▷ 오늘 학습 계획: EDA 강의(CCTV 1~2)
📖 Pandas 기초
Pandas: powerful Python data analysis toolkit
Python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
단일 프로세스에서는 최대 효율
코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
누군가는 스테로이드를 맞은 엑셀로 표현함
import MODULE → MODULE.function으로 사용
import MODULE as md → md.function
from MODULE import function → function
- import pandas as pd
import numpy as np
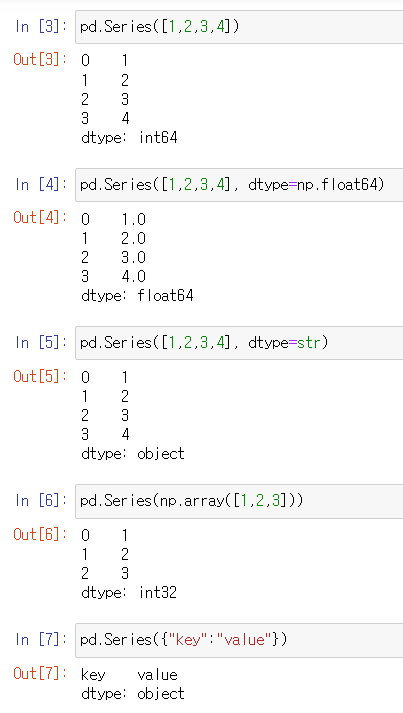
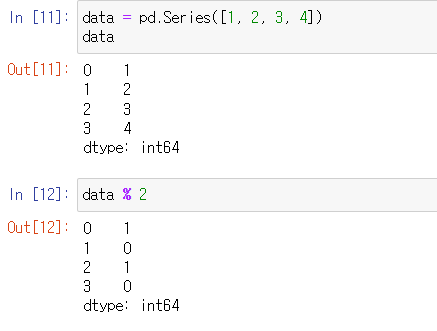
Pandas series
Pandas의 데이터형을 구성하는 기본, 한 가지 데이터 타입만 가질 수 있음
pd.Series() → index, value
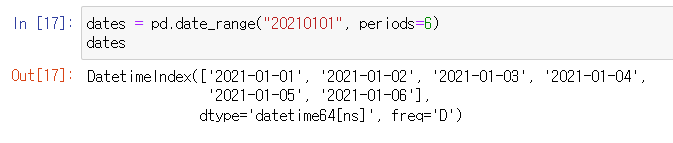
- pd.date_range: 날짜(시간)를 이용할 수 있다.
DataFrame
- Pandas에서 가장 많이 사용되는 데이터형
pd.DataFrame() → index, value, column
ex) 표준정규본포에서 샘플링한 난수 생성: data = np.random.randn(6,4)
df= pd.DataFrame(data, index=dates, columns=["A", "B", "C", "D"])- 데이터 프레임 정보 탐색
.head() → 상단 5개까지
.tail() → 하단 5개까지
.index → DataFrame의 index 확인
.columns → DataFrame의 column 확인
.values → DataFrame의 value 확인
.info() → 데이터 프레임의 기본 정보 확인(각 컬럼의 크기, 데이터 형태 등)
.describe() → 데이터 프레임의 기술통계 정보 확인
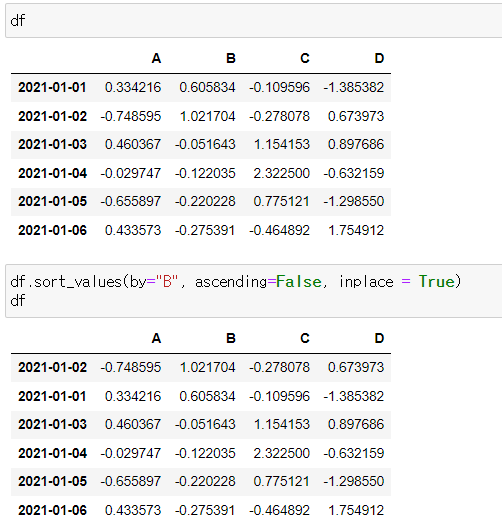
데이터 정렬
.sort_values() → 특정 컬럼(열)을 기준으로 데이터를 정렬
데이터 선택
- 한 개 컬럼 선택: df["A"] 또는 df.A
(알파벳인 경우에는 해당하는 문자열만 기재하면 되는데 숫자는 안됨)- 두 개 이상 컬럼 선택하려면 리스트 안에 담기: df[["A", "B"]]
Pandas Slice
- offset index
[n:m] : n부터 m-1까지 선택
인덱스나 컬럼의 이름으로 slice 하는 경우에는 끝을 포함- loc : location의 약자(index 이름으로 특정 행, 열을 선택)
- iloc : inter location(컴퓨터가 인식하는 인덱스 값으로 선택)
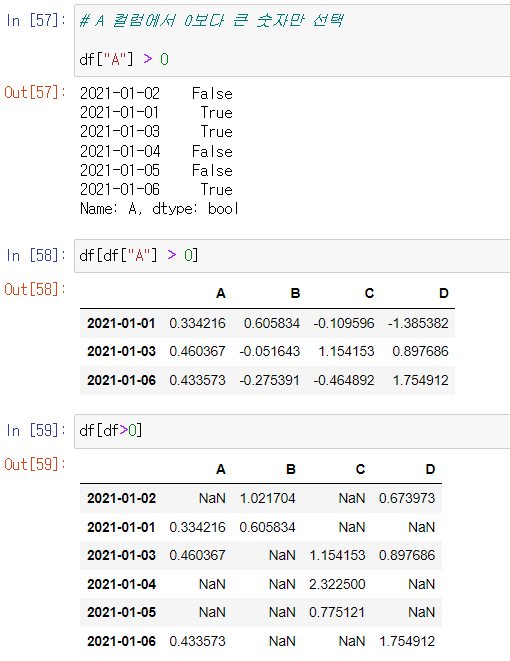
- condition
df[condition]으로 사용하는 것이 일반적이며 Pandas 버전에 따라 문법이 다르다
컬럼 추가: 기존 컬럼이 없으면 추가, 기존 컬럼이 있으면 수정
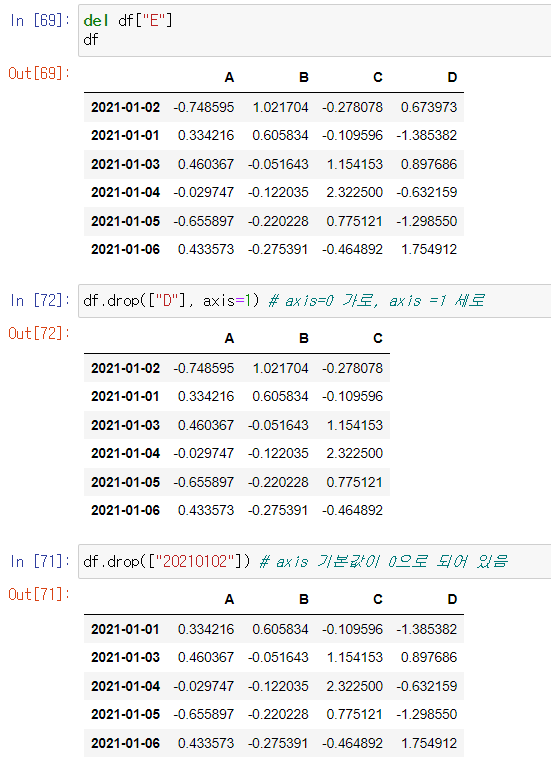
특정 컬럼 제거: del, drop
다중 컬럼에서 특정 컬럼 제거: df.columns.droplevel()
.isin(): 특정 요소가 있는지 확인 → True/False
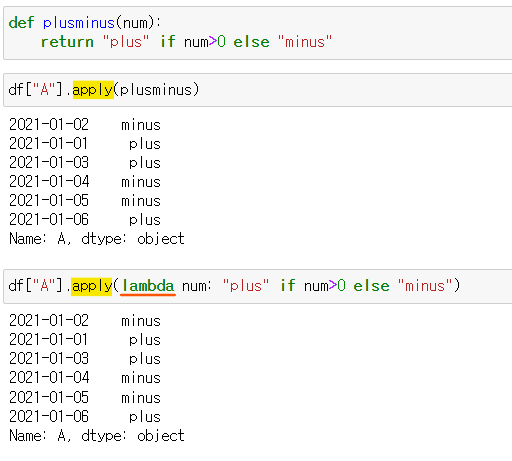
.apply()
ex) df.apply("sum")
df.apply(np.sum)
Pandas 데이터 합치기
- pd.concat()
- pd.join()
- pd.merge()
두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
기준이 되는 컬럼이나 인덱스를 키값이라고 한다.
기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 한다.
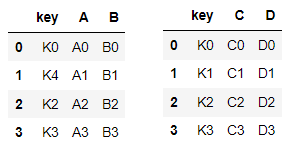
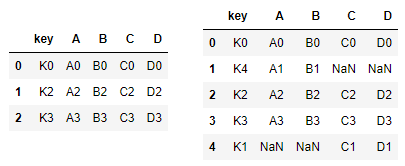
#1) 딕셔너리 안의 리스트 형태 left = pd.DataFrame({"key" : ["K0", "K4", "K2", "K3"], "A" : ["A0", "A1", "A2", "A3"], "B" : ["B0", "B1", "B2", "B3"]}) #2) 리스트 안의 딕셔너리 형태 right = pd.DataFrame([{"key":"K0", "C":"C0", "D":"D0"}, {"key":"K1", "C":"C1", "D":"D1"} {"key":"K2", "C":"C2", "D":"D2"} {"key":"K3", "C":"C3", "D":"D3"}])
- pd.merge(left, right, on="key")
→ how = "inner" 기본값으로 지정되어 있음(교집합)- pd.merge(left, right, how="outer", on="key)
→ how = "outer" : 합집합
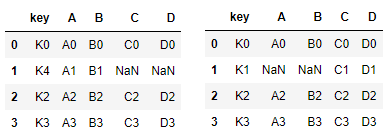
- pd.merge(left, right, how="left", on="key")
- pd.merge(left, right, how="right", on="key")
인덱스 변경
.set_index()
선택한 컬럼을 데이터 프레임의 인덱스로 지정
상관관계
두 변량 사이에 한쪽이 증가하면 다른 쪽도 증가(또는 감소)하는 경향이 있을 때, 이 두 변량 사이에는 상관관계가 있다고 한다.
단, 상관관계가 있다고 해서 두 변량이 인과관계인 것은 아니다.
- 0.2 이하: 상관관계가 없거나 무시해도 좋은 수준
- 0.4 이하: 약한 상관관계
- 0.6 이상: 강한 상관관계
상관계수
corr() → correlation의 약자로, 상관계수가 0.2 이상인 데이터를 비교
문자열 데이터가 있으면 상관관계가 나오지 않음
📖 Matplotlib 기초
- 파이썬의 대표 시각화 도구
- Jupyter Notebook 유저의 경우 matplotlib의 결과가 out session에 나타나는 것이 유리하므로 %matplotlib inline 옵션을 사용한다.
import matplotlib.pyplot as plt #(참고) matplotlib만 불러오는 경우 import matplotlib as mpl plt.rcParams[axes.unicode_minus] = False #마이너스 부호 때문에 한글이 깨질 수 있어서 주는 설정 from matplotlib import rc rc("font", family="Malgun Gothic") %matplotlib inline #또는 get_ipython().run_line_magic("matplotlib", "inline")matplotlib 그래프 기본 형태
plt.figure(figsize=(10,6)) plt.plot(x,y) plt.show()
삼각함수 그리기
np.arange(a, b, s): a부터 b까지 s의 간격으로
np.sin(value)import numpy as np t = np.arange(0, 12, 0.01) y = np.sin(t) plt.figure(figsize=(10,6)) plt.plot(t, np.sin(t)) # plt.plot(t, np.sin(t), label = "sin") plt.plot(t, np.cos(t)) # plt.plot(t, np.sin(t), label = "cos") plt.grid(True) plt.legend(labels = ["sin", "cos"], loc = "lower left") #범례 plt.title("Example of sinewave") plt.xlabel("time") plt.ylabel("Amplitude") plt.show()
- 격자무늬 추가: plt.grid(True) / plt.grid(False)
- 그래프 제목 추가: plt.title()
- x축, y축 제목 추가: plt.xlabel(), plt.ylabel()
- 각각의 선이 나타내는 데이터 의미 구분: plt.legend()

그래프 커스텀
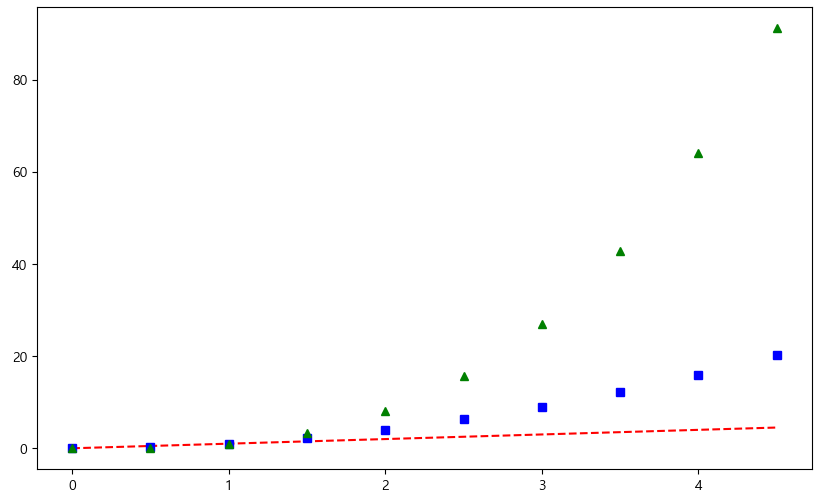
t = np.arange(0, 5, 0.5) plt.figure(figsize=(10,6)) plt.plot(t, t, "r--") plt.plot(t, t ** 2, "bs") plt.plot(t,t ** 3, "g^") plt.show()
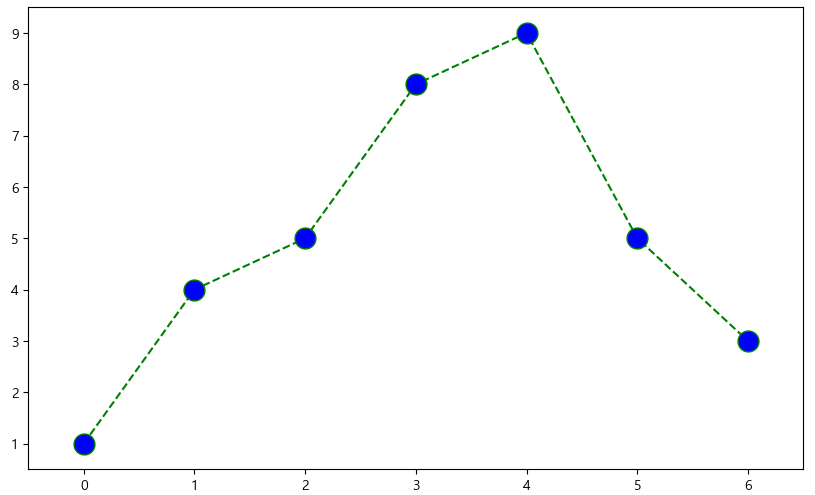
t = list(range(0,7)) y = [1, 4, 5, 8, 9, 5, 3] def drawGraph(): plt.figure(figsize = (10,6)) plt.plot( t, y, color = "green", linestyle = "dashed", #linestyle = "--" #linestyle = "-" marker = "o", markerfacecolor = "blue", markersize = 15, ) plt.xlim([-0.5, 6.5]) plt.ylim([0.5, 9.5]) plt.show() drawGraph()
scatter plot
t = np.array(range(0,10)) y = np.array([9, 8, 7, 9, 8, 3, 2, 4, 3, 4]) def drawGraph(): plt.figure(figsize=(10,6)) plt.scatter(t,y) plt.show() drawGraph()
colormap 적용하기
colormap = t def drawGraph(): plt.figure(figsize=(10,6)) plt.scatter(t,y, s=100, c=colormap, marker=">") plt.colorbar() plt.show() drawGraph()
Pandas에서 plot 그리기
matplotlib 가져와서 사용하기
- Pandas DataFrame은 데이터 변수에서 바로 plot()명령을 사용할 수 있다
data_result["인구수"].plot(kind="bar", figsize=(15,10)) data_result["인구수"].plot(kind="barh", figsize=(15,10))
Numpy를 이용한 1차 직선 만들기
np.polyfit(): 직선을 구성하기 위한 계수를 계산
np.poly1d(): polyfit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어 주는 기능
np.linspace(a, b, n): a부터 b까지 n개의 등간격 데이터 생성
📝 미니콘다, 주피터 노트북, matplotlib 등 처음 다뤄보는 프로그램이 많았다. 파이썬을 여기저기서 활용할 수 있어서 신기하기도 했지만 모르는 게 너무 많았다.
▷ 내일 학습 계획: EDA 강의(CCTV 3~5)
