들어가기 전에 앞서서
작성자가 쓰고도 뭐라는지 이해가 좀..
너그럽게 봐주시면 감사하겠습니다..ㅎㅎ
서론
다음과 같은 문제가 있다고 하자.
특정 구간에서 최솟값, 혹은 최댓값을 찾고 싶어한다.
혹은 특정 구간에서 어떠한 수와 가장 가까운 수는 무엇인지에 대해 알고 싶어한다.
이러한 문제들은 어떻게 접근해야할까?
기본적으로 선형적인 방법을 우선 생각할 것이다. 하지만 해당 방법으로는 굉장히 오랜 시간이 걸릴 것이다. 10e9(1000000000)개의 원소가 있다고 가정하였을 때, 최악의 경우 10e9번 모두 훑어보아야한다.
세그먼트 트리는 이러한 문제점들을 해결해준다.
특히, "특정 구간"이라는 키워드를 중심으로 세그먼트 트리의 진가를 엿볼 수 있다.
본론에 들어가기에 앞서서
해당 글은 작성자가 이해한 것을 바탕으로 작성되었습니다.
따라서 정말 지극히 작성자의 눈높이에 맞춘 글일 확률이 굉장히 높습니다.
그렇기에 지적은 언제나 환영입니다.
본론
1. 아이디어
일반적인 배열에서의 문제점은 선형적인 방법으로 완전탐색을 해야한다는 것이 가장 큰 문제점이었다.
그렇다면 도대체 어떤 방법으로 이를 해결할 수 있을까
작성자가 이해한 원리는 다음과 같다.
- 압축
원소의 정보를 압축할 수는 없을까? 원소의 정보를 압축해서 저장해 놓고, 언제든 풀어낼 수 있다면? 압축된 정보를 사용할 수도 있다면?
2. 구체적인 방법
사실 "'압축'이라는 단어를 어떻게 실현시켜야 하는가?"가 중점이다. 그 열쇠가 바로 완전이진트리이다.
두 가지 원소씩 묶어서 부모 노드에 저장하고, 그렇게 묶인 부모노드들 끼리도 묶어서 저장한다면?
예를 들어서 특정 구간에서 최댓값을 구하고 싶다고 해보자.
우리의 목적은 특정 구간에서의 최댓값이다. 따라서 최댓값이라는 점에 초점을 두고 정보를 압축할 것이다.
그림은 높이가 원소 [1, 5, 9, 2]에 대해 압축을 실행한 결과이다. 각 노드가 의미하는 바는 다음과 같다.
1번 노드: 1번째 원소부터 4번째 원소 중 최댓값
2번 노드: 1번째 원소부터 2번째 원소 중 최댓값
3번 노드: 3번째 원소부터 4번째 원소 중 최댓값
4~7번 노드: 각 원소의 값
만약 우리가 1번 원소와 3번 원소사이에서 최댓값을 찾고 싶다면, 다음과 같이 조회하면 된다.
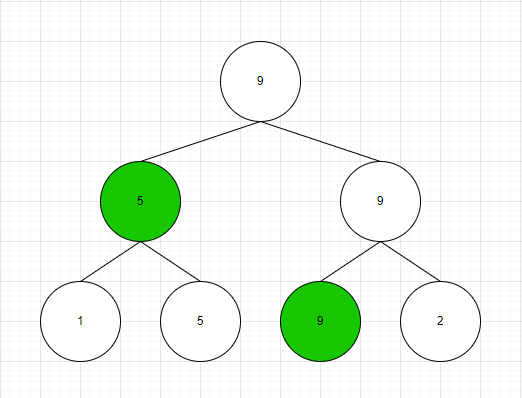
우리는 이를 위해서 재귀를 이용한 방식으로 목표값까지 접근할 것이다.
3. 코드
코드의 진행은 다음과 같다.
1. 트리를 만들어준 다음, 트리의 잎노드에 우리의 원소를 복사해준다.
2. 복사가 완료되었다면, 압축을 실시한다.
def tree_init():
# 해당 반복문은 가장 아랫가지부터 채워올라오기 위해 다음과 같이 작성하였다.
for h in range(int(tree_height), -1, -1):
# 만약 리프노드라면 복사를 먼저 해준다.
if h == int(tree_height):
# standard는 값을 넣을 리프노드의 배열에서의 인덱스값을 의미한다.
standard = 2 ** h
# 이후 list_num에서 하나씩 떼어와서 넣어줄 것이다.
for node in range(len(list_num)):
segment_tree[standard] = list_num[node]
standard += 1
else:
# 리프노드가 아니라면 자식노드의 두 값을 비교하여 원하는 정보(최댓값)를 저장한다.
for node in range(2 ** h, 2 ** (h + 1)):
segment_tree[node] = max(segment_tree[node * 2][0], segment_tree[node * 2 + 1][0])이제 우리가 원하는 범위에서 원하는 정보를 뽑아야하므로
1. 우리가 원하는 범위에 해당하는 값을 찾는다.
2. 필요에 따라 걸러준다.
def query(target_start, target_end, current_start, current_end):
# 현재 위치가 목표범위와 일치하다면
if current_start >= target_start and current_end <= target_end:
# 이 부분이 조금 난해할 수 있다. (작성자의 해석적인 부분이 들어가는바람에..)
# 1. 범위의 길이를 구한다.
length = current_end - current_start + 1
# 2. 범위의 첫 시작에 해당하는 원소의 세그먼트 트리에서의 인덱스를 구한다.
# 이를 범위의 길이로 나누어준다면, 범위가 가리키는 세그먼트 트리에서의 인덱스를 구할 수 있다.
# (자세한건 아래 수필로 올림)
node_pos = (2 ** tree_height + current_start - 1) // length
return segment_tree[node_pos]
# 현재 위치가 완전히 어긋낫다면
if current_start > target_end or current_end < target_start:
return -1
# 현재 위치중 하나라도 어긋나있다면
m1 = query(target_start, target_end, current_start, (current_start + current_end) // 2)
m2 = query(target_start, target_end, (current_start + current_end) // 2 + 1, current_end)
return max(m1, m2)
코드 부가 설명 (query 부분)
파란 글씨 = 범위
빨간 글씨 = 실제 세그먼트 트리 배열에서의 인덱스 (0번째 인덱스는 0으로 따로 설정)
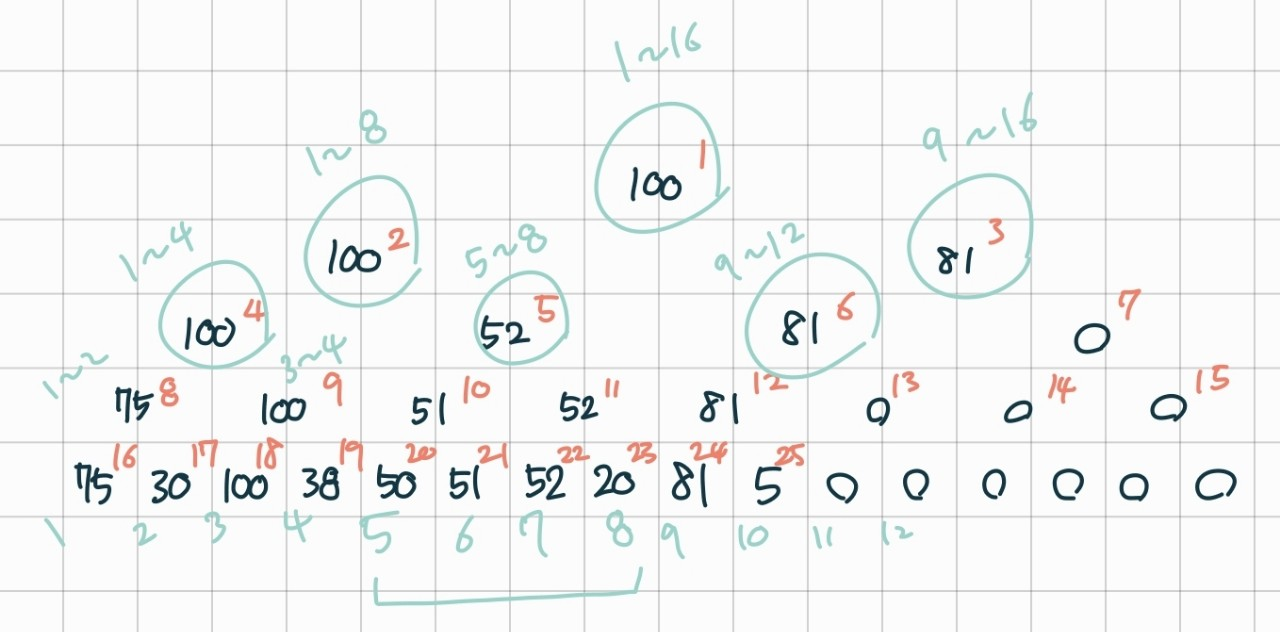
해당 그림에서 만약 5~8범위의 값을 조회하고 싶다면
일단, 우리가 아는 정보는 '5~8범위에서 찾을거에요!'라는 정보뿐이다. 또한 처음 원소를 주었을 때 트리의 높이가 결정되었으므로 틀리의 높이도 안다.
이를 바탕으로 진행해보자.
먼저 5~8번 원소의 실제 세그먼트 트리에서의 인덱스 값을 구해보자
해당 높이의 첫 원소는 16, 즉 2^tree_height에 해당한다. 따라서 5번 원소의 실제 인덱스 값은 2^tree_height + 5 - 1에 해당한다.
먼저 5~8번 노드의 공통 부모가 빨간5, 파란 5~8에 해당하는 노드이다. 즉, 어떤 원소에서 시작해도 결론적으로 우리가 원하는 5~8에 도달할 수 있다. 우리는 5번 노드의 실제 인덱스 값을 구했으므로 거슬러 올라가면 된다. 근데 몇번이나 거슬러 올라가야 하나?
압축횟수는 다음과 같이 구한다.
50, 51, 52, 20 총 4개의 정보를 하나로 압축한 값이기 때문에 총 2번 압축되었음을 확인할 수 있다.
코드에서 직접 작성한 length = current_end - current_start + 1 부분은 5~8범위에서 8 - 5 + 1을 통해서 길이를 구한 것이다.
즉 해당 실제 인덱스 값 20에서 20 // 2 ** 2를 해준다면 5~8의 범위에서 최댓값을 담고 있는 실제 인덱스값 5를 얻을 수 있다.
