클린 아키텍쳐의 개념들은 레이어를 이루고 있는데 레이어를 형성한 이유와 본질부터 작성해보도록 하겠다. 엉클 밥이 추구한 아키텍쳐의 큰 두 가지의 가치는,
첫 번째, 같은 목표를 가진다.
둘 째, 소프트웨어를 계층(layer)로 나눠서 관심사를 분리한다.
아키텍쳐는 선을 긋는 기술이며, 엉클 밥은 이 선을 경계(boundary)라고 부른다. 경계를 이렇게 쓰는 이유는 핵심적인 비즈니스 로직을 오염시키지 못하게 만들려는 목적으로 쓰인다는 것이다. 또한 이렇게 관심사를 분리함으로써 내부에서 외부의 것을 알지 못하게 한다.
소프트웨어 아키텍쳐는 선을 긋는 기술이며, 나는 이러한 선을 경계(boundary)라고 부른다. 경계는 소프트웨어 요소를 서로 분리하고, 경계 한편에 있는 요소가 반대편에 있는 요소를 알지 못하도록 막는다.
Robert C.Martin, Clean Architecture, Ch.17
이런 가치를 실현시키고 단일 아이디어로 통합하길 원하면서 소개한 아이디어가 클린 아키텍쳐이자 경계로 나누어진 구성요소들이다.
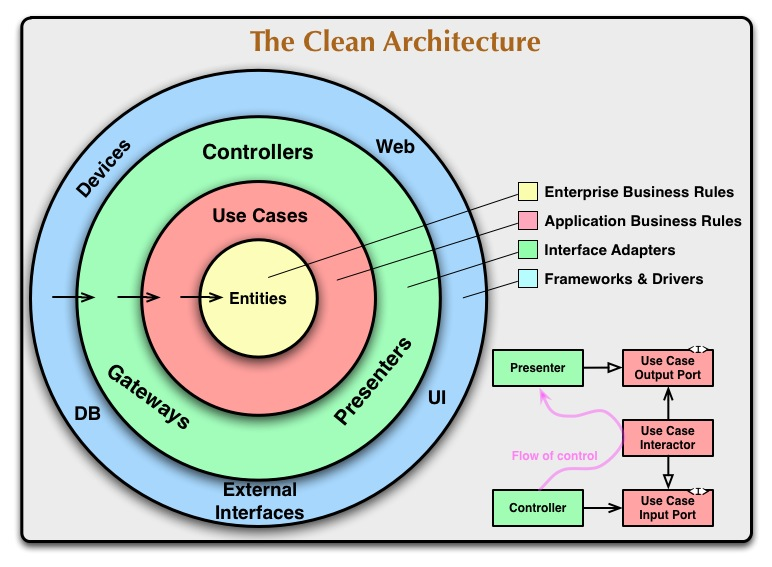
이와 같이 클린 아키텍쳐에 쓰이는 개념들이 각각의 목표를 가지면서 4개의 레이어를 형성하며 두 가지의 가치를 그대로 보여주는 것을 볼 수 있다.
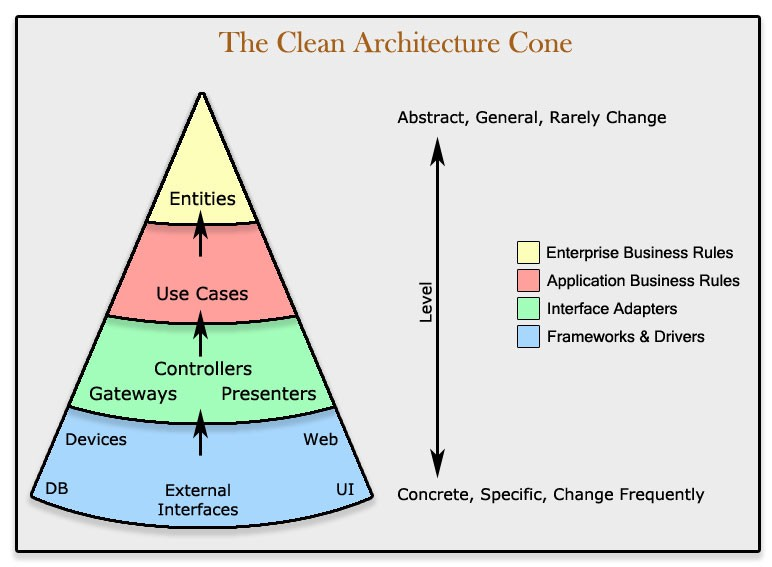
이 4가지의 구성요소는 서로의 의존도가 어느정도인가를 기준으로 계층을 이루고 있다.
의존성 규칙의 방향을 보면 가장 외부 UI나 data source가 의존도가 높고, adaptor, use case, entity의 방향으로 낮아지는 것을 볼 수 있다.
의존성 규칙의 가장 큰 개념으로서는,
1. 안쪽의 원 즉 비즈니스 로직은 바깥의 원, 즉 UI나 data source에 대해 전혀 알지 못한다.
2. 또한 안쪽 영역으로 갈수록 추상화와 정책의 수준이 높아지며, 반대로 갈수록 구체적인 세부사항으로 구성된다.
크게 안쪽에는 도메인의 영역인 entity, use case 그리고 가장 최상층에는 Infrastructure, 그 둘 사이를 이어주는 adapter가 있다.
어플리케이션의 핵심이자 비즈니스 규칙인 도메인은 다시 Entity와 Use case로 나눌 수 있다.
그리고 Adapter 은 도메인과 인프라 사이의 경계선으로 생성된다.
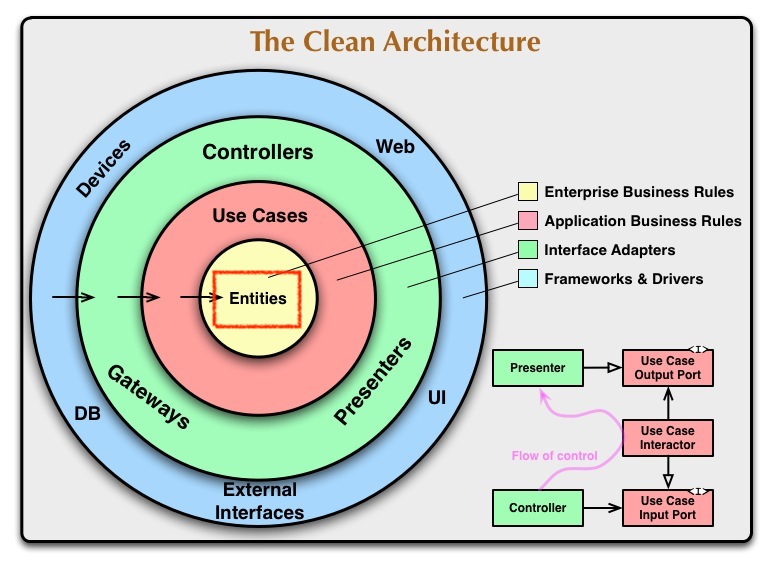
1. Entities
Entity는 무언가를 처리 할 때, Clean Architecture의 다른 구성요소에 의존하지 않는 비즈니스 로직이자, 데이터 구조, 메소드들의 집합체이다. 따라서 핵심 업무 규칙을 캡슐화하고 이렇게 캡슐화된 엔티티는 가장 변하지 않는 영역이다.
동심원에서 외부의 구성요소에 의존하지 않기 때문에 Use Case나 다른 구성요소에 의해서 어떻게 사용되는지 전혀 신경쓰지 않는다. 다른 것에 대해 아무것도 의존하지 않는다. 즉슨, 다른 어떠한 클래스명이나 밖의 레이어에 있는 컴포넌트들의 이름을 사용하지 않는 것이다.
쉬운 예제로, 영화 검색앱에서는 무엇이 entity인가? 일반적으로 가장 높은 수준의 규칙이 무엇인가?
struct Movie: Equatable, Identifiable {
typealias Identifier = String
enum Genre {
case adventure
case scienceFiction
}
let id: Identifier
let title: String?
let genre: Genre?
let posterPath: String
let overview: String?
let releaseDate: Date? } struct MoviesPage: Equatable {
let page: Int
let totalPages: Int
let movies: [Movie] }
출처: https://zeddios.tistory.com/1065 [ZeddiOS]Movie라는 데이터 구조가 entity이다. entity는 데이터 구조 및 함수 집합이라고 생각하면 된다. Movie라는 데이터 구조가 가장 높은 수준의 규칙이라고 말할 수 있다.
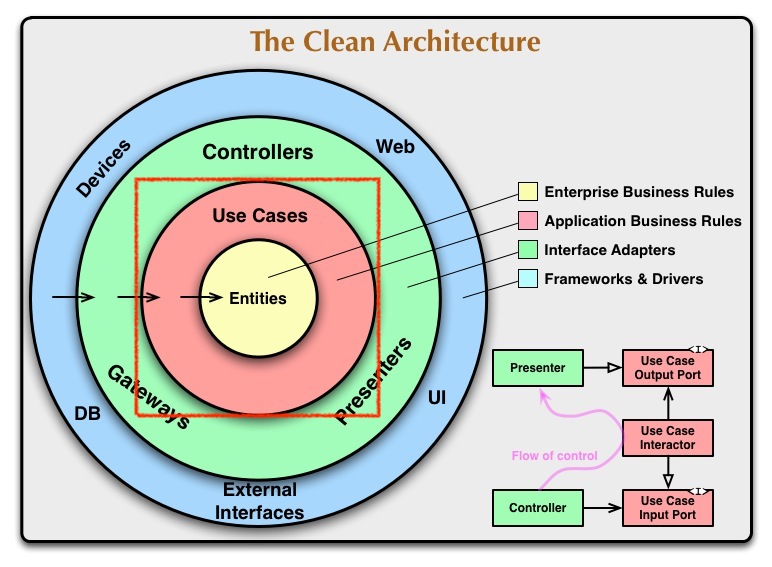
2. Use Cases
Use Cases는 Entity를 사용해서 어플리케이션 고유의 비즈니스 로직을 실현한다. 시스템의 동작을 사용자의 입장에서 표현한 시나리오이다. 어떻게 시스템이 자동화되는지 말해주고 어떻게 어플리케이션이 행동하고 실행하는지 결정한다.
따라서, Entity가 복수의 어플리케이션에 공유되고 Use Case는 만들어질 대상이 되는 어플리케이션에만 사용된다.
둘 간의 관계를 살펴보면, Use Case는 Entity로 들어오고 나가는 데이터 흐름을 조정하고 조작하고 해당 Entity가 Use Case의 목표를 달성하도록 지시하는 역할을 한다.
둘이 의존성 관계 또한, 가장 내부의Entity는 이 Use Case에 대해 전혀 알지 못한다는 것이다. 하지만 Use cases는 Entity의 흐름을 알고 조작해야 하므로 알고있어야 한다. 이 두 개념은 web page든 iPhone app에서 작동하든 상관하지 않고, 저장 장소 또한cloud에 저장되는 SQL 데이터베이스에 저장되는 전혀 영향을 받지 않는다.
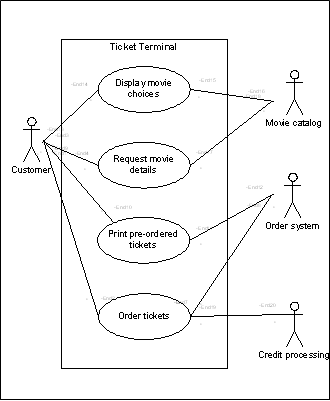
영화 검색 어플에서, 유저가 티켓을 주문하는 과정까지를 예시로 들면,
Use Case는 사용자에게 보여줄 출력을 위해 해당 출력을 생성하기 위한 처리 단계를 기술한다. 그래서 이 Use Case를 Use Case Interactor라고도 한다.
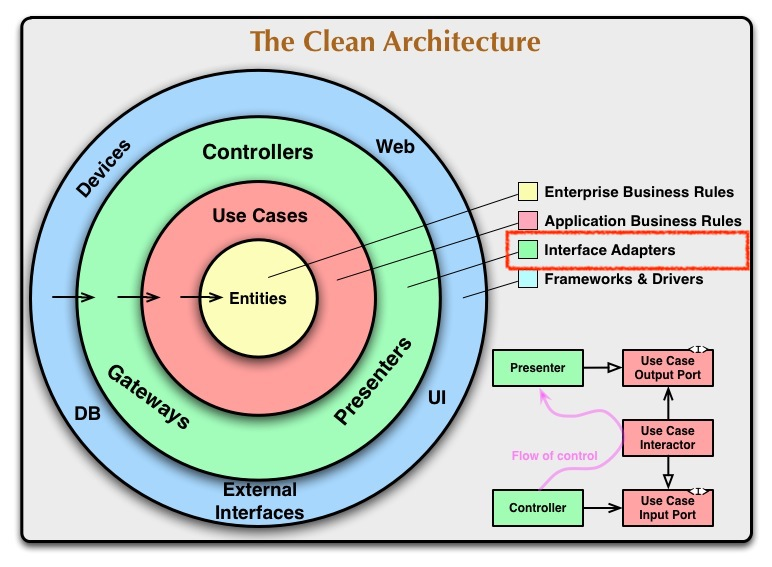
3. Adapters
도메인안의 두 개념들과 인프라의 사이에는 Adapter라는 레이어가 존재한다.
이는 Controllers, GateWays, Presenters를 포함하는 interface adaptor 이다. 또는 Presentation Layer라고도 하는 이 adaptor은 도메인과 인프라 사이의 통역하고 변환하는 역할을 한다. 즉, 본인의 계층 안밖에 있는 Data나 Event를 교환하기 위한 존재.
예를 들어, 이 계층에 데이터가 들어온다면 데이터를 Use Case와 Entity에서 사용될 수 있도록 변환하거나 반대로 Entity에서 사용되는 Data를 데이터베이스나 웹 같은 외부 프레임워크에 가장 편리한 형식으로 변환시킨다.
또한, 이 Adaptor는 Use case와 동심원의 가장 바깥쪽을 연결해주는 역할을 담당한다. Use Case의 입출력 포트를 동심원 바깥쪽의 어느 것과 연결시킬지도 결정하는 역할도 한다.
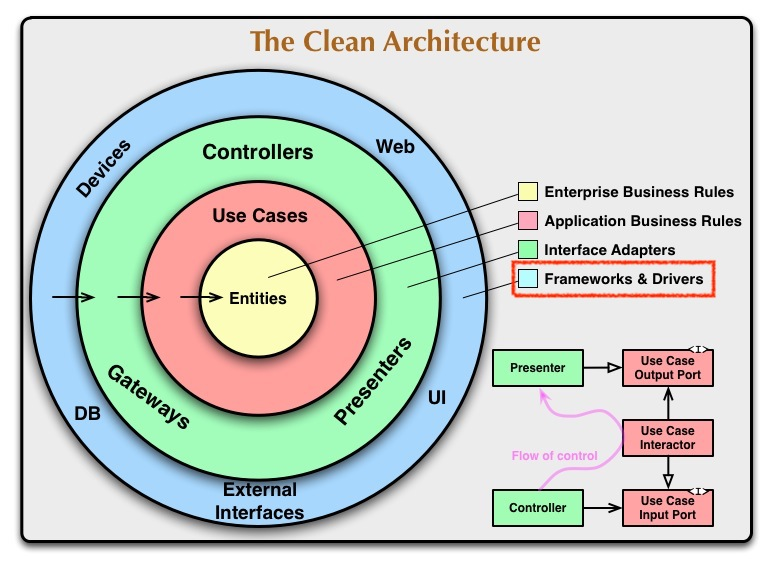
4. Infrastructure
일반적으로 DB, 프레임워크 같은 것들로 구성이 되는 영역.
의존성 규칙의 방향을 보면,
DB -> Adapter -> Use Cases -> Entities
따라서 시스템의 핵심 업무와는 관련 없는 세부 사항으로 언제든 갈아 끼울 수 있다. 이런 성질 때문에 프레임워크나 데이터베이스, 웹 서버등이 해당되는 것이다.
여기에 위치하게 되는 코드의 공통점은 비지니스 로직과는 전혀 관계가 없고 상황에 따라 만들어지는 수단이 변경할 가능성이 있다는 것이다.
따라서, 가장 취약한 레이어로써, 의존도가 높고 거리를 유지하고 분리되는 것을 유지하기 때문에 상대적으로 변화를 쉽게하고 컴포넌트와 다른 컴포넌트 사이를 쉽게 바꿀 수 있는 것이다.
Advantage of Layers
이렇게 구조를 나눈 장점을 크게 두 가지로 소개하자면, 이 구조 그대로 어플리케이션을 만들면 자주 변경되는 부분을 수정하기 쉽고, 유지하고 싶은 부분은 그대로 유지하기 쉽다는 점이다.
바깥 레이어에 포함된느 프레임워크가 바뀌어도 크게 시스템이 영향을 받지 않고, 클래스가 집중화되어 유지보수가 쉽게 되는 것.
또한, web api나 device drive에 의존하지 않는 entity와 use case의 특성상 당연히 test 작성이 용이해진다. 각각의 관심사에 특화된 독립적인 테스트를 할 수 있어 코드의 테스트 가능성이 증대된다.
이는 모두 동심원 가장 안쪽에 위치한 핵심가치인 entity 와 use case는 고유의 로직을 지키면서 외부세계를 알지 못하고 분리되어 있기에 가능한 것.
네 개의 원으로 크게 보았지만, 꼭 원이 네 개만일 필요는 없다. 원이 몇개든 의존성 규칙만 안쪽으로 향하면 되고, 안쪽으로 갈수록 추상화 수준이 증가하면 되는 것이다.
plus
비즈니스 로직이란?
회원가입 홈페이지를 예로 들자면, 유저는 아이디 중복 검사, 본인 인증, 비밀번호 재검사 등 유저가 해야할 것이 많다.
회원가입 기능을 구현하면서 두 가지의 부분으로 나눌 수 있는데, 하나는 중복 아이디가 있는지 없는지 검사하는 서버통신의 과정들이고 다른 하나는 유저에게 단순히 텍스트나 alert창으로 알려주는 것이다. 후자가 흔히 Presentation 영역 또는 View 영역이라고 불리고, 데이터를 단순히 보여주기만 하는 것이다. 그리고 데이터를 가공하고 로직을 통과시키는 부분이 전자인 Model 영역이다.
전자의 영역이 비즈니스 로직이다. 이처럼 비즈니스 로직은 가장 핵심이 되는 요소이다. 또한 유지보수와 확장성 또한 고려해야하므로 아키텍쳐를 알고 있어야 한다.
Clean architecture for the rest of us :
https://pusher.com/tutorials/clean-architecture-introduction

크으...👍🏻👍🏻 단비님 잘보고 갑니당!!