⭐ HR 데이터 분석 및 시각화
01. 데이터 파악하기
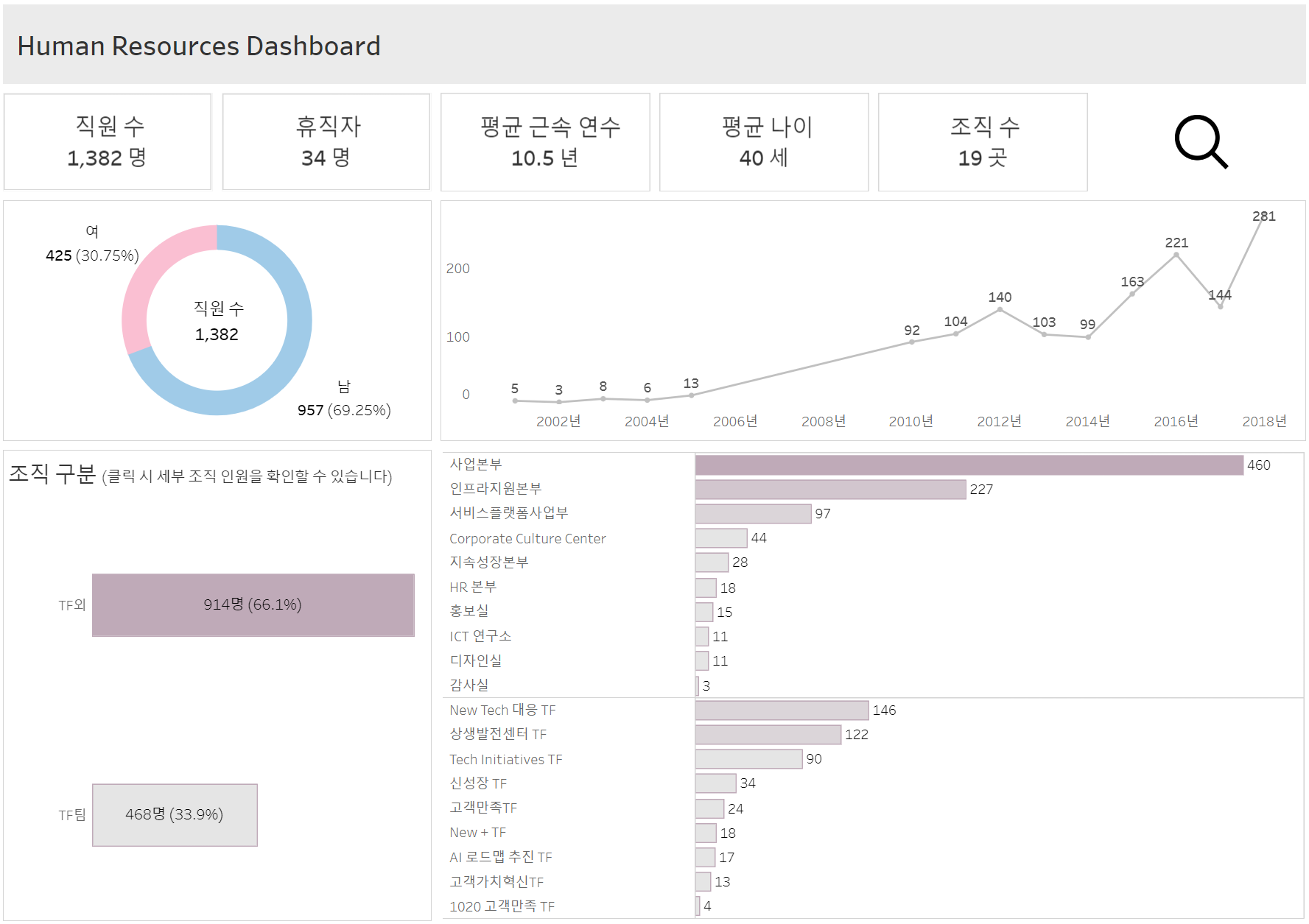
- 전체 데이터 수: 1,382개
- 사번
정규직과 계약직의 사번이 다르다. (정규직 1,325명, 계약직 57명)
- 재직
휴직 중인 직원 수: 34명 (무급 휴직 31명, 유급 휴직 3명)
- 입사
신입, 경력, NULL (신입 753명, 경력 572명, NULL 57명)
- 조직
19개로 구성됨
- 입사일
2001년 ~ 2018년, 2006년부터 2009년까지는 NULL
- 생년월일
1996년생 ~ 1968년생까지
- 성별
남자 957명, 여자 425명
- 최종 학력
석사: 178명, 박사: 37명, 학사: 1,167명으로 대부분 학사
✅️ 데이터를 통해 얻을 수 있는 내용
- 입사 연도별로 인원수를 파악하려면 라인 차트 사용
연, 월, 일 중에 연도만 사용한다면 집계로 미리 가져와서 데이터를 간단히 하는 방법
- 신입이 많은 부서와 경력이 많은 부서
- 부서별, 성별 인원수는? (인원이 적은 곳도 있음)
- 현재 날짜 - 입사일 = 재직 기간 → 오래 일한 사람이 많은 부서는?
- 석사 또는 박사 학위를 가진 사람이 많은 부서 → 학력별 인원수
- 조직 수가 많아 히트맵으로 나타내면 보기 편하다.
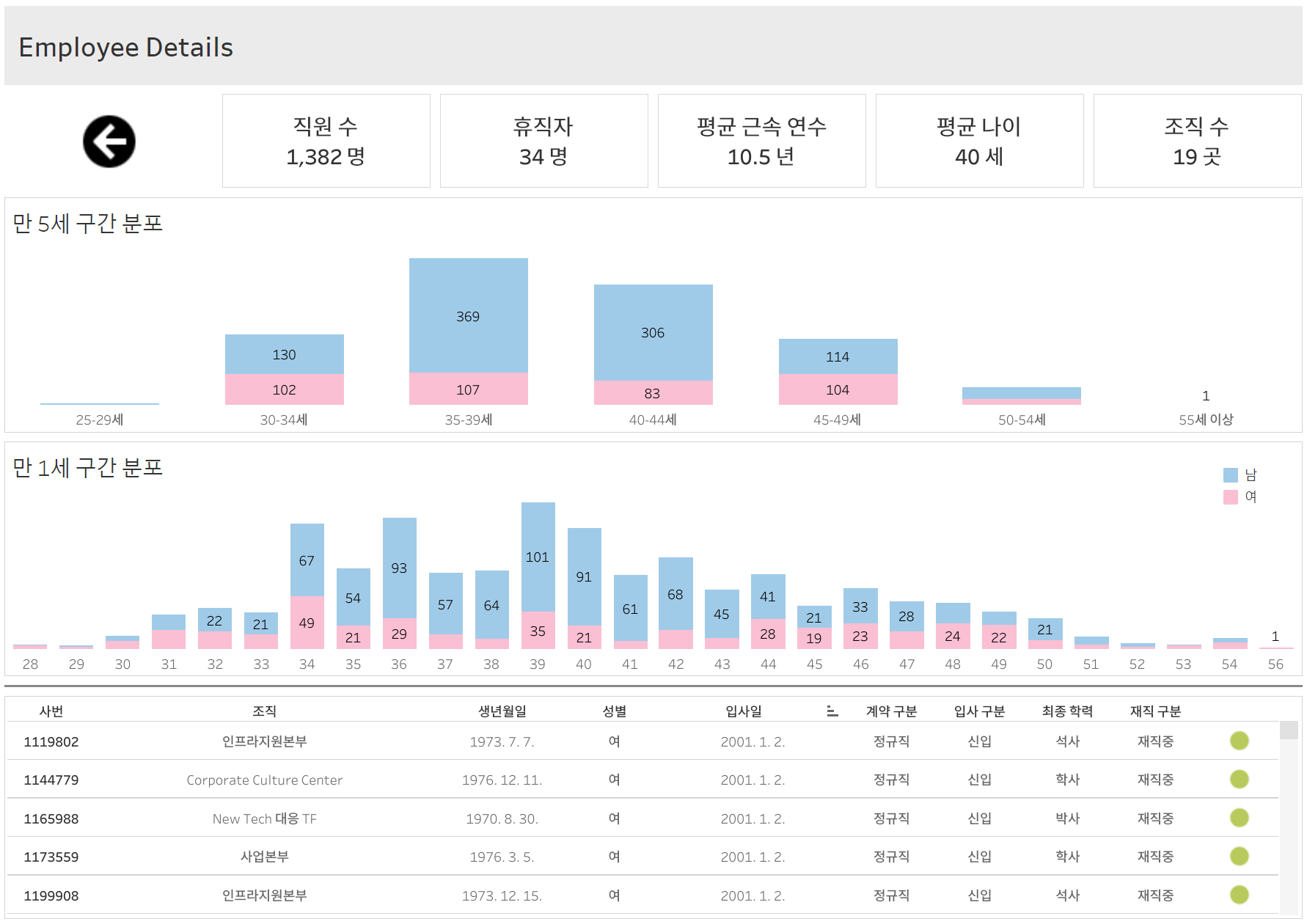
- 생년월일로 나이 계산 후 연령대 만들어서 인원수 파악
- 조직 수가 19개로 많아 히트맵으로 나타내기
02. 데이터 전처리
- 사번: 측정값이 아닌 차원으로 변경 (숫자 → 문자), LEFT 함수로 정규/계약 구분
- 입사(신입, 경력, NULL)
IFNULL 함수로 NULL 값을 계약으로 변경
- 직원 수 필드 생성
COUNT 또는 COUNTD
- 재직(유급 휴직, 무급 휴직, NULL)
IFNULL 함수로 NULL 값을 재직 중으로 변경
- 재직 구분에 대한 그룹 만들기(휴직 중, 재직 중)
- 파생 변수 생성
- 근속연수(DATEDIFF) → 집계 방식 평균으로 변경
- 나이(DATEDIFF)
- 만 나이(DATEDIFF, DATEADD) → 구간 차원 만들기
IF [생년월일] > DATEADD('year',-DATEDIFF('year',[생년월일],TODAY()),TODAY())
THEN DATEDIFF('year',[생년월일],TODAY())-1
ELSE DATEDIFF('year',[생년월일],TODAY())
END
03. 데이터 분석 및 인사이트
- 입사 직원 수 파악(라인 차트, 막대 그래프)
- 신입, 경력 누적 막대 차트
- 부서별 인원수(막대 그래프)
- 조직별 평균 근속연수
- 조직별 학력 구분
- 연령별 직원 수(누적 막대)
✅️ 부분 전체 분석
- 전체에서 각각의 멤버들의 값이 어느 정도의 비율을 차지하는지
파이 차트, 도넛 차트, 누적 막대 차트, 트리맵 활용
✅️ 히스토그램
📝 인사이트
- 2006년부터 2009년까지 입사자가 없고 2010년부터 매년 90년 이상 입사했다.
- 2001년부터 2005년까지 신입 직원만 채용했고 2010년부터 경력 직원도 함께 채용했다. 계약직 직원은 2018년에만 채용했다.
- 사업본부에 재직 중인 사람이 가장 많고 감사실 직원은 3명으로 가장 적다.
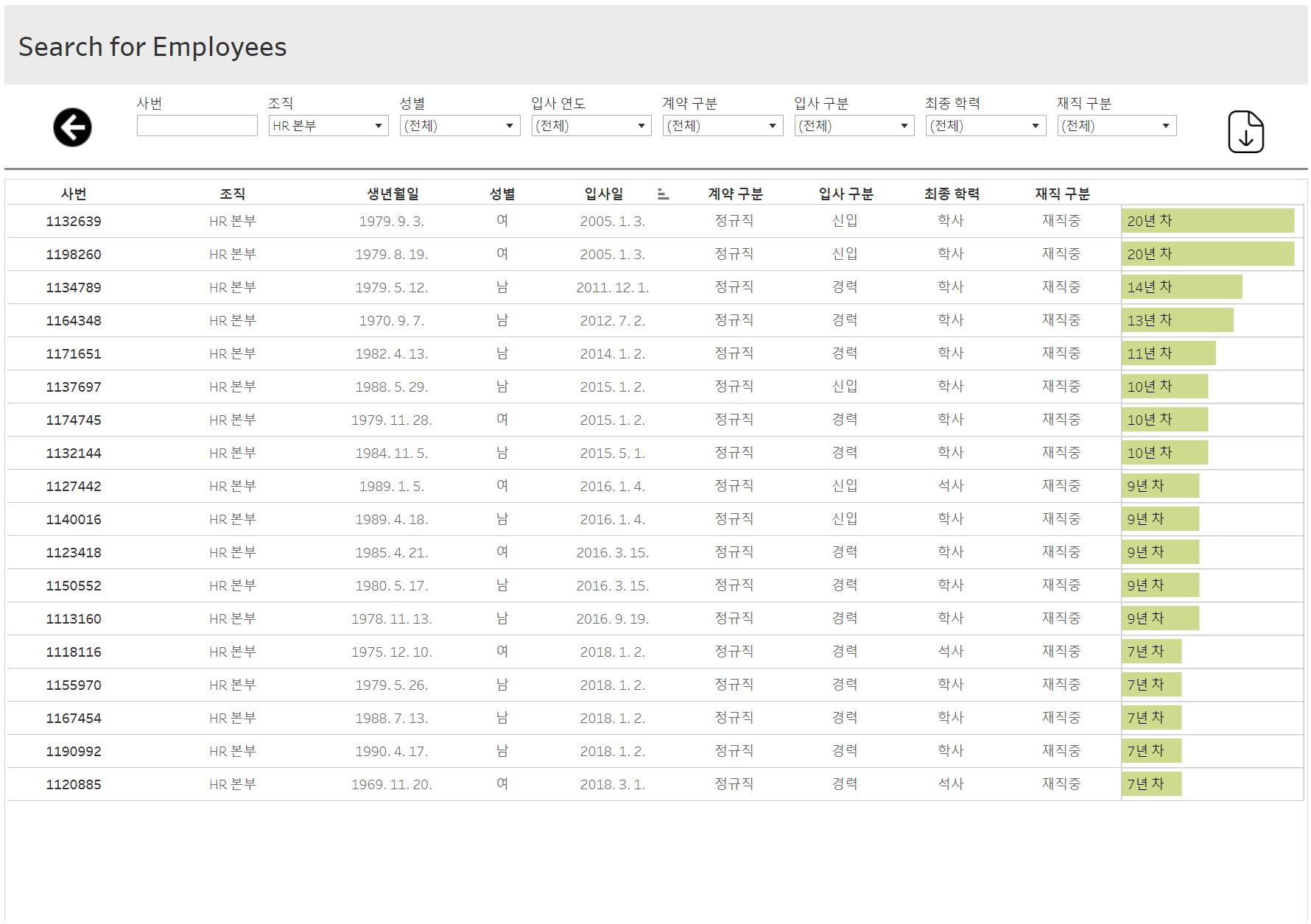
- ICT 연구소 직원의 평균 근속연수는 13.2년으로 가장 길다.
- 박사 학위를 가진 직원이 없는 부서도 있고, Tech Initiatives TF 부서에 박사가 8명, 석사가 38명으로 다른 직원에 비해 석사와 박사 비율이 높다.
- 35~39세 직원이 가장 많다. 20대 직원(7명)은 적은 편이고 55세 이상은 1명밖에 없다.
- 19개의 조직은 TF팀(9개)과 TF 이외 팀(10개)으로 구분된다. 이를 기반으로 그룹을 나눠 시각화를 진행했다.
04. 느낀 점
- 대시보드를 구성해야 한다는 생각이 앞서 있었는데, 시각화 전에 데이터 이해 및 전처리 작업이 중요하다는 생각이 들었다.
- NULL 값에 대한 처리 등 간단해 보이는 작업이지만 필수로 진행
- 연령대 범위를 계산된 필드가 아닌 구간 차원으로 바로 나눌 수 있어서 편리했다.
- 활용할 수 있는 변수가 많을 때는 하나의 대시보드에 모든 것을 표현하기보다 적절히 내용을 분산시켜 상세 내용을 표현해야겠다.
- 데이터에 대해 파악하고 의견을 공유하면서 내가 놓쳤던 부분도 알 수 있었고, 의사소통을 기반으로 협업이 중요하다는 점을 다시 느꼈다.
- 태블로 퍼블릭에서 해외 HR 대시보드도 살펴봤는데 인종이나 성별 항목이 달랐고 미국 같은 경우 다른 주에 위치한 회사의 직원도 파악할 수 있었다. 인사관리라는 목적으로 만들어진 대시보드의 형태가 정말 다양했고 본사뿐만이 아니라 해외라든지 지사가 여러 개 있는 회사에서 HR 대시보드를 사용하면 효율적일 것 같다.
05. 한계
- 인사관리자 입장에서 어떤 항목을 중요시할지 궁금했다. 부서 이동, 퇴사자, 근무 평가나 급여, 직원 만족도 등의 데이터가 없어서 아쉬웠다.
- 다양한 변수로 여러 차트를 만들 수 있었지만 대시보드 구조를 생각하는 데 시간이 오래 걸렸다. 대시보드 구조를 생각하고 진행했음에도 생각대로 되지 않아 구조를 몇번이나 바꿨다.
- 대시보드에 휴직자 수도 명시했는데 0명일 때 표시가 안됐는데 왜 그러는지 못 찾았고, 표나 그래프의 서식(테두리, 라인 등) 설정에 대해 더 알아봐야겠다.
