▷ 오늘 학습 계획: EDA 강의(범죄 1~3)
Pandas pivot table
index, columns, values, aggfunc
values에 함수(기본값: 평균), 갯수 적용 가능(aggfunc=np.sum, len)
NaN에 대한 처리 지정: fill_value
하단에 합계 나오게 지정: margins = True# 인덱스 설정 pd.pivot_table(df, index="Name") df.pivot_table(index="Name")# values, 함수, columns 설정 df.pivot_table( index=["Manager", "Rep"], values = "Price", columns = "Product", aggfunc=np.sum)# Nan 값 설정 : fill_value df.pivot_table( index=["Manager", "Rep"], values = "Price", columns = "Product", aggfunc=np.sum, fill_value=0)# 총계 추가 df.pivot_table( index=["Manager", "Rep", "Product"], values = ["Price", "Quantity"], aggfunc=[np.sum, np.mean], fill_value=0, margins=True)
Python 모듈 설치
- pip 명령
python의 공식 모듈 관리자
pip list: 현재 설치된 모듈 리스트 반환
pip install module_name: 모듈 설치
pip uninstall module_name: 설치된 모듈 제거# !pip list get_ipython().system("pip list")
- conda 명령
conda list: 설치된 모듈 list
conda install module_name
conda uninstall module_name
conda install -c channel_name module_name
: 지정된 배포 채널에서 모듈 설치- pip 사용 시 conda 환경에서 dependency 관리가 정확하지 않을 수 있어서 아나콘다에서는 가급적 conda 명령으로 모듈을 관리하는 것이 좋다.
모든 모듈이 conda로 설치되는 것은 아니다.
Google Maps API 설치
터미널에서 googlemaps 패키지 설치
conda install -c conda-forge googlemaps
Google Map API Key 필요함
Python의 반복문
MATLAB은 반복, 조건, 함수 모두 end로 끝나게 해서 구분
C/C++은 중괄호로 구문의 시작과 끝을 구분
Python은 들여쓰기로 구분[n**2 for n in range(0,10)] # 결과: [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
- 파이썬에서 for 문을 한 줄로 요약하는 것: list comprehension
- Pandas에 잘 맞춰진 반복문용 명령: iterrows()
Pandas 데이터 프레임은 대부분 2차원이여서 for문을 사용하면 n번째라는 지정을 반복해서 가독률이 떨어짐
Pandas 데이터 프레임으로 반복문을 만들때 iterrows()라는 옵션을 사용하면 컬럼이름을 바로 사용할 수 있어서 편함(인덱스, 내용 받기)
컬럼 나누기
- 하나의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu['강도검거'] / crime_anal_gu['강도발생']
- 다수의 컬럼을 다른 컬럼으로 나누기
crime_anal_gu[['강도검거', '폭력검거']].div(crime_anal_gu['강도발생'], axis = 0)
- 다수의 컬럼을 다수의 컬럼으로 각각 나누기
num = ["강간검거", "강도검거", "살인검거", "절도검거", "폭력검거"] den = ["강간발생", "강도발생", "살인발생", "절도발생", "폭력발생"] crime_anal_gu[num].div(crime_anal_gu[den].values)
Seaborn
seaborn은 matplotlib과 함께 실행된다.
import matplotlib.pyplot as plt import seaborn as sns # %matplotlib inline get_ipython().run_line_magic("matplotlib", "inline")
seaborn 기초
sns.set_style() → "white", "whitegrid", "dark", "darkgrid", "ticks"
despine 적용: sns.despine(offset=10)
seaborn 에는 실습용 데이터가 몇 개 내장되어 있다.
seaborn tips data
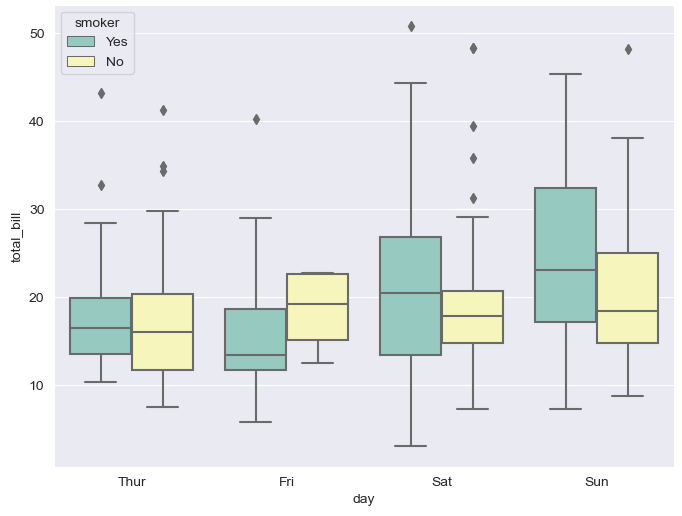
- boxplot
hue: 카테고리 데이터 표현
palette optionplt.figure(figsize=(8,6)) sns.boxplot( x = "day", y = "total_bill", data = tips, hue = "smoker", palette = "Set3") plt.show()
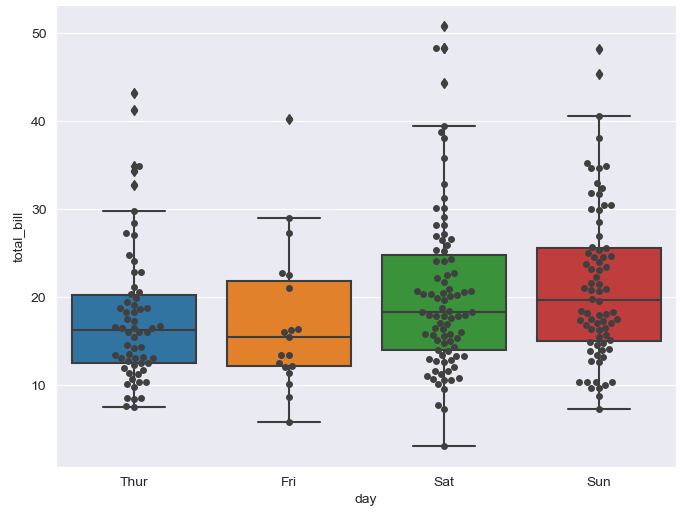
- swarmplot
color: 0~1(검은색~흰색 사이 값을 조절)plt.figure(figsize=(8,6)) sns.swarmplot(x="day", y="total_bill", data=tips, color = "1") plt.show()
- boxplot with swarmplot
plt.figure(figsize=(8,6)) sns.boxplot(x="day", y="total_bill", data=tips) sns.swarmplot(x="day", y="total_bill", data=tips, color="0.25") plt.show()
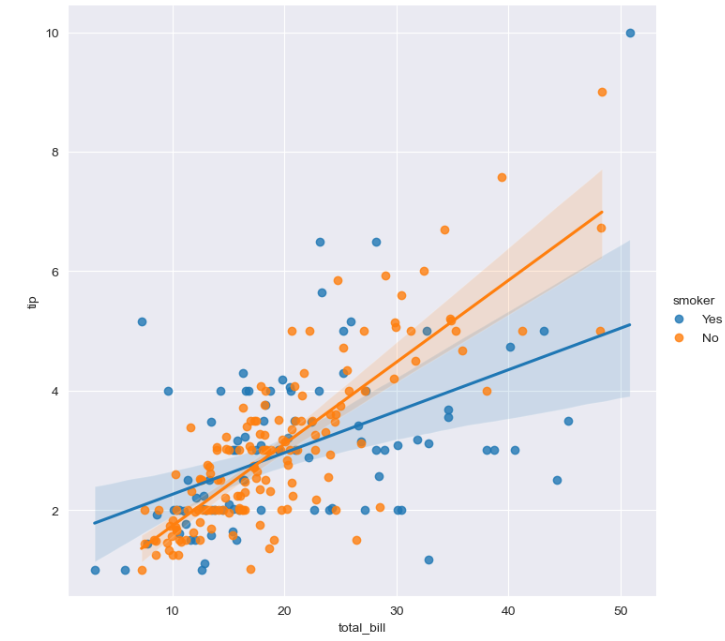
- lmplot
lmplot: total_bill과 tip 사이 관계 파악
hue 옵션 사용 가능sns.set_style("darkgrid") sns.lmplot(x="total_bill", y="tip", data=tips, size=7, hue="smoker") plt.show()
seaborn flights data
- heatmap으로 전체 경향 파악하기
2차원 숫자 배열을 색상으로 표현하는 기능
annot=True/False(데이터 값 표시)
fmt="d"(정수형 표현)
cmap으로 colormap 적용plt.figure(figsize=(10,8)) sns.heatmap(flights, annot=True, fmt="d", cmap="YlGnBu") plt.show()
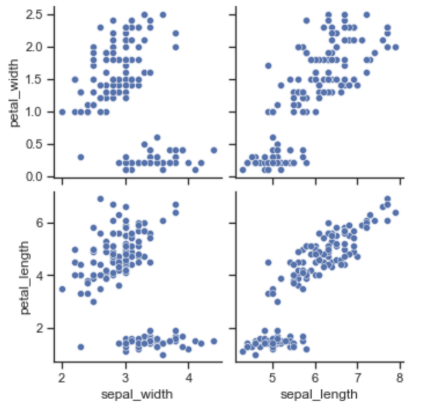
seaborn iris data
pairplot: 다수의 컬럼을 비교
hue 옵션 지정 가능, 원하는 컬럼만 pairplot 가능sns.pairplot( iris, x_vars=["sepal_width", "sepal_length"], y_vars=["petal_width", "petal_length"]) plt.show()
seaborn anascombe data
- lmplot
ci 신뢰구간 선택
order option
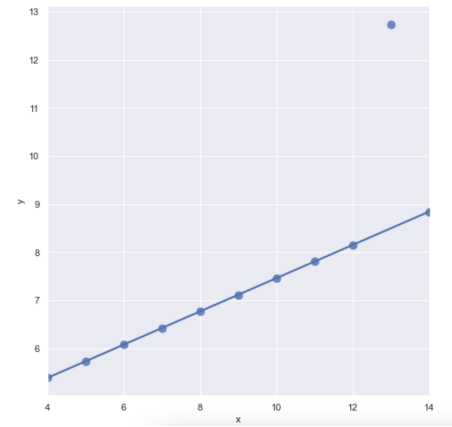
outlier(robust=True)sns.set_style("darkgrid") sns.lmplot( x = "x", y = "y", data = anscombe.query("dataset == 'III'"), ci = None, size =7, scatter_kws = {"s":10}) plt.show()
folium 지도 시각화
jupyter notebook에서 설치
!pip install folium # 오류 발생할 경우 아래 먼저 설치 # !pip install charset # !pip install charset-normalizerimport folium import pandas as pd import json
follium.Map()
location: tuple or list, default None
Latitude and Longitude of Map (Northing, Easting).m = folium.Map(location=[위도, 경도], zoom_start=14) # 0~18save(): html로 저장 가능
m.save("./folium.html") !dirtiles option: 지도 스타일 지정
"OpenStreetMap"
"Mapbox Bright" (Limited levels of zoom for free tiles)
"Mapbox Control Room" (Limited levels of zoom for free tiles)
"Stamen" (Terrain, Toner, and Watercolor)
"Cloudmade" (Must pass API key)
"Mapbox" (Must pass API key)
"CartoDB" (positron and dark_matter)m = folium.Map( location=[37.447, 127.1384], zoom_start=14, tiles="Stamen Terrain" )
folium.Marker(): 지도에 마커 생성
folium.Marker((37.5834, 126.9772)).add_to(m)
- popup, tooltip
folium.Marker( location = [37.4444, 127.1388], popup = "<b>medical</b>", #마커 클릭시 표현될 문구 tooltip = "<i>의료원</i>" ).add_to(m) # popup → 페이지로 연결되도록 링크도 지정할 수 있음 popup = "<a href='https://www.naver.com' target=_'blink'>naver</a>>"
folium.Icon()
- icon basic
# 기본값 color="blue", icon="info-sign" folium.Marker((37.5834, 126.9772), icon=folium.Icon(color="black", icon='info-sign')).add_to(m)
- icon icon_color
folium.Marker(icon=folium.Icon(color="red", icon_color="white", icon="cloud"))
- icon custom
folium.Marker(icon=folium.Icon(color="beige", icon_color="white", icon="android", angle=50, prefix="fa")).add_to(m)prefix → 'fa' 또는 'glyphicon'
아이콘 참고: font-awesome 또는 glyphicon
folium.ClickForMarker(): 지도 위에서 클릭했을 때 마커 생성
m.add_child(folium.ClickForMarker(popup="ClickForMarker"))folium.LatLngPopup(): 지도 위에서 클릭했을 때 위도 경도 정보 반환
m.add_child(folium.LatLngPopup())folium.Circle(), folium.CircleMarker()
folium.Circle(location = [37.5436, 127.0386], radius = 100, fill = True, color="#f5d442", fill_color="red", popup="Circle Popup", tooltip="Circle Tooltip" ).add_to(m)folium.Choropleth()
import json m = folium.Map([43, -102], zoom_start=3) folium.Choropleth( geo_data="../data/02. us-states.json", # 경계선 좌표값이 담긴 데이터 data = state_data, # Series or DataFrame columns=["State", "Unemployment"], key_on="feature.id", fill_color="BuPu", fill_opacity=1, #0~1 line_opacity=1, #0~1 legend_name="Unemployment rate (%)" ).add_to(m)
▷ 내일 학습 계획: EDA 강의(범죄 4~6)
