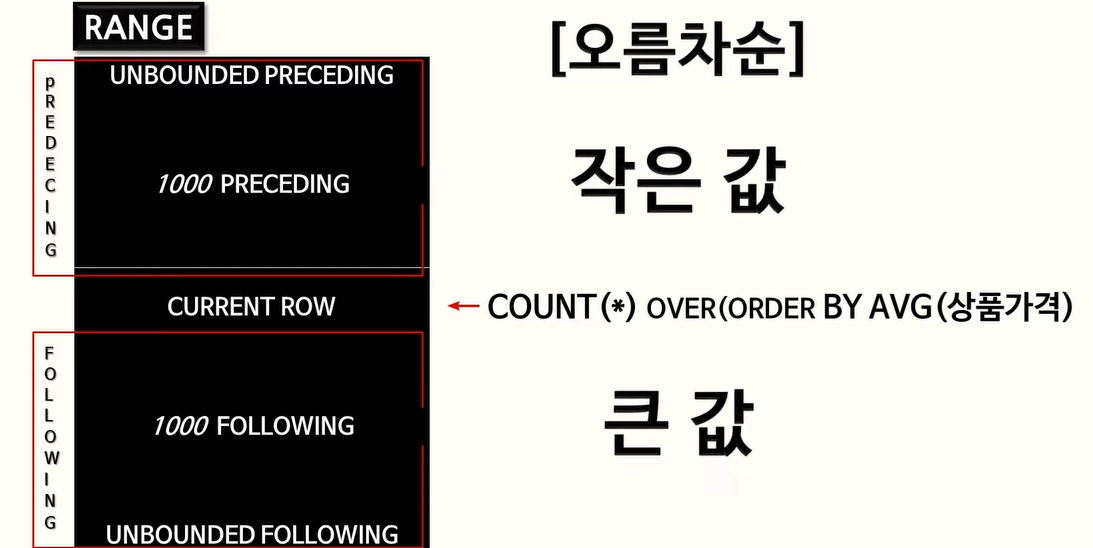
(22.03.03 ~ 116)
118. LAG, LEAD 함수
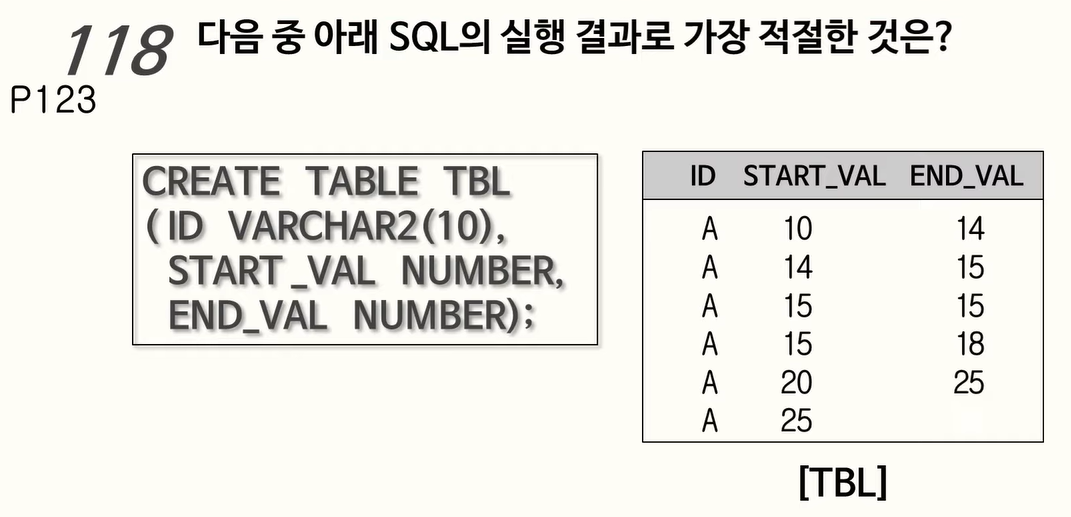

LAG는 바로 앞에껄 찾게하고, LEAD는 바로 뒤에껄 찾게 함.

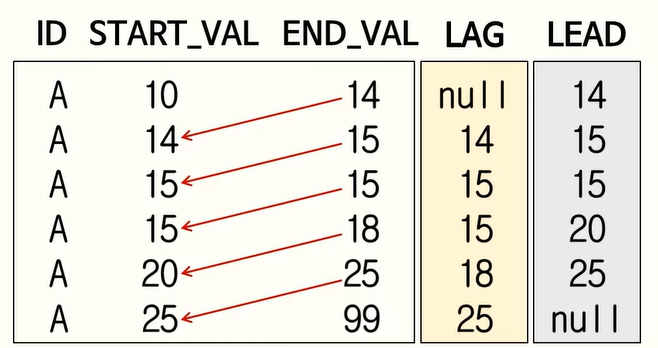
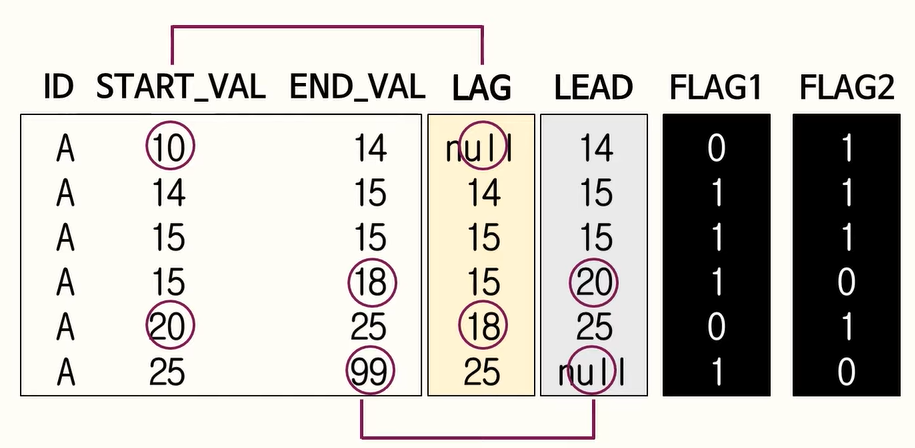
120. GRANT 사용법

GRANT SELECT, UPDATE ON A_User.TB_A TO B_User;
GRANT, REVOKE 사용 예제

121. ROLE

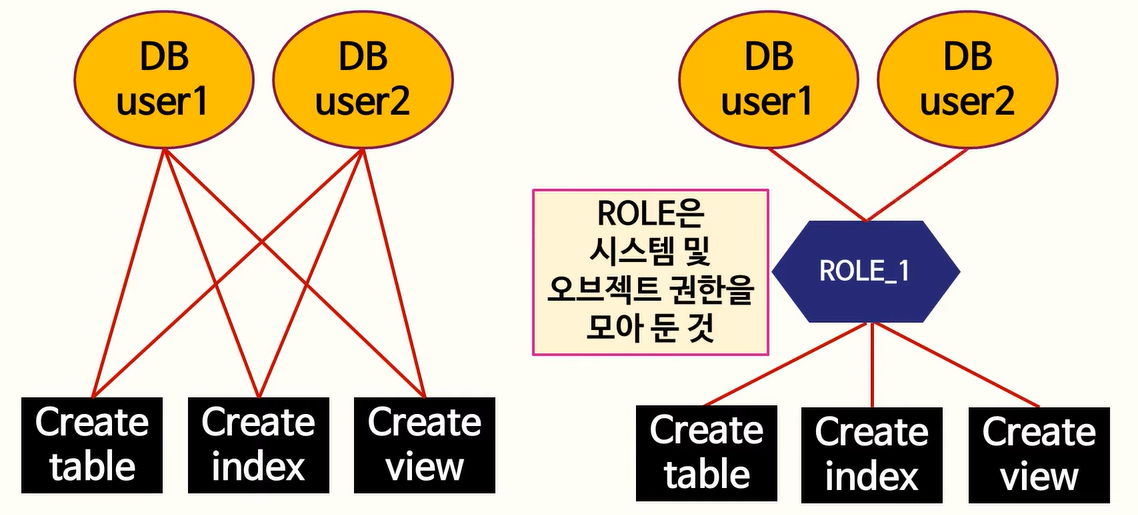
122. WITH GRANT OPTION

WITH GRANT OPTION으로 인해 Kim이 Park에게 권한을 줄 수 있음
123. PL/SQL의 특징
- 변수와 상수들을 사용하여 일반 SQL 문장을 실행할 때 WHERE 절의 조건 등으로 대입할 수 있다. (가능)
- Procedure, User defined function, Trigger 객체를 PL/SQL로 작성할 수 있다. (가능)
- PL/SQL로 작성한 Procedure, User defined function은 전체가
하나의 트랜잭션으로 처리되어야 한다.- 트랜잭션은 분할될 수 있으며, 각 트랜잭션 별로 프로시져, UDF를 호출할 수 있다.
- PL/SQL은 Block 구조로 되어있어 각 기능별로 모듈화가 가능하다.
- 트랜잭션은 분할될 수 있으며, 각 트랜잭션 별로 프로시져, UDF를 호출할 수 있다.
- 여러 SQL문장을 Block으로 묶고 한 번에 Block 전부를 서버로 보내기 때문에 통신량을 줄일 수 있다.
- Procedure 내부에서 작성된 절차적 코드는 PL/SQL 엔진이 처리하고 일반적인 SQL 문장은 SQL 실행기가 처리한다.
124. PL/SQL ~ ROLLBACK이 불가능한 삭제

TRUNCATE를 사용,DELETE는ROLLBACK이 가능하도록 삭제하는 것임
DDL 명령어를 PL/SQL내에서 실행시키려면 execute immediate문을 활용해야됨.

125. 절차형 SQL 모듈
- 저장형 프로시져는 SQL을 로직과 함께 데이터베이스 내에 저장해 놓은 명령문의 집합을 의미한다.
CREATE PROCEDURE명령을 사용해서 생성 - 사용자 정의 함수는 단독적으로 실행되기 보다는 다른 SQL 문을 통하여 호출되고 그 결과를 리턴 하는 SQL의 보조적인 역할을 수행한다.
CREATE FUNCTION명령을 사용해서 생성- 이때 함수는 한 번에 리턴할 수 있는 최대 데이터 수가 1개, 없으면 NULL 리턴
- 데이터의 무결성, 일관성을 위해서 사용자 정의 함수를 사용한다. (
TRIGGER을 사용하여 데이터 무결성, 일관성을 유지할 수 있음)
126. TRIGGER 설명
- Trigger는 데이터베이스에 의해서 자동으로 호출되고 수행된다. (O)
- Trigger는 특정 테이블에 대해서 INSERT, UPDATE, DELETE 문이 수행되었을 때 호출되도록 정의할 수 있다.(O)
- Trigger는 TCL을 이용하여 트랜잭션을
제어할 수 있다.(단적인 예로, Trigger 는 ROLLBACK이 안됨) - Trigger는 데이터베이스에 로그인하는 작업에도 정의할 수 있다.
1. 순위/순번 매기기
-
RANK() OVER
- Argument 없음
- OVER 절에는 PARTITION BY, ORDER BY 사용 가능
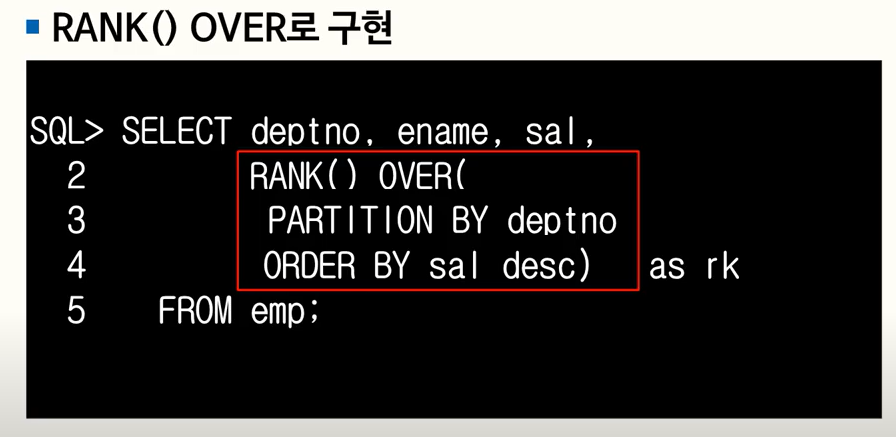
-
ROWNUMBER() OVER
- Argument 없음
- OVER 절에는 PARTITION BY, ORDER BY 사용 가능
2. 백분율 계산하기
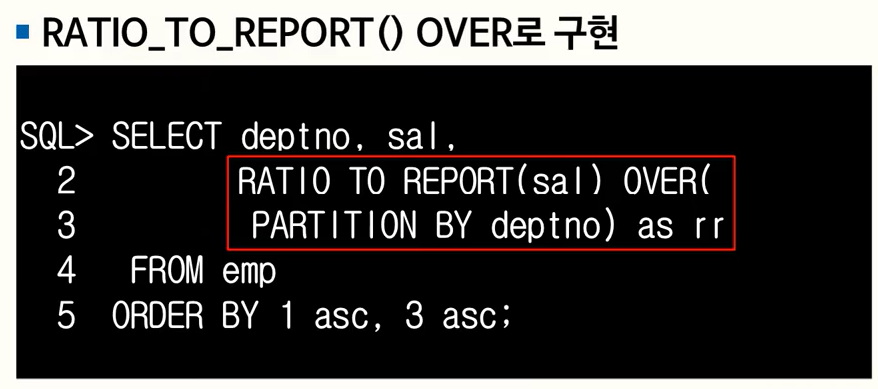
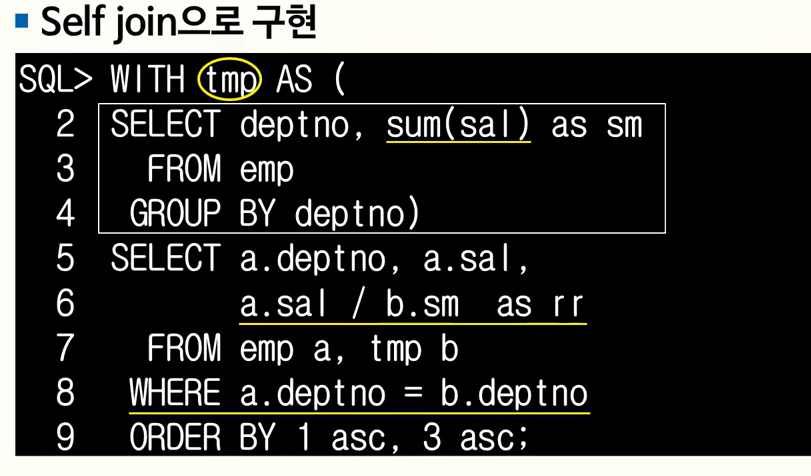
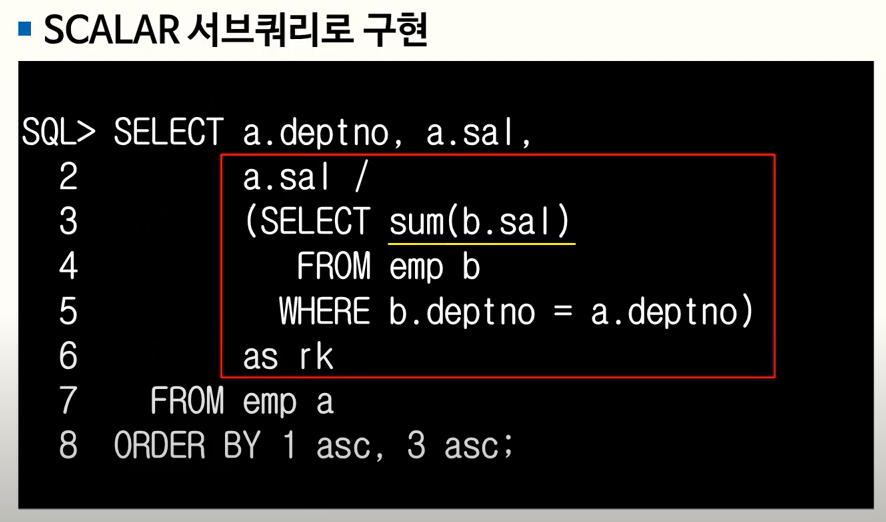
- RATIO_TO_REPORT() OVER
- Argument 있음
- OVER 절에는 PARTITION BY 만 가능
3. 직후/직전 값 처리
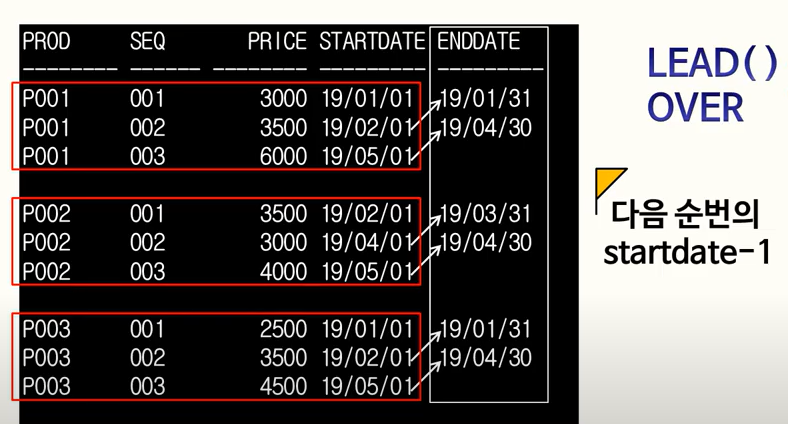
-
LEAD() OVER
- Argument 있음
- OVER 절에는 PARTITION BY, ORDER BY 사용 가능
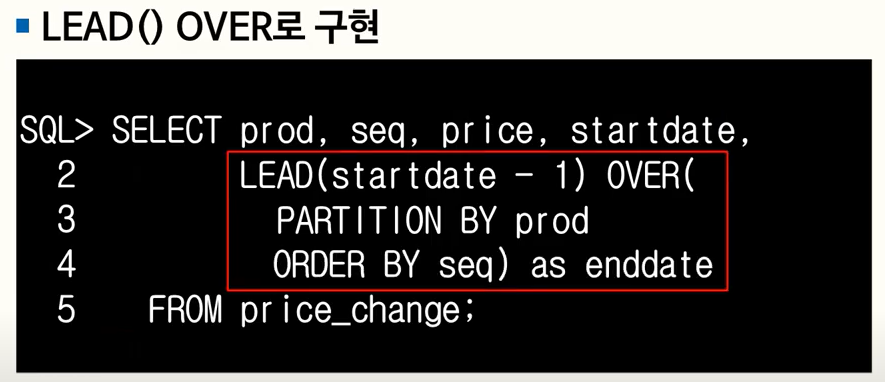
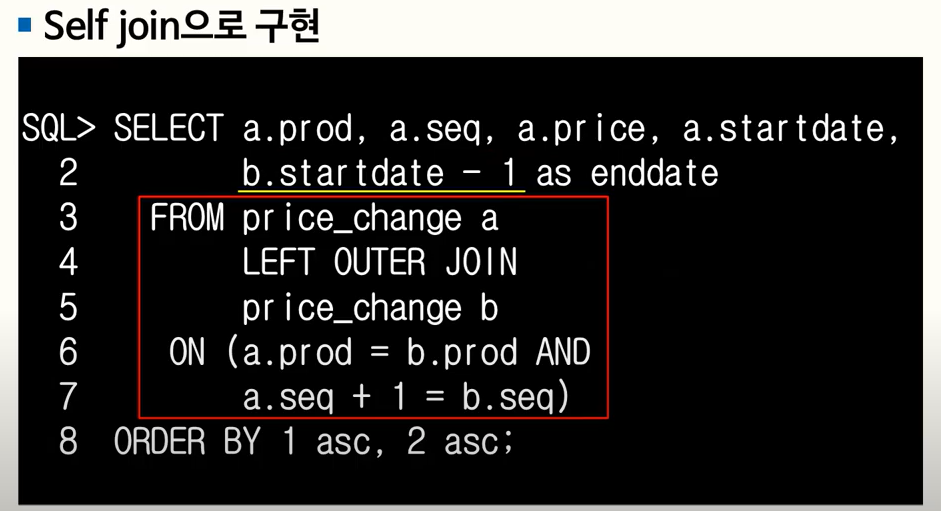

-
LAG() OVER
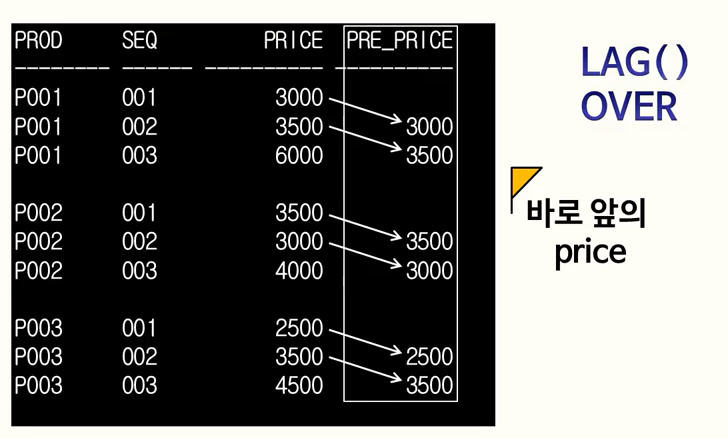

SQL 최적화 기본원리
128. OPTIMIZER
COST BASED OPTIMIZEZR(CBO)
테이블 및 인덱스 등의 통계 정보를 활용하여 SQL문을 실행하는 데 소요 될 처리시간 및 CPU, I/O 자원량 등을 계산하여 가장 효율적일 것으로 예상되는 실행계획을 선택하는 옵티마이저
129. 실행계획
실행계획을 통해서 알 수 있는 정보
- 액세스 기법
- 질의 처리 예상 비용
- 조인 순서
실제처리 건수
130. 실행계획의 실행순서
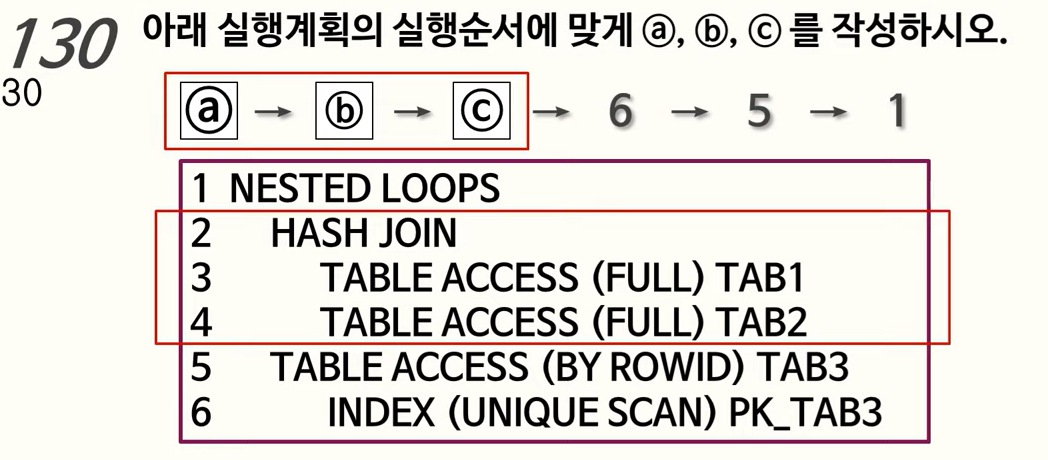
2번을 기준으로 3번과 4번이 깊이가 같은 작업이고 4번보다는 3번이 먼저이므로 3 4 2

2번과 5번 중 2번이 먼저 수행
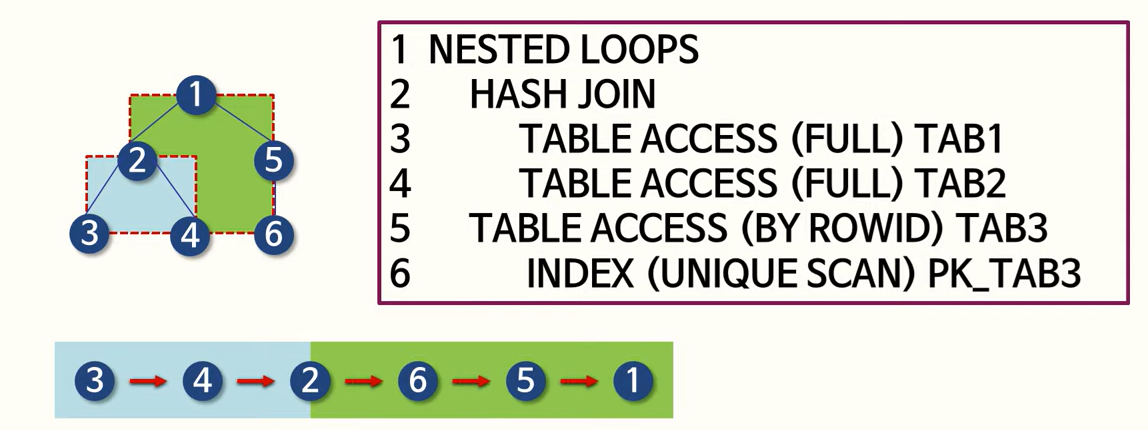
133. 옵티마이저와 실행계획에 대한 설명
- SQL 처리 흐름도는
성능적인 측면의 표현은 고려하지 않는다(성능적인 측면도 충분히 고려함) - 규칙 기반 옵티마이저에서 제일 높은 우선순위는 행에 대한 고유주소를 사용하는 방법이다. (O, Rule based 옵티마이저는 ROWID라는 고유주소를 통해서 1건의 데이터를 찾는 것에 가장 높은 우선순위가 주어짐)
- 인덱스 범위 스캔은 항상 여러 건의 결과가 반환된다.

134. 인덱스
- 기본인덱스 = PRIMARY KEY INDEX 는 UNIQUE이며, NOT NULL
- 보조인덱스에는 고유한 키 값들
만나타날 수 있다. (NOT UNIQUE한 중복된 값을 갖는 INDEX도 있음) - 인덱스는 조회의 작업 속도를 향상시키며, 전체 데이터를 full scan 하는 경우에는 인덱스를 타지 않는 것이 빠름 (B* tree index는 일반적으로 테이블 내의 데이터 중 10%이하의 데이터를 검색할 때 유리함)
136. 인덱스의 종류
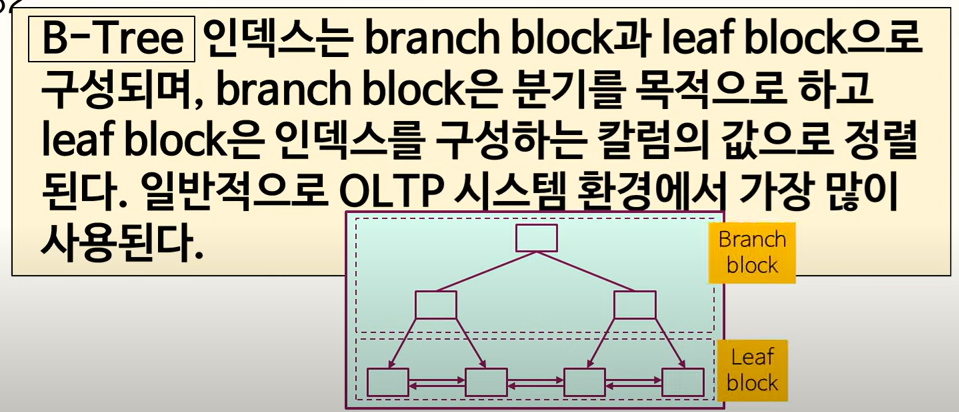
B-Tree 인덱스
CLUSTERED 인덱스

BITMAP 인덱스

137. 인덱스에 대한 설명
- 인덱스는 인덱스 구성 칼럼으로 항상 오름차순으로 정렬된다. (X, 내림차순인 것도 있음)
- 비용 기반 옵티마이저는 인덱스 스캔이 항상 유리하다고 판단한다. (X, RBO는 인덱스 스캔이 항상 유리하다고 한단)
- 규칙기반 옵티마이저는 적절한 인덱스가 존재하면 항상 인덱스를 사용하려고 한다.
- 인덱스 범위 스캔은 결과가 없으면 한 건도 반환하지 않을 수 있다.
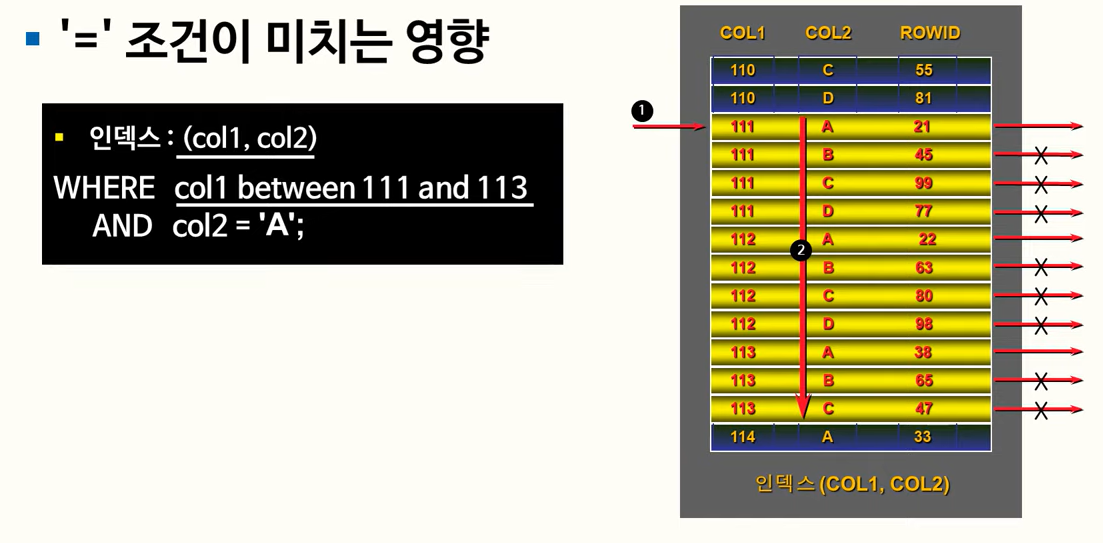
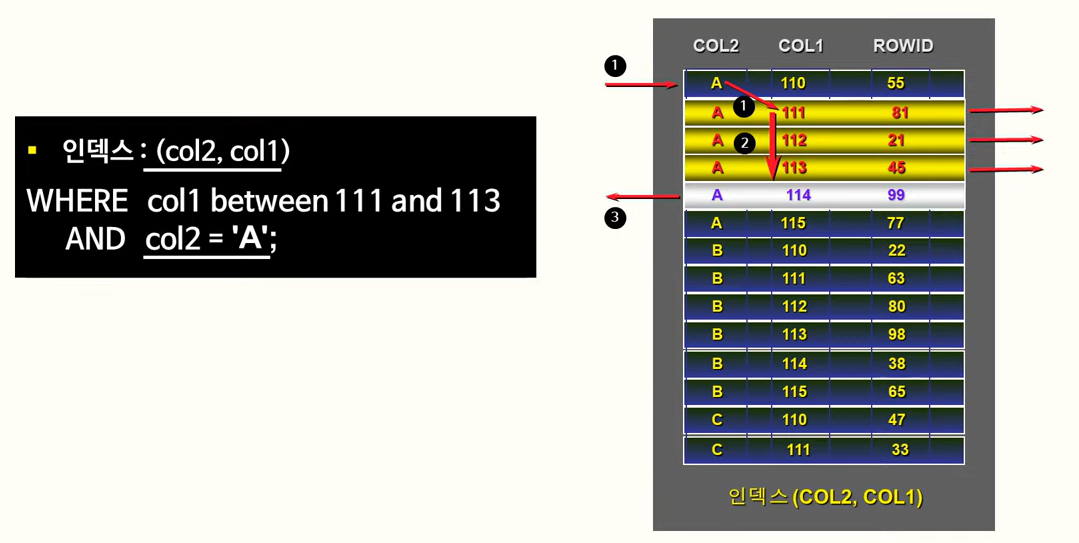
138. 결합 인덱스

인덱스의 컬럼을 DEPTNO + REGIST_DATE 순으로 변경하면 효율적으로 탐색이 가능함.
인덱스의 첫번째 컬럼에 준 조건이 동등조건이 되면 탐색함에 있어서 효율적으로 활용됨.
두 칼럼에 대한 '='를 모두 사용해서 범위를 좁히는 데 사용!
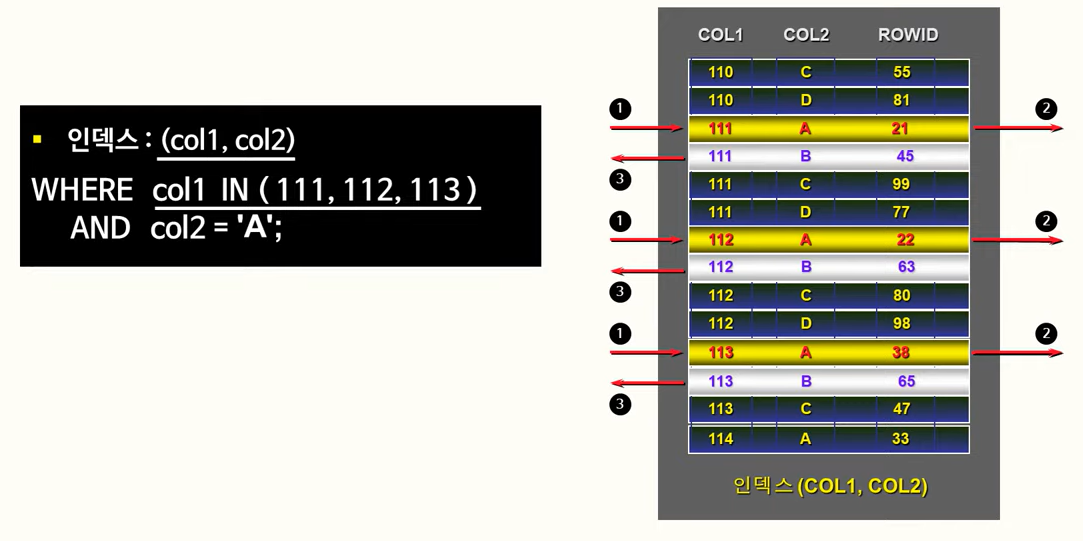
140. 인덱스와 UPDATE
- SQL Server의 클러스터형 인덱스는 ORACLE의 IOT와 매우 유사하다. (O)
- 인덱스는 INSERT, DELETE 작업과는 다르게 UPDATE 작업에는 부하가 없을 수도 있다. (O)
141. 옵티마이저와 실행계획에 대한 설명
비용기반 옵티마이저는 테이블, 인덱스, 컬럼 등 객체의 통계정보를 사용하여 실행계획을 수립하므로 통계정보가 변경되면 SQL의 실행계획이 달라질 수 있다.
ORACLE의 실행계획에 나타나는 기본적인 Join 기법으로는 NL Join, Hash Join, Sort Merge Join 등이 있다.
- NL Join은 데이터 집계하는 업무 보다는 OLTP의 목록 처리 업무에 많이 사용된다.
- DW 등의 데이터 집계 업무에서 많이 사용되는 Join 기법은 Hash Join 또는 Sort Merge Join이다.
- OLTP, One Line Transaction Process : 여러 과정의 연산이 하나의 단위 프로세스(트랜잭션)로 실행되도록 하는 프로세스
- Ex. A 가 B에게 10,000을 입금하는 상황에서
- A의 계좌에서 10,000이 인출되고,
- B의 계좌에서 10,000이 입금되는 프로세스가 하나의 프로세스로 이루어져야 하고, 중간에 오류가 발생하는 경우 모든 단계를 되돌려야 함.
- DW (Data Warehouse) : 오랜기간을 통해 추적된 데이터를 하나의 통합 데이터베이스로 구축해 놓은 것을 의미
142. Nested Loop Join
Nested Loop Join
- 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여 원하는 결과를 조합하는 방식
- 먼저 선행 테이블의 처리 범위를 하나씩 액세스하면서 추출된 값으로 연결할 테이블을 조인한다.
특징- 좁은 범위에서 유리한 성능을 보여줌
- 순차적으로 처리하며, Random access 위주
- 후행 테이블(Driven)에는 조인을 위한 인덱스 생성 필요
- 실행 속도 = 선행 테이블 사이즈 * 후행 테이블 접근횟수
- 조인 칼럼에 적당한 인덱스가 있어서 자연조인(Natural Join)이 효율적일 때 유용하다.
- Driving Table의 조인 데이터 양이 큰 영향을 주는 조인 방식이다.

143. 서브쿼리와 조인

- 서브쿼리 내의 WHERE 절의 조건에서 FROM 절의 DEPT 테이블의 DEPTNO를 확인하는 연관 서브쿼리

144. Sort Merge Join 에 대한 설명
SMJ은 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행한다.
NL조인은 주로 랜덤 액세스 방식으로 데이터를 읽는 반면,
SMJ은 주로 스캔 방식으로 데이터를 읽는다.
SMJ는 랜덤 액세스로 NL 조인에서 부담이 되던 넓은 범위의 데이터를 처리할 때 이용되는 조인 기법.
그러나 SMJ은 정렬할 데이터가 많아 메모리에서 모든 정렬 작업을 수행하기 어려운 경우에는 임시 영역(디스크)을 사용하기 때문에 성능이 떨어진다.
- 조인 칼럼에 적당한 인덱스가 없어서 NL 조인(Nested Loops)가 비효율적일 때 사용할 수 있다.
- Driving Table의 개념이 중요하지 않은 조인 방식이다. (Driving Table이 중요한 조인은 NL 조인과 Hash 조인)
- 조인조건의 인덱스의 유무에 영향 받지 않는다.
- EQUI(=) 조인 조건에서만 동작한다 (X, Hash Join의 경우만 동등 조건에서만 동작)
145. Hash 조인
Hash Join은 조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있는 조인 기법이다. Hash 함수를 이용하여 조인을 수행하기 때문에 '='로 수행하는 동등 조인에서만 사용이 가능
한쪽 테이블이 주 메모리의 가용 메모리에 담길 정도로 충분히 작고 해시 키 속성에 중복 값이 적을 때 효과적이다.
- Sort Merge Join을 하기에는 두 테이블이 너무 커서 소트 부하가 심할 때 사용하기 좋음
(22.03.06 p146번까지 1회독 완료)
(22.03.11 쓱 2회독)
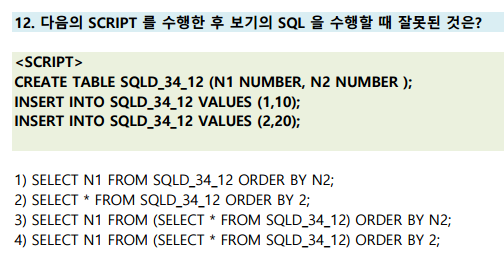
ORDERY BY 1, 2
ORDER BY 1, 2란 첫번째 컬럼, 두번째 컬럼을 의미하고, DESC가 생략되어 있으므로 오름차순으로 정렬
- 4번의 경우 N1만 뽑았으므로 2번째 컬럼이 없기 때문에 오류가 발생함.
PROCEDURE, TRIGGER 차이
- 둘 다 CREATE 명령어로 생성
- PROCEDURE는 COMMIT, ROLLBACK 명령어를 사용할 수 있음
- TRIGGER는 COMMIT, ROLLBACK 명령어를 사용할 수 없음
SUM() 과 NULL
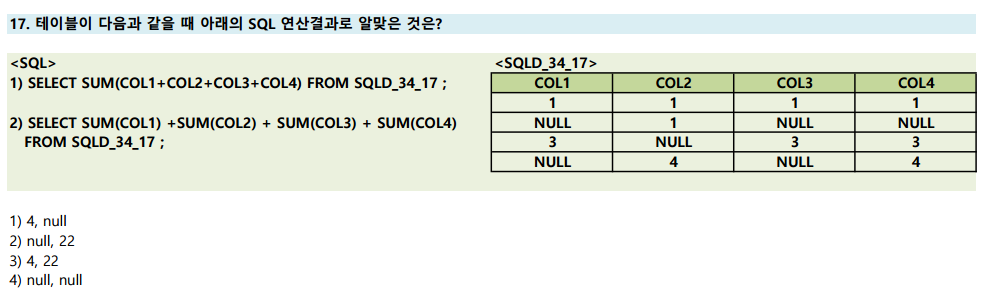
(a + b + c + d) 의 경우는 해당 로우에 대해서 계산이 되고 난 컬럼에 대해서 Sum 이 수행됨
(a) + (b) .. 의 경우 각각의 sum 을 수행하고 나서 다시 사칙연산이 수행됨
SUM() 함수에서 단일 컬럼이 연산이 될 때에는 NULL값은 연산의 대상에서 제외!
ORACLE 의 OUTER JOIN 기호 (+)
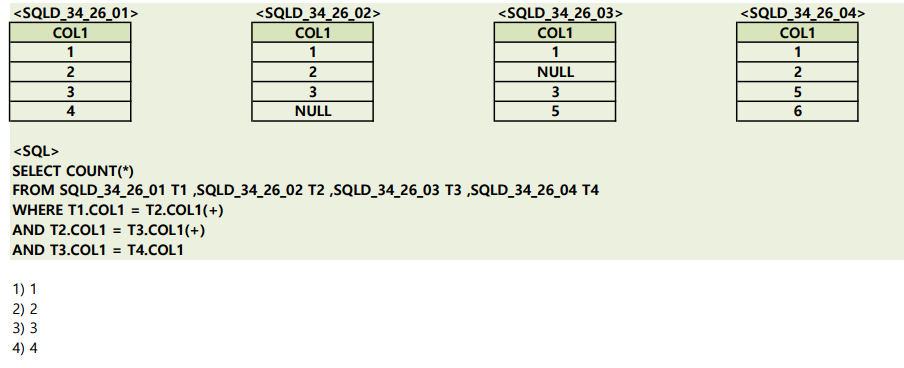
T1.COL1 = T2.COL1(+) 의 의미는 LEFT OUTER JOIN으로 COL1기준으로 OUTER JOIN최상위 관리자

LEFT OUTER JOIN을 통해야 MANAGER_ID가 NULL인 최상위 관리자가 나올 수 있음.
NTILE()
NTILE(숫자) 를 하면 숫자만큼 등분하여 순위를 매길 수 있음.