
김영한 강사님 스프링 MVC 1편 - 백엔드 웹 개발 핵심 기술 강의 참조
⭐ 로깅
-
대표적인 로그 라이브러리
- SLF4J : 인터페이스로 제공
- Logback : 로그구현체(스프링부트가 기본으로 제공)
-
@RestController
- @Controller 는 반환 값이 String 이면 뷰 이름으로 인식. 그래서 뷰를 찾고 뷰가 랜더링 된다.
- @RestController 는 반환 값으로 뷰를 찾는 것이 아니라, HTTP 메시지 바디에 바로 입력.
- 따라서 실행 결과로 ok 메세지를 받을 수 있다.
import Slf4j로 해줘야해!!
//@Slf4j 사용하면 로그선언 필요없음, log.info("name")만 쓰면됨
@RestController
public class LogTestController {
//로그선언
private final Logger log = LoggerFactory.getLogger(getClass());
@RequestMapping("/log-test")
public String logTest() {
String name = "Spring";
//로그호출 - 로그 레벨에 따라 설정
log.trace("trace log={}", name);//로컬pc
log.debug("debug log={}", name);//개발서버에서 디버그할때 사용
log.info(" info log={}", name);//비즈니스 정보, 운영시스템에서 봐야하는 정보
log.warn(" warn log={}", name);//경고
log.error("error log={}", name);//위험
//로그를 사용하지 않아도 a+b 계산 로직이 먼저 실행됨, 이런 방식으로 사용하면 X
log.debug("String concat log=" + name);
return "ok";
}
}
- 로그 출력되는 포멧 확인 (시간, 로그레벨, 프로세스ID, 쓰레드 명, 클래스명, 로그메시지)

- 로그 레벨 설정을 변경한 출력 결과 확인
- LEVEL: TRACE > DEBUG > INFO > WARN > ERROR
- 개발 서버는 debug 출력
- 운영 서버는 info 출력
- application.properties
#전체 로그 레벨 설정(기본 info) logging.level.root=info #hello.springmvc 패키지와 그 하위 로그 레벨 설정(root보다 우선) logging.level.hello.springmvc=debug
📕 백엔드 개발자의 고민 Point
-
정적 리소스 어떻게 제공할거야?
- 고정된 HTML파일, CSS, JS, 이미지, 영상 등을 제공
- 주로 웹 브라우저
-
동적으로 제공되는 HTML 페이지 어떻게 제공할거야?
- 동적으로 필요한 HTML파일을 생성해서 전달
- 웹브라우저 : HTML 해석
-
HTTP API 어떻게 제공할거야?
- HTML이 아니라 데이터를 전달(UI화면이 필요하면, 클라이언트가 별도 처리)
- 주로 JSON 형식 사용
- 앱(안드로이드, 아이폰), 웹(JS를 통한 HTTP API호출) 클라이언트(react, vue.js) to 서버, 서버(주문 서버) to 서버(결제 서버)
- 다양한 시스템에서 호출
📕 SSR vs CSR
-
브라우저 렌더링 : 브라우저가 서버로부터 HTML, CSS, JS 등 파일을 요청해서 받은 내용을 브라우저에 표시하는 작업으로 브라우저 엔진이 서버로부터 받은 파일을 각 해석해서 브라우저 화면을 구성
-
서버 사이드 렌더링 (SSR, Server Side Rendering)
- 서버에서 렌더링을 처리해서 브라우저로 전달(화면을 구성하는 주체 : 서버)
- 클라이언트가 서버에 데이터를 요청할 때마다 서버에서 데이터로 새 화면을 구성해 전달

-
클라이언트 사이드 렌더링 (CSR, Client Side Rendering)
- 클라이언트인 브라우저가 렌더링 처리 (화면을 구성하는 주체 : 브라우저)
- 서버에서 데이터를 받은 데이터를 통해 클라이언트인 브라우저가 화면을 구성함

-
클라이언트 사이드 렌더링 Flow
- 서버에서 index.html 파일을 브라우저에 보냄
- HTML 파일에는 애플리케이션에서 필요한 자바스크립트의 링크만 있음
- 브라우저에 처음 페이지에 접속하면 빈 화면만 보이고, 서버로부터 app.js 파일 다운로드
- app.js 파일은 애플레케이션에서 필요한 로직과 애플리케이션을 구동하는 프레임워크, 라이브러리를 포함함
- 데이터가 필요하면 추가로 데이터를 서버에 요청 후 JSON 파일을 전달 받아 동적으로 HTML을 생성해 보여줌
📌 HttpServletRequest 역할
서블릿은 개발자가 HTTP 요청 메시지를 편리하게 사용할 수 있도록 개발자 대신에 HTTP 요청 메시지를 파싱, 그 결과를 HttpServletRequest 객체에 담아서 제공.
📌 WEB-INF
이 경로안에 JSP가 있으면 외부에서 직접 JSP를 호출 불가. 우리가 기대하는 것은 항상 컨트롤러를 통해서 JSP를 호출하는 것
📌 람다 표현식(화살표)
- lambda expression : 메소드를 하나의 식으로 표현한 것 (클래스를 작성하고 객체를 생성하지 않아도 메소드 사용가능)
-
화살표 함수의 형식
(parameter1, parameter2, ...) -> expression- 매개변수 리스트 -> 함수 몸체(한 줄로 표현 가능한 표현식)
- ex.
(int x, int y) -> x + y: 두 수를 더하는 람다식
📌 MultiValueMap
- 하나의 키에 여러 값을 받을 수 있다.(HTTP header, HTTP 쿼리 파라미터와 같이 하나의 키에 여러 값을 받을 때 사용)
MultiValueMap<String, String> map = new LinkedMultiValueMap();
map.add("keyA", "value1");
map.add("keyA", "value2");
//[value1,value2] 배열로 반환됨
List<String> values = map.get("keyA");📕 Packaging War vs Jar
-
war : WAS서버(톰캣)를 별도로 설치하고 거기에 빌드된 파일을 넣을때, jsp 사용할때 사용
-
jar : 별도의 톰캣없이 내장서버를 사용할 경우 사용. webapp 경로도 사용 X
- 스프링 부트에 Jar 를 사용하면 /resources/static/ 위치에 index.html 파일을 두면 Welcome
페이지로 처리
- 스프링 부트에 Jar 를 사용하면 /resources/static/ 위치에 index.html 파일을 두면 Welcome
📙 HTTP 요청 데이터
- GET(쿼리 파라미터)
- POST(HTML Form)
- HTTP message body(HTTP API에서 주로 사용, JSON, XML, TEXT)
- 데이터 형식은 주로 JSON사용(POST, PUT, PATCH)
- HTTP message body에 데이터를 직접 담아서 요청
📙 HTTP 응답 데이터
-
정적 리소스 : 웹 브라우저에 정적인 HTML, css, js를 제공할 때는, 정적 리소스를 사용한다.(해당 파일을 변경 없이 그대로 서비스)
-
뷰 템플릿 사용 : 웹 브라우저에 동적인 HTML을 제공할 때는 뷰 템플릿을 사용한다.
-
HTTP 메시지 사용 : HTTP API를 제공하는 경우에는 HTML이 아니라 데이터를 전달해야 하므로, HTTP 메시지 바디에 JSON 같은 형식으로 데이터를 실어 보낸다.
📙 캐시 & 캐싱
- 캐시 : 동일한 데이터에 반복해서 접근해야 하거나 많은 연산이 필요한 일일때, 결과를 빠르게 이용하고자 성능이 좋은 혹은 가까운 곳에 저장하는 것 (컴퓨터의 성능을 향상 시키기 위해 사용되는 메모리)
- 주기억장치와 CPU 사이에 위치하고, 자주 사용하는 데이터를 기억한다
- 예를 들어, 한번 접속한 웹 사이트에 동일한 브라우저로 다시 접속할 때 용량이 큰 이미지나 비디오는 다시 받아오지 않고 브라우저 캐시에 저장해 놨다가 동일하게 가져다 씀
- 캐시 메모리 : CPU 에서 가장 빠른 Register 와 메인 메모리 사이 존재.(디스크 혹은 메모리에서 읽어온 데이터를 빠르게 저장하는 용도)
- CPU 요청에 따라 메인 메모리에서 해당 데이터와 함께 인접한 데이터로 이뤄진 메모리 블럭을 캐시 메모리로 가져온다. CPU가 다시 데이터를 요청하면 메인 메모리가 아니라 캐시에 요청을 해보고, 캐시에서 해당 데이터를 읽어온다. 없으면 다시 메인 메모리에서 읽어온다.)
- 캐싱 : 이 캐시 영역으로 데이터를 가져와서 접근하는 방식
- 예를 들어, 속도가 느린 디스크의 데이터를 속도가 빠른 메모리로 가져와 메모리상에서 읽고 쓰는 작업을 수행(메모리상에 있는 데이터를 연산하는데, 이 연산을 더 빠른 CPU 메모리 영역으로 가져와 처리를 수행하는 것)
-
브라우저 캐시 : 이미지, 비디오 뿐만 아니라 CSS 와 Javascript 등 정적 리소스를 로컬에 저장하여 성능을 향상시킨다.
-
웹 캐시 : 서버 지연을 줄이기 위해 웹 페이지, 이미지, 기타 유형의 웹 멀티미디어 등의 웹 문서들을 임시 저장하기 위한 정보 기술.
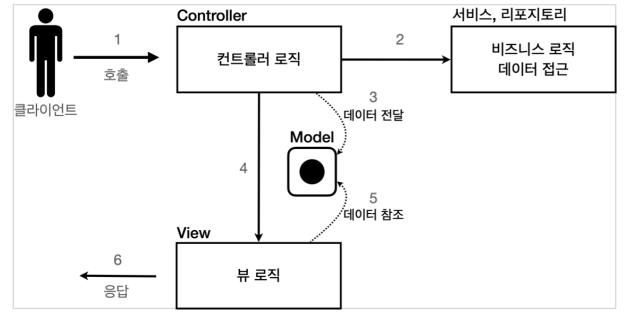
📒 MVC 패턴
-
컨트롤러: HTTP 요청을 받아서 파라미터를 검증하고, 비즈니스 로직을 실행, 뷰에 전달할 결과데이터를 조회해서 모델에 담는다.
-
모델: 뷰에 출력할 데이터를 담아둔다. 뷰가 필요한 데이터를 모두 모델에 담아서 전달해주는 덕분에 뷰는 비즈니스 로직이나 데이터 접근을 몰라도 되고, 화면을 렌더링 하는 일에 집중
-
뷰: 모델에 담겨있는 데이터를 사용해서 화면을 그리는 일에 집중한다. 여기서는 HTML을 생성하는 부분을 말한다.
- 일반적으로 비즈니스 로직은 Service라는 계층을 별도로 만들어서 처리, 컨트롤러는 비즈니스 로직이 있는 서비스를 호출하는 역할을 담당.
📒 redirect vs forward
-
리다이렉트 : 실제 클라이언트(웹 브라우저)에 응답이 나갔다가, 클라이언트가 redirect 경로로 다시 요청한다. 따라서 클라이언트가 인지할 수 있고, URL 경로도 실제로 변경된다.
-
포워드 : 서버 내부에서 일어나는 호출이기 때문에 클라이언트가 전혀 인지하지 못한다.
📒 RPG (Post/Redirect/Get)
- post등록 후 새로고침 시 문제점 (웹 브라우저의 새로 고침은 마지막에 서버에 전송한 데이터를 다시 전송)
- 상품 등록 폼에서 데이터를 입력하고 저장을 선택하면 POST /add + 상품 데이터를 서버로 전송한다.
- 이 상태에서 새로 고침을 또 선택하면 마지막에 전송한 POST /add + 상품 데이터를 서버로 다시 전송하게 된다.
- 그래서 내용은 같고, ID만 다른 상품 데이터가 계속 쌓이게 된다.

- 해결방안 : RPG (Post/Redirect/Get)
- 웹 브라우저는 리다이렉트의 영향으로 상품 저장 후에 실제 상품 상세 화면으로 다시 이동한다. 따라서 마지막에 호출한 내용이 상품 상세 화면인 GET /items/{id} 가 되는 것이다.
이후 새로고침을 해도 상품 상세 화면으로 이동하게 되므로 새로 고침 문제를 해결할 수 있다.

📒 RedirectAttributes
@PostMapping("/add")
public String addItemV3(Item item, RedirectAttributes redirectAttributes){
Item saveItem = itemRepository.save(item);
redirectAttributes.addAttribute("itemId",saveItem.getId() );
redirectAttributes.addAttribute("status", true);//남는거는 쿼리파라미터로 들어감
return "redirect:/basic/items/{itemId}";
}- 실행해보면
http://localhost:8080/basic/items/3?status=true로 이동됨- URL 인코딩도 해주고, pathVarible 바인딩 , 나머지는 쿼리 파라미터로 처리
- 뷰 템플릿 메시지 추가
<h2 th:if="${param.status}" th:text="'저장 완료!'"></h2>- th:if : 해당 조건이 참이면 실행
- ${param.status} : 타임리프에서 쿼리 파라미터를 편리하게 조회하는 기능
- 원래는 컨트롤러에서 모델에 직접 담고 값을 꺼내야 한다. 그런데 쿼리 파라미터는 자주 사용해서 타임리프에서 직접 지원
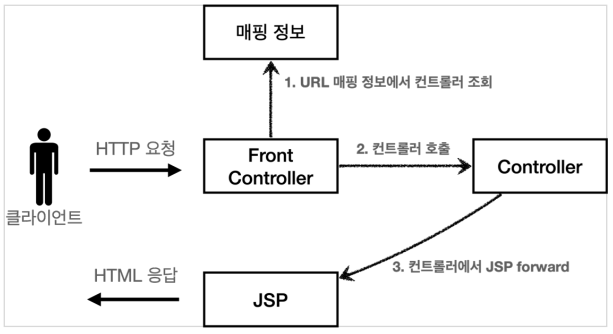
📗 프런트 컨트롤러
-
서블릿 하나로 클라이언트의 요청을 받음 (프론트 컨트롤러가 요청에 맞는 컨트롤러를 찾아서 호출)
-
입구를 하나로(공통 처리 가능)
-
프론트 컨트롤러를 제외한 나머지 컨트롤러는 서블릿을 사용하지 않아도 됨

-
핸들러 : 컨트롤러 뿐만 아니라 어떠한 것이든 해당하는 종류의 어댑터만 있으면 다 처리 가능 (핸들러 어댑터 : 핸들러 처리)
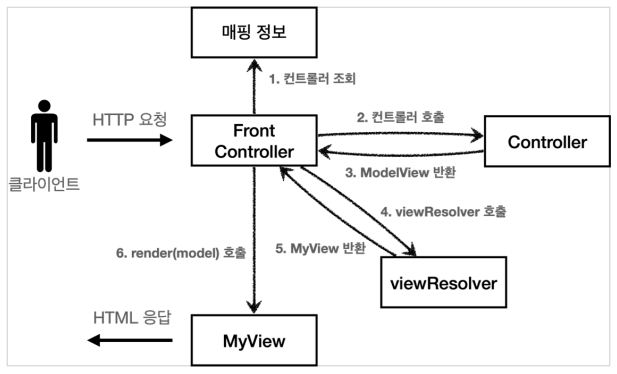
📗 스프링 MVC 전체 구조
- 스프링 MVC도 프론트 컨트롤러 패턴 (프론트 컨트롤러가 바로 디스패처 서블릿이다.)
- DispacherServlet 도 부모 클래스에서 HttpServlet 을 상속 받아서 사용하고, 서블릿으로 동작.
- 스프링 부트는 DispacherServlet 을 서블릿으로 자동으로 등록하면서 모든 경로(urlPatterns="/" )에 대해서 매핑한다.
- 참고: 더 자세한 경로가 우선순위가 높다. 그래서 기존에 등록한 서블릿도 함께 동작한다.
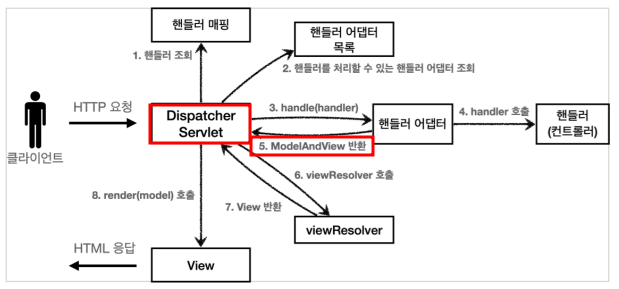
- 동작순서
- 핸들러 조회: 핸들러 매핑을 통해 요청 URL에 매핑된 핸들러(컨트롤러)를 조회한다.
- 핸들러 어댑터 조회: 핸들러를 실행할 수 있는 핸들러 어댑터를 조회한다.
- 핸들러 어댑터 실행: 핸들러 어댑터를 실행한다.
- 핸들러 실행: 핸들러 어댑터가 실제 핸들러를 실행한다.
- ModelAndView 반환: 핸들러 어댑터는 핸들러가 반환하는 정보를 ModelAndView로 변환해서 반환한다.
- viewResolver 호출: 뷰 리졸버를 찾고 실행한다. JSP의 경우: InternalResourceViewResolver 가 자동 등록되고, 사용된다.
- View 반환: 뷰 리졸버는 뷰의 논리 이름을 물리 이름으로 바꾸고, 렌더링 역할을 담당하는 뷰 객체를 반환한다. JSP의 경우 InternalResourceView(JstlView) 를 반환하는데, 내부에 forward() 로직이 있다.
- 뷰 렌더링: 뷰를 통해서 뷰를 렌더링 한다.
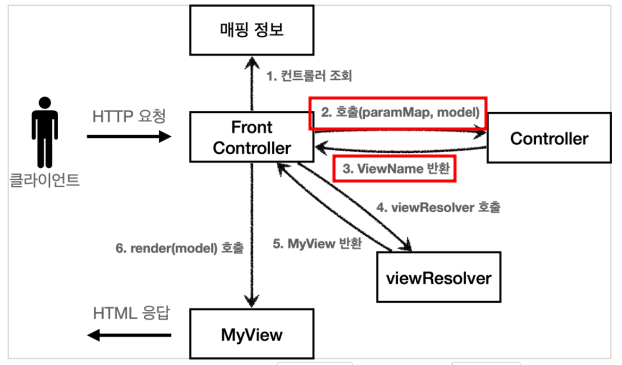
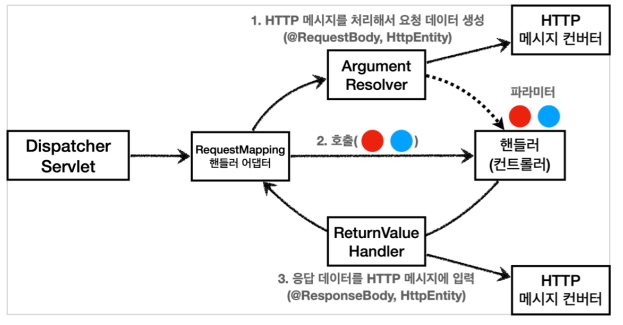
- RequestMappingHandlerAdapter 동작 방식
- Argument Resolver
- 모든 파라미터로 요청된것은 Argument Resolver에서 처리하는데 HTTP 메시지를 처리해서 요청 데이터를 생성할 경우에는 HTTP 메시지 컨버터에게 넘김
- HTTP 메시지 컨버터에서 메시지바디에 있는 내용을 확인해서 알려줘(바이트배열인지, text인지, json인지)
- 이렇게 파라미터 값이 모두 준비되면 컨트롤러를 호출하면서 값을 넘겨줘
- ReturnValue Handler
- 모든 응답(반환값)은 ReturnValue Handler에서 처리하는데 응답데이터를 HTTP 메시지에 입력하면 HTTP 메시지 컨버터로 이동
- 응답 결과 반환값이 준비되면 핸들러 어댑터에게 알려줘
📘 스프링 MVC 어노테이션
-
@Controller : 스프링이 자동으로 스프링 빈으로 등록.
(내부에 @Component 애노테이션이 있어서 컴포넌트 스캔의 대상이 됨)- 스프링 MVC에서 애노테이션 기반 컨트롤러로 인식 ㅡ> 핸들러 매핑에서 핸들러 정보로 인식하며 꺼낼 수 있는 대상이 됨
-
@RequestMapping : 요청 정보를 매핑. 해당 URL이 호출되면 이 메서드가 호출된다.
-
@PathVariable
@GetMapping("/mapping/{userId}")//url에 변수가 들어감 //변수명이 같으면 생략 가능- @PathVariable("userId") String userId -> @PathVariable userId public String mappingPath(@PathVariable("userId") String data) { log.info("mappingPath userId={}", data);//mappingPath userId=a return "ok"; }- 다중사용도 가능
@GetMapping("/mapping/users/{userId}/orders/{orderId}") public String mappingPath(@PathVariable String userId, @PathVariable Long orderId) { log.info("mappingPath userId={}, orderId={}", userId, orderId); return "ok"; }
- 다중사용도 가능
-
@RequestParam.required : 파라미터 필수 여부(파라미터 이름만 있고 값이 없는 경우 빈문자로 통과)
- 참고!
@RequestParam(required = false) int agefalse라고 값이 없을 경우 null ㅡ> null 을 int 에 입력하는 것은 불가능(500 예외 발생) 따라서 null 을 받을 수 있는 Integer 로 변경
- 참고!
-
@ModelAttribute : 객체 생성해서 1)요청 파라미터의 이름으로 프로퍼티 찾아 그리고 세터 호출해서 파라미터값 바인딩 (ex. username ㅡ> setUsername()메소드 찾아서 호출)
- 위에서 지정한 객체를 자동으로 2)모델에 넣어주는 역할까지 수행 (ex. model.addattribute("a",a) : a라는 이름으로 a가 담김)
public String add(@ModelAttribute("item") Item item: item이라는 이름으로 item 객체 저장 (이름 생략시 클래스이름-첫문자만 소문자로 변경됨)
-
@PostConstruct : 의존성 주입이 끝나고 실행됨이 보장(어플리케이션이 실행될 때 한번만 실행됨- bean이 여러 번 초기화되는 것 방지)
📘 HTTP 메세지 컨버터
- HttpEntity: HTTP header, body 정보를 편리하게 조회
- 메시지 바디 정보를 직접 조회(@RequestParam X, @ModelAttribute X 즉 get, post방식 아니야)
- 응답에서도 HttpEntity 사용 가능 ㅡ> 메시지 바디 정보 직접 반환(view 조회X)
- HttpMessageConverter 사용 ㅡ> StringHttpMessageConverter 적용
- ex. HttpEntity<String> httpEntity : http바디에 있는 것 문자로 바꿔서 실행시켜줄게(inputstream실행할 필요 없음)
@PostMapping("/request-body-string-v3")
public HttpEntity<String> requestBodyStringV3(HttpEntity<String> httpEntity) {
String messageBody = httpEntity.getBody();
log.info("messageBody={}", messageBody);
return new HttpEntity<>("ok");//바디메시지
}HttpEntity를 간단하게 어노테이션으로 사용 가능
- @ResponseBody : HTTP message body 정보 직접 반환
- @RequestBody : HTTP message body 정보 직접 조회
