
linux와 shell script 등에 대해 배우던 중 궁금한 점이 생겼다.
shell command 중에는 sort가 있다.
sort [filename], cat [filename]|sort (option) 등으로 사용하는데 말 그대로 정렬을 해준다.
예를 들어 다음과 같은 식이다.
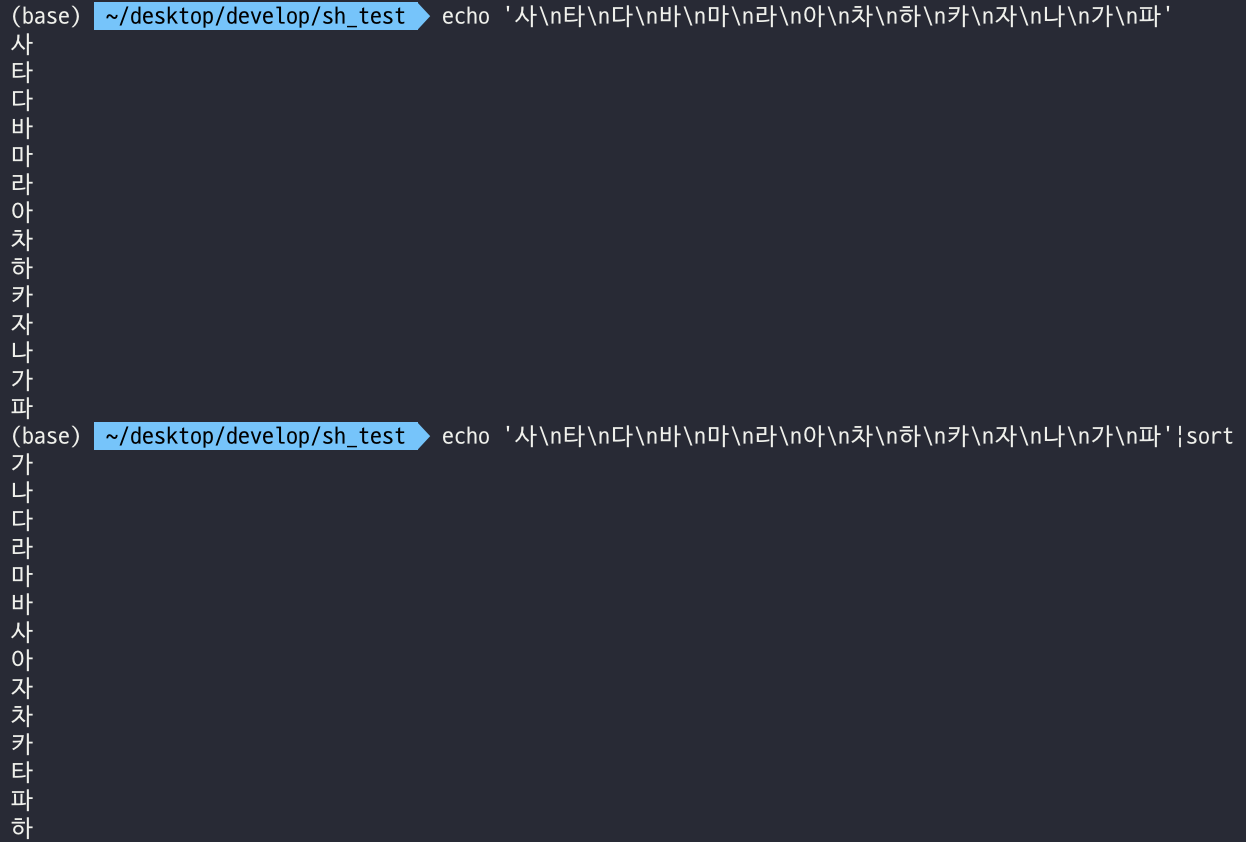
sort 명령어를 다양한 텍스트에 대해 옵션도 달리 하면서 이리저리 사용해보던 중 의아한 상황을 마주쳤다.

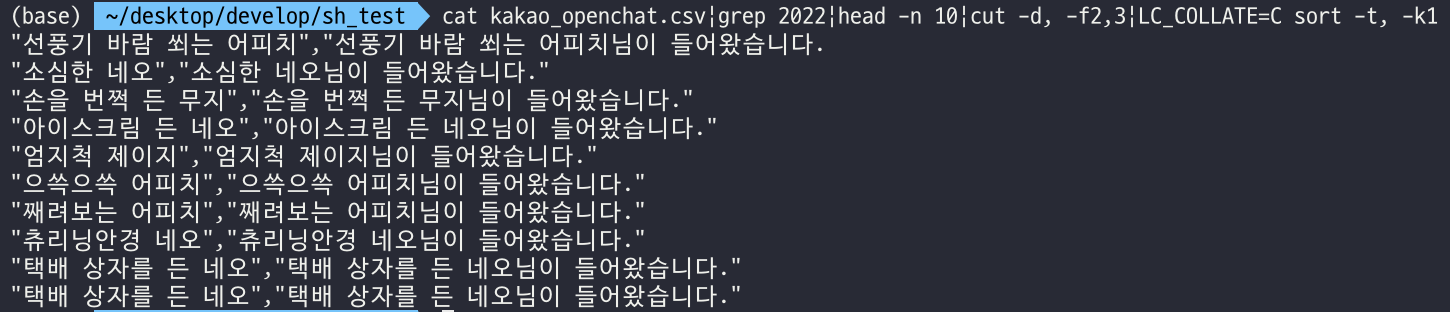
오픈채팅방에서 카톡 내보내기를 한 후 csv확장자로 저장된 해당 파일을 불러오고 2022년 카톡(grep 2022) → 위에서 10개(head -n 10) → 발신자와 내용만 표시(cut -d, -f2,3)한 텍스트이다.
sort 명령어를 통해 발신자 기준 정렬을 해보고 싶었다.
(참고로 sort의 옵션으로 -t, -k를 사용했다. -k는 sort를 어떤 key에 대해 수행할건지 정하는 옵션인데 -t뒤에 이어지는 문자열을 delimeter로 삼아 여러 개의 key로 나눌 수 있다.)

그런데 보다시피 정렬이 정상적으로 수행되지 않는다.
'택배 상자를 든 네오' 다음에 '선풍기 바람 쐬는 어피치'가 오고 '째려보는 어피치' 다음에 '아이스크림 든 네오'가 온다. 한글의 순서를 생각하면 올바르지 않은 정렬이다.
하지만 첫번째 이미지에서 알 수 있듯이 내 컴퓨터 환경에서 sort은 정상적으로 이루어진다. 뭐가 문제일까?
결론부터 말하면 해결책은 찾았다.(근본적인 원인은 아직... 찜찜한 마무리다.)
'locale'이란 것이 있다. 쉽게 말해 각 언어권/나라별 언어 규약 같은건데 여기에는 날짜 표현 방식, 큰 숫자에 삽입되는 콤마(,), 언어 정렬 방식 등이 포함된다.
https://docs.oracle.com/cd/E26925_01/html/E27145/glmbx.html
https://mug896.github.io/bash-shell/locale.html
이를 이용해 sort 시에 locale 옵션을 바꿔주면 정상적으로 정렬이 된다.
LC_COLLATE는 정렬 순서와 관련이 있다. LC_COLLATE=C란 언어 규약에서 정렬순서와 관련된 설정을 C로 하겠다는 것인데 이는 특정 언어에 맞추지 않고 C programming locale로 맞추겠다는 것이다.
LC_COLLATE=ko_KR.UTF-8과 LC_COLLATE=C는 같은 정렬 방식이라고 한다.
다만 아직도 의문은 남았다.
-
우선 나의 locale 설정은 모두
ko_KR.UTF-8로 맞춰져 있다.
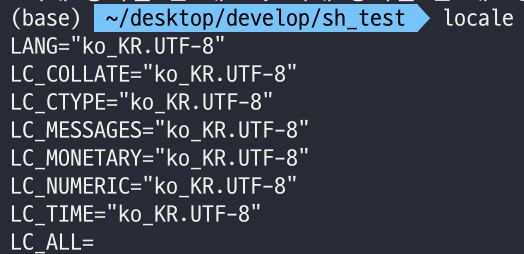
만약LC_COLLATE=en_US.UTF-8과 같은 식으로 한글이 아닌 다른 언어로 설정되어 있었다면 한글 텍스트가 제대로 정렬되지 않는 것이 이해가 된다. 하지만 정렬 방식을 한국어에 맞췄는데 왜 제대로 정렬이 되지 않는 것인가? -
txt파일을 생성해
sort를 적용해보거나echo명령어로 문자열을 생성하고sort해보면 정상적으로 정렬이 된다. 왜 카카오톡 내보내기로 생성한 파일에 대해서 정렬을 시도하면 원하는대로 결과가 나오지 않을까?- txt파일이 아닌 csv파일인게 문제일까?
csv파일을 생성해 순서가 꼬인 한글 텍스트를 집어넣고 실험해봤다.
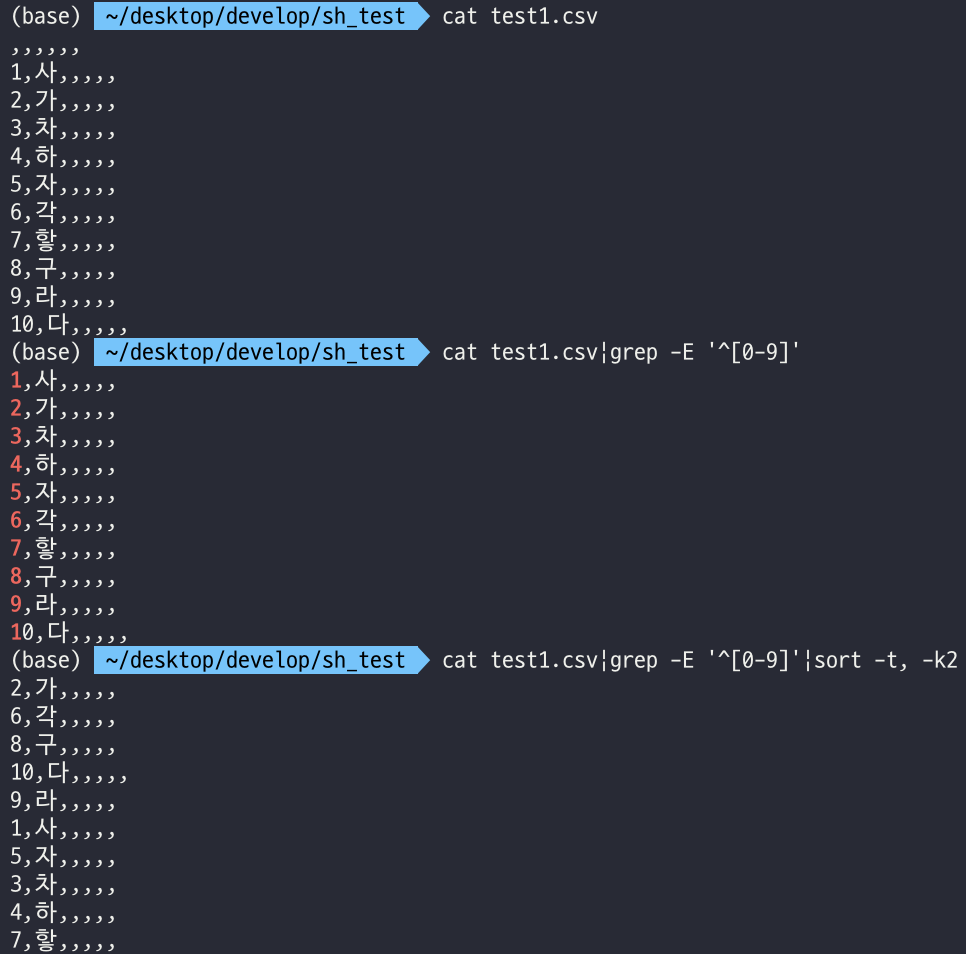
정상적으로 정렬이 된다.
- txt파일이 아닌 csv파일인게 문제일까?
위의 의문은 아직도 해결되지 않은 상태이다. 카카오톡만의 문제는 아닌 것 같은게 공공 데이터를 csv로 받아 동일한 방식의 실험을 해봤더니 역시 정렬이 제대로 이뤄지지 않았다. LC_COLLATE=C를 넣어 sort해야 정상적인 결과가 나왔다.
완전히 동일한 상황은 아니지만 해결법이 유사한 상황은 다음 게시글에서 찾을 수 있었다.
https://jupiny.com/2016/12/12/sort-korean-in-postgresql/
혹시 더 나은 해결법을 찾거나 원인을 정확히 알게 되면 추가하도록 하겠다. 꽤 시간을 잡아먹긴 했지만 생각보다 재밌고 유익한 경험이었다. 덕분에 locale에 대해서도 알게 되고 shell command는 어떤 과정을 거쳐 동작하는지도 생각해볼 수 있었다.
